
In this recipe, we will see how an HTML code may be read and interpreted using regular expressions. We will create a program that will read an HTML stream in a string and will display the tag names along with the content of the tags. The FIND and replace statements are used together with a do loop. (This recipe will focus on reading tags beginning with <tag> and ending with < ag>).
For creating a program for interpreting HTML code, follow the steps shown in the following steps:
- Declare three strings by the name
htmlstream,tagcontents, andtagname. - We then assign a suitable HTML code to the
htmlstreamvariable. - Within a do loop, a
FIND REGEXstatement is added that finds tag names and their contents. The regex used in this case for matching an HTML tag is'<(uw*)[^>]*>(.*)</1>'. - Once a tag is processed, a
replace all occurrencesstatement is used for replacing the tag with'$$$'. - The tag name and tag contents are printed.
- Once all the tags are processed, the
exitstatement is executed.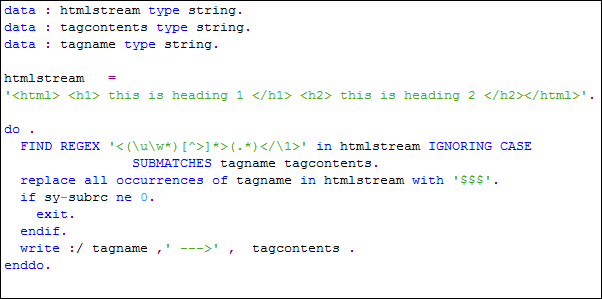
We have used ignoring case since the tag names may start with upper or lowercase such as H1 or h1. The regular expression searches for tags starting with a <, then followed by a single alphabet (denoted in regex by u), followed by zero or more alphanumeric characters. After this, an optional substring (comprising of all characters except for a > may be found, followed by a > character. This will match HTML tag names such as H1, H2, HTML, or html. The tag name without the special characters < and > is assigned to a subgroup that is then available in the submatch variable tagname. The start and end of the tag is checked using the back-referencing operator 1. Note that in this case, the forward slash / is part of the HTML code denoting the end of the tag. The content of a particular tag is read into the submatch variable tagcontents.
The find statement finds all the tags. Once a tag is processed, we replace the tag name as $$$ in order to avoid it to be found by the find statement another time. On the next do loop pass, the next tag is matched and contents are read.
Using a WRITE statement, all the tag names and tag contents are printed on screen. The output is shown in the following screenshot:

Once all the tags are processed, the sy-subrc condition of being not equal to zero is met and the loop is exited.
- http://help.sap.com/saphelp_erp2005/helpdata/en/42/9d6ceabb211d73e10000000a1553f6/frameset.htm
- http://help.sap.com/abapdocu_702/en/abenregex_search.htm
- http://www.sdn.sap.com/irj/scn/go/portal/prtroot/docs/library/uuid/03a52be5-0901-0010-9da4-e9d5f8c5ce1c?QuickLink=index&overridelayout=true
- http://help.sap.com/abapdocu_702/en/abenregex_syntax_operators.htm
- http://www.sdn.sap.com/irj/scn/go/portal/prtroot/docs/library/uuid/866072ca-0b01-0010-54b1-9c02a45ba8aa?QuickLink=index&overridelayout=true