
Chapter 10. A Zoo of DSLs
As I’ve said at the beginning of this book, the software world is full of DSLs. Here I want to show a brief summary of a few of them. I haven’t picked them out of any desire to show the best; it’s just a selection of those I’ve come across and considered suitable to show the variety of different kinds of DSL that exist. It’s a tiny fraction of DSLs that exist out there, but I hope even a small sample can give you a taste of the full population.
10.1 Graphviz
Graphviz is both a good example of a DSL and a useful package for anyone working with DSLs. It is a library for producing graphical renderings of node-and-arc graphs. Figure 10.1 shows an example stolen from Graphviz’s website.
Figure 10.1 An example use of Graphviz
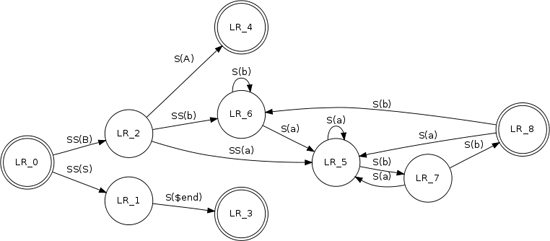
To produce this diagram, you provide the following code in the DOT language, which is an external DSL:
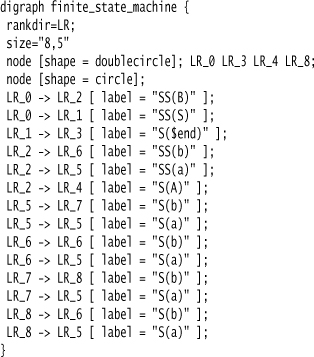
This example shows two kinds of things on the graph: nodes and arcs. Nodes are declared with the node keyword, but don’t have to be declared. Arcs are declared using the -> operator. Both nodes and arcs can be given attributes listed between square brackets.
Graphviz uses a Semantic Model in the form of a C data structure. The Semantic Model is populated by a parser using Syntax-Directed Translation and Embedded Translation written in Yacc and C. The parser makes good use of Embedment Helper. As it’s C, it doesn’t have a helper object, but a set of helper functions which are called in the grammar actions. As a result, the grammar itself is quite readable with short code actions that don’t obstruct the grammar. The lexer is handwritten, which is fairly common with Yacc parsers despite the presence of the Lex lexer generator.
The real business of Graphviz occurs once the Semantic Model of nodes and arcs is populated. The package figures out how to lay the graph out onto a diagram and has rendering code that can render the graph in various graphics formats. All of this is independent of the parser code; once the script is turned into the Semantic Model, everything else is based on those C data structures.
The example I show uses semicolons as statement separators, but these are entirely optional.
10.2 JMock
JMock is a Java library for Mock Objects [Meszaros]. Its authors have written several mock object libraries, which have evolved their ideas of a good internal DSL for defining expectations on the mocks ([Freeman and Pryce] is an excellent paper that talks about this evolution).
Mock objects are used in testing. You begin the test by declaring expectations, which are methods that an object expects will be called on it during the test. You then plug in the mock object to the actual object you are testing and stimulate that actual object. The mock object then reports if it received the correct method calls, thus supporting Behavior Verification [Meszaros].
To illustrate JMock’s DSL, I’ll go through a couple of eras of its evolution, beginning with the first library named JMock (JMock 1) that its authors dub the Cenozoic era [Freeman and Pryce]. Here are some example expectations:

This says that, as part of a test, the mainframe object (which is a mock mainframe) expects the buy method to be called once on it. The parameter to the call should be equal to the QUANTITY constant. When called, it will return the value in the TICKET constant.
Mock expectations need to be written in with test code as a fragmentary DSL, so an internal DSL is a natural choice for them. JMock 1 uses a mix of Method Chaining on the mock object itself (expects) and Nested Function (once). Object Scoping is used to allow the Nested Function methods to be bare. JMock 1 does the Object Scoping by forcing all tests using mocks to be written in a subclass of their library class.
In order to make the Method Chaining work better with IDEs, JMock uses progressive interfaces. This way, with is only available after method, which allows the autocompletion in IDEs to guide you through writing the expectations in the right way.
JMock uses Expression Builder to handle the DSL calls and translate them onto a Semantic Model of mocks and expectations. [Freeman and Pryce] refers to the Expression Builders as a syntax layer and the Semantic Model as the interpreter layer.
An interesting lesson in extensibility came from the interplay of Method Chaining and Nested Function. The Method Chaining defined on the Expression Builder is tricky for users to extend, since all the methods you can use are defined on the Expression Builder. However, it’s easy to add new methods in the Nested Function since you define them on the test class itself, or use your own subclass of the library superclass used for Object Scoping.
This approach works well, but still has some problems. In particular, there is the constraint that all tests using mocks must be defined in a subclass of the JMock library class so that Object Scoping can work. JMock 2 used a new style of DSL that avoided this problem; in this version, the same expectation reads like this:

With this version, JMock now uses Java’s instance initialization to do the Object Scoping. Although this does add some noise at the beginning of the expression, we can now define expectations without being in a subclass. The instance initializer effectively forms a Closure, making this a use of Nested Closure. It’s also worth noting that instead of using Method Chaining everywhere, the expectations now use Function Sequence to separate the method call part of the expectation from specifying the return value.
10.3 CSS
When I talk about DSLs, I often use the example of CSS.

CSS is an excellent example of a DSL for many reasons. Primarily, it’s a good example because most CSS programmers don’t call themselves programmers, but web designers. CSS is thus a good example of a DSL that’s not just read by domain experts, but also written by them.
CSS is also a good example because of its declarative computational model, which is very different from imperative models. There’s no sense of “do this, then do that” that you get with traditional programming languages. Instead, you simply declare matching rules for HTML elements.
This declarative nature introduces a good bit of complexity into figuring out what’s going on. In my example, an h2 element inside a sidebar div matches two different color rules. CSS has a somewhat complicated specificity scheme to figure out which color will win in such situations. However, many people find it hard to figure out how these rules work—which is the dark side of a declarative model.
CSS plays a well-focused role in the web ecosystem. While it’s pretty much essential these days, the thought of using only it to build an entire web application is ludicrous. It does its job pretty well, and works with a mix of other DSLs and general-purpose languages inside a complete solution.
CSS is also quite large. There’s a lot to it, both in the basic language semantics and in the semantics of the various attributes. DSLs can be limited in what they can express, but still have a lot to learn.
CSS fits in with the general DSL habit of limited error handling. Browsers are designed to ignore erroneous input, which usually means that a CSS file with a syntax error misbehaves silently, often making for some annoying debugging.
Like most DSLs, CSS lacks any way to create new abstractions—a common consequence of the limited expressiveness of DSLs. While this is mostly fine, there are some features that are annoyingly missing. The sample CSS shows one of these—I can’t name colors in my color schemes, so I have to use meaningless hex strings. People commonly complain about the lack of arithmetic functions that would be useful when manipulating sizes and margins. The solutions to this are the same as with other DSLs. Many simple problems, such as named colors, can be solved with Macros.
Another solution is to write another DSL that is similar to CSS and generates CSS as output. SASS (http://sass-lang.com) is an example of this, providing arithmetic operations and variables. It also uses a very different syntax, preferring syntactic newlines and indentation to CSS’s block structure. This is a common solution: use one DSL as a layer on top of another to provide abstractions the underlying DSL misses. The overlayed DSL needs to be similar (SASS uses the same attribute names), and the user of the overlayed DSL usually also understands the underlying DSL.
10.4 Hibernate Query Language (HQL)
Hibernate is a widely used object-relational mapping system which allows you to map Java classes onto the tables of a relational database. HQL provides the ability to write queries in a SQLish form in terms of Java classes that can be mapped to SQL queries against a real database. Such a query might look like this:
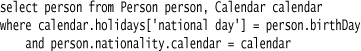
This allows people to think in terms of Java classes rather than database tables, and also avoid dealing with the various annoying differences between different databases’ SQL dialects.
The essence of HQL processing is to translate from an HQL query to a SQL query. Hibernate does this in three steps:
• HQL input text is transformed using Syntax-Directed Translation and Tree Construction into an HQL abstract syntax tree (AST).
• The HQL AST is transformed into a SQL AST.
• A code generator generates SQL code from the SQL AST.
In all these cases, ANTLR is used. In addition to using a token stream as an input to ANTLR’s syntactic analyzer, you can use ANTLR with an AST as input (this is what ANTLR calls a “tree grammar”). ANTLR’s tree construction syntax is used to build both the HQL and SQL ASTs.
This path of transformations, input text ▶ input AST ▶ output AST ▶ output text, is a common one with source-to-source transformation. Like in many transformation scenarios, it’s good to break down a complex transformation into several small transformations that can be easily plugged together.
You can think of the SQL AST as the Semantic Model for this case. The meaning of the HQL queries is defined by the SQL rendering of the query, and the SQL AST is a model of SQL. More often than not, ASTs are not the right structure for a Semantic Model, as the constraints of a syntax tree usually help more than they hinder. But for source-to-source translation, using an AST of the output language makes a great deal of sense.
10.5 XAML
Ever since the beginning of full-screen user interfaces, people have experimented with how to define the screen layout. The fact that this is a graphic medium has always led people to use some kind of graphic layout tool. Often, however, greater flexibility can be achieved by performing the layout in code. The trouble is that code may be an awkward mechanism. A screen layout is primarily a hierarchic structure, and stitching together a hierarchy in code is often more fiddly than it ought to be. So, with the appearance of Windows Presentation Framework, Microsoft introduced XAML as a DSL to lay out UIs.
(I confess I find Microsoft’s product naming to be remarkably banal these days. Good code names like “Avalon” and “Indigo” get turned into boring acronyms like WPF and WCF. Although it does invite a fantasy of seeing “Windows” turned one day into “Windows Technology Foundation.”)
XAML files are XML files that can be used to lay out an object structure; with WPF, they can lay out a screen, as in this example I stole from [Anderson]:
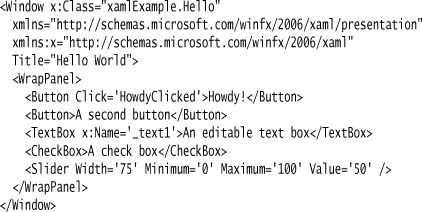
Microsoft is a fan of graphical design surface, so when working with XAML you can use a design surface, a text representation, or both. As a textual representation, XAML does suffer from XML’s syntactic noise, but XML does work fairly well on hierarchic structures like this. The fact that it bears a strong resemblance to HTML for laying out screens is also a plus.
XAML is a good example of what my old colleague Brad Cross refers to as a compositional (rather than computational) DSL. Unlike my initial state machine example, XAML is about how to organize relatively passive objects into a structure. Program behavior usually doesn’t depend strongly on the details of how a screen is laid out. Indeed, one of XAML’s strengths is that it encourages separating the screen layout from the code that drives the behavior of the screen.
A XAML document logically defines a C# class, and indeed there is some code generation. The code is generated as a partial class, in this case xamlExample.Hello. I can add behavior to the screen by writing code in another partial class definition.
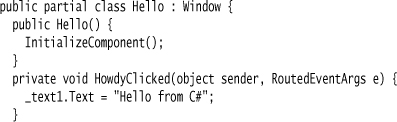
This code allows me to wire behavior together. For any control defined in the XAML file, I can tie an event on that control to a handler method in the code (HowdyClicked). The code can also refer to controls by name in order to manipulate them (_text1). By using names like this, I can keep the references free of the structure of the UI layout, which allows me to change it without having to update the behavior code.
XAML is usually thought of in the context of UI design, as it’s almost always described together with WPF. However, XAML can be used to wire up instances of any CLR classes, so it could be used in many more situations.
The structure that XAML defines is a hierarchy. DSLs can define hierarchy, but they can also define other structures by mentioning names. Indeed this is what Graphviz does using references to names to define a graph structure.
DSLs to lay out graphical structures like this are quite common. Swiby (http://swiby.codehaus.org) uses a Ruby internal DSL to define screen layout. It uses Nested Closure which provides a natural way of defining a hierarchic structure.
While I’m talking about DSLs for graphical layout, I can’t help but mention PIC—an old, and rather fascinating, DSL. PIC was created in the very early days of Unix, when graphical screens were still unusual. It allows you to describe a diagram in a textual format and then process it to produce the image. As an example, the following code produces Figure 10.2:
Figure 10.2 A simple PIC diagram

The written form is mostly obvious; the only hint is that you refer to connection points on shapes by compass points, so A.s means the “south” point on shape A. Textual descriptions like PIC aren’t so popular in the days of WYSIWYG environments, but the approach can be rather handy.
10.6 FIT
FIT (http://fit.c2.com) is a testing framework developed by Ward Cunningham in the early noughties (FIT stands for Framework for Integrated Test). Its aim is to describe testing scenarios in the form that a domain expert can understand. The basic idea has been extended by various tools since, in particular Fitnesse (http://fitnesse.org).
Looking at FIT as a DSL, there are a couple of things that make it interesting. The first is its form; at the heart of FIT is the notion that nonprogrammers are very comfortable with specifying examples in a tabular form. So a FIT program is a collection of tables, typically embedded in HTML pages. In between the tables, you can put any other HTML elements, which are treated as comments. This allows a domain expert to use prose narrative to describe what they want, with tables providing something that’s processable.
FIT tables can take different forms. The most program-like form is the action fixture, which is essentially a simple imperative language. It’s simple in that there are no conditionals or loops, just a sequence of verbs:
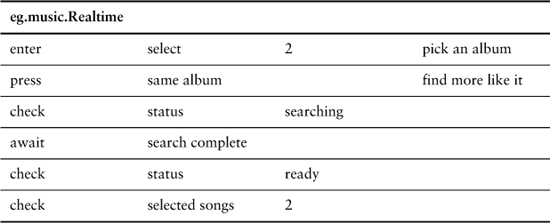
Each table is connected to a fixture that can translate the verbs into actions against the system. The check verb is special, in that it carries out a comparison. When the table is run, an output HTML is created which is the same as the input page except that all the check rows are colored either green or red, depending on whether the comparison matches or not.
Apart from this limited imperative form, FIT works with a number of other table styles. Here’s one that defines tabular output data from a list of objects (in this case, the search above):
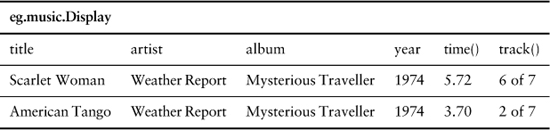
The header line defines various methods to be invoked against the collection of objects in the list. Each row compares against an object, defining the expected value from the object for its columns attribute. When the table is run, FIT compares the expected values against actual values, again using green/red coloring. This table follows the imperative table earlier, so you get an imperative table (called an action fixture in FIT) to navigate the applications, followed by a declarative table of expected results (called a row fixture) to compare to what the application displays.
This use of tables as source code is unusual, but it’s an approach that could be used more often. People like specifying things in tabular form, whether it’s examples for test data or more general processing rules such as a Decision Table. Many domain experts are very comfortable with editing tables in spreadsheets, which can then be processed into source code.
The second interesting thing about FIT is that it’s a testing-oriented DSL. In recent years, there’s been quite a growth in interest for automated testing tools, with several DSLs created for organizing tests. Many of these have been influenced by FIT.
Testing is a natural choice for a DSL. Compared to general-purpose programming languages, testing languages often require different kinds of structures and abstractions, such as the simple linear imperative model of FIT’s action tables. Tests often need to be read by domain experts, so a DSL makes a good choice, usually with a DSL purpose-written for the application at hand.
10.7 Make et al.
A trivial program is trivial to build and run, but it isn’t long before you realize that building code requires several steps. So, in the early days of Unix, the Make tool (www.gnu.org/software/make) provided a platform for structuring builds. The issue with builds is that many steps are expensive and don’t need to be done every time, so a Dependency Network is a natural choice of programming model. A Make program consists of several targets linked through dependencies.

The first line of this program says that edit depends on the other targets in the program; so, if any of them is not up-to-date, then, after building them, we must also build the edit target. A Dependency Network allows me to minimize build times to a bare minimum while ensuring that everything that needs to be built is actually built. Make is a familiar external DSL.
To me, the most interesting thing about build languages like Make isn’t so much their computational model as the fact that they need to intermix their DSL with a more regular programming language. Apart from specifying the targets and the dependencies between them (a classic DSL scenario), you also need to say how each target gets built—which suggests a more imperative approach. In Make, this means using shell script commands, in this example the calls to cc (the C compiler).
In addition to language intermixing in the target definitions, a simple Dependency Network suffers when the build gets more complex, requiring further abstractions on top of the Dependency Network. In the Unix world, this has led to the Automake toolchain, where Makefiles are generated by the Automake system.
A similar progression is visible in the Java world. The standard Java build language is Ant, which is also an external DSL using an XML carrier syntax. (Which, despite my dislike of XML carrier syntax, did avoid Make’s horrendous problems caused by allowing tabs and spaces in syntactic indentation.) Ant started simple, but ended up with embedded general-purpose scripts and other systems, like Maven, generating Ant scripts.
For my personal projects, the build system I prefer these days is Rake (http://rake.rubyforge.org). Like Make and Ant, it uses a Dependency Network as its core computational model. The big difference is that it is an internal DSL in Ruby. This allows you to write the contents of the targets in a more seamless manner, but also to build larger abstractions more easily.
Here is an example culled from the Rakefile that builds this book:
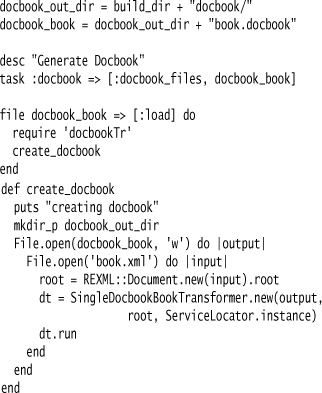
The line task :docbook ⇒ [:docbook_files, docbook_book] is the Dependency Network, saying that the :docbook depends on the other two targets. Targets in Rake can be either tasks or files (supporting both task-oriented and product-oriented styles of Dependency Network). The imperative code for building a target is contained in a Nested Closure after the target declaration. (See [Fowler rake] for more on the nice things you can do with Rake.)