
Chapter 57. Generation Gap
Separate generated code from non-generated code by inheritance.
One of the difficulties of code generation is that generated code and handwritten code need to be treated differently. Generated code should never be edited by hand, otherwise you can’t safely regenerate it.
Generation Gap is about keeping the generated and handwritten parts separate by putting them in different classes linked by inheritance.
This pattern was first described by the late John Vlissides. In his formulation, the handwritten class was a subclass of the generated class. My description is a little different, based on the use I’ve seen; I really wish I were able to talk it through with him.
57.1 How It Works
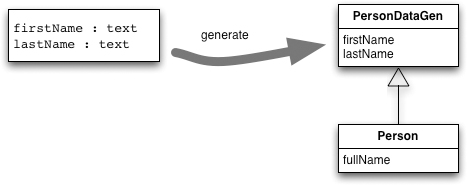
The basic form of Generation Gap involves generating a superclass, which Vlissides refers to as the core class, and hand-coding a subclass. This way you can always override any aspect of the generated code that you like in the subclass.
The handwritten code can easily call any generated features, and the generated code can call hand-coded features by using abstract methods—which the compiler can check are implemented by the subclass—or hook methods which are only overridden when needed.
When you refer to these classes from outside, you always refer to the handwritten concrete class. The generated class is effectively ignored by the rest of the code.
A common variation I’ve seen is to add a third class, a handwritten class that is a superclass of the generated class. This is done to pull out any logic of the generated class that doesn’t depend on the variations triggered by the code generation. Instead of generating the nonvarying code, having it in a superclass allows it to be better tracked by tools, particularly IDEs. In general, my suggestion with code generation is to generate as little code as possible. This is because any generated code is more awkward to edit than handwritten code. Whenever you change generated code, you need to rerun the code generation system. Refactoring capabilities of modern IDEs won’t work properly with generated code.
So, potentially you end up with three classes in an inheritance structure:
• Handwritten base class contains logic that doesn’t vary based on the parameters to code generation.
• Generated class contains logic that can be generated automatically from the generation parameters.
• Handwritten concrete class contains logic that can’t be generated and relies on generated features. This class is the only one that should be mentioned by other code.
You don’t always need all three of these classes. If you don’t have any unvarying logic, you don’t need the handwritten base class. Similarly, if you never need to override the generated code, you can skip the handwritten concrete class. Thus another reasonable variation of Generation Gap is a handwritten superclass and a generated subclass.
Often, you find more complex structures of generated and handwritten classes, related by both inheritance and general calling use. The interplay of code generation and handwriting does lead to a more complicated class structure—this is the price you pay for the convenience of code generation.
A wrinkle that pops up with Generation Gap is the question of what to do when you have handwritten concrete classes some of the time, but not all of the time. In this case, you have to decide what to do for those classes that don’t have a handwritten class. You could make the generated class the named class used by calling code, but that causes a lot of confusion over naming and usage. As a result, I prefer to always create a concrete class, leaving it empty if it has nothing to override.
This still leaves a question—should the programmer create these empty classes by hand, or should the code generation system create them? If there’s only a few and they change rarely, then it’s fine to leave it to a programmer. However, if you have a lot of them and they change frequently, then it’s good to tweak the code generation system to check if there’s an existing concrete class and generate an empty one if not.
57.2 When to Use It
Generation Gap is a very effective technique that allows you to create one logical class split into separate files to keep your generated code separate. You do need a language with inheritance to pull it off. Using inheritance means that any members that can be overridden need to have sufficiently relaxed access controls to make them visible to subclasses—that is, not private in Java or C#’s schemes.
If your language allows you to put code for one class in multiple files, such as C#’s partial classes or Ruby’s open classes, then this is an alternative to Generation Gap. The advantage of partial class files is that it allows you to separate generated and handwritten code without using inheritance—everything is in one class. A downside of C#’s partial classes is that while it’s good for adding features to generated classes, it doesn’t give you a mechanism to override features. Ruby’s open classes do handle this by evaluating the handwritten code after the generated code—which allows you to replace a generated method with a handwritten one.
The common early alternative to Generation Gap was generating code into a marked area of a file between comments that said something like code gen start and code gen end. The trouble with this was that it was confusing, leading to people modifying the generated code and awkward source control diffs. Keeping generated code in separate files is almost always a better idea if you can find a way to do it.
Although Generation Gap is a nice approach, it isn’t the only way to keep generated code separate from handwritten code. Often, it works well just to put the two in separate classes with calls between them. Collaborating classes are a simpler mechanism to use and understand, so in general I prefer them. I am only pushed to Generation Gap when the call interaction becomes more complicated—for example, when there is a default behavior in the generated class that I want to override for special cases.
57.3 Generating Classes from a Data Schema (Java and a Little Ruby)
A common topic for code generation is generating the data definitions for classes based on some form of data schema. If you are writing a Row Data Gateway [Fowler PoEAA] to access a database, you might generate much of this class from the database schema itself.
I’m feeling too lazy to mess around with SQL or XML schemata today, so I’ll pick something simpler. Let’s assume I’m reading simple CSV files, so simple that they don’t even do any quotes and escaping. For each file, I have a simple schema file to define the filenames and the data type for each field. So I have a schema for people:
firstName : text
lastName : text
empID : int
and some sample data:
martin, fowler, 222
neal, ford, 718
rebecca, parsons, 20
From this, I want to generate a Java DTO [Fowler PoEAA] with the right type for each field in the schema, getters and setters for each field, as well as the ability to run some validations.
When generating code is in a compiled language like Java, the build process can often get in the way. If I write my code generator in Java itself, I have to compile my code generator separately from compiling the rest of my code. This makes for a messy build process, particularly when working with an IDE. An alternative approach is to use a scripting language for code generation; then I only have to run a script to generate code. This simplifies the build process at the cost of introducing another language. Of course my view is that you should always have a scripting language at hand anyway, since there’s always a need to automate tasks with scripts. In this case, I use Ruby, since that’s my scripting language of choice. I’ll use Templated Generation with ERB which is Ruby’s built-in templating system.
The Semantic Model for the schema is very simple. The schema is a collection of fields with a name and type for each field.

Parsing the schema file is pretty easy—I just read each line, split it into tokens around the colon, and create the field objects. Since this parsing logic is so simple, I don’t break the parsing code away from the Semantic Model objects themselves.

Once I’ve populated the Semantic Model, I can use it to generate the data classes. I’ll start with the field definitions and methods that access them. I want to generate code like this:

protected void checkEmpID(Notification note) {};
I set up the generated class to be a subclass of the nonvarying hand-coded class. I don’t use this class for the basic definition of the fields, but I’ll show some usage shortly.
To do this, I make a template.

The template refers to a number of methods on the Semantic Model that assist with the code generation.

Generating fields like this allows me to override the getter and setter methods, or add new methods to the class. In this case, I can return capitalized names and add the ability to form a full name.

Apart from data access, I also want to have validation. For the moment, I’ll do this by adding code to the hand-coded subtype. However, I want to ensure that all the validation methods can easily be run together. This I can do by adding code to the base handwritten class.
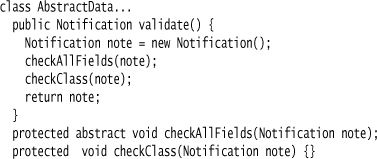
protected abstract void checkAllFields(Notification note);
protected void checkClass(Notification note) {}
The validate method here calls an abstract method to check all the fields individually and an empty hook method for validation checks that involve multiple fields. The idea is that I can override the hook method in my concrete handwritten class. The generated class will implement the abstract method using the same information used to generate the fields.
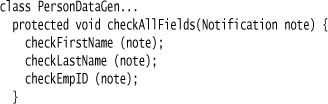
As you may have noticed in the earlier code example, these check methods are themselves just empty hook methods. I can override them to add some validation behavior.
