
In this recipe, we will use the start and end of word operators along with the subgroup register placeholders in order to write a program that will remove adjacent duplicate words from a text string. For example, from the text 'this this is is a repeated text text 11 11', the duplication of words will be removed and the new text 'this is a repeated text 11' is given as the output.
In order to create a repeated word removal program, proceed as follows:
- Declare the
textstreamstring. Then assign some text to it that has repeated words in it. - A
replace all occurrencesstatement is then written with the regular expression(<w+>) 1. The replacement key is'$1'. - The
ifstatement is then used for checking the return code. Forsy-subrchaving the value0, the messageNumber is Validis displayed.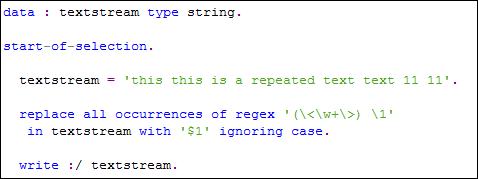
The regex used in this recipe is different from that used in the previous one. Since we require searching of duplicate words rather than single characters, we will use the start and end word operators. We used w+ so that all words comprising of alphanumeric characters will be found searched and then replaced. In order to find out repeated adjacent words (set of characters surrounded by blank space) we used parenthesis for the first subgroup and then the back-referencing operator 1 to find out repetition. It is also necessary to include a space between the subgroup in brackets and the 1 (since we are dealing with words).
The replace statement uses the placeholder $1, referring to the first subgroup register. In other words, via the replace statement, we are actually telling the system to first find the occurrence of two adjacent words, and then replace this found duplicate with a single word that is the one stored in the first subgroup register (thus removing duplicates).
For the example shown in the code, the string outputted after removal of adjacent duplicates is shown in the following screenshot: