
Let us start with the simple and beautiful nearest neighbor method from the previous chapter. Although it is not as advanced as other methods, it is very powerful. As it is not model-based, it can learn nearly any data. However, this beauty comes with a clear disadvantage, which we will find out very soon.
This time, we won't implement it ourselves, but rather take it from the sklearn toolkit. There, the classifier resides in sklearn.neighbors. Let us start with a simple 2-nearest neighbor classifier:
>>> from sklearn import neighbors >>> knn = neighbors.KNeighborsClassifier(n_neighbors=2) >>> print(knn) KNeighborsClassifier(algorithm=auto, leaf_size=30, n_neighbors=2, p=2, warn_on_equidistant=True, weights=uniform)
It provides the same interface as all the other estimators in sklearn. We train it using fit(), after which we can predict the classes of new data instances using predict():
>>> knn.fit([[1],[2],[3],[4],[5],[6]], [0,0,0,1,1,1]) >>> knn.predict(1.5) array([0]) >>> knn.predict(37) array([1]) >>> knn.predict(3) NeighborsWarning: kneighbors: neighbor k+1 and neighbor k have the same distance: results will be dependent on data order. neigh_dist, neigh_ind = self.kneighbors(X) array([0])
To get the class probabilities, we can use predict_proba(). In this case, where we have two classes, 0 and 1, it will return an array of two elements as in the following code:
>>> knn.predict_proba(1.5)array([[ 1., 0.]])>>> knn.predict_proba(37)array([[ 0., 1.]])>>> knn.predict_proba(3.5) array([[ 0.5, 0.5]])
So, what kind of features can we provide to our classifier? What do we think will have the most discriminative power?
The TimeToAnswer attribute is already present in our meta dictionary, but it probably won't provide much value on its own. Then there is only Text, but in its raw form, we cannot pass it to the classifier as the features must be in numerical form. We will have to do the dirty work of extracting features from it.
What we could do is check the number of HTML links in the answer as a proxy for quality. Our hypothesis would be that more hyperlinks in an answer indicate better answers, and thus have a higher likelihood of being up-voted. Of course, we want to only count links in normal text and not in code examples:
import re
code_match = re.compile('<pre>(.*?)</pre>',
re.MULTILINE|re.DOTALL)
link_match = re.compile('<a href="http://.*?".*?>(.*?)</a>',
re.MULTILINE|re.DOTALL)
def extract_features_from_body(s):
link_count_in_code = 0
# count links in code to later subtract them
for match_str in code_match.findall(s):
link_count_in_code +=
len(link_match.findall(match_str))
return len(link_match.findall(s)) – link_count_in_codeWith this in place, we can generate one feature per answer. But before we train the classifier, let us first have a look at what we will train it with. We can get a first impression with the frequency distribution of our new feature. This can be done by plotting the percentage of how often each value occurs in the data as shown in the following graph:
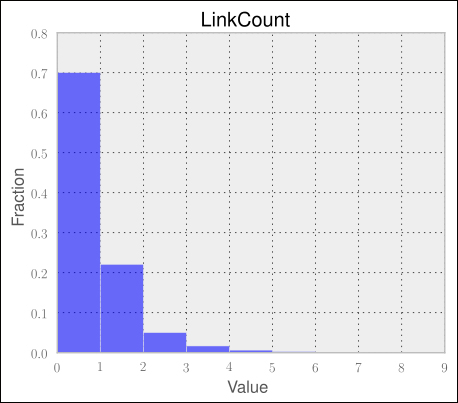
With the majority of posts having no link at all, we now know that this feature alone will not make a good classifier. Let us nevertheless try it out to get a first estimation of where we are.
We have to pass the feature array together with the previously defined Y labels to the kNN learner to obtain a classifier:
X = np.asarray([extract_features_from_body(text) for post_id, text in fetch_posts() if post_id in all_answers]) knn = neighbors.KNeighborsClassifier() knn.fit(X, Y)
Using the standard parameters, we just fitted a 5NN (meaning NN with k = 5) to our data. Why 5NN? Well, with the current state of our knowledge about the data, we really have no clue what the right k should be. Once we have more insight, we will have a better idea of how to set the value for k.
We have to be clear about what we want to measure. The naive but easiest way is to simply calculate the average prediction quality over the test set. This will result in a value between 0 for incorrectly predicting everything and 1 for perfect prediction. Accuracy can be obtained through knn.score().
But as we learned in the previous chapter, we will not do it just once, but apply cross-validation here using the ready-made KFold class from sklearn.cross_validation. Finally, we will average the scores on the test set of each fold and see how much it varies using standard deviation. Refer to the following code:
from sklearn.cross_validation import KFold
scores = []
cv = KFold(n=len(X), k=10, indices=True)
for train, test in cv:
X_train, y_train = X[train], Y[train]
X_test, y_test = X[test], Y[test]
clf = neighbors.KNeighborsClassifier()
clf.fit(X, Y)
scores.append(clf.score(X_test, y_test))
print("Mean(scores)=%.5f Stddev(scores)=%.5f"%(np.mean(scores, np.std(scores)))The output is as follows:
Mean(scores)=0.49100 Stddev(scores)=0.02888
This is far from being usable. With only 49 percent accuracy, it is even worse than tossing a coin. Apparently, the number of links in a post are not a very good indicator of the quality of the post. We say that this feature does not have much discriminative power—at least, not for kNN with k = 5.
In addition to using a number of hyperlinks as proxies for a post's quality, using a number of code lines is possibly another good option too. At least it is a good indicator that the post's author is interested in answering the question. We can find the code embedded in the <pre>…</pre> tag. Once we have extracted it, we should count the number of words in the post while ignoring the code lines:
def extract_features_from_body(s):
num_code_lines = 0
link_count_in_code = 0
code_free_s = s
# remove source code and count how many lines
for match_str in code_match.findall(s):
num_code_lines += match_str.count('
')
code_free_s = code_match.sub("", code_free_s)
# sometimes source code contain links,
# which we don't want to count
link_count_in_code += len(link_match.findall(match_str))
links = link_match.findall(s)
link_count = len(links)
link_count -= link_count_in_code
html_free_s = re.sub(" +", " ", tag_match.sub('', code_free_s)).replace("
", "")
link_free_s = html_free_s
# remove links from text before counting words
for anchor in anchors:
if anchor.lower().startswith("http://"):
link_free_s = link_free_s.replace(anchor,'')
num_text_tokens = html_free_s.count(" ")
return num_text_tokens, num_code_lines, link_countLooking at the following graphs, we can notice that the number of words in a post show higher variability:
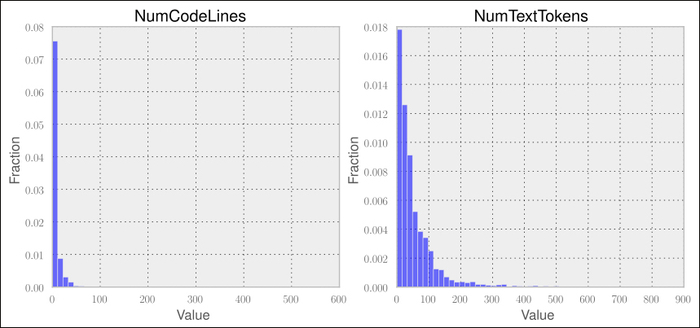
Training on the bigger feature space improves accuracy quite a bit:
Mean(scores)=0.58300 Stddev(scores)=0.02216
But still, this would mean that we could classify roughly four out of the ten wrong answers. At least we are heading in the right direction. More features lead to higher accuracy, which leads us to adding more features. Therefore, let us extend the feature space with even more features:
AvgSentLen: This feature measures the average number of words in a sentence. Maybe there is a pattern that particularly good posts don't overload the reader's brain with very long sentences.AvgWordLen: This feature is similar toAvgSentLen; it measures the average number of characters in the words of a post.NumAllCaps: This feature measures the number of words that are written in uppercase, which is considered a bad style.NumExclams: This feature measures the number of exclamation marks.
The following charts show the value distributions for average sentences and word lengths as well as the number of uppercase words and exclamation marks:

With these four additional features, we now have seven features representing individual posts. Let's see how we have progressed:
Mean(scores)=0.57650 Stddev(scores)=0.03557
Now that's interesting. We added four more features and got worse classification accuracy. How can that be possible?
To understand this, we have to remind ourselves of how kNN works. Our 5NN classifier determines the class of a new post by calculating the preceding seven described features, namely LinkCount, NumTextTokens, NumCodeLines, AvgSentLen, AvgWordLen, NumAllCaps, and NumExclams, and then finds the five nearest other posts. The new post's class is then the majority of the classes of those nearest posts. The nearest posts are determined by calculating the Euclidean distance. As we did not specify it, the classifier was initialized with the default value p = 2, which is the parameter in the Minkowski distance. This means that all seven features are treated similarly. kNN does not really learn that, for instance, NumTextTokens is good to have but much less important than NumLinks. Let us consider the following two posts, A and B, which only differ in the following features, and how they compare to a new post:
|
Post |
NumLinks |
NumTextTokens |
|---|---|---|
|
A |
2 |
20 |
|
B |
0 |
25 |
|
New |
1 |
23 |
Although we would think that links provide more value than mere text, post B would be considered more similar to the new post than post A.
Clearly, kNN has a hard time correctly using the available data.