
World Wide Web
In 1969, the U.S. Department of Defense (DoD) issued contracts to develop a decentralized and fault-tolerant computer network called ARPANET. ARPANET was intended to be a platform to support DoD research and other academic research of interest to the DoD. As ARPANET grew and became more functional, additional educational institutions and large corporations joined the network. Throughout the 1980s the new global network grew in popularity, and both individuals and organizations of all sizes began to realize the benefits of a network with so many varied available resources. By the later 1980s, commercial service providers were offering individual access to the network, now called the Internet, for subscription fees.
Although the global reach of the Internet made it easy to exchange messages and files, it wasn’t easy to identify online resources. There were early tools and protocols available such as gopher, but those were limited in the resources one was able to find. Prior to 1990, the Internet was mainly made up of FTP sites, bulletin boards, and a cool way to exchange email.
In 1989, everything changed.
From the Internet to the Web: How the World Wide Web Works
In 1989, an English computer scientist, Tim Berners-Lee, proposed a novel way to connect resources scattered across the Internet. His proposal was to develop a protocol that allowed resources to be “linked” to documents and other resources. His vision was that all resources would someday be linked together into a “World Wide Web,” now commonly called “the web.” In 1991, he released the first program to implement his new protocol, called a web browser.
A web browser downloads and interprets webpages that are formatted in the common language of the web, Hypertext Markup Language (HTML). HTML documents can contain text, media, and links to external resources on the web, called hyperlinks. Hyperlinks, along with the ability to locate remote resources using a Uniform Resource Locator (URL), make the web a true global repository of resources. Although creating a browser program that can “follow” links to navigate to remote resources may sound simple, it transformed the way we all communicate and do business. With very little fanfare, the web was born.
HTTP: The Web’s Workhorse
The way the web operates is pretty simple: When a user wants to interact with a webpage, that user enters a URL in the web browser’s address field. The web browser builds an HTTP message and sends it to the web server (monitoring port 80 by default) on the specified server. The web server looks up the requested document and returns it to the web browser, and the web browser carries out any formatting commands to “render” (or draw) the page. Each HTTP message starts with a request to the server and results in a response from the server. Once the web browser receives the HTTP response from the web server, the cycle is complete. Any further communication would be a new HTTP message sequence. FIGURE 6-3 shows an HTTP request and response.
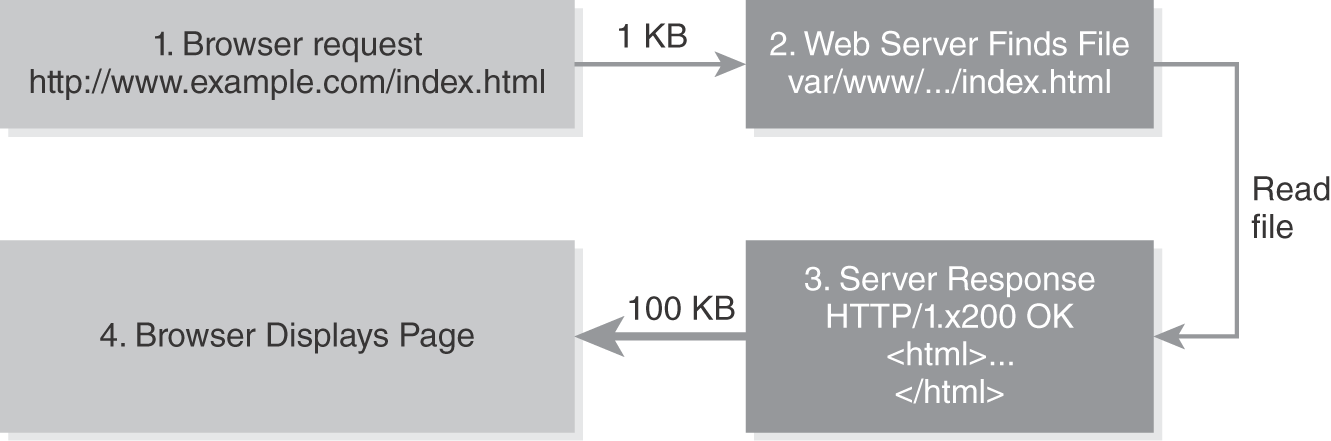
FIGURE 6-3 HTTP request and response.
HTTP Request
When a web browser initiates a connection, it sends an HTTP request to a web server. The URL consists of several parts.
The web browser constructs an HTTP message and sends it to the host from the URL. Unless an alternate port is specified, HTTP requests are directed to port 80 on the destination host computer. HTTP/1.1 defines nine methods, often called verbs, to tell the web server how to interpret the HTTP message. HTTP request methods indicate whether the request and/or any response has a body (i.e., more data), and how to handle the message. TABLE 6-4 shows the nine request methods in the HTTP/1.1 specification.
| METHOD | DESCRIPTION |
|---|---|
| GET | Most common initial request to retrieve and render a resource (webpage) |
| HEAD | Same as GET, without any data in the response body |
| POST | Method to submit data to a resource through a web server, often used to trigger server-side functionality to process input data |
| PUT | Similar to POST, but submits data to overwrite the specified resource |
| DELETE | Deletes the specified resource |
| TRACE | Generates an echo of the received request; useful in debugging and auditing |
| OPTIONS | Returns the HTTP methods that the specified web server supports for a specific URL |
| CONNECT | Translates a connection request to a TCP/IP tunnel; generally used to increase the security of a connection to use HTTPS |
| PATCH | Applies partial modifications to the specified resource |
 NOTE
NOTE
Many of today’s mobile and distributed apps use a technique called Representational State Transfer (REST), which issues remote service calls using HTTP and the web. Part of the REST technique is to map server-side functions to URLs and specific HTTP request methods. REST makes it easy for a single URL to resolve to nine different functions, just by using one of the eight different HTTP methods.
HTTP Response
An HTTP response contains up to three parts: a status code, response header fields, and an optional message body. The most important part is the status code, which tells the web browser what happened. If you’ve ever seen the infamous 404 status code, that simply means the resource you’re looking for can’t be found (or just isn’t available). There are lots of other status codes. The one you’re normally looking for is 200, which means OK. (Actually, any status code in the range of 200–299 means success.) Any time you get errors or unexpected behavior when communicating with a web server, check the status code to see what’s going on.
The rest of the HTTP response depends on what type of resource you requested. If you are invoking a web service using REST, your header fields (or the body) could contain return values. The status code helps your web browser determine how best to handle the returned data.
Although HTTP is a simple protocol, it has shown its flexibility and ability to support an ever-expanding range of online applications.