
6
Interprocess Communication Based on Message Passing
CONTENTS
6.5 Message Structure and Contents
All interprocess communication methods presented in Chapter 5 are essentially able to pass synchronization signals from one process to another. They rely on shared memory to transfer data. Informally speaking, we know that it is possible to meaningfully transfer data among a group of producers and consumers by making them read from, and write into, a shared memory buffer “at the right time.” We use one ore more semaphores to make sure that the time is indeed right, but they are not directly involved in the data transfer.
It may therefore be of interest to look for a different interprocess communication approach in which one single supporting mechanism accomplishes both data transfer and synchronization, instead of having two distinct mechanisms for that. In this way, we would not only have a higher-level interprocess communication mechanism at our disposal but we will be able to use it even if there is no shared memory available. This happens, for example, when the communicating processes are executed by distinct computers.
Besides being interesting from a theoretical perspective, this approach, known as message passing, is very important from the practical standpoint, too. In Chapters 7 and 8, it will be shown that most operating systems, even very simple ones, provide a message-passing facility that can easily be used by threads and processes residing on the same machine. Then, in Chapter 9, we will see that a message-passing interface is also available among processes hosted on different computers linked by a communication network.
6.1 Basics of Message Passing
In its simplest, and most abstract, form a message-passing mechanism involves two basic primitives:
a send primitive, which sends a certain amount of information, called a message, to another process;
a receive primitive, which allows a process to block waiting for a message to be sent by another process, and then retrieve its contents.
Even if this definition still lacks many important details that will be discussed later, it is already clear that the most apparent effect of message passing primitives is to transfer a certain amount of information from the sending process to the receiving one. At the same time, the arrival of a message to a process also represents a synchronization signal because it allows the process to proceed after a blocking receive.
The last important requirement of a satisfactory interprocess communication mechanism, mutual exclusion, is not a concern here because messages are never shared among processes, and their ownership is passed from the sender to the receiver when the message is transferred. In other words, the mechanism works as if the message were instantaneously copied from the sender to the receiver even if real-world message passing systems do their best to avoid actually copying a message for performance reasons.
In this way, even if the sender alters a message after sending it, it will merely modify its local copy, and this will therefore not influence the message sent before. Symmetrically, the receiver is allowed to modify a message it received, and this action will not affect the sender in any way.
Existing message-passing schemes comprise a number of variations around this basic theme, which will be the subject of the following sections. The main design choices left open by our summary description are
For a sender, how to identify the intended recipient of a message. Symmetrically, for a receiver, how to specify from which other processes it is interested in receiving messages. In more abstract terms, a process naming scheme must be defined.
The synchronization model, that is, under what circumstances communicating processes shall be blocked, and for how long, when they are engaged in message passing.
How many message buffers, that is, how much space to hold messages already sent but not received yet, is provided by the system.
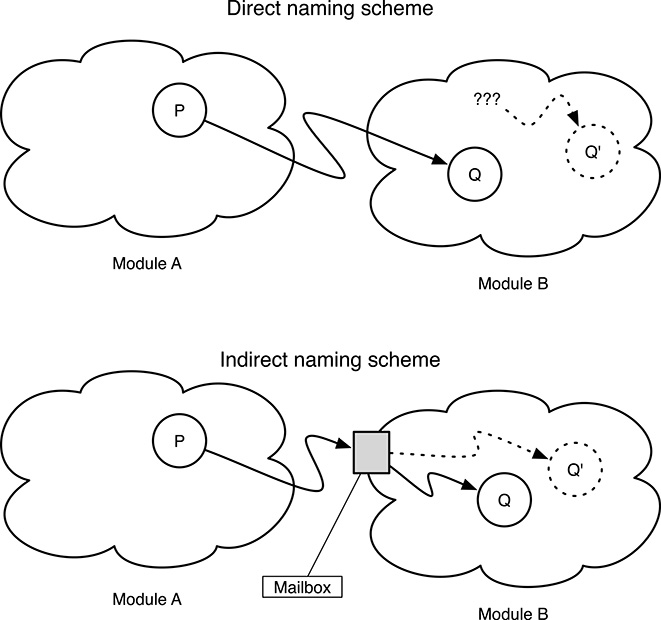
FIGURE 6.1
Direct versus indirect naming scheme; the direct scheme is simpler, the other one makes software integration easier.
6.2 Naming Scheme
The most widespread naming schemes differ for two important aspects:
how the
sendandreceiveprimitives are associated to each other;their symmetry (or asymmetry).
About the first aspect, the most straightforward approach is for the sending process to name the receiver directly, for instance, by passing its process identifier to send as an argument. On the other hand, when the software gets more complex, it may be more convenient to adopt an indirect naming scheme in which the send and receive primitives are associated because they both name the same intermediate entity. In the following, we will use the word mailbox for this entity, but in the operating system jargon, it is also known under several other names, such as channel or message queue.
As shown in Figure 6.1, an indirect naming scheme is advantageous to software modularity and integration. If, for example, a software module A wants to send a message to another module B, the process P (of module A) responsible for the communication must know the identity of the intended recipient process Q within module B. If the internal architecture of module B is later changed, so that the intended recipient becomes Q′ instead of Q, module A must be updated accordingly, or otherwise communication will no longer be possible.
In other words, module A becomes dependent not only upon the interface of module B—that would be perfectly acceptable—but also upon its internal design and implementation. In addition, if process identifiers are used to name processes, as it often happens, even more care is needed because there is usually no guarantee that the identifier of a certain process will still be the same across reboots even if the process itself was not changed at all.
On the contrary, if the communication is carried out with an indirect naming scheme, depicted in the lower part of the figure, module A and process P must only know the name of the mailbox that module B is using for incoming messages. The name of the mailbox is part of the external interface of module B and will likely stay the same even if B’s implementation and internal design change with time, unless the external interface of the module is radically redesigned, too.
Another side effect of indirect naming is that the relationship among communicating processes becomes more complex. For both kinds of naming, we can already have
a one-to-one structure, in which one process sends messages to another;
a many-to-one structure, in which many processes send messages to a single recipient.
With indirect naming, since multiple processes can receive messages from the same mailbox, there may also be a one-to-many or a many-to-many structure, or in which one or more processes send messages to a group of recipients, without caring about which of them will actually get the message.
This may be useful to conveniently handle concurrent processing in a server. For example, a web server may comprise a number of “worker” processes (or threads), all equal and able to handle a single HTTP request at a time. All of them will be waiting for requests through the same intermediate entity (which will most likely be a network communication endpoint in this case).
When a request eventually arrives, one of the workers will get it, process it, and provide an appropriate reply to the client. Meanwhile, the other workers will still be waiting for additional requests and may start working on them concurrently.
This example also brings us to discussing the second aspect of naming schemes, that is, their symmetry or asymmetry. If the naming scheme is symmetric, the sender process names either the receiving process or the destination mailbox, depending on whether the naming scheme is direct or indirect. Symmetrically, the receiver names either the sending process or the source mailbox.
If the naming scheme is asymmetric, the receiver does not name the source of the message in any way; it will accept messages from any source, and it will usually be informed about which process or mailbox the received message comes from. This scheme fits the client–server paradigm better because, in this case, the server is usually willing to accept requests from any of its clients and may not ever know their name in advance.
Regardless of the naming scheme being adopted, another very important issue is to guarantee that the named processes actually are what they say they are. In other words, when a process sends a message to another, it must be reasonably sure that the data will actually reach the intended destination instead of a malicious process. Similarly, no malicious processes should be able to look at or, even worse, alter the data while they are in transit.
In the past, this design aspect was generally neglected in most real-time, embedded systems because the real-time communication network was completely closed to the outside world and it was very difficult for a mischievous agent to physically connect to that network and do some damage. Nowadays this is no longer the case because many embedded systems are connected to the public Internet on purpose, for example, for remote management, maintenance, and software updates.
Besides its obvious advantages, this approach has the side effect of opening the real-time network and its nodes to a whole new lot of security threats, which are already well known to most Internet users. Therefore, even if network security as a topic is well beyond the scope of this book and will not be further discussed, it is nonetheless important for embedded system designers to be warned about the issue.
6.3 Synchronization Model
As said in the introduction to this chapter, message passing incorporates both data transfer and synchronization within the same communication primitives. In all cases, data transfer is accomplished by moving a message from the source to the destination process. However, the synchronization aspects are more complex and subject to variations from one implementation to another.
The most basic synchronization constraint that is always supported is that the receive primitive must be able to wait for a message if it is not already available. In most cases, there is also a nonblocking variant of receive, which basically checks whether a message is available and, in that case, retrieves it, but never waits if it is not. On the sending side, the establishment of additional synchronization constraints proceeds, in most cases, along three basic schemes:
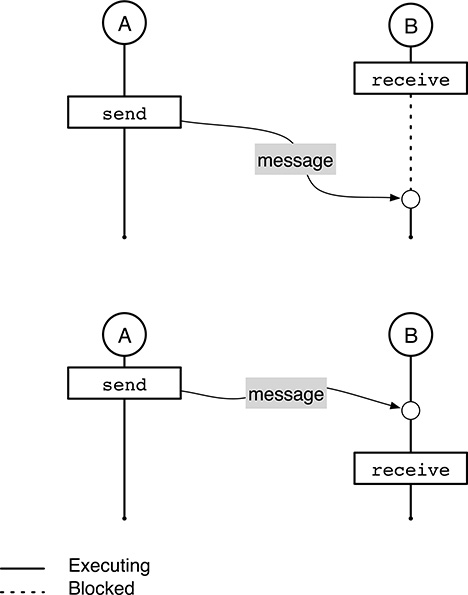
FIGURE 6.2
Asynchronous message transfer. The sender is never blocked by send even if the receiver is not ready for reception.
As shown in Figure 6.2, a message transfer is asynchronous if the sending process is never blocked by
sendeven if the receiving process has not yet executed a matchingreceive. This kind of message transfer gives rise to two possible scenarios:If, as shown in the upper part of the figure, the receiving process B executes
receivebefore the sending process A has sent the message, it will be blocked and it will wait for the message to arrive. The message transfer will take place when A eventually sends the message.If the sending process A sends the message before the receiving process B performs a matching
receive, the system will buffer the message (typically up to a certain maximum capacity as detailed in Section 6.4), and A will continue right away. As shown in the lower part of the figure, thereceivelater performed by B will be satisfied immediately in this case.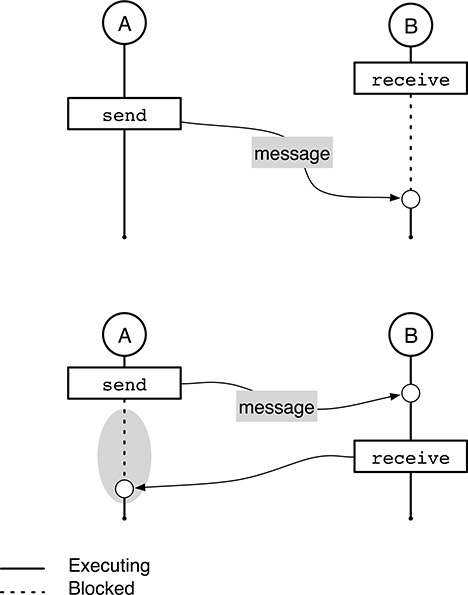
FIGURE 6.3
Synchronous message transfer, or rendezvous. The sender is blocked bysendwhen the receiver is not ready for reception.
The most important characteristic to keep in mind about an asynchronous message transfer is that, when B eventually gets a messages from A, it does not get any information about what A is currently doing because A may be executing well beyond its
sendprimitive. In other words, an asynchronous message transfer always conveys “out of date” information to the receiver.In a synchronous message transfer, also called rendezvous and shown in Figure 6.3, there is an additional synchronization constraint, highlighted by a grey oval in the lower part of the figure: if the sending process A invokes the
sendprimitive when the receiving process B has not calledreceiveyet, A is blocked until B does so.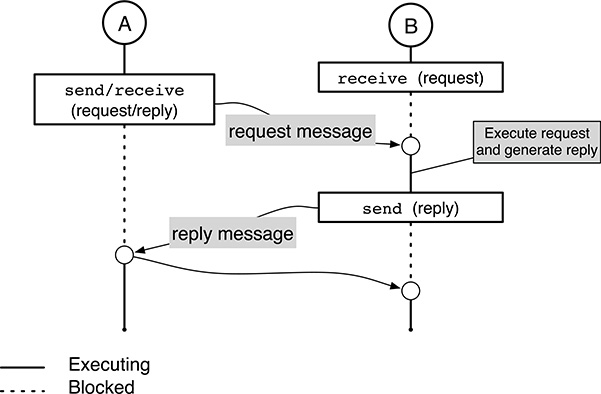
FIGURE 6.4
Remote invocation message transfer, or extended rendezvous. The sender is blocked until it gets a reply from the receiver. Symmetrically, the receiver is blocked until the reply has successfully reached the original sender.When B is eventually ready to receive the message, the message transfer takes place, and A is allowed to continue. As shown in the upper part of the figure, nothing changes with respect to the asynchronous model if the receiver is ready for reception when the sender invokes
send. In any case, with this kind of message transfer, the receiver B can rest assured that the sending process A will not proceed beyond itssendbefore B has actually received the message.This difference about the synchronization model has an important impact for what concerns message buffering, too: since in a rendezvous the message sender is forced to wait until the receiver is ready, the system must not necessarily provide any form of intermediate buffering to handle this case. The message can simply be kept by the sender until the receiver is ready and then transferred directly from the sender to the receiver address space.
A remote invocation message transfer, also known as extended renvezvous, is even stricter for what concerns synchronization. As depicted in Figure 6.4, when process A sends a request message to process B, it is blocked until a reply message is sent back from B to A.
As the name suggests, this synchronization model is often used to imitate a function call, or invocation, using message passing. As in a regular function call, the requesting process A prepares the arguments of the function it wants process B to execute. Then, it puts them into a request message and sends the message to process B, often called the server, which will be responsible to execute it.
At the same time, and often with the same message passing primitive entailing a combination of both
sendandreceive, A also blocks, waiting for a reply from B. The reply will contain any return values resulting from the function execution.Meanwhile, B has received the request and performs a local computation in order to execute the request, compute its results, and eventually generate the reply message. When the reply is ready, B sends it to A and unblocks it.
It should also be noted that the last message is not sent asynchronously, but B blocks until the message has been received by A. In this way, B can make sure that the reply has reached its intended destination, or at least be notified if there was an error.
The synchronization models discussed so far are clearly related to each other. In particular, it is easy to see that all synchronization models can be implemented starting from the first one, that is
A synchronous message transfer from a process A to another process B can be realized by means of two asynchronous message transfers going in opposite directions. The first transfer (from A to B) carries the actual message to be transferred, and the second one (from B to A) holds an acknowledgment. It should be noted that the second message transfer is not used to actually transfer data between processes but only for synchronization. Its purpose is to block A until B has successfully received the data message.
A remote invocation from A to B can be based on two synchronous message transfer going in opposite directions as before. The first transfer (from A to B) carries the request, and the second one (from B to A) the corresponding reply. Both being synchronous, the message transfers ensure that neither A nor B is allowed to continue before both the request and the reply have successfully reached their intended destination.
At first sight it may seem that, since an asynchronous message transfer can be used as the “basic building block” to construct all the others, it is the most useful one. For this reason, as will be discussed in Chapters 7 and 8, most operating systems provide just this synchronization model. However, it has been remarked [18] that it has a few drawbacks, too:
The most important concern is perhaps that asynchronous message transfers give “too much freedom” to the programmer, somewhat like the “goto” statement of unstructured sequential programming. The resulting programs are therefore more complex to understand and check for correctness, also due to the proliferation of explicit message passing primitives in the code.
Moreover, the system is also compelled to offer a certain amount of buffer for messages that have already been sent but have not been received yet; the amount of buffering is potentially infinite because, in principle, messages can be sent and never received. Most systems only offer a limited amount of buffer, as described in Section 6.4, and hence the kind of message transfer they implement is not truly asynchronous.
6.4 Message Buffers
In most cases, even if message passing occurs among processes being executed on the same computer, the operating system must provide a certain amount of buffer space to hold messages that have already been sent but have not been received yet. As seen in Section 6.3, the only exception occurs when the message transfer is completely synchronous so that the message can be moved directly from the sender to the recipient address space.
The role of buffers becomes even more important when message passing occurs on a communication network. Most network equipment, for example, switches and routers, works according to the store and forward principle in which a message is first received completely from a certain link, stored into a buffer, and then forwarded to its destination through another link. In this case, dealing with one or more buffers is simply unavoidable.
It also turns out that it is not always possible to decide whether a buffer will be useful or not, and how large it should be, because it depends on the application at hand. The following is just a list of the main aspects to be considered for a real-time application.
Having a large buffer between the sender and the receiver decouples the two processes and, on average, makes them less sensitive to any variation in execution and message passing speed. Thus, it increases the likelihood of executing them concurrently without unnecessarily waiting for one another.
The interposition of a buffer increases the message transfer delay and makes it less predictable. As an example, consider the simple case in which we assume that the message transfer time is negligible, the receiver consumes messages at a fixed rate of k messages per second, and there are already m messages in the buffer when the m + 1 message is sent. In this case, the receiver will start processing the m + 1 message after m/k seconds. Clearly, if m becomes too large for any reason, the receiver will work on “stale” data.
For some synchronization models, the amount of buffer space required at any given time to fulfill the model may depend on the processes’ behavior and be very difficult to predict. For the purely asynchronous model, the maximum amount of buffer space to be provided by the system may even be unbounded in some extreme cases. This happens, for instance, when the sender is faster than the receiver so that it systematically produces more messages than the receiver is able to consume.
For these and other reasons, the approach to buffering differs widely from one message passing implementation to another. Two extreme examples are provided by
The local message-passing primitives, discussed in Chapters 7 and 8. Those are intended for use by real-time processes all executing on the same computer.
The network communication primitives, discussed in Chapter 9 and intended for processes with weaker real-time requirements, but possibly residing on distinct computers.
In the first case, the focus is on the predictability of the mechanism from the point of view of its worst-case communication delay and amount of buffer space it needs. Accordingly, those systems require the user to declare in advance the maximum number of messages a certain mailbox can hold and their maximum size right when the mailbox itself is created.
Then, they implement a variant of the asynchronous communication model, in which the send primitive blocks the caller when invoked on a mailbox that is completely full at the moment, waiting for some buffer space to be available in the future. Since this additional synchronization constraint is not always desirable, they also provide a nonblocking variant of send that immediately returns an error indication instead of waiting.
In the second case, the goal is instead to hide any anomaly in network communication and provide a smooth average behavior of the message-passing mechanism. Therefore, each network equipment makes its “best effort” to provide an appropriate buffering, but without giving any absolute guarantee. The most important consequence is that, at least for long-distance connections, it may be very difficult to know for sure how much buffer is being provided, and the amount of buffer may change with time.
6.5 Message Structure and Contents
Regardless of the naming scheme, synchronization model, and kind of buffering being used, understanding what kind of data can actually be transmitted within a message with meaningful results is of paramount importance. In an ideal world it would be possible to directly send and receive any kind of data, even of a user-defined type, but this is rarely the case in practice.
The first issue is related to data representation: the same data type, for instance the int type of the C language, may be represented in very different ways by the sender and the receiver, especially if they reside on different hosts. For instance, the number of bits may be different, as well as the endianness, depending on the processor architecture. When this happens, simply moving the bits that made up an int data item from one host to another is clearly not enough to ensure a meaningful communication.
A similar issue also occurs if the data item to be exchanged contains pointers. Even if we take for granted that pointers have the same representation in both the sending and receiving hosts, a pointer has a well-defined meaning only within its own address space, as discussed in Chapter 2. Hence, a pointer may or may not make sense after message passing, depending on how the sending and receiving agents are related to each other:
If they are two threads belonging to the same process (and, therefore, they necessarily reside on the same host), they also live within the same address space, and the pointer will still reference the same underlying memory object.
If they are two processes residing on the same host, the pointer will still be meaningful after message passing only under certain very specific conditions, that is, only if their programmers were careful enough to share a memory segment between the two processes, make sure that it is mapped at the same virtual address in both processes, and allocate the referenced object there.
If the processes reside on different hosts, there is usually no way to share a portion of address spaces between them, and the pointer will definitely lose its meaning after the transfer.
Even worse, it may happen that the pointer will still be formally valid in the receiver’s context—that is, it will not be flagged as invalid by the memory management subsystem because it falls within the legal boundaries of the address space—but will actually point to a different, and unrelated, object.
In any case, it should also be noted that, even if passing a pointer makes sense (as in cases 1 and 2 above), it implies further memory management issues, especially if memory is dynamically allocated. For instance, programmers must make sure that, when a pointer to a certain object is passed from the sender to the receiver, the object is not freed (and its memory reused) before the receiver is finished with it.
This fact may not be trivial to detect for the sender, which in a sense can be seen as the “owner” of the object when asynchronous or synchronous transfers are in use. This is because, as discussed in Section 6.3, the sender is allowed to continue after the execution of a send primitive even if the receiver either did not get the message (asynchronous transfer) or did not actually work on the message (synchronous transfer) yet.
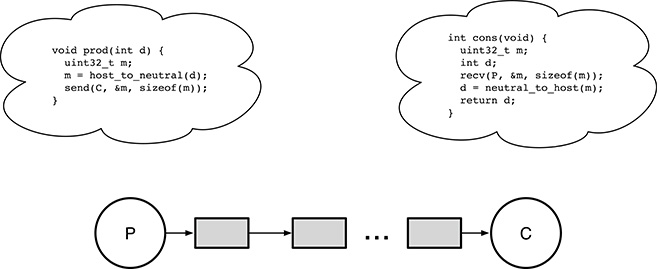
FIGURE 6.5
A straightforward solution to the producer–consumer problem with synchronous message passing. The same approach also works with asynchronous message passing with a known, fixed amount of buffering.
Since the problem is very difficult to solve in general terms, most operating systems and programming languages leave this burden to the programmer. In other words, in many cases, the message-passing primitives exported by the operating system and available to the programmer are merely able to move a sequence of bytes from one place to another.
The programmer is then entirely responsible for making sure that the sequence of bytes can be interpreted by the receiver. This is the case for both POSIX/Linux and FreeRTOS operating systems (discussed in Chapters 7 and 8), as well as the socket programming interface for network communication (outlined in Chapter 9).
6.6 Producer–Consumer Problem with Message Passing
The most straightforward solution to the producer–consumer problem using message passing is shown in Figure 6.5. For simplicity, the example only deals with one producer P and one consumer C, exchanging integer data items no larger than 32 bits. For the same reason, the operations performed to set up the communication path and error checks have been omitted, too.
Despite of the simplifications, the example still contains all the typical elements of message passing. In particular, when the producer P wants to send a certain data item d, it calls the function prod with d as argument to perform the following operations:
Convert the data item to be sent,
d, from the host representation to a neutral representation that both the sender and the receiver understand. This operation is represented in the code as a call to the abstract functionhost_to_neutral(). For a single, 32-bit integer variable, one sensible choice for a C-language program conforming to the POSIX standard would be, for instance, the functionhtonl().Send the message to the consumer C. A direct, symmetric naming scheme has been adopted in the example, and hence the
sendprimitive names the intended receiver directly with its first argument. The next two arguments are the memory address of the message to be sent and its size.
On the other side, the consumer C invokes the function cons() whenever it is ready to retrieve a message:
The function waits until a message arrives, by invoking the
recvmessage-passing primitive. Since the naming scheme is direct and symmetric, the first argument ofrecvidentifies the intended sender of the message, that is, P. The next two arguments locate a memory buffer in whichrecvis expected to store the received message and its size.Then, the data item found in the message just received is converted to the host representation by means of the function
neutral_to_host(). For a single, 32-bit integer variable, a suitable POSIX function would bentohl(). The resultdis returned to the caller.
Upon closer examination of Figure 6.5, it can be seen that the code just described gives rise to a unidirectional flow of messages, depicted as light grey boxes, from P to C, each carrying one data item. The absence of messages represents a synchronization condition because the consumer C is forced to wait within cons() until a message from P is available.
However, if we compare this solution with, for instance, the semaphore-based solution shown in Figure 5.12 in Chapter 5, it can easily be noticed that another synchronization condition is amiss. In fact, in the original formulation of the producer–consumer problem, the producer P must wait if there are “too many” messages already enqueued for the consumer. In Figure 5.12, the exact definition of “too many” is given by N, the size of the buffer interposed between producers and consumers.
Therefore, the solution just proposed is completely satisfactory—and matches the previous solutions, based on other interprocess synchronization mechanisms—only if the second synchronization condition is somewhat provided implicitly by the message-passing mechanism itself. This happens when the message transfer is synchronous, implying that there is no buffer at all between P and C.
An asynchronous message transfer can also be adequate if the maximum amount of buffer provided by the message-passing mechanism is known and fixed, and the send primitive blocks the sender when there is no buffer space available.
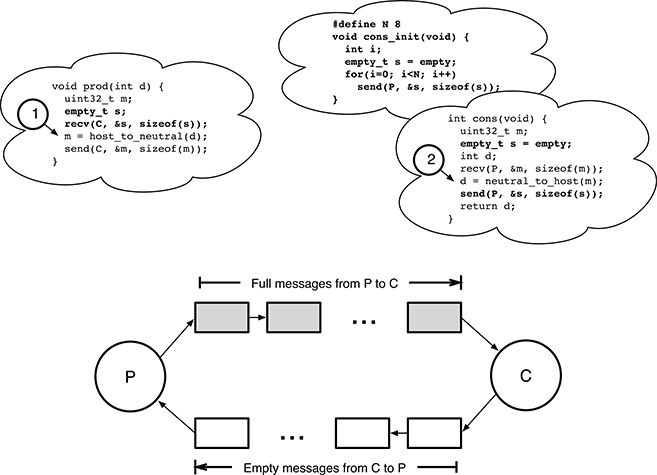
FIGURE 6.6
A more involved solution to the producer–consumer problem based on asynchronous message passing. In this case, the synchronization condition for the producer P is provided explicitly rather than implicitly.
If only asynchronous message passing is available, the second synchronization condition must be implemented explicitly. Assuming that the message-passing mechanism can successfully buffer at least N messages, a second flow of empty messages that goes from C to P and only carries synchronization information is adequate for this, as shown in Figure 6.6. In the figure, the additional code with respect to Figure 6.5 is highlighted in bold. The data type empty_t represents an empty message. With respect to the previous example,
The consumer C sends an empty message to P after retrieving a message from P itself.
The producer P waits for an empty message from the consumer C before sending its own message to it.
By means of the initialization function
cons_init(), the consumer injectsNempty messages into the system at startup.
At startup, there are therefore N empty messages. As the system evolves, the total number of empty plus full messages is constant and equal to N because one empty (full) message is sent whenever a full (empty) message is retrieved. The only transient exception happens when the producer or the consumer are executing at locations 1 and 2 of Figure 6.6, respectively. In that case, the total number of messages can be N − 1 or N − 2 because one or two messages may have been received by P and/or C and have not been sent back yet.
In this way, C still waits if there is no full message from P at the moment, as before. In addition, P also waits if there is no empty message from C. The total number of messages being constant, this also means that P already sent N full messages that have not yet been handled by C.
6.7 Summary
In this chapter we learnt that message passing is a valid alternative to interprocess communication based on shared variables and synchronization devices because it encompasses both data transfer and synchronization in the same set of primitives.
Although the basics of message passing rely on two intuitive and simple primitives, send and receive, there are several design and implementation variations worthy of attention. They fall into three main areas:
How to identify, or name, message senders and recipients;
What kind of synchronization constraints the send and receive primitives enforce;
How much buffer space, if any, is provided by the message-passing mechanism.
Moreover, to use message passing in a correct way, it is of paramount importance to ensure that messages retain their meaning after they are transferred from one process or thread to another. Especially when working with a distributed system in which the application code is executed by many agents spread across multiple hosts, issues such as data representation discrepancies among computer architectures as well as loss of pointer validity across distinct address spaces cannot be neglected.
Then, message passing has been applied to the well-known producer–consumer problem to show that its use leads to a quite simple and intuitive solution. The example also highlighted that, in some cases, it may be appropriate to introduce a message stream between processes, even if no data transfer is required, as a way to guarantee that they synchronize in the right way.
For the sake of completeness, it should also be remarked that the message-addressing scheme presented in this chapter, based on explicitly naming the source and recipient of a message, is not the only possible one. A popular alternative—quite common in real-time networks based on an underlying communication medium that supports broadcast transmission—is to adopt the so-called Publish/Subscribe scheme.
With this approach, the sending processes do not explicitly name any intended receiver. Rather, they attach a tag to each message that specifies the message class or contents rather than recipients. The message is then published, often by broadcasting it on the network, so that any interested party can get it. In turn, each receiving process subscribes to the message classes it is interested in so that it only receives and acts upon messages belonging to those specific classes.
A full discussion of the Publish/Subscribe scheme is beyond the scope of this book. Interested readers can refer, for example, to Reference [28] for a thorough discussion of this addressing scheme in the context of the Controller Area Network [49, 50].