
One of the critical mistakes many big data architectures make is trying to handle multiple stages of the data pipeline with one tool. A fleet of servers handling the end-to-end data pipeline, from data storage and transformation to visualization, may be the most straightforward architecture, but it is also the most vulnerable to breakdowns in the pipeline. Such tightly-coupled big data architecture typically does not provide the best possible balance of throughput and cost for your needs.
It is recommended that big data architects decouple the pipeline. There are several advantages to decoupling storage and processing in multiple stages in particular, including increased fault tolerance. For example, if something goes wrong in the second round of processing and the hardware dedicated to that task fails, you won't have to start again from the beginning of the pipeline; your system can resume from the second storage stage. Decoupling your storage from various processing tiers gives you the ability to read and write to multiple data stores.
The following diagram illustrates various tools and processes to consider when designing a big data architecture pipeline:
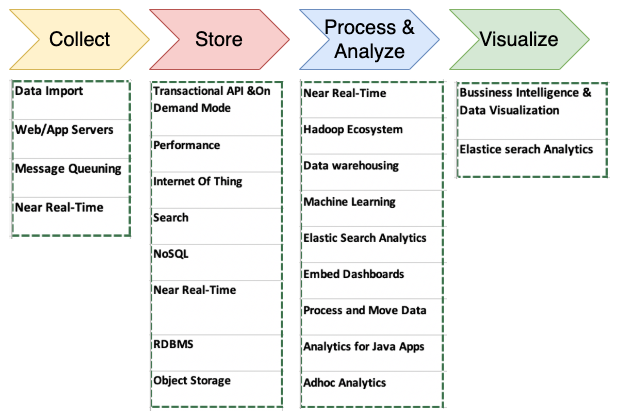
The things you should consider when determining the right tools for your big data architectures include the following:
- The structures of your data
- The maximum acceptable latency
- The minimum acceptable throughput
- The typical access patterns of your system's end users
Your data structure has an impact on both the tools you use to process it and where you store it. The ordering of your data and the size of each object you're storing and retrieving are also essential considerations. The time-to-answer is determined by how your solution weighs latency/throughput and cost.
User access patterns are another important component to consider. Some jobs require the rapid joining of many related tables regularly, and other jobs require daily or less frequent use of stored data. Some jobs require a comparison of data from a wide range of data sources, and other jobs pull data from only one unstructured table. Knowing how your end users will most often use the data will help you determine the breadth and depth of your big data architecture. Let's dive deep into each process and the tools involved in big data architecture.