
Finally, we have our vectors that we believe capture the posts to a sufficient degree. Not surprisingly, there are many ways to group them together. Most clustering algorithms fall into one of the two methods, flat and hierarchical clustering.
Flat clustering divides the posts into a set of clusters without relating the clusters to each other. The goal is simply to come up with a partitioning such that all posts in one cluster are most similar to each other while being dissimilar from the posts in all other clusters. Many flat clustering algorithms require the number of clusters to be specified up front.
In hierarchical clustering, the number of clusters does not have to be specified. Instead, the hierarchical clustering creates a hierarchy of clusters. While similar posts are grouped into one cluster, similar clusters are again grouped into one uber-cluster. This is done recursively, until only one cluster is left, which contains everything. In this hierarchy, one can then choose the desired number of clusters. However, this comes at the cost of lower efficiency.
Scikit provides a wide range of clustering approaches in the package sklearn.cluster. You can get a quick overview of the advantages and drawbacks of each of them at http://scikit-learn.org/dev/modules/clustering.html.
In the following section, we will use the flat clustering method, KMeans, and play a bit with the desired number of clusters.
KMeans is the most widely used flat clustering algorithm. After it is initialized with the desired number of clusters, num_clusters, it maintains that number of so-called cluster centroids. Initially, it would pick any of the num_clusters posts and set the centroids to their feature vector. Then it would go through all other posts and assign them the nearest centroid as their current cluster. Then it will move each centroid into the middle of all the vectors of that particular class. This changes, of course, the cluster assignment. Some posts are now nearer to another cluster. So it will update the assignments for those changed posts. This is done as long as the centroids move a considerable amount. After some iterations, the movements will fall below a threshold and we consider clustering to be converged.
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
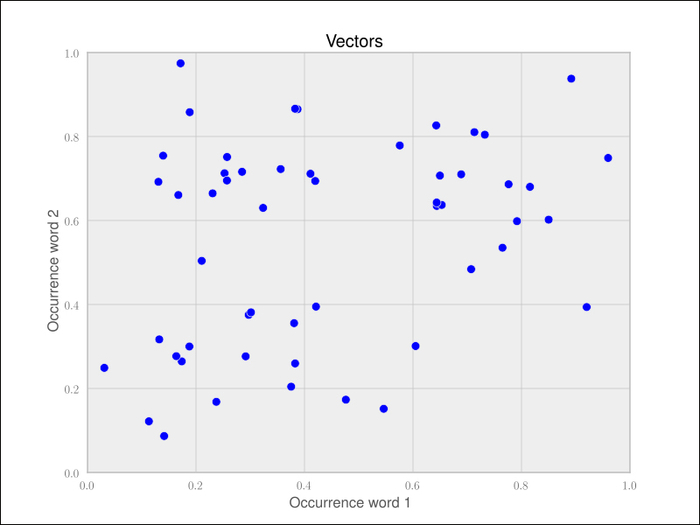
Let us play this through with a toy example of posts containing only two words. Each point in the following chart represents one document:
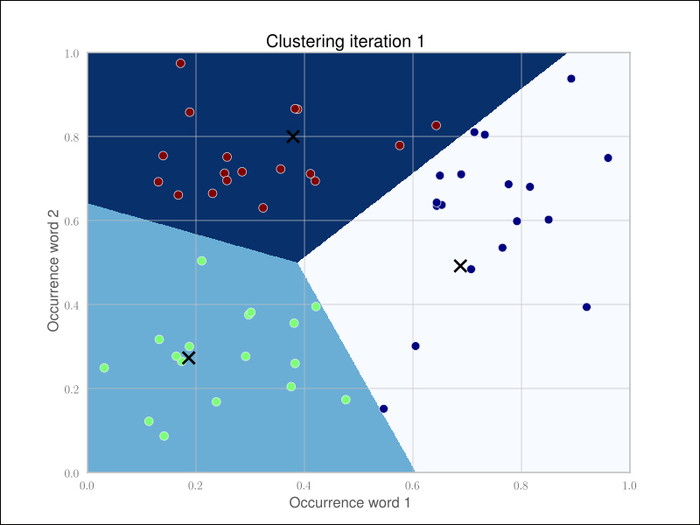
After running one iteration of KMeans, that is, taking any two vectors as starting points, assigning labels to the rest, and updating the cluster centers to be the new center point of all points in that cluster, we get the following clustering:
Because the cluster centers are moved, we have to reassign the cluster labels and recalculate the cluster centers. After iteration 2, we get the following clustering:
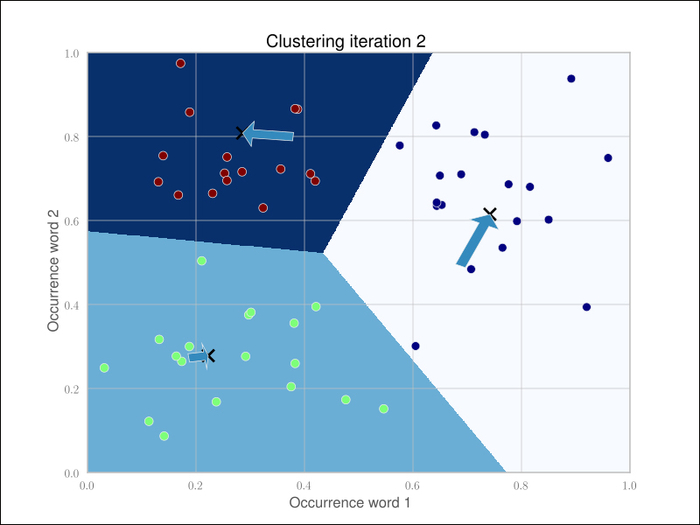
The arrows show the movements of the cluster centers. After five iterations in this example, the cluster centers don't move noticeably any more (Scikit's tolerance threshold is 0.0001 by default).
After the clustering has settled, we just need to note down the cluster centers and their identity. When each new document comes in, we have to vectorize and compare it with all the cluster centers. The cluster center with the smallest distance to our new post vector belongs to the cluster we will assign to the new post.
In order to test clustering, let us move away from the toy text examples and find a dataset that resembles the data we are expecting in the future so that we can test our approach. For our purpose, we need documents on technical topics that are already grouped together so that we can check whether our algorithm works as expected when we apply it later to the posts we hope to receive.
One standard dataset in machine learning is the 20newsgroup dataset, which contains 18,826 posts from 20 different newsgroups. Among the groups' topics are technical ones such as comp.sys.mac.hardware or sci.crypt as well as more politics- and religion-related ones such as talk.politics.guns or soc.religion.christian. We will restrict ourselves to the technical groups. If we assume each newsgroup is one cluster, we can nicely test whether our approach of finding related posts works.
The dataset can be downloaded from http://people.csail.mit.edu/jrennie/20Newsgroups. Much more simple, however, is to download it from MLComp at http://mlcomp.org/datasets/379 (free registration required). Scikit already contains custom loaders for that dataset and rewards you with very convenient data loading options.
The dataset comes in the form of a ZIP file, dataset-379-20news-18828_WJQIG.zip, which we have to unzip to get the folder 379, which contains the datasets. We also have to notify Scikit about the path containing that data directory. It contains a metadata file and three directories test, train, and raw. The test and train directories split the whole dataset into 60 percent of training and 40 percent of testing posts. For convenience, the dataset module also contains the function fetch_20newsgroups, which downloads that data into the desired directory.
Note
The website http://mlcomp.org is used for comparing machine-learning programs on diverse datasets. It serves two purposes: finding the right dataset to tune your machine-learning program and exploring how other people use a particular dataset. For instance, you can see how well other people's algorithms performed on particular datasets and compare them.
Either you set the environment variable MLCOMP_DATASETS_HOME or you specify the path directly with the mlcomp_root parameter when loading the dataset as follows:
>>> import sklearn.datasets
>>> MLCOMP_DIR = r"D:data"
>>> data = sklearn.datasets.load_mlcomp("20news-18828", mlcomp_root=MLCOMP_DIR)
>>> print(data.filenames)
array(['D:\data\379\raw\comp.graphics\1190-38614',
'D:\data\379\raw\comp.graphics\1383-38616',
'D:\data\379\raw\alt.atheism\487-53344',
...,
'D:\data\379\raw\rec.sport.hockey\10215-54303',
'D:\data\379\raw\sci.crypt\10799-15660',
'D:\data\379\raw\comp.os.ms-windows.misc\2732-10871'],
dtype='|S68')
>>> print(len(data.filenames))
18828
>>> data.target_names
['alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc']We can choose among training and test sets as follows:
>>> train_data = sklearn.datasets.load_mlcomp("20news-18828", "train", mlcomp_root=MLCOMP_DIR)
>>> print(len(train_data.filenames))
13180
>>> test_data = sklearn.datasets.load_mlcomp("20news-18828", "test", mlcomp_root=MLCOMP_DIR)
>>> print(len(test_data.filenames))
5648For simplicity's sake, we will restrict ourselves to only some newsgroups so that the overall experimentation cycle is shorter. We can achieve this with the categories parameter as follows:
>>> groups = ['comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.ma c.hardware', 'comp.windows.x', 'sci.space']
>>> train_data = sklearn.datasets.load_mlcomp("20news-18828", "train", mlcomp_root=MLCOMP_DIR, categories=groups)
>>> print(len(train_data.filenames))
3414You must have already noticed one thing – real data is noisy. The newsgroup dataset is no exception. It even contains invalid characters that will result in UnicodeDecodeError.
We have to tell the vectorizer to ignore them:
>>> vectorizer = StemmedTfidfVectorizer(min_df=10, max_df=0.5,
... stop_words='english', charset_error='ignore')
>>> vectorized = vectorizer.fit_transform(dataset.data)
>>> num_samples, num_features = vectorized.shape
>>> print("#samples: %d, #features: %d" % (num_samples, num_features))
#samples: 3414, #features: 4331We now have a pool of 3,414 posts and extracted for each of them a feature vector of 4,331 dimensions. That is what KMeans takes as input. We will fix the cluster size to 50 for this chapter and hope you are curious enough to try out different values as an exercise, as shown in the following code:
>>> num_clusters = 50 >>> from sklearn.cluster import KMeans >>> km = KMeans(n_clusters=num_clusters, init='random', n_init=1, verbose=1) >>> km.fit(vectorized)
That's it. After fitting, we can get the clustering information out of the members of km. For every vectorized post that has been fit, there is a corresponding integer label in km.labels_:
>>> km.labels_ array([33, 22, 17, ..., 14, 11, 39]) >>> km.labels_.shape (3414,)
The cluster centers can be accessed via km.cluster_centers_.
In the next section we will see how we can assign a cluster to a newly arriving post using km.predict.