
Introduction to multitasking
Abstract
Most complex real-time systems require a number of tasks (or programs) to be processed at the same time. For example, consider an extremely simple real-time system that is required to flash an LED at required intervals, and at the same time look for a key input from a keyboard. One solution would be to scan the keyboard in a loop at regular intervals while flashing the LED at the same time. Although this approach may work for a simple example, in most complex real-time systems a multitasking approach should be implemented. The term multitasking means that several tasks are processed in parallel on the same CPU. In a multitasking system, several tasks to run on a single CPU at the same time. Therefore, task switching is done where the tasks share the CPU time. In many applications, tasks cannot run independently of each other and they are expected to cooperate in some way. For example, the execution of a task may depend upon the completion of another task. This chapter describes briefly the various scheduling algorithms used in practice and gives their advantages and disadvantages.
Keywords
7.1. Overview
7.2. Multitasking kernel advantages
- • Without a multitasking kernel, multiple tasks can be executed in a loop, but this approach results in very poorly controlled real-time performance where the execution times of the tasks cannot be controlled.
- • It is possible to code the various tasks as interrupt service routines. This may work in practice, but if the application has many tasks then the number of interrupts grow, making the code less manageable.
- • A multitasking kernel allows new tasks to be added or some of the existing tasks to be removed from the system without any difficulty.
- • The testing and debugging of a multitasking system with a multitasking kernel are easy compared to a multitasking system without a kernel.
- • Memory is better managed using a multitasking kernel.
- • Inter-task communication is easily handled using a multitasking kernel.
- • Task synchronization is easily controlled using a multitasking kernel.
- • CPU time is easily managed using a multitasking kernel.
- • Most multitasking kernels provide memory security where a task cannot access the memory space of another task.
- • Most multitasking kernels provide task priority where higher priority tasks can grab the CPU and stop the execution of lower priority tasks. This allows important tasks to run whenever it is required.
7.3. Need for an RTOS
7.4. Task scheduling algorithms
- • Co-operative scheduling
- • Round-robin scheduling
- • Preemptive scheduling
7.4.1. Co-operative scheduling

- • Tasks must not block the overall execution, for example, by using delays or waiting for some resources and not releasing the CPU.
- • The execution time of each tasks should be acceptable to other tasks.
- • Tasks should exit as soon as they complete their processings.
- • Tasks do not have to run to completion and they can exit for example before waiting for a resource to be available.
- • Tasks should resume their operations from the point after they release the CPU.


- • Start the Timer Calculator utility
- • Select device STM32F2xx/3xx/4xx
- • Set MCU frequency to 168 MHz
- • Choose Timer 2
- • Set the interrupt time to 100 ms
- • Click calculate
- • Copy function InitTimer2 to your program to initialize the timer. Also, copy the interrupt service routine function Timer2_interrupt to your program.

7.4.2. Round-robin scheduling
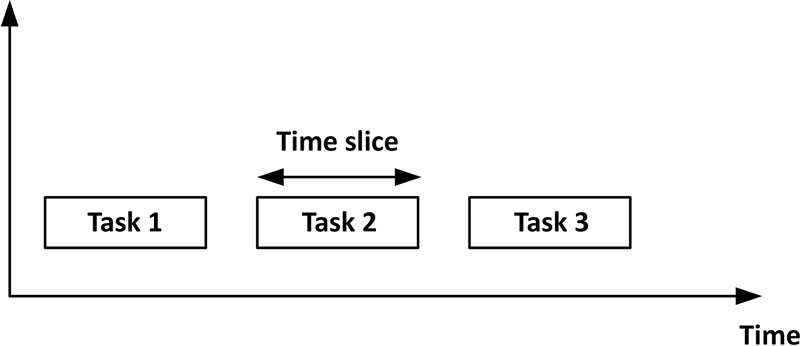
- • It is easy to implement.
- • Every task gets an equal share of the CPU.
- • Easy to compute the average response time.
- • It is not generally good to give the same CPU time to each task.
- • Some important tasks may not run to completion.
- • Not suitable for real-time systems where tasks usually have different processing requirements.
7.4.3. Preemptive scheduling
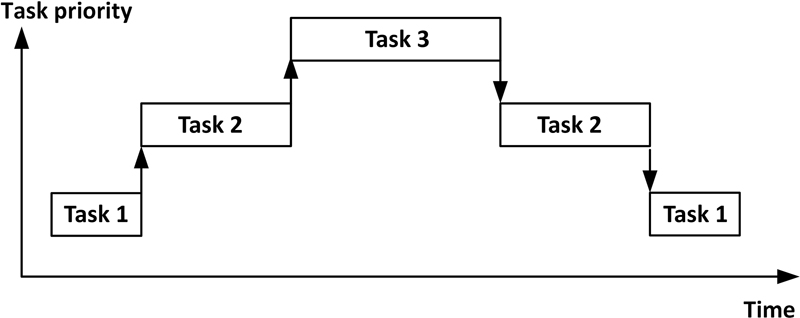
7.4.4. Scheduling algorithm goals
- • Be fair such that each process gets a fair share of the CPU.
- • Be efficient by keeping the CPU busy. The algorithm should not spend too much time to decide what to do.
- • Maximize throughput by minimizing the time users have to wait.
- • Be predictable so that same tasks take the same time when run multiple times.
- • Minimize response time.
- • Maximize resource use.
- • Enforce priorities.
- • Avoid starvataion.
7.4.5. Difference between preemptive and nonpreemptive scheduling
Table 7.1
| Nonpreemptive scheduling | Preemptive scheduling |
|---|---|
| Tasks have no priorities | Tasks have priorities |
| Tasks cannot be interrupted | A higher priority task interrupts a lower priority one |
| Waiting and response times are longer | Waiting and response times are shorter |
| Scheduling is rigid | Scheduling is flexible |
| Tasks do not have priorities | High priority tasks run to completion |
| Not suitable for real-time systems | Suitable for real-time systems |
7.4.6. Some other scheduling algorithms
7.4.6.1. First come first served
- • Throughput is low since long processes can hold the CPU, causing short processes to wait for a long time.
- • There is no proritization and thus real-time tasks cannot be executed quickly.
- • It is non-preemptive.
- • The context switching occurs only on task termination and therefore the overhead is minimal.
- • Each process gets the chance to be executed even if they have to wait for long time.
7.4.6.2. Shortest remaining time first
- • If a shorter task arrives then the currently running task is interrupted, thus causing overhead.
- • Waiting time of tasks requiring long processing times can be very long.
- • If there are too many small tasks in the system, longer tasks may never get the chance to run.
7.4.6.3. Longest remaining time first
- • If a longer task arrives then the currently running task is interrupted, thus causing overhead.
- • Waiting time of tasks requiring short processing times can be very long.
- • If there are too many long tasks in the system, shorter tasks may never get the chance to run.