Chapter 27. Foreign Code
Embed some foreign code into an external DSL to provide more elaborate behavior than can be specified in the DSL.

By definition, a DSL is a limited language that only does a few things. Sometimes, however, you need to describe something in the DSL script that is beyond the capabilities of the DSL. One solution may be to extend the DSL to handle this capability, but taking this path may significantly complicate the DSL, removing much of the simplicity that makes it appealing.
Foreign Code embeds a different language—often, a general-purpose language—into certain places in the DSL.
27.1 How It Works
Putting bits of another language into a DSL involves two questions. First, how do we recognize these foreign pieces and weave them into the grammar, and second, how do we execute this code so it can do its job?
Foreign Code only appears in certain parts of a DSL, so the DSL’s grammar will mark the spots where it can show up. One wrinkle in handling Foreign Code is that the grammar will not be able to recognize the internal structure of the Foreign Code. As a result, you will usually need to use Alternative Tokenization with a Foreign Code and read it into the parser as one long string. You can then either embed that string into the Semantic Model in its raw form, or pass it to a separate parser for the Foreign Code in order to weave it more intimately into the Semantic Model. The latter is more involved—it’s something you’d only consider if your Foreign Code is another DSL. Often, the Foreign Code is a general-purpose language, in which case the pure string is usually enough.
Once the Foreign Code is in the Semantic Model, we have to decide what to do with it. The biggest issue lies in whether the Foreign Code can be interpreted or needs to be compiled.
Interpreted Foreign Code is usually the easiest, providing you have a mechanism to interoperate the interpreter with the host language. If the host language of the system is also interpreted, it’s easy to use the host language itself for Foreign Code. If the host language is compiled, then you’ll need to use an interpreted language that can be called from the host language, allowing for some data transfer. Increasingly, we see static language environments gaining the ability to interoperate with interpreted languages. It’s usually a bit fiddly, especially when it comes to moving data around. It also might involve introducing another language to the project, which can sometimes be an issue.
The alternative is to embed the host language itself, even if it’s a compiled language. The complexity here is that this introduces an extra compilation step into the build process, just like using code generation. Of course if you are actually doing code generation, you have to do this extra compilation step anyway, so adding compiled Foreign Code doesn’t make things any more complex. The complexity matters if you’re compiling code while interpreting the Semantic Model.
Whenever you use general-purpose Foreign Code, you should seriously consider using an Embedment Helper. That way, the only Foreign Code in your DSL script should be the minimum required for the context within the DSL, calling out to the Embedment Helper for any more general processing. One of the big problems with Foreign Code is that a lot of foreign code can overwhelm the DSL, thus losing most of the advantages of readability that the DSL offers. Embedment Helper is an easy technique and is worth it in all but the smallest cases.
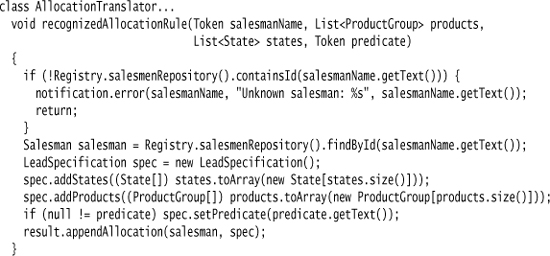
Sometimes, the Foreign Code needs to refer to symbols that are defined in the DSL script itself. This only occurs if the DSL script includes variables or other ways to create indirect constructs. While these are omnipresent in general-purpose languages, they are actually not so common in DSLs as DSLs often don’t need that kind of expressiveness. As a result, these seem rare in practice, but are nevertheless a familiar case because they crop up in grammars—which are a common case of using Foreign Code. Here’s an example of this:

Here the Foreign Code is Java. The Java code includes references to salesman, pc, lc, and predicate, all of which are symbols defined in the grammar. When processing the Foreign Code, the Parser Generator needs to resolve these references.
27.2 When to Use It
When you’re thinking about using Foreign Code, the usual alternative is to extend the DSL to do what you’re considering the Foreign Code for. Introducing Foreign Code certainly has its downsides. By using it, you are breaking the abstraction that the DSL gives you. Anyone who reads the DSL now needs to understand the Foreign Code as well as the DSL itself—at least to an extent. Also, using Foreign Code complicates the parsing process and probably complicates the Semantic Model as well.
These added complexities have to be weighed against the additional complexity you’d need to add to the DSL to support the capability you need. The more powerful the DSL, the harder it is to understand and use.
So what are the cases that lean to using Foreign Code? One natural case is when you really need a general-purpose language. You certainly don’t want to turn your DSL into a general-purpose language, so that pushes you quickly to using Foreign Code.
Another case for Foreign Code is when you only need a capability very rarely in your DSL scripts. A rarely used capability may not be worth extending the DSL for.
Who uses the DSL is a factor in the decision. If the DSL is only used by programmers, then adding Foreign Code is not a problem—they will be able to understand the Foreign Code as much as the DSL. If nonprogrammers will read the DSL, that argues against Foreign Code as they may not be able to understand, and thus engage with, the foreign code. If the Foreign Code is to handle rare cases, however, this may not be a big problem.
27.3 Embedding Dynamic Code (ANTLR, Java, and Javascript)
In order to sell stuff, you need salesmen; if you have many salesmen, you need some way to decide how to allocate the leads to them. A common notion is that of “territories,” which are effectively a set of rules for distributing leads to salesmen. These territories can be based on various factors; here’s an allocation script that uses US states and products:

It’s a simple DSL where each allocation rule is checked in sequence, and once a deal matches the conditions, the lead is allocated to that salesman.
Now, let’s imagine that Scott has got very friendly with an executive at Baker Industries, who operate in southern New England. Since they spend so much time on the golf course together, we want any leads involving floor wax at Baker Industries to go to Scott. To complicate matters, Baker Industries has a number of variations on its name: Baker Industrial Holdings, Baker Floor Toppings, etc. So we decide that we want any lead with a company whose name starts with “Baker” in New England to go to Scott.
To do this, we could extend our DSL, but since it’s one of those particular cases that would end up complicating the language, we’ll go for some Foreign Code instead. This is what we’d like to say:
scott handles floor_wax in MA RI CT when {/^Baker/.test(lead.name)};
The foreign code I’m using here is Javascript, which I’ve picked because it’s easily integrated with Java and can be evaluated at runtime, which avoids recompilation when someone changes the allocation rules. The Javascript code isn’t exactly super readable—I suspect I’d have to say “trust me” to the sales manager—but it will do the job. I’m also not using Embedment Helper here, as the predicate is very small.
27.3.1 Semantic Model
Figure 27.1 The model for lead allocation
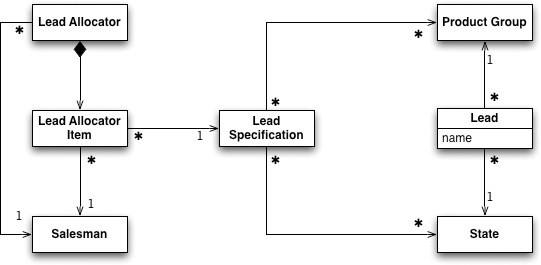
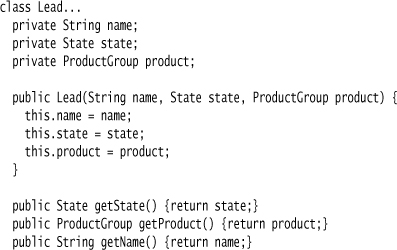
In this simple model, we have leads, and each lead has a product group and a state.
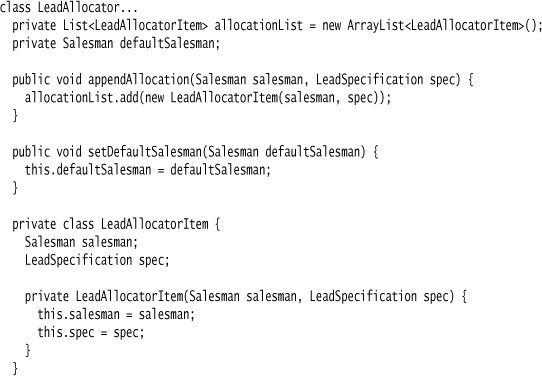
To allocate these leads to salesmen, we have a lead allocator which contains a list of items that link salesmen to lead specifications.
A lead specification follows the Specification [Evans DDD] pattern, set to match the lead if the lead’s attributes are included in the specification’s lists.

The specification also contains a predicate, which is some embedded Javascript code. The specification evaluates that using Java’s Rhino Javascript engine.

I add the lead that’s being evaluated to the scope of the Javascript evaluation, so that the embedded Javascript code can access the lead’s properties.
The lead allocator works by running down the list of items, returning the first salesman with a matching specification.

27.3.2 Parser
The main driver class for the translation builds a lead allocator as its result.

The allocation translator also acts as the Embedment Helper for the grammar file.

I’ll walk through the grammar file from the top down. I’m using Embedded Translation.
Here are the core tokens I’m using:
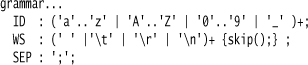
This defines the usual whitespace and identifier tokens, together with an explicit semicolon statement separator.
Here’s the top-level rule of the grammar:

I’m assuming the salesmen, products, and states all exist before we interpret the allocation rules, probably in a database. For this example, I’ll access this data using Repositories [Fowler PoEAA].
At the risk of getting all recursive, you might enjoy the point that this grammar also demonstrates Foreign Code—the code actions in a grammar are an excellent example of Foreign Code. With ANTLR, the Foreign Code gets woven into the generated parser during code generation, which is a different approach from what I’m doing with the Javascript allocation rule. But the same basic Foreign Code pattern is still in play. I’m also using Embedment Helper to keep the amount of Foreign Code down to a minimum.
Now it’s time for me to return to the plot and show you the allocation rule.

The rule is pretty straightforward. It calls for a salesman name, product, and location clauses (subrules) as well as an optional predicate token and a separator. The fact that the predicate is a token rather than a subrule is important, because we want to take all the Javascript as a single string and won’t parse it further.
I have a single helper call to record the recognition, which I’ll go into when we see what the product and location clauses return. I’ve followed a convention of giving a fully spelled-out name to the labels for a salesman and predicate, because the tokens aren’t sufficiently clear. I’ve used abbreviations for the labels for the subrules because those subrule names are clear, so a full label would be just duplicating the subrule name and thus add noise.
Let’s look at the subrules, in particular the product clause.

I’ve made the clause itself return a list of product groups. As a result, it doesn’t populate the Semantic Model itself but returns the objects for the parent clause to populate the Semantic Model. I do this because otherwise I need to access the current allocation rule inside the action for the product rule. This would usually require a Context Variable which I’d like to avoid. ANTLR has the ability to pass down objects as rule arguments—so I could do that there instead—but I prefer to do all the Semantic Model in the one place.
I still need an action to convert the product tokens to actual product objects. This is just a simple lookup in the repository.
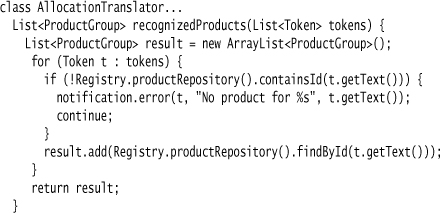
The location clause works pretty much the same way, so I’ll move on to the meat of this example—grabbing the Javascript. As I indicated above, I do this in the lexer. After all, I don’t care about the content of the Javascript, so I’m just going to bung the entire string into the lead specification. There’s no point in building or using a Javascript parser, unless I want to check during parsing whether the Javascript is syntactically legal. Since parsing would only detect a syntactic error and not a semantic error, I don’t think it’s worth the trouble.
I use Alternative Tokenization to grab the text. The simplest way is to choose a pair of delimiters that aren’t being used for anything else and have a token rule like this:
ACTION : '{' .* '}' ;
This is a reasonable rule which will work in many situations. However, it does have a potential problem—things go awry if I have any curly brackets inside the Javascript code itself. I can avoid this by using more unlikely delimiters, for example pairs of characters.
ACTION : '{:' .* ':}' ;
In ANTLR, however, I can make use of its own ability to handle nested tokens.

It’s not quite perfect; I’d be defeated by a Javascript fragment of badThing = "}"; but it should do for most cases.
With the subclause collections, and the Javascript predicate, I can update the Semantic Model.