
Chapter 30. Newline Separators
Use newlines as statement separators.
first statement
second statement
third statement
30.1 How It Works
Using newlines to mark the end of a statement is a common feature of programming languages. This fits very well with Delimiter-Directed Translation since newlines are used as the main delimiter to break up the input. As a result I have nothing to add here for that context.
With Syntax-Directed Translation, however, newline separators are rather more tricky, introducing a number of subtle traps that can trip you up. This section will hopefully point out of few of those traps.
(Of course it’s possible to use newlines for a syntactic purpose other than statement separation—but I’ve yet to come across it.)
The reason that newline separators and Syntax-Directed Translation don’t go together too well is that newlines play two roles when you use them as separators. Apart from their syntactic role, they also play a formatting role in providing vertical space. As a result, they can appear in spaces where you wouldn’t expect a statement separator to pop up.
Here’s what I might think of as the obvious grammar for using line endings as separators:

This grammar captures a simple list of items where each line is the keyword item followed by an identifier of the item. I’ve got into the habit of using this grammar as my “Hello World” example for parsing, as it’s drop-dead simple. This grammar is easy to follow—keyword, identifier, newline—but there are a number of common cases that will trip it up:
• Blank lines in between statements
• Blank lines before the first statement
• Blank lines after the last statement
• Last statement on last line has no end-of-line
The first three above are all blank lines, but they may need different ways of handling them in the grammar, so should all be tested. Making sure you have tests for these cases is probably the most important thing to do. I’ve got some solutions for these problems below, but the good tests are the key to ensuring that the situations are covered properly.
One way of handling blank lines effectively is to use an end-of-statement rule that matches multiple newlines. The logical place to put this rule is in the lexer, since it’s a regular rule (I’m using “regular” here in the language theory sense of the word, meaning I can use a regex to match it). This is somewhat complicated by that last test—where the last line of the file is a statement with a missing endof-line. To handle that case you need to match the end-of-file character in the lexer, which, depending on your Parser Generator, may not be possible. So in ANTLR, to do this I need an end-of-statement rule in the parser grammar.
A missing end-of-line on the last line is often an awkward case. How awkward depends on how the Parser Generator deals with an end-of-file. ANTLR makes it available to the parser as a token, which is why I can match it in the parser rules (and not in the lexer rules). Others make matching an end-of-file very hard or impossible. One option to consider is forcing an end-of-line at the end—either through the lexer (if you can) or perhaps by prelexing. Forcing a final end-of-line can help avoid a few awkward corner cases.
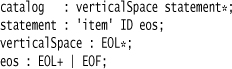
Another approach to dealing with statement terminators—one that avoids the general problem of a missing final terminator—is to think of them as separators instead of terminators. This leads to a rule of this form:
catalog : verticalSpace statement (separator statement)* verticalSpace;
statement : 'item' ID;
separator : EOL+;
verticalSpace : EOL*;
I’ve come to prefer this style. Instead of defining an extra verticalSpace rule, I can use separator?.
A third alternative is to think of a statement body as an optional element for each line of the catalog.
catalog : line* ;
line : EOL | statement EOF | statement EOL;
statement : 'item' ID;
This rule needs to match the end-of-file explicitly in order to handle the missing last end-of-line case. If you can’t match the end-of-file, you need something like:
catalog : line* statement?;
line : statement? EOL;
statement : 'item' ID;
which doesn’t read as clearly to me, but also doesn’t need the end-of-file matching.
A separate element that can also cause a lot of trouble with newline separators is comments. Comments that match up to the end-of-line are very useful. When you are ignoring newlines, you can easily match comments in such a way that eats the newline (although that can trip you up if there’s a final line that’s a comment with a missing end-of-line). When you are using newline separators, however, eating a newline can be a real problem since comments often appear at the end of a statement, like this:
item laser # explain something
If the comment matching eats the newline, then you’ll lose the statement terminator too.
It’s usually easy to avoid this problem by using an expression like this:
COMMENT : '#' ~' '* {skip();};
which in classical regex terms looks like this:
Comment = #[^ ]*
A final issue to bear in mind is to provide some form of continuation character for lines that get too long. This is easily handled with a lexer rule like this:
CONTINUATION : '&' WS* EOL {skip();};
30.2 When to Use It
Deciding to use newline separators is really a pair of decisions: deciding to have statement separators and then deciding to use newlines as the separator character.
The limited structure of a DSL often means that you can live without statement separators. The parser can usually figure out the context of the parse from the various keywords you use. As an example, the introductory grammar for Miss Grant’s controller doesn’t use any statement separators, yet parses quite easily.
Statement separators can make it easier to localize, and thus find, errors. In order for the parser to localize errors it needs some kind of checkpointing marker to tell where it’s supposed to be in the parse. Without checkpointing, an error in one line of the script may not be apparent to the parser until several lines later, leading to confusing error messages. Statement separators can often fulfill this role. (Although they are not the only mechanism that can do this; keywords often do this too.)
If you’ve decided to use statement separators, the choice is between a visible character, such as a semicolon, and a newline. The nice thing about using newlines is that most of the time, you have one statement per line anyway, so using a newline separator doesn’t add any syntactic noise to the DSL. This is particularly valuable when working with nonprogrammers, although many programmers (including myself) prefer newline separators as well. The downside with newline separators is that Syntax-Directed Translation is made more finicky and you have to use the techniques I’ve described here. You also need to ensure you have tests to cover the common problem cases. On the whole, however, I still prefer to use newlines rather than a visible statement separator.