
In the previous chapter we clustered texts into groups. This is a very useful tool, but it is not always appropriate. Clustering results in each text belonging to exactly one cluster. This book is about machine learning and Python. Should it be grouped with other Python-related works or with machine-related works? In the paper book age, a bookstore would need to make this decision when deciding where to stock it. In the Internet store age, however, the answer is that this book is both about machine learning and Python, and the book can be listed in both sections. We will, however, not list it in the food section.
In this chapter, we will learn methods that do not cluster objects, but put them into a small number of groups called topics. We will also learn how to derive between topics that are central to the text and others only that are vaguely mentioned (this book mentions plotting every so often, but it is not a central topic such as machine learning is). The subfield of machine learning that deals with these problems is called topic modeling.
LDA and LDA: unfortunately, there are two methods in machine learning with the initials LDA: latent Dirichlet allocation, which is a topic modeling method; and linear discriminant analysis, which is a classification method. They are completely unrelated, except for the fact that the initials LDA can refer to either. However, this can be confusing. Scikit-learn has a submodule, sklearn.lda, which implements linear discriminant analysis. At the moment, scikit-learn does not implement latent Dirichlet allocation.
The simplest topic model (on which all others are based) is latent Dirichlet allocation (LDA). The mathematical ideas behind LDA are fairly complex, and we will not go into the details here.
For those who are interested and adventurous enough, a Wikipedia search will provide all the equations behind these algorithms at the following link:
http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
However, we can understand that this is at a high level and there is a sort of fable which underlies these models. In this fable, there are topics that are fixed. This lacks clarity. Which documents?
For example, let's say we have only three topics at present:
- Machine learning
- Python
- Baking
Each topic has a list of words associated with it. This book would be a mixture of the first two topics, perhaps 50 percent each. Therefore, when we are writing it, we pick half of our words from the machine learning topic and half from the Python topic. In this model, the order of words does not matter.
The preceding explanation is a simplification of the reality; each topic assigns a probability to each word so that it is possible to use the word "flour" when the topic is either machine learning or baking, but more probable if the topic is baking.
Of course, we do not know what the topics are. Otherwise, this would be a different and much simpler problem. Our task right now is to take a collection of text and reverse engineer this fable in order to discover what topics are out there and also where each document belongs.
Unfortunately, scikit-learn does not support latent Dirichlet allocation. Therefore, we are going to use the gensim package in Python. Gensim is developed by Radim Řehůřek, who is a machine learning researcher and consultant in the Czech Republic. We must start by installing it. We can achieve this by running one of the following commands:
pip install gensim easy_install gensim
We are going to use an Associated Press (AP) dataset of news reports. This is a standard dataset, which was used in some of the initial work on topic models:
>>> from gensim import corpora, models, similarities
>>> corpus = corpora.BleiCorpus('./data/ap/ap.dat', '/data/ap/vocab.txt')Corpus is just the preloaded list of words:
>>> model = models.ldamodel.LdaModel(
corpus,
num_topics=100,
id2word=corpus.id2word)This one-step process will build a topic model. We can explore the topics in many ways. We can see the list of topics a document refers to by using the model[doc] syntax:
>>> topics = [model[c] for c in corpus]
>>> print topics[0]
[(3, 0.023607255776894751),
(13, 0.11679936618551275),
(19, 0.075935855202707139),
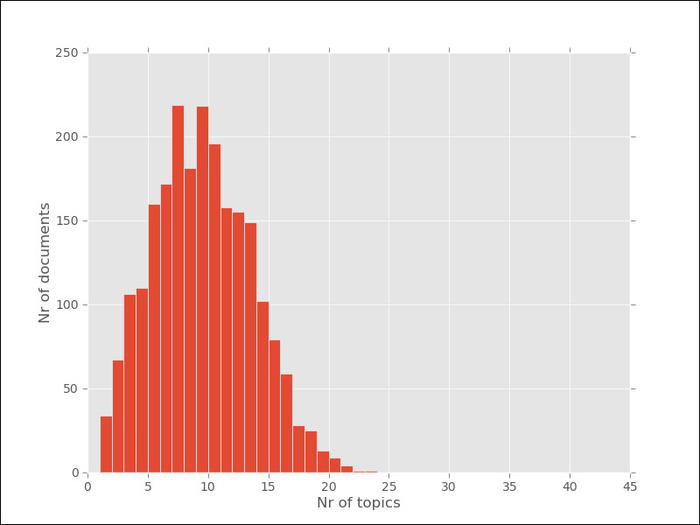
(92, 0.10781541687001292)]I elided some of the output, but the format is a list of pairs (topic_index, topic_weight). We can see that only a few topics are used for each document. The topic model is a sparse model, as although there are many possible topics for each document, only a few of them are used. We can plot a histogram of the number of topics as shown in the following graph:
Tip
Sparsity means that while you may have large matrices and vectors, in principle, most of the values are zero (or so small that we can round them to zero as a good approximation). Therefore, only a few things are relevant at any given time.
Often problems that seem too big to solve are actually feasible because the data is sparse. For example, even though one webpage can link to any other webpage, the graph of links is actually very sparse as each webpage will link to a very tiny fraction of all other webpages.
In the previous graph, we can see that about 150 documents have 5 topics, while the majority deal with around 10 to 12 of them. No document talks about more than 20 topics.
To a large extent, this is a function of the parameters used, namely the alpha parameter. The exact meaning of alpha is a bit abstract, but bigger values for alpha will result in more topics per document. Alpha needs to be positive, but is typically very small; usually smaller than one. By default, gensim will set alpha equal to 1.0/len (corpus), but you can set it yourself as follows:
>>> model = models.ldamodel.LdaModel( corpus, num_topics=100, id2word=corpus.id2word, alpha=1)
In this case, this is a larger alpha, which should lead to more topics per document. We could also use a smaller value. As we can see in the combined histogram given next, gensim behaves as we expected:
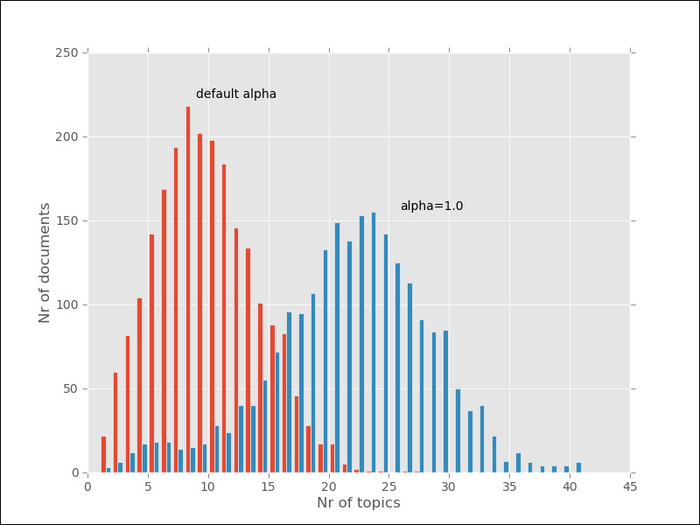
Now we can see that many documents touch upon 20 to 25 different topics.
What are these topics? Technically, they are multinomial distributions over words, which mean that they give each word in the vocabulary a probability. Words with high probability are more associated with that topic than words with lower probability.
Our brains aren't very good at reasoning with probability distributions, but we can readily make sense of a list of words. Therefore, it is typical to summarize topics with a the list of the most highly weighted words. Here are the first ten topics:
- dress military soviet president new state capt carlucci states leader stance government
- koch zambia lusaka one-party orange kochs party i government mayor new political
- human turkey rights abuses royal thompson threats new state wrote garden president
- bill employees experiments levin taxation federal measure legislation senate president whistleblowers sponsor
- ohio july drought jesus disaster percent hartford mississippi crops northern valley virginia
- united percent billion year president world years states people i bush news
- b hughes affidavit states united ounces squarefoot care delaying charged unrealistic bush
- yeutter dukakis bush convention farm subsidies uruguay percent secretary general i told
- Kashmir government people srinagar india dumps city two jammu-kashmir group moslem pakistan
- workers vietnamese irish wage immigrants percent bargaining last island police hutton I
Although daunting at first glance, we can clearly see that the topics are not just random words, but are connected. We can also see that these topics refer to older news items, from when the Soviet union still existed and Gorbachev was its Secretary General. We can also represent the topics as word clouds, making more likely words larger For example, this is the visualization of a topic, which deals with the Middle East and politics:

We can also see that some of the words should perhaps be removed (for example, the word I) as they are not so informative (stop words). In topic modeling, it is important to filter out stop words, as otherwise you might end up with a topic consisting entirely of stop words, which is not very informative. We may also wish to preprocess the text to stems in order to normalize plurals and verb forms. This process was covered in the previous chapter, and you can refer to it for details. If you are interested, you can download the code from the companion website of the book and try all these variations to draw different pictures.
Note
Building a word cloud like the one in the previous screenshot can be done with several different pieces of software. For the previous graphic, I used the online tool wordle (http://www.wordle.net), which generates particularly attractive images. Since I only had a few examples, I copy and pasted the list of words manually, but it is possible to use it as a web service and call it directly from Python.