
Chapter 29. Nested Operator Expression
An operator expression that can recursively contain the same form of expression (for example, arithmetic and Boolean expressions).
2 * (4 + 5)
Calling Nested Operator Expression a pattern is a bit of a stretch, since it isn’t so much a solution as it is a common problem in parsing. This is particularly the case with bottom-up parsers where you need to avoid left recursion.
29.1 How It Works
Nested Operator Expressions have two aspects that can make them a bit tricky—their recursive nature (the rule appears in its own body) and sorting out precedence. Exactly how to deal with these depends in part on the particular Parser Generator you are using, but there are some useful general principles that apply. The biggest difference lies in how bottom-up and top-down parsers work with them.
My example problem is a calculator that can handle four common arithmetic operations (+ - * /), parenthesized groups, as well as raising to a power (using “**”) and taking a root (using “//”). It also allows a unary minus—referring to a negative number with a minus sign.
This choice of operators means we want several levels of precedence. Unary minus binds tightest, followed by power and root, then multiplication and division, and finally addition and subtraction. I’ve introduced power and root into the problem as they are right-associative operators while the other binary operators are left-associative.
29.1.1 Using Bottom-Up Parsers
I’ll start with bottom-up parsers, because they are the easiest to describe. The basic grammar to handle four-function arithmetic expressions with parentheses looks like this:

This grammar uses the Java CUP Parser Generator, which is essentially a version of the classic Yacc system for Java. The grammar captures the structure of expression syntax in a single production rule, with one alternative for each kind of operator we need to work with, together with the base case where there’s just a number present.
Unlike ANTLR, my usual choice for examples in this book, you can’t put literal tokens into the grammar file, which is why I have token names like PLUS rather than +. A separate lexer translates the operators and numbers into the form that the parser needs.
I’m using Embedded Interpretation here to do the calculation, so you see the resulting calculations following each alternative in the code actions. (Code actions are delimited with {: and :} to make it easier to deal with curlies in the code action.) The special variable RESULT is used for the return value; rule elements are labeled with a trailing :label.
The basic grammar rules handle the recursive structure quite directly, but they don’t handle precedence: we want 1 + 2 * 3 to be interpreted as 1 + (2 * 3). To do this, I can use a set of precedence declarations.
precedence left PLUS, MINUS;
precedence left TIMES, DIVIDE;
precedence right POWER, ROOT;
precedence left UMINUS;
Each precedence statement lists some operators at the same precedence level and says how they associate (left or right). The precedence goes from low to high.
The precedence can also be mentioned in the grammar rules, as it is in the unary minus case with %prec UNMINUS. The UMINUS is a token reference that isn’t a real token; it’s only used to adjust the precedence of that rule. By using this context-dependent precedence, I’m instructing the Parser Generator that this rule doesn’t use the default precedence for the “-” operator, but uses the precedence declared for the ghostly UMINUS operator instead.
In programming language terms, the problem that precedence solves is that of ambiguity. Without the precedence rules, a parser with this grammar could parse 1 + 2 * 3 as (1 + 2) * 3 or as 1 + (2 * 3), which makes it ambiguous. The same is true for 1 + 2 + 3 even though we (humans) know it doesn’t matter in this case. This is why we have to state the direction of associativity as well, even though it doesn’t matter for “+” and “*”.
The combination of a simple recursive grammar rule and precedence declarations makes it very easy to handle nested expressions in a bottom-up parser.
29.1.2 Top-Down Parsers
Top-down parsers are more complicated when it comes to Nested Operator Expression. You can’t use a simple recursive grammar because it would introduce left recursion. As a result, you have to use a series of different grammar rules, which both solves the left recursion problem and handles precedence at the same time. The resulting grammar, however, is much less clear. Indeed, this lack of clarity is why many people prefer a bottom-up parser.
Let’s look at these rules with ANTLR. I’ll start with the two top-level rules, which introduce the two operators at the lowest precedence level. For a pure parse, they would look like this:
expression : mult_exp ( ('+' | '-') mult_exp )* ;
mult_exp : power_exp ( ('*' | '/') power_exp )* ;
Here you see the pattern for left-associative operators. The body of the rule starts with a reference to the next lowest rule, followed by a repeating group with the operators and right-hand sides. At all times, I mention the next-lowest rule rather than the rule I’m in.
The power and root operators show the pattern for a right-associative operator.
power_exp : unary_exp ( ('**' | '//') power_exp )? ;
Notice a couple of differences here that make it right-associative. First, the right-hand side rule is a recursive reference to the rule itself, rather than the next lower rule. Second, instead of a repeating group, it’s just an optional group. The recursion allows multiple power expressions to be combined together, and the right recursion like this is inherently right-associative.
Unary expressions need to support an optional minus sign.

Notice how I use recursion when the sign is present (to allow multiple minus signs in an expression) but the next lower when it isn’t (to avoid left recursion).
Now we get to the lowest level, the atoms of the language (in this case just numbers) and parentheses.
factor_exp : NUMBER | par_exp ;
par_exp : '(' expression ')' ;
Parenthetic expressions introduce deep recursion as they reference the top-level expression again.
(An ANTLR-specific note: ANTLR can get confused if your grammar only has these rules, as there’s no top-level rule that isn’t called by other rules (it gives a “no start rule” error message). So you have to add something like prog : expression;.)
As you can see, this is much more complicated than the bottom-up case. You’re spending your time massaging the Parser Generator rather than expressing intent. The resulting mangled grammars are why many people prefer bottom-up Parser Generators to top-down ones. Advocates of top-down parsing argue that it’s only nested expressions that get thus mangled, and that’s a worthwhile tradeoff compared to the other problems with bottom-up parsers.
Another consequence of this mangled grammar is that the resulting parse tree is more complicated. You would expect the parse tree for 1 + 2 to look something like:

All the grammar rules for precedence add a lot of clutter nodes to the parse tree. This isn’t a huge deal in practice; you need to write code to handle these nodes for the cases when they’re useful, but sometimes they are just irritating.
The grammars I’ve just shown are pure grammars that don’t involve any output production. Doing something with the parsing often introduces some additional mangling. To replicate the calculator Embedded Interpretation, the top-level rule looks like this:
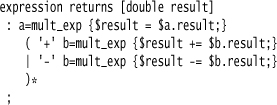
Here, the interplay of code actions and grammar is more involved than I usually like. Since we can have any number of terms at this level (e.g., 1 + 2 + 3 + 4) I need to declare an accumulating variable at the beginning of the expression and accumulate values within the repeating group. Furthermore, since I need to do something different depending on whether it’s a plus or minus, I need to widen the alternative—that is, going from ('+'|'-') mult_exp to ('+' mult_exp | '-' mult_exp). This introduces some duplication, but this is often the case once you actually do something with your grammar. Tree Construction often reduces this problem, but even so you might want to return a different type of node for plus and minus, which would require widening the alternative.
The examples I’ve shown above are all using ANTLR, as it’s the top-down parser that you’re likely to come across. Different top-down parsers have slightly different problems and solutions. Usually they will have documentation on how to deal with left recursion.
29.2 When to Use It
As I indicated earlier, Nested Operator Expression doesn’t quite fit my usual description of a pattern, and if I were a better writer I would do something better than include it here as one. As a consequence, this “when to use it” section only serves to flaunt a fixation with consistency which isn’t usually something I’m known for.