
Chapter 50. Production Rule System
Organize logic through a set of production rules, each having a condition and an action.

There are many situations that are easily thought of as a set of conditional tests. If you are validating some data, you can think of each validation as a condition where you raise an error if the condition is false. Qualifying for some position can often be thought of as a chain of conditions where you qualify if you make it all the way up the chain. Diagnosing a failure can be thought of a series of questions, with each question leading to new questions, and hopefully to the identification of the root fault.
The Production Rule System computational model implements the notion of a set of rules, where each rule has a condition and a consequential action. The system runs the rules on the data it has through a series of cycles, each cycle identifying the rules whose conditions match, then executes the rules’ actions. A Production Rule System is usually at the heart of an expert system.
50.1 How It Works
The basic structure of the rules in a Production Rule System is pretty simple. You have a set of rules where each rule has a condition and an action. The condition is a Boolean expression. The action can be anything, but may be limited depending on the context of the Production Rule System. For example, if your Production Rule System is only doing validation, then your actions may only be raising errors, so each action may specify which error to raise and what data to provide to the error.
The more complex part of a Production Rule System is deciding how to execute the rules. Doing this for general expert systems can be very involved, which is why a whole community of expert systems and a market of tools have developed. As is often the case, however, the fact that a general Production Rule System is very complicated doesn’t mean that you can’t build a simple Production Rule System for limited cases.
A Production Rule System usually puts all the control of rule execution into a single component, often called a rule engine, inference engine, or scheduler. A simple rule engine operates in a series of inference cycles. The cycle begins by running all of the conditions of the available rules. Each rule whose condition returns true is then said to be activated. The engine keeps a list of activated rules, called an agenda. When the engine has finished checking the rules’ conditions, it then looks at the rules on the agenda with the intention of executing these rules’ actions. Executing the action of a rule is called firing the rule.
The sequence in which the rules are fired may be determined in different ways. The simplest approach is to fire the rules in an arbitrary sequence. In this case, the way in which the rules are written doesn’t determine the sequence of firing—which can help keep the computation simple. Another approach is to always fire the rules in the order they are defined in the system. The filter rules of an email system are a good example of this. You define your filters specifically so the first one that matches will process the email, and any rules that might match later won’t get fired.
Another sequencing approach is to define rules with a priority, in expert system circles often referred to as salience. In this case, the rule engine will pick the rule with the highest priority on the agenda to fire first. Using priorities is often considered a smell; if you find yourself using priorities a lot, you should reconsider whether a Production Rule System is the appropriate computational model for your problem.
Another variation in a rule engine is whether to check the rules for activation after each rule is fired, or whether to fire all the rules on the agenda before rechecking. Depending on how the rules are structured, this may affect the behavior of the system.
When you look at a rule base, you’ll often find different groups of rules, with each group being a logical part of the overall problem. In this case, it makes sense to divide the rules up into separate rule sets and evaluate them in a particular order. So, given some rules that do basic validation of data and others that determine qualification, you might choose to run the validation rule set first, and only if there are no errors, to run the qualification rule set.
50.1.1 Chaining
The common case of a series of validation rules is the simplest kind of Production Rule System. In this case, you scan all the rules, and those that fire add an error or warning to some form of log or Notification. One cycle of activation and firing is enough, because the actions of the rules don’t change the state of the data that the Production Rule System is working with.
Often, however, rule actions will change the state of the world. In this case, you need to reevaluate the rule conditions to see if any of them have become true, in which case they get added to the agenda. This interaction between rules is known as forward chaining: You start with some facts, use rules to infer more facts, these facts activate more rules, which create more facts, and so on. The engine stops only when there are no more rules on the agenda.
For the simple sequence in the sketch, all of the rules would be checked first. If the second two rules are both activated and fired, then the first rule gets activated and fired.
Another approach is to work the other way around. In this style, you begin with a goal and examine the rule base to see which rules have actions that would make this goal true. You then take these rules and make them subgoals to find further rules that support them. This style is called backward chaining; it is less common in simple Production Rule Systems as it’s much more involved to get a simple case working. As a result, my discussion here is focused more on forward-chaining or nonchaining engines.
50.1.2 Contradictory Inferences
One of the great advantages of rules is that you can state each rule independently and let the Production Rule System figure out the consequences. But this strength comes with a problem. What if you get chains of inferences that contradict each other? We may have a series of rules for membership in a local military reenactment club that says that to join the freedom-loving American revolutionary army, you have to be over 18, American citizen, have your own imitation musket, etc. Then there’s another rule in section 4.7 which says that British citizens may join the club but can only be part of the army of the cruel tyrants. This works well for a few years, till I turn up as dual citizen; now we have one rule that says I can join the revolutionary army and another that says I can’t.
The biggest danger here is that we may not notice this can happen at all. If the consequence of these rules is to change the value of the isEligibleForRevolutionaryArmy Boolean, then whichever rule runs last will win. Unless we have a defined sequence or priority values on the rules, this could lead to an incorrect inference, or even different inferences depending on hidden qualities in the rule execution sequence.
There are two broad ways to tackle contradictory rules. One is to design the rule structure to avoid them. This involves ensuring that the way the rules run avoids contradiction, perhaps by the way the rules update the data, or by organizing rule sets, or by playing with priorities. In our example, we could start with all the eligibility conditions set to false, and only allow them to be changed to true. This convention would force whoever wanted to keep out the Brits to write the rule in a different way, surfacing the potential contradiction while writing the rules. You have to be careful because a mistake can sneak in a rule that will potentially subvert the design.
An alternative approach is to record all the inferences in such a way that tolerates contradiction, allowing you to spot a contradiction should you get one. In this case, instead of having a Boolean value for eligibility, you would create a separate fact object whose key is eligibilityForRevolutionaryArmy and the value is a Boolean. Once you’re done running the rules, you’d look for all the facts with the key you’re interested in. You could then spot if you had facts with the same key but different values. The Observation [Fowler AP] pattern is one way to handle this kind of situation.
In general, you need to be careful of circles in your rule structure, where multiple rules are arranged so that one keeps the next one firing endlessly. This can happen with contradictory rules that keep arguing with each other, and with rules that get into a positive feedback loop.
Tools specifically designed for Production Rule Systems have their own techniques for dealing with such problems.
50.1.3 Patterns in Rule Structure
While I have seen a few rule bases, I can’t claim to have done any kind of reasonable study of how rule systems tend to be organized. But those few I have seen did reveal a few common patterns in the structure of the rules.
A common, and simple, case is validation. This is simple because all the rules usually have a simple consequence: raising some form of validation error. There’s little, if any, chaining. I suspect most people who work seriously with Production Rule Systems wouldn’t consider these to be rule systems since they are so simple—and, certainly, it seemed an overkill to me to use a specialized rules tool for something like this. However, this kind of simple structure is a nice one for you to write yourself.
Determining eligibility is somewhat more involved. In this kind of rule base, you are trying to assess whether a candidate is eligible for one or more agreements. It could be a system assessing which, if any, insurance policy someone qualifies for, or determining what discount scheme an order may fall into. In this case, the rules can be structured as a progression of steps where lower-level rules lead to higher-level inferences. You can avoid contradictions by keeping all the inferences positive, perhaps with some separate route for disqualifications.
More involved still is some kind of diagnostic system where you observe some problems and want to determine the root cause. Here, you’re much more likely to get contradictions, so having something like Observation [Fowler AP] is more important.
50.2 When to Use It
A Production Rule System is a natural choice when you have behavior that feels like it is best expressed as a set of if-then statements. Indeed, just writing control flow like that is often a good starting point for evolving into a Production Rule System.
The big danger with Production Rule System is that they are so seductive. A small example is easy to understand and demos well to nonprogrammers. What isn’t clear from simple demos is that it may become very hard to reason about what a Production Rule System is doing as it gets bigger, particularly if you are using chaining. This can make debugging very difficult.
This problem is often exacerbated by a rule engine tool. It’s very easy to stretch a tool—to use it in lots of places without realizing how difficult it is to modify until you’ve already built something too large. Thus there is an argument to building something simple yourself, which you can tune to your particular needs as well as use to learn more about the domain and how a Production Rule System can fit in with it. Once you’ve learned more, you can evaluate whether it’s worth replacing your simple Production Rule System with a tool.
I’m not saying that rule engines are always a bad idea, although I’ve yet to see one that’s worked well. What is important is that you should treat them with caution and understand what you are getting into when you use them.
50.3 Validations for club membership (C#)
Validations are a good simple example of a Production Rule System, as they are common and usually don’t involve any chaining. For the example problem, I’ll consider the first stage of an application for joining some imaginary Victorian English club. To process these applications, I’ll use two separate rule sets. The first will do validation on the basic application data, just to make sure the form is filled out properly. The second rule set will evaluate eligibility for an interview, and I’ll describe that in the second example.
Here are a few of the validation rules:
• Nationality must not be null.
• University must not be null.
• Annual income must be positive.
50.3.1 Model
There are two bits of the model I need to describe. The first, and really simple, bit is the data about the person that the rules will work on. This is a simple data class with properties for the various things we’re interested in.

Now I’ll move on to the rule processing part. The basic structure of the validation engine is a list of validation rules.

To run the engine, all I do is run each of the rules, collecting the result in a Notification.
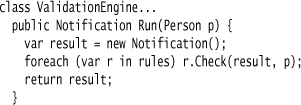
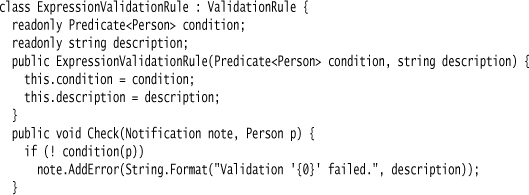
The most basic validation rule takes a predicate and a message to record if it fails.
I can then set up and run rules using the command-query interface with code like this:

50.3.2 Parser
For this example, I’ll use a simple internal DSL. I’ll make direct use of C#’s lambdas to capture the rules. My DSL script starts like this:

I’m using Object Scoping so I can define validation with a simple call to the Validate method, followed by a bit of method chaining to capture the predicate.
Creating the builder sets up an engine. The validate method sets up a child rule builder to capture the rule information.

Using a progressive interface here feels a bit of overkill, since there’s only one method present on the rule builder. But I think the interface name helps communicate what the parser is looking for.
50.3.3 Evolving the DSL
These validations work well to capture the logic—but, hopefully, once you’ve written a few expressions to look for null values, you’d begin to think there should be a better way to do these null checks. If such checks are common, you can place the null check logic in the rule, so all we have to do in the script is state which property should not be null.
One way to do this, which works in many languages, is to write the name of the property as a string and use reflection to check the logic. So I would have this line in the DSL script:
MustHave("University");
To support this, I need to augment the model and parser.

I want to stress here that I didn’t need to change the Semantic Model to support this. Instead, I could easily put this code in the builder:

It’s often an easy reflex to put this kind of logic in the builder, but I urge you not to fall for it. If I put the logic in the Semantic Model, it will be able to make a much better use of the information, since it knows what it’s doing. For example, this allows the Semantic Model to generate code for this validation should you want to embed Javascript in a form. But even without a need like this, my preference is to put smarts in the Semantic Model as much as possible. It isn’t any more work than putting it in the builder, but it keeps the knowledge of the rules where it’s most useful.
The string argument is all very well, but it does have disadvantages, particularly in an environment like C# with static typing and good tool support. It would be nicer to capture the property name with a mechanism that has its place within C#, so we can use autocompletion and static checking.
Fortunately, this can be done in C# by using lambda expressions. The DSL script for a not-null check looks like this:
MustHave(p => p.Nationality);
Again, I implement it in the model, with a simple call from the builder.

I’ve used an expression of the lambda here, rather than just the lambda. This is so that I can print out the text of the code in the error message when the validation fails.
50.4 Eligibility Rules: extending the club membership (C#)
The previous example showed validation rules for the input form for our fictional club. This example now looks at eligibility rules, and gets a little more involved as it includes some forward chaining. The top-level rule says that a candidate is considered for interview if he (and for a club like this it must be a “he”) is of good stock and a productive member of society.

As with the previous example, I’m using an internal DSL with Object Scoping using a superclass, although I’ll describe the details of the parsing later. There are various rules for determining good stock and what it means to be a productive member of society. Two ways to be of good stock are to have your father as a member or to be militarily accomplished.

These rules illustrate an important property of a Production Rule System—the various rules are open-ended, in that I can easily add new rules that say what it means to be of good stock. I can add these rules without altering the rules that are already in place. The downside is that there’s no single spot in the rule base text where I can be sure of finding all the conditions. One way to deal with this is to have a tool capable of finding all the rules that have a consequence of calling MarkOfGoodStock.
The other leg of what makes someone eligible for an interview is the issue of being a productive member of society, which is typical English refined double-speak for saying how much you earn.

A club like this naturally prefers Englishmen, but will take others providing they are sufficiently well heeled.
Looking at the patterns in use here, we see that the list of rules is defined using Function Sequence. The details for each rule use Method Chaining for the When and Then clauses, and Nested Closure for capturing the contents of the condition and action for each rule.
50.4.1 The Model
The model for eligibility is similar to the validation one, but a little more complicated in order to handle the different consequences and the forward chaining. The first part is the data structure used to report the results of the logic—this is an application.

Like the Person earlier on, it’s mostly a simple data class, but it does have a somewhat unusual structure. All the properties are Booleans that start false and can only be changed to true. This enforces some structure in the rules system to avoid undetected contradictions.
Each eligibility rule takes a pair of closures, one for the condition and another for consequence, with a textual description.

I can load eligibility rules into a rule set.
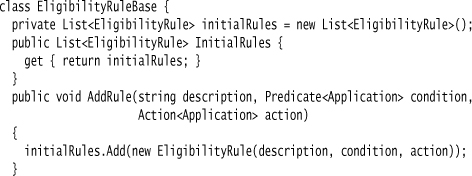
Running the engine is a bit more involved due to the forward chaining. The basic cycle is to check the rules, place those that can be activated onto the agenda, fire the rules on the agenda, and then check to see if more rules can be activated.

I use some further data structures to keep track of the running of the rules.

I copy the rules from the rule base into a list of available rules. When a rule is activated, I remove it from that list (so it can’t be activated again) and put it on the agenda.

I trap null references in CanActivate, just treating them as failures to activate. This allows me to write a conditional expression like anApplication.Candidate. Father.IsMember without having to do any null checking when I write the rule—moving that responsibility to the model.
When I fire a rule, I remove it from the agenda and put it on a log of fired rules. Later I can use the log to provide a trace for diagnostic purposes.

50.4.2 The Parser
As I said earlier, I’m using a similar structure for the eligibility rule builder as I did for the validation rules—with Object Scoping using a superclass.

I define a rule as a Function Sequence of calls to Rule.
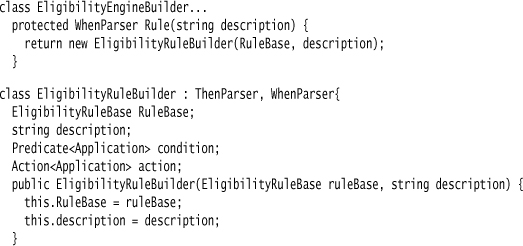
I use Method Chaining on a child rule builder with progressive interfaces to capture the rest of the rule. The first clause is When.
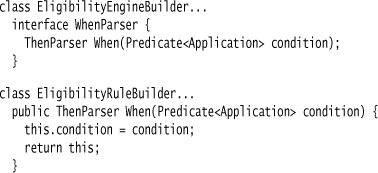
It is followed by Then.
