
Chapter 3. System Dynamics
In Chapter 2 we discussed how a feedback loop can drive the output of a system to a desired value. We also described the typical challenges associated with this scheme: making sure that the overall system is stable (meaning that it does, in fact, converge to the preset value) and performs well (so that it converges quickly). However, this is not the whole story.
Lags and Delays
The aspect that we have neglected so far is that many systems do not respond immediately to a control input; instead, they respond with some form of lag or delay. In addition, many systems exhibit even more complicated behavior when stimulated. These factors need to be taken into account when designing a control loop.
Let’s consider a few examples (see Figure 3-1 and Figure 3-2).
- A heated vessel:
(Basically, this describes a pot on the stove.) As the heat is turned on, the temperature in the vessel does not immediately jump to its final value; rather, it shows a gradual response. Likewise, when the external heat supply is later shut off, the temperature in the vessel does not drop immediately but instead slowly decays to the ambient temperature. The temperature in the vessel (which is the tracked quantity or “output”) follows the temperature (which is the configurable quantity or “input”), but it lags behind and shows a more “rounded” behavior. This form of rounded, partial response is called a lag.
- A tank fed by a pipe:
Imagine a long hose or pipe that feeds into a storage tank. When the valve at the beginning of the pipe is opened, the level in the tank (which is the tracked metric in this case) does not change. Only after the liquid has traveled the entire distance of the pipeline and begins to flow into the tank does the tank’s fill level begin to rise. This type of behavior is called a delay. In contrast to a lag, which consists of an immediate but partial response, a delay is characterized by an initial time interval during which there is no response at all.
- A mass on a spring:
Consider a mass supported by a spring. If we give the other end of the spring a sudden jerk, the mass on the spring will begin to oscillate. This system exhibits a lag, because there is an immediate but gradual response. In addition, however, this system also displays complicated behavior on its own; it has nontrivial internal dynamics.
- A fishing rod:
When a flexible fishing rod is yanked back, its tip initially moves forward. In other words, for this system the first response to an external stimulus is in the direction opposite to the stimulus. Such systems occasionally do occur in practice and obviously pose particular challenges for any controller. They are known as non-minimum phase systems (for reasons involving the theoretical description of such behavior), but a more descriptive name would be “inverse response” systems.
Of course, all of these behaviors can also occur in combination.
Forced Response and Free Response
The examples discussed so far also demonstrate the difference between forced and free (or internal) response. In the case of the heated pot, the steady increase in temperature while the stove is turned on is the response to the external disturbance (namely, the applied heat). In contrast, the exponential cooling off is subject only to the system’s internal structure (because there is no input being applied from the outside). The initial displacement of the mass on the spring is due to the externally applied force on the free end of the spring; the subsequent oscillation is the free response of the spring–mass system itself. The storage tank does not have any free response: its fill level does not change unless liquid is flowing in. The dynamic response of the fishing rod is extremely complicated and includes both forced and free components.
Transient Response and Steady-State Response
The response of a system to an external disturbance often consists of both a transient component, which disappears over time, and a steady-state component. These components are well illustrated by the spring–mass system: the initial oscillations die away in time, so they are transient. But the overall displacement of the mass, which is the result of the change in position of the spring’s free end, persists in the steady state.

Control actions are often applied to bring about a change in the steady-state output. (If you turn up the heat, you want the room to be warmer and to stay that way.) From this perspective, transient responses are viewed mainly as a nuisance: unwanted accompaniments of an applied change. Hence an important measure for the performance of a control system is the time it takes for all transient components of the response to have disappeared. Usually, handling the transient response in a control system involves an engineering trade-off: systems in which transients are strongly damped (so that they disappear quickly) will respond more slowly to control inputs than do systems in which transient behavior is suppressed less strongly.

Dynamics in the Physical World and in the Virtual World
All objects in the physical world exhibit some form of lag or delay, and most mechanical or electrical systems will also have a tendency to oscillate.
The reason for the lags or delays is that the world is (to use the proper mathematical term) continuous: An object that is in some place now cannot be at some totally different place a moment later. The object has to move, continuously, from its initial to its final position. It can’t move infinitely quickly, either. Moreover, to move a physical object very quickly requires large amounts of force, energy, and power (in the physical sense), which may not be available or may even be impossible to supply. (Accelerating a car from 0 to 100 km/h in 5 seconds takes a large engine, to do so in 0.5 seconds would take a significantly larger engine, and a very different mode of propulsion, too.) The amount by which objects in the physical world can move (or change their state in any other way) is limited by the laws of nature. These laws rule supreme: No amount of technical trickery can circumvent them.
For computer systems, however, these limitations do not necessarily apply in quite this way! A computer program can arbitrarily change its internal state. If I want to adjust the cache size from 10 items to 10 billion items, there is nothing to stop me—the next time through the loop, the cache will have the new size. (The cache size may be limited by the amount of memory available, but that is not a fundamental limitation—you can always buy some more.) In particular, computer programs do not exhibit the partial response that is typical of continuous systems. You will typically get the entire response at once. If you asked for a 100-item cache, you will get the entire lot the next time through the loop—not one item now, five more the next time around, another 20 coming later, and so on. In other words, computer programs typically do not exhibit lags. They do, however, exhibit delays; these are referred to as “latency” in computer terminology. If you are asking for 20 additional server instances in your cloud data center, it will take a few minutes to spin them up. During that time, they are not available to handle requests—not even partially. But once online, they are immediately fully operational. Figure 3-3 shows schematically the typical response characteristic of a computer program. Compared to the “smooth” behavior of physical objects displayed in Figure 3-1 and Figure 3-2, the dynamics of computer applications tend to be discontinuous and “hard.”

The considerations of the preceding paragraph apply to standalone computer applications. For computer systems, which consist of multiple computers (or computer programs) communicating with each other and perhaps with the rest of the world (including human users), things are not quite as clear-cut. For instance, recall our example of the item cache. We can adjust the size of the cache from one iteration to the next, and by an arbitrary amount. But it does not follow that the hit rate (the tracked quantity or “output” for this system) will respond just as quickly. To the contrary, the hit rate will show a relatively smooth, lag-type response. The reason is that it takes time for the cache to load, which slows the response down. Moreover, the hit rate itself is necessarily calculated as some form of trailing average over recent requests, so some time must elapse before the new cache size makes itself felt. In the case of the additional server instances being brought up in the data center, we may find that not all the requested instances come online at precisely the same moment but instead one after another. This also will tend to “round out” the observed response.
Another case of computer systems exhibiting nontrivial dynamics consists of systems that already include a “controller” (or control algorithm) of some form. For example, it is common practice to double the size of a buffer whenever one runs out of space. Similar strategies can be found, for instance, in network protocols, for the purpose of maximizing throughput without causing congestion. In these and similar situations, the behavior of the computer system is constrained by its own internal control algorithms and will not change in arbitrary ways.
Dynamics and Memory
We saw that objects in the physical world cannot suddenly change their state (their position, temperature, whatever): Changes must occur continuously. This is another way of saying that the state of such an object is not independent of its past. These objects have a “memory” of their past, and it is this memory that leads to nontrivial dynamics. To make this point more concrete: The pot on the stove does not just “forget” its current temperature when the stove is turned on; the pot “remembers” its original temperature and therefore takes time to adjust.
For objects in the physical world, different modes of energy storage form the mechanism for the kind of memory that leads to “lags”; in contrast “delays” are generally due to transport phenomena.
For computer systems, we need to evaluate whether or not they do possess a “memory” (in the sense discussed here). The cache size does not have a memory: It can change immediately and by an arbitrary amount. The cache’s hit rate, however, does retain knowledge of its past—not only through the cache loading but also through the averaging process implicit in the calculation of the hit rate.
All mechanisms that explicitly retain knowledge of their past are likely to give rise to lags. With computer systems, words such as “buffer,” “cache,” and “queue” serve as indicators for nonimmediate responses. Another source of “memory” is any form of “time averaging,” “filtering,” or “smoothing.” All of these operations involve the current value of some quantity as well as past values, thus leading to nontrivial dynamical behavior. Lags tend to be collective phenomena.
Delays (or “latency”) tend to result from transport issues (as in the physical world—think of network traffic) or to internal processes of the system that are not observable in the monitored metrics. Examples include the boot-up process of newly commissioned server instances, the processing time of database requests, and also the delays that individual events might experience while stuck in some form of opaque queue. Delays can occur both for individual systems and for events.
The Importance of Lags and Delays for Feedback Loops
The reason we spend so much time discussing these topics is that lags and delays make it much more difficult to design a control system that is both stable and performant. Take the heated vessel: Initially, we want to raise its temperature and so we apply some heat. When we check the output a short while later, we find that the temperature has barely moved (because it’s lagging behind). If we now increase the heat input, then we will end up overheating the vessel. To avoid this outcome, we must take the presence (and length) of the lag into account.
Moreover, unless we are careful we might find ourselves applying corrective action at precisely the wrong moment: Applying a control action intended to reduce the output precisely when the output has already begun to diminish (but before this is apparent in the actual system output). If we reach this scenario, then the closed-loop system undergoes sustained oscillations. (Toward the end of this chapter, you will find a brief computer exercise that demonstrates how the delay of even a single step can lead to precisely this situation.)
Avoiding Delays
The whole feedback principle is based on the idea of applying corrective actions in response to deviations of the output from the reference value. This scheme works better the more quickly any deviation is detected: If we detect a deviation early, before it has had a chance to become large, then the corrective action can be small. This is good not only because it is obviously desirable to keep the tracking error small (which is, after all, the whole point of the exercise!) but also because small control actions are more likely to lead to stable behavior. Furthermore, there is often a “cost” associated with control actions, making large movements more expensive—in terms of wear and tear, for instance. (This is not always true, however: sometimes there is a fixed cost associated with making a control action, independent of its size. When adding server instances, for example, there may be a fixed commissioning fee in addition to the cost for CPU time used. In such cases, we naturally want to limit the number of control actions. Nevertheless, early detection of deviations is still relevant. It is up to the controller to decide how to react.)
For this reason, we should make an effort to ensure timely observation of all relevant quantities. For physical systems, this means using quick-acting sensors and placing them close to the action. Old-style thermometers, for instance, have their own lags (they are nothing but “heated vessels” as discussed earlier) and transport delays (if they are placed far away from the heat source).
Because computer systems manage “logical” signals, there is often greater freedom in the choice of quantities that we use as monitoring or “output” signals than for systems in the physical world. To quantify the performance of a server farm, we can use the number of requests pending, the average (or maximum) age of all requests, the number (or fraction) of dropped requests, the arrival rate of incoming request, the response time, and several other metrics. We should make the best use of this freedom and make an effort to identify and use those output variables that respond the most quickly to changes in process input. In general, metrics that are calculated as averages or other summaries will tend to respond more slowly than quantities based on individual observations; the same is true for quantities that have been “smoothed” to avoid noise. In fact, it is often better to use a noisy signal directly than to run it through a smoothing filter: The slowdown incurred through the filtering outweighs the benefits of having a smoother signal. We will discuss some relevant choices in Chapter 5.
There is usually little that can be done about lags and delays inherent in the dynamics of the controlled system—simply because the system is not open to modification. (But don’t rule this possibility out, especially if the “system” is merely a computer program rather than, say, a chemical plant.) We should, however, make every effort to avoid delays in the architecture of the control loop. Chapter 15 and Chapter 16 will provide some examples.
Theory and Practice
There exists a very well-developed, beautiful, and rather deep theory to describe the dynamic behavior of feedback loops, which we will sketch in Part IV. An essential ingredient of this theory is knowledge of the dynamic behavior of the controlled system. If we can describe how the controlled system behaves by itself, then the theory helps us understand how it will behave as part of a feedback loop. In particular, the theory is useful for understanding and calculating the three essential properties of a feedback system (stability, performance, and accuracy) even in the presence of lags and delays.
The theory does require a reasonably accurate description of the dynamics of the system that we wish to control. For many systems in the physical world, such descriptions are available in the form of differential equations. In particular, simple equations describing mechanical, electrical, and thermal systems are well known (the so-called laws of nature), and the entire theory of feedback systems was really conceived with them in mind.
For computer systems, this is not the case. There are no laws, outside the program itself, that govern the behavior of a computer program. For entire computer systems there may be applicable laws, but they are neither simple nor universal; furthermore, these laws are not known with anything like the degree of certainty that applies to, say, a mechanical assembly. For instance, one can (at least in principle) use methods from the theory of stochastic processes to work out how long it will take for a cache to repopulate after it has been resized. But such results are difficult to obtain, are likely to be only approximate, and in any case depend critically on the nature of the traffic—which itself is probably not known precisely.
This does not mean that feedback methods are not applicable to computer systems—they are! But it does mean that the existing theory is less easily applied and provides less help and insight than one might wish. Developing an equivalent body of theoretical understanding for computer systems and their dynamics is a research job for the future.
Code to Play With
To understand how even a simple delay can give rise to nontrivial behavior when encountered in a feedback architecture, let’s consider a system that simply replicates the input from the previous time step to its output. We close the feedback loop as in Figure 2-1 and use a controller, which merely multiplies its input by some constant k.
The brief listing that follows shows a program that can be used to experiment with this
closed-loop system. The program reads both the setpoint r
and the controller gain k from the command line. The
iteration itself is simple: The tracking error and the controller output are calculated as in
Chapter 2, but the current output y is set to the value of the controller output from the
previous time step. Figure 3-4 shows the time evolution of the output
y for two different values of the controller gain
k.
import sys
r = float(sys.argv[1]) # Reference or "setpoint"
k = float(sys.argv[2]) # Controller gain
u = 0 # "Previous" output
for _ in range( 200 ):
y = u # One-step delay: previous output
e = r - y # Tracking error
u = k*e # Controller output
print r, e, 0, u, y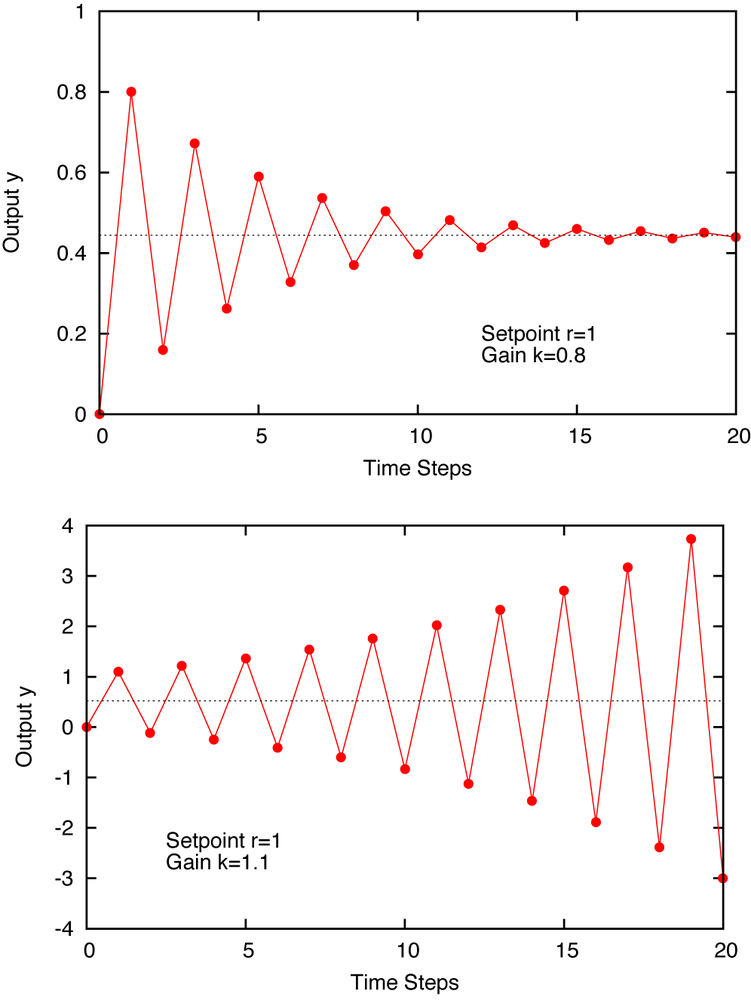
Although the setpoint is constant, the process output oscillates. Moreover, for values of
the controller gain k greater than 1, the amplitude of the
oscillation grows without bounds: The system diverges.
If you look closely, you will also find that the value to which the system converges (if it does converge) is not equal to the desired setpoint. (You might want to base control actions on the cumulative error, as in Chapter 2. Does this improve the behavior?)