
Application Architectures
In the early days of computing, users ran an individual program on large, expensive mainframe computers to accomplish a specific task—general purpose applications didn’t exist. A program’s instructions were either manually entered via a computer console or stored on cards with holes punched in them. These punch cards made early programming life easier by relieving computer operators from having to enter CPU instructions one at a time. Early computer programs had specific uses and almost no recognizable user interface. The computer operator would load a program’s instructions along with its initial data, and then the program would run and hopefully produce some usable output.
As the value of computers began to be appreciated more and more, users began to find new uses and expect more from computers. Programs became more complex and started to use interactive input from users. Instead of loading all the data at the beginning, users could provide some data as the program ran. Early user interfaces began to emerge but were generally expressed as a collection of text-based menus. (Graphics and mice were a few years off at this point.) Growing interest in computers resulted in increasing complexity of computer programs. Execution time (the CPU access time required to run any program) became scarce and expensive.
At the same time demand for computing sophistication was increasing, computing hardware was becoming more available and affordable. Application architects began to explore ways to spread the computing load across more devices and computers. They saw that distributing the computing load made applications more functional, and reserved the large expensive computers for the tasks that required heavy processing. And thus, the drive toward distributed computing began.
Architecture Types and Examples
Computer architects explored different types of architectures to get the distribution mix just right. You can see examples of most architectures still in use today. The main application architectures are host-based, client-based, client/server, cloud computing/N-tier, and peer-to-peer (P2P). You can classify an application architecture by examining where core processing functions occur. There are four main processing functions (and questions to determine where each function is located):
- Data storage—Where the application data is stored. Is your data stored on a central server or copied to each client (or perhaps somewhere in between)?
- Data access—How do clients access application data? Is your data stored in files or in a repository, such as a database, that requires a database management system (DBMS) to control access to the data? If your application uses a DBMS, where is it located?
- Processing logic—Also commonly referred to as business logic, this is the software that carries out most of the computations on your application data. Processing logic is normally identified by any code that handles data that is stored in your repository. Where should functions like daily sales summaries be run?
- User interface—Although some functions may overlap with processing logic, user interface functions generally focus on getting data from, and presenting data to, end users. End users don’t have to be humans—output files, printers, and remote processes can all be classified as end users. (Data consumers is really a better term.) Does a function interact with an end user? If so, it is a user interface function.
TABLE 6-1 shows how each application architecture is defined by where each processing function is located. Each application architecture places core processing functions in different places with the goal of distributing processing and network use.

Let’s briefly look at each architecture.
Host-Based Applications
Software applications all began as host-based architectures. Early computing consisted of a central host with text-based terminals connected to them. Everything ran on the central host. All storage was connected to the central host; the data access software (i.e., DBMS), along with all the processing of user interface logic, ran on the central host. Terminal devices didn’t need any intelligence other than to accept a stream of characters from the host and display them to the user. These early terminals were simple display devices, so they were often called dumb terminals.
Most business software, such as accounting and enterprise resource planning, started as host-based applications. Before the availability of reasonably priced computers and reliable networks, central computers provided the most value for enterprises that could afford them. These computers were almost always closed systems with strict access controls, so securing them was easy compared to today’s requirements.
Client-Based Applications
In the 1980s, computers and networks became affordable and more functional. For the first time it was possible to place a computer on many people’s desks and connect them with a network. Although the fastest networks at the time could only reach speeds of 10 Mbps, that was blazing fast for its day. The availability of so many inexpensive CPUs scattered across an organization led application architects to push applications out to these new clients. The idea at the time was to offload the processing requirement of their overloaded mainframe computers and just use the central hosts to store shared data.
One of the catchphrases of the day was “diskless workstations.” Organizations tried saving money by purchasing computers with no disks and connecting them to the corporate network. The data storage function stayed on the central server, but everything else ran on the client. Although this may sound like a good idea, it wasn’t at all. Those 10 Mbps networks were saturated as soon as just a few computers were connected. Application architects underestimated just how much data is read from, and written to, disks during normal operation. Client-based applications, in the purest sense, didn’t last long.
Client/Server Applications
The next step toward distribution from client-based computing was to push the disk access functionality back up to the central server and allow clients to have local disks. Client/server computing essentially split the data and processing tasks into two main partitions: Servers handle the data while clients handle the processing. Application architects found that the client/server model worked far better than the client-based model. Servers can be optimized to store vast amounts of data and to use their large memory spaces to serve requests for data to large numbers of clients. Client computers could handle all of the processing needs for retrieved data and user interface. Client/server architecture is still a popular architecture for many enterprise-class applications, such as accounting information systems (AISs) and enterprise resource planning (ERP) systems.
Cloud Computing/N-Tier Applications
The most popular application architecture during the 1990s and early 2000s was still client/server; however, it became clear soon after the turn of the century that application demands were exceeding client computing capacity. Specifically, more and more data could be analyzed and incorporated into the application functionality, but clients were having an increasingly harder time fetching and processing the growing amount of data in a reasonable time. Something as simple as an AR Aging report became a process that took longer than it should. (In accounting, the AR Aging report lists all unpaid invoices and groups them into “buckets” depending on how overdue each one is.)
To remedy this performance and network utilization problem, application architects introduced a new infrastructure component, the application server (appServer). An appServer is a program that runs on a central server that handles processing logic. The appServer generally runs on a server in the same data center as the database server. Being co-located with the database server means the appServer can read vast amounts of data from the DBMS using a high-speed network connection and process lots of instructions and data on a high-powered server computer. Once the processing finishes, the appServer sends only the results over the network to the client. Pushing the processing logic up to a new server was originally called a 3-tier architecture, because the client, appServer, and database server each represented a separate tier in the application. The new architecture was so successful, many organizations began adding multiple appServers, leading to the more common term, N-tier architecture. FIGURE 6-2 shows an example of a common N-tier application architecture.
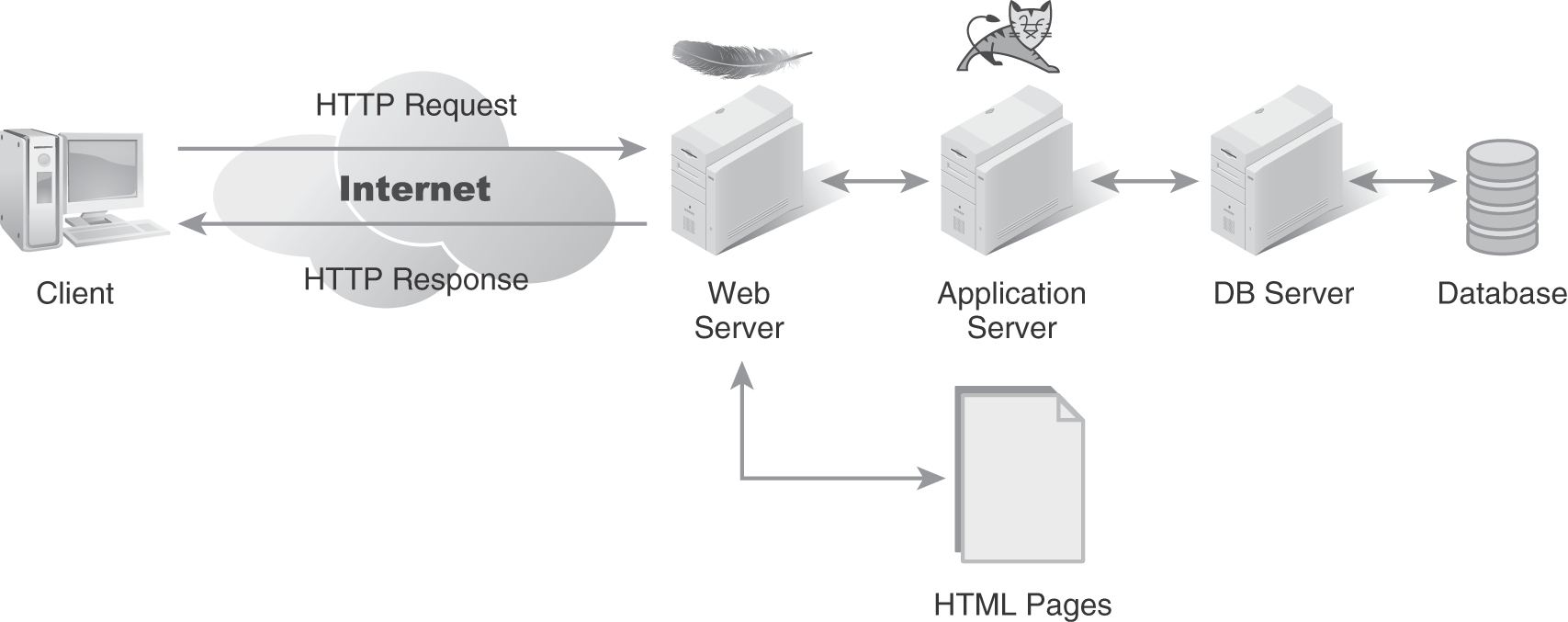
FIGURE 6-2 N-tier application architecture.
This N-tier architecture used to exist only in an in-house data center. Today, cloud computing makes it possible for organizations of any size to lease data center infrastructure and implement an N-tier architecture. In fact, cloud computing takes things a step further through the use of web-based client applications. In a web-based model, end users run browser software to create the user interface. The user interface processing functions are actually split between the client computer or device and the cloud-based web server.
Peer-to-Peer Applications
The last application architecture is the peer-to-peer (P2P) application. In a P2P environment, peers share data and processing with each other. For situations in which contention for data is low, P2P may work well. Clients rely primarily on their local resources and only share what they need to get a task accomplished. P2P applications work best in collaborative environments in which peers trust one another.
However, there is a rapidly emerging use case for untrusted P2P applications—blockchain technology. Blockchain solves many of the issues with traditional P2P application architectures by implementing a decentralized data sharing protocol based on cryptography to maintain integrity. A proper discussion of blockchain technology is beyond the scope of this text, but it is a fascinating topic and one that will affect how we all use networks in the near future.
Features and Benefits of Each Architecture Type
Each application architecture has its own benefits and drawbacks. Each architecture grew out of user demands and requirements to address processing and network use constraints. Understanding how each architecture impacts networks (and infrastructure) can help you make better architectural choices. TABLE 6-2 lists some benefits and drawbacks for each application architecture.
| ARCHITECTURE | BENEFITS | DRAWBACKS |
|---|---|---|
| Host-based |
|
|
| Client-based |
|
|
| Client/server |
|
|
| Cloud computing/N-tier |
|
|
| P2P |
|
|
Aligning Architecture with Business Requirements
With so many application architecture choices, which one is best? There is no “right” answer for all situations. The best choice for any organization is to first understand your business problems. You should never adopt a technical solution and then decide how to apply it to a problem. Always start with the business problem. Then, identify a business solution to the problem, and finally identify a technical solution (if possible). Choosing an application architecture is the final step—identifying a technical solution.
Regardless of what decision you eventually make with respect to an application architecture, always choose the option that will best satisfy the requirements provided to you by the business unit. All technical solutions should support your business. The trendiest looking mobile apps don’t make any money for you if they don’t contribute to your business’ goals. Always align technical choices with business requirements.
 NOTE
NOTE
Suppose your company owns a string of retail clothing stores. Your management has identified a problem with shrinkage of several types of women’s sweaters. (Shrinkage is the situation in which inventory disappears without any explanation. In retail, shrinkage is normally due to shoplifting or insufficient inventory management.) What application architecture would be the best choice to solve this shrinkage problem?
You first have to identify a business solution. One solution may be to relocate the sweaters that are disappearing to a location near the cash register. If that solves the problem, you don’t need a technical solution. Another option would be to add clothing tags and install scanners at the doors. Another solution may be to upgrade your inventory management software to support mobile devices your store personnel can carry around the store with them.
This last option is the one that might require you to make an application architecture choice. In this case, a cloud-based solution might provide the most flexibility and ability to use mobile devices.