
Chapter 6
System and Acceptance Testing
In this chapter—
6.1 SYSTEM TESTING OVERVIEW
System testing is defined as a testing phase conducted on the complete integrated system, to evaluate the system compliance with its specified requirements. It is done after unit, component, and integration testing phases.
The testing conducted on the complete integrated products and solutions to evaluate system compliance with specified requirements on functional and nonfunctional aspects is called system testing.
A system is a complete set of integrated components that together deliver product functionality and features. A system can also be defined as a set of hardware, software, and other parts that together provide product features and solutions. In order to test the entire system, it is necessary to understand the product's behavior as a whole. System testing helps in uncovering the defects that may not be directly attributable to a module or an interface. System testing brings out issues that are fundamental to design, architecture, and code of the whole product.
System testing is the only phase of testing which tests the both functional and non-functional aspects of the product. On the functional side, system testing focuses on real-life customer usage of the product and solutions. System testing simulates customer deployments. For a general-purpose product, system testing also means testing it for different business verticals and applicable domains such as insurance, banking, asset management, and so on.
On the non-functional side, system brings in different testing types (also called quality factors), some of which are as follows.
- Performance/Load testing To evaluate the time taken or response time of the system to perform its required functions in comparison with different versions of same product(s) or a different competitive product(s) is called performance testing. This type of testing is explained in the next chapter.
- Scalability testing A testing that requires enormous amount of resource to find out the maximum capability of the system parameters is called scalability testing. This type of testing is explained in subsequent sections of this chapter.
- Reliability testing To evaluate the ability of the system or an independent component of the system to perform its required functions repeatedly for a specified period of time is called reliability testing. This is explained in subsequent sections of this chapter.
- Stress testing Evaluating a system beyond the limits of the specified requirements or system resources (such as disk space, memory, processor utilization) to ensure the system does not break down unexpectedly is called stress testing. This is explained in subsequent sections of this chapter.
- Interoperability testing This testing is done to ensure that two or more products can exchange information, use the information, and work closely. This is explained in subsequent sections of this chapter.
- Localization testing Testing conducted to verify that the localized product works in different languages is called localization testing. This is explained in Chapter 9, Internationalization Testing.
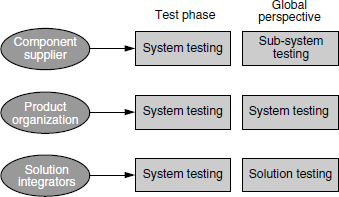
The definition of system testing can keep changing, covering wider and more high-level aspects, depending on the context. A solution provided to a customer may be an integration of multiple products. Each product may be a combination of several components. A supplier of a component of a product can assume the independent component as a system in its own right and do system testing of the component. From the perspective of the product organization, integrating those components is referred to as sub-system testing. When all components, delivered by different component developers, are assembled by a product organization, they are tested together as a system. At the next level, there are solution integrators who combine products from multiple sources to provide a complete integrated solution for a client. They put together many products as a system and perform system testing of this integrated solution. Figure 6.1 illustrates the system testing performed by various organizations from their own as well as from a global perspective. The coloured figure is available on Illustrations.
System testing is performed on the basis of written test cases according to information collected from detailed architecture/design documents, module specifications, and system requirements specifications. System test cases are created after looking at component and integration test cases, and are also at the same time designed to include the functionality that tests the system together. System test cases can also be developed based on user stories, customer discussions, and points made by observing typical customer usage.
System testing may not include many negative scenario verification, such as testing for incorrect and negative values. This is because such negative testing would have been already performed by component and integration testing and may not reflect real-life customer usage.
System testing may be started once unit, component, and integration testing are completed. This would ensure that the more basic program logic errors and defects have been corrected. Apart from verifying the business requirements of the product, system testing is done to ensure that the product is ready for moving to the user acceptance test level.
6.2 WHY IS SYSTEM TESTING DONE?
An independent test team normally does system testing. This independent test team is different from the team that does the component and integration testing. The system test team generally reports to a manager other than the project manager to avoid conflict of interest and to provide freedom to individuals doing system testing. Testing the product with an independent perspective and combining that with the perspectives of the customer makes system testing unique, different, and effective. System testing by an independent team removes the bias on the product and inducting a “fresh pair of eyes” through an independent system test team helps in locating problems missed out by component and integration testing.
The behavior of the complete product is verified during system testing. Tests that refer to multiple modules, programs, and functionality are included in system testing. Testing the complete product behavior is critical as it is wrong to believe that individually tested components will work together when they are put together.
System testing helps in identifying as many defects as possible before the customer finds them in the deployment. This is the last chance for the test team to find any remaining product defects before the product is handed over to the customer.
System testing is conducted with an objective to find product level defects and in building the confidence before the product is released to the customer. Component and integration testing phases focus on finding defects. If the same focus is provided in system testing and significant defects are found, it may generate a feeling that the product is unstable (especially because system testing is closer to product release than component or integration testing). Contrary to this, if system testing uncovers few defects, it raises questions on the effectiveness and value of system testing phase. Hence, system testing strives to always achieve a balance between the objective of finding defects and the objective of building confidence in the product prior to release.
Since system testing is the last phase of testing before the release, not all defects can be fixed in code due to time and effort needed in development and testing and due to the potential risk involved in any last-minute changes. Hence, an impact analysis is done for those defects to reduce the risk of releasing a product with defects. If the risk of the customers getting exposed to the defects is high, then the defects are fixed before the release; else, the product is released as such. The analysis of defects and their classification into various categories also gives an idea about the kind of defects that will be found by the customer after release. This information helps in planning some activities such as providing workarounds, documentation on alternative approaches, and so on. Hence, system testing helps in reducing the risk of releasing a product.
System testing is highly complementary to other phases of testing. The component and integration test phases are conducted taking inputs from functional specification and design. The main focus during these testing phases are technology and product implementation. On the other hand, customer scenarios and usage patterns serve as the basis for system testing. Thus system testing phase complements the earlier phases with an explicit focus on customers. The system testing phase helps in switching this focus of the product development team towards customers and their use of the product.
To summarize, system testing is done for the following reasons.
- Provide independent perspective in testing
- Bring in customer perspective in testing
- Provide a “fresh pair of eyes” to discover defects not found earlier by testing
- Test product behavior in a holistic, complete, and realistic environment
- Test both functional and non-functional aspects of the product
- Build confidence in the product
- Analyze and reduce the risk of releasing the product
- Ensure all requirements are met and ready the product for acceptance testing.
6.3 FUNCTIONAL VERSUS NON-FUNCTIONAL TESTING
Functional testing involves testing a product's functionality and features. Non-functional testing involves testing the product's quality factors. System testing comprises both functional and non-functional test verification.
Functional testing helps in verifying what the system is supposed to do. It aids in testing the product's features or functionality. It has only two results as far as requirements fulfillment is concerned—met or not met. If requirements are not properly enumerated, functional requirements may be understood in many ways. Hence, functional testing should have very clear expected results documented in terms of the behavior of the product. Functional testing comprises simple methods and steps to execute the test cases. Functional testing results normally depend on the product, not on the environment. It uses a pre-determined set of resources and configuration except for a few types of testing such as compatibility testing where configurations play a role, as explained in Chapter 4. Functional testing requires in-depth customer and product knowledge as well as domain knowledge so as to develop different test cases and find critical defects, as the focus of the testing is to find defects. Failures in functional testing normally result in fixes in the code to arrive at the right behavior. Functional testing is performed in all phases of testing such as unit testing, component testing, integration testing, and system testing. Having said that, the functional testing done in the system testing phase (functional system testing) focuses on product features as against component features and interface features that get focused on in earlier phases of testing.
Non-functional testing is performed to verify the quality factors (such as reliability, scalability etc.). These quality factors are also called non-functional requirements. Non-functional testing requires the expected results to be documented in qualitative and quantifiable terms. Non-functional testing requires large amount of resources and the results are different for different configurations and resources. Non-functional testing is very complex due to the large amount of data that needs to be collected and analyzed. The focus on non-functional testing is to qualify the product and is not meant to be a defect-finding exercise. Test cases for non-functional testing include a clear pass/fail criteria. However, test results are concluded both on pass/fail definitions and on the experiences encountered in running the tests.
Apart from verifying the pass or fail status, non-functional tests results are also determined by the amount of effort involved in executing them and any problems faced during execution. For example, if a performance test met the pass/fail criteria after 10 iterations, then the experience is bad and test result cannot be taken as pass. Either the product or the non-functional testing process needs to be fixed here.
Non-functional testing requires understanding the product behavior, design, and architecture and also knowing what the competition provides. It also requires analytical and statistical skills as the large amount of data generated requires careful analysis. Failures in non-functional testing affect the design and architecture much more than the product code. Since nonfunctional testing is not repetitive in nature and requires a stable product, it is performed in the system testing phase.
The points discussed in the above paragraphs are summarized in Table 6.1.
Table 6.1 Functional testing versus non-functional testing.
| Testing aspects | Functional testing | Non-functional testing |
|---|---|---|
| Involves | Product features and functionality | Quality factors |
| Tests | Product behavior | Behavior and experience |
| Result conclusion | Simple steps written to check expected results | Huge data collected and analyzed |
| Results varies due to | Product implementation | Product implementation, resources, and configurations |
| Testing focus | Defect detection | Qualification of product |
| Knowledge required | Product and domain | Product, domain, design, architecture, statistical skills |
| Failures normally due to | Code | Architecture, design, and code |
| Testing phase | Unit, component, integration, system | System |
| Test case repeatability | Repeated many times | Repeated only in case of failures and for different configurations |
| Configuration | One-time setup for a set of test cases | Configuration changes for each test case |
Some of the points mentioned in Table 6.1 may be seen as judgmental and subjective. For example, design and architecture knowledge is needed for functional testing also. Hence all the above points have to be taken as guidelines, not dogmatic rules.
Since both functional and non-functional aspects are being tested in the system testing phase, the question that can be asked is “What is the right proportion of test cases/effort for these two types of testing?” Since functional testing is a focus area starting from the unit testing phase while non-functional aspects get tested only in the system testing phase, it is a good idea that a majority of system testing effort be focused on the non-functional aspects. A 70%–30% ratio between non-functional and functional testing can be considered good and 50%–50% ratio is a good starting point. However, this is only a guideline, and the right ratio depends more on the context, type of release, requirements, and products.
6.4 FUNCTIONAL SYSTEM TESTING
As explained earlier, functional testing is performed at different phases and the focus is on product level features. As functional testing is performed at various testing phases, there are two obvious problems. One is duplication and other one is gray area. Duplication refers to the same tests being performed multiple times and gray area refers to certain tests being missed out in all the phases. A small percentage of duplication across phases is unavoidable as different teams are involved. Performing cross-reviews (involving teams from earlier phases of testing) and looking at the test cases of the previous phase before writing system test cases can help in minimizing the duplication. A small percentage of duplication is advisable, as different people from different teams test the features with different perspectives, yielding new defects.
Gray areas in testing happen due to lack of product knowledge, lack of knowledge of customer usage, and lack of co-ordination across test teams. Such gray areas in testing make defects seep through and impact customer usage. A test team performing a particular phase of testing may assume that a particular test will be performed by the next phase. This is one of the reasons for such gray areas. In such cases, there has to be a clear guideline for team interaction to plan for the tests at the earliest possible phase. A test case moved from a later phase to an earlier phase is a better alternative than delaying a test case from an earlier phase to a later phase, as the purpose of testing is to find defects as early as possible. This has to be done after completing all tests meant for the current phase, without diluting the tests of the current phase.
There are multiple ways system functional testing is performed. There are also many ways product level test cases are derived for functional testing. Some of the common techniques are given below.
- Design/architecture verification
- Business vertical testing
- Deployment testing
- Beta testing
- Certification, standards, and testing for compliance.
6.4.1 Design/Architecture Verification
In this method of functional testing, the test cases are developed and checked against the design and architecture to see whether they are actual product-level test cases. Comparing this with integration testing, the test cases for integration testing are created by looking at interfaces whereas system level test cases are created first and verified with design and architecture to check whether they are product-level or component-level test cases. The integration test cases focus on interactions between modules or components whereas the functional system test focuses on the behavior of the complete product. A side benefit of this exercise is ensuring completeness of the product implementation. This technique helps in validating the product features that are written based on customer scenarios and verifying them using product implementation. If there is a test case that is a customer scenario but failed validation using this technique, then it is moved appropriately to component or integration testing phases. Since functional testing is performed at various test phases, it is important to reject the test cases and move them to an earlier phase to catch defects early and avoid any major surprise at a later phases. Some of the guidelines used to reject test cases for system functional testing include the following.
- Is this focusing on code logic, data structures, and unit of the product? (If yes, then it belongs to unit testing.)
- Is this specified in the functional specification of any component? (If yes, then it belongs to component testing.)
- Is this specified in design and architecture specification for integration testing? (If yes, then it belongs to integration testing.)
- Is it focusing on product implementation but not visible to customers? (This is focusing on implementation—to be covered in unit/component/integration testing.)
- Is it the right mix of customer usage and product implementation? (Customer usage is a prerequisite for system testing.)
6.4.2 Business Vertical Testing
General purpose products like workflow automation systems can be used by different businesses and services. Using and testing the product for different business verticals such as insurance, banking, asset management, and so on, and verifying the business operations and usage, is called “business vertical testing.” For this type of testing, the procedure in the product is altered to suit the process in the business. For example, in loan processing, the loan is approved first by the officer and then sent to a clerk. In claim processing, the claim is first worked out by a clerk and then sent to an officer for approval. User objects such as clerk and officer are created by the product and associated with the operations. This is one way of customizing the product to suit the business. There are some operations that can only be done by some user objects; this is called role-based operations. It is important that the product understands the business processes and includes customization as a feature so that different business verticals can use the product. With the help of the customization feature, a general workflow of a system is altered to suit specific business verticals.
Another important aspect is called terminology. To explain this concept let us take the example of e-mail. An e-mail sent in the insurance context may be called a claim whereas when an e-mail is sent in a loan-processing system, it is called a loan application. The users would be familiar with this terminology rather than the generic terminology of “e-mail.” The user interface should reflect these terminologies rather than use generic terminology e-mails, which may dilute the purpose and may not be understood clearly by the users. An e-mail sent to a blood bank service cannot take the same priority as an internal e-mail sent to an employee by another employee. These differentiations need to be made by the product using the profile of the sender and the mail contents. Some e-mails or phone calls need to be tracked by the product to see whether they meet service level agreements (SLAS). For example, an e-mail to a blood bank service needs as prompt a reply as possible. Some of the mails could be even automated mail replies based on rules set in the e-mail management system for meeting the SLAs. Hence the terminology feature of the product should call the e-mail appropriately as a claim or a transaction and also associate the profile and properties in a way a particular business vertical works.
Yet another aspect involved in business vertical testing is syndication. Not all the work needed for business verticals are done by product development organizations. Solution integrators, service providers pay a license fee to a product organization and sell the products and solutions using their name and image. In this case the product name, company name, technology names, and copyrights may belong to the latter parties or associations and the former would like to change the names in the product. A product should provide features for those syndications in the product and they are as tested part of business verticals testing.
Business vertical testing can be done in two ways—simulation and replication. In simulation of a vertical test, the customer or the tester assumes requirements and the business flow is tested. In replication, customer data and process is obtained and the product is completely customized, tested, and the customized product as it was tested is released to the customer.
As discussed in the chapter on integration testing, business verticals are tested through scenarios. Scenario testing is only a method to evolve scenarios and ideas, and is not meant to be exhaustive. It's done more from the perspective of interfaces and their interaction. Having some business verticals scenarios created by integration testing ensures quick progress in system testing, which is done with a perspective of end-to-end scenarios. In the system testing phase, the business verticals are completely tested in real-life customer environment using the aspects such as customization, terminology, and syndication described in the above paragraphs.
6.4.3 Deployment Testing
System testing is the final phase before product delivery. By this time the prospective customers and their configuration would be known and in some cases the products would have been committed for sale. Hence, system testing is the right time to test the product for those customers who are waiting for it. The short-term success or failure of a particular product release is mainly assessed on the basis of on how well these customer requirements are met. This type of deployment (simulated) testing that happens in a product development company to ensure that customer deployment requirements are met is called offsite deployment.
Deployment testing is also conducted after the release of the product by utilizing the resources and setup available in customers’ locations. This is a combined effort by the product development organization and the organization trying to use the product. This is called onsite deployment. Even though onsite deployment is not conducted in the system testing phase, it is explained here to set the context. It is normally the system testing team that is involved in completing the onsite deployment test. Onsite deployment testing is considered to be a part of acceptance testing (explained later in this chapter) and is an extension of offsite deployment testing.
Onsite deployment testing is done at two stages. In the first stage (Stage 1), actual data from the live system is taken and similar machines and configurations are mirrored, and the operations from the users are rerun on the mirrored deployment machine. This gives an idea whether the enhanced or similar product can perform the existing functionality without affecting the user. This also reduces the risk of a product not being able to satisfy existing functionality, as deploying the product without adequate testing can cause major business loss to an organization. Some deployments use intelligent recorders to record the transactions that happen on a live system and commit these operations on a mirrored system and then compare the results against the live system. The objective of the recorder is to help in keeping the mirrored and live system identical with respect to business transactions. In the second stage (Stage 2), after a successful first stage, the mirrored system is made a live system that runs the new product. Regular backups are taken and alternative methods are used to record the incremental transactions from the time mirrored system became live. The recorder that was used in the first stage can also be used here. However, a different method to record the incremental transaction is advised, for sometimes failures can happen due to recorder also. This stage helps to avoid any major failures since some of the failures can be noticed only after an extended period of time. In this stage, the live system that was used earlier and the recorded transactions from the time mirrored system became live, are preserved to enable going back to the old system if any major failures are observed at this stage. If no failures are observed in this (second) stage of deployment for an extended period (for example, one month), then the onsite deployment is considered successful and the old live system is replaced by the new system. Stages 1 and 2 of deployment testing are represented in Figure 6.2. The coloured figure is available on Illustrations.
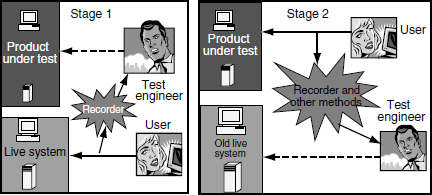
In Stage 1 of Figure 6.2, it can be seen that the recorder intercepts the user and live system to record all transactions. All the recorded transactions from the live system are then played back on the product under test under the supervision of the test engineer (shown by dotted lines). In Stage 2, the test engineer records all transactions using a recorder and other methods and plays back on the old live system (shown again by dotted lines).
6.4.4 Beta Testing
Developing a product involves a significant amount of effort and time. Delays in product releases and the product not meeting the customer requirements are common. A product rejected by the customer after delivery means a huge loss to the organization. There are many reasons for a product not meeting the customer requirements. They are as follows.
- There are implicit and explicit requirements for the product. A product not meeting the implicit requirements (for example, ease of use) may mean rejection by the customer.
- Since product development involves a good amount of time, some of the requirements given at the beginning of the project would have become obsolete or would have changed by the time the product is delivered. Customers’ business requirements keep changing constantly and a failure to reflect these changes in the product makes the latter obsolete.
- The requirements are high-level statements with a high degree of ambiguity. Picking up the ambiguous areas and not resolving them with the customer results in rejection of the product.
- The understanding of the requirements may be correct but their implementation could be wrong. This may mean reworking the design and coding to suit the implementation aspects the customer wants. If this is not done in time, it may result in rejection of the product.
- Lack of usability and documentation makes it difficult for the customer to use the product and may also result in rejection.
The list above is only a sub-set of the reasons and there could be many more reasons for rejection. To reduce the risk, which is the objective of system testing, periodic feedback is obtained on the product. One of the mechanisms used is sending the product that is under test to the customers and receiving the feedback. This is called beta testing. This testing is performed by the customer and helped by the product development organization. During the entire duration of beta testing, there are various activities that are planned and executed according to a specific schedule. This is called a beta program. Some of the activities involved in the beta program are as follows.
- Collecting the list of customers and their beta testing requirements along with their expectations on the product.
- Working out a beta program schedule and informing the customers. Not all the customers in the list need to agree to the start date and end date of the beta program. The end date of a beta program should be reasonably before the product release date so that the beta testing defects can be fixed before the release.
- Sending some documents for reading in advance and training the customer on product usage.
- Testing the product to ensure it meets “beta testing entry criteria.” The customers and the product development/management groups of the vendor together prepare sets of entry/exit criteria for beta testing.
- Sending the beta product (with known quality) to the customer and enable them to carry out their own testing.
- Collecting the feedback periodically from the customers and prioritizing the defects for fixing.
- Responding to customers’ feedback with product fixes or documentation changes and closing the communication loop with the customers in a timely fashion.
- Analyzing and concluding whether the beta program met the exit criteria.
- Communicate the progress and action items to customers and formally closing the beta program.
- Incorporating the appropriate changes in the product.
Deciding on the entry criteria of a product for beta testing and deciding the timing of a beta test poses several conflicting choices to be made. Sending the product too early, with inadequate internal testing will make the customers unhappy and may create a bad impression on quality of product. Sending the product too late may mean too little a time for beta defect fixes and this one defeats the purpose of beta testing. Late integration testing phase and early system testing phase is the ideal time for starting a beta program.
It is quite possible that customers discontinue the beta program after starting it or remain passive, without adequately using the product and giving feedback. From the customers’ perspective, it is possible that beta testing is normally just one of their activities and it may not be high on their priority list. Constant communication with the customers is necessary to motivate them to use the product and help them whenever they are facing problems with the product. They should also be made to see the benefits of participating in the beta program. The early exposure they get to emerging technologies, the competitive business advantages that can come from these technologies, and the image of the beta customer as a pioneer in the adoptation of these technologies should all be impressed upon the customers. Once the customers see the beta program as a win-win program for them as well as for the vendor (rather than be viewed only as a test bed for the product), their motivation to actively participate in the program increases. Defects reported in beta programs are also given the same priority and urgency as that of normal support calls, with the only difference being that the product development/engineering department is likely to have a more direct interaction with the beta customers. Failure in meeting beta testing objectives or in giving timely fixes may mean some customers rejecting the product. Hence, defect fixes are sent to customers as soon as problems are reported and all necessary care has to be taken to ensure the fixes meets the requirements of the customer.
One other challenge in beta programs is the choice of the number of beta customers. If the number chosen are too few, then the product may not get a sufficient diversity of test scenarios and test cases. If too many beta customers are chosen, then the engineering organization may not be able to cope up with fixing the reported defects in time. Thus the number of beta customers should be a delicate balance between providing a diversity of product usage scenarios and the manageability of being able to handle their reported defects effectively.
Finally, the success of a beta program depends heavily on the willingness of the beta customers to exercise the product in various ways, knowing fully well that there may be defects. This is not an easy task. As mentioned earlier, the beta customers must be motivated to see the benefits they can get. Only customers who can be thus motivated and are willing to play the role of trusted partners in the evolution of the product should participate in the beta program.
6.4.5 Certification, Standards and Testing for Compliance
A product needs to be certified with the popular hardware, operating system, database, and other infrastructure pieces. This is called certification testing. A product not working with any of the popular hardware or software or equipment, may be unsuitable for current and future use. The sales of a product depend on whether it was certified with the popular systems or not. The product has to work with the popular systems, as the customer would have already invested heavily on those. Not only should the product co-exist and run with the current versions of these popular systems, but the product organization should also document a commitment (in the form of a roadmap) to continue to work with the future versions of the popular systems. This is one type of testing where there is equal interest from the product development organization, the customer, and certification agencies to certify the product. However, the onus of making sure the certification happens rests with the product development organization. The certification agencies produce automated test suites to help the product development organization. The product development organization runs those certification test suites and corrects the problems in the product to ensure that tests are successful. Once the tests are successfully run, the results are sent to the certification agencies and they give the certification for the product. The test suite may be rerun by the certification agencies to verify the results, in which case the product under test should be sent along with the test results.
There are many standards for each technology area and the product may need to conform to those standards. This is very important as adhering to these standards makes the product interact easily with other products. This also helps the customer not to worry too much about the products future compatibility with other products. As explained, there are many standards for each technology area and the product development companies select the standards to be implemented at the beginning of the product cycle. Following all the standards may not be possible and sometime there may be some non-functional issues (for example, performance impact) because of which certain standards may not get implemented. Standards can be evolving also (for example, Ipv6 in networking and 3G in mobile technology) and finer details are worked out as and when some implementations kick off. Some of the standards are evolved by the open community and published as public domain standards (for example, Open LDAP standard). Tools associated with those open standards can be used free of cost to verify the standard's implementation. Testing the product to ensure that these standards are properly implemented is called testing for standards. Once the product is tested for a set of standards, they are published in the release documentation for the information of the customers so that they know what standards, are implemented in the product.
There are many contractual and legal requirements for a product. Failing to meet these may result in business loss and bring legal action against the organization and its senior management. Some of these requirements could be contractual obligations and some statutory requirements. Failing to meet these could severely restrict the market for the product. For example, it may not be possible to bid for US government organizations if usability guidelines (508 Accessibility Guidelines) are not met. Testing the product for contractual, legal, and statutory compliance is one of the critical activities of the system testing team. The following are some examples of compliance testing.
- Compliance to FDA This act by the food and drug administration requires that adequate testing be done for products such as cosmetics, drugs, and medical sciences. This also requires that all the test reports along with complete documentation of test cases, execution information for each test cycle along with supervisory approvals be preserved for checking adequacy of tests by the FDA.
- 508 accessibility guidelines This accessibility set of guidelines requires the product to meet some requirements for its physically challenged users. These guidelines insist that the product should be as accessible to physically challenged people as it is to people without those disabilities.
- SOX (Sarbanes–Oxley's Act) This act requires that products and services be audited to prevent financial fraud in the organization. The software is required to go through all transactions and list out the suspected faulty transactions for analysis. The testing for this act helps the top executives by keeping them aware of financial transactions and their validity.
- OFAC and Patriot Act This act requires the transactions of the banking applications be audited for misuse of funds for terrorism.
The terms certification, standards and compliance testing are used interchangeably. There is nothing wrong in the usage of terms as long as the objective of the testing is met. For example, a certifying agency helping an organization to meet standards can be called as both certification testing and standards testing (for example, Open LDAP is both a certification and a standard).
6.5 NON-FUNCTIONAL TESTING
In Section 6.3, we have seen how non-functional testing is different from functional testing. The process followed by non-functional testing is similar to that of functional testing but differs from the aspects of complexity, knowledge requirement, effort needed, and number of times the test cases are repeated. Since repeating non-functional test cases involves more time, effort, and resources, the process for non-functional testing has to be more robust stronger than functional testing to minimize the need for repetition. This is achieved by having more stringent entry/exit criteria, better planning, and by setting up the configuration with data population in advance for test execution.
6.5.1 Setting Up the Configuration
The biggest challenge, setting up the configuration, is common to all types of non-functional testing. There are two ways the setup is done—simulated environment and real-life customer environment. Due to varied types of customers, resources availability, time involved in getting the exact setup, and so on, setting up a scenario that is exactly real-life is difficult. Even though using real-life customer environment is a crucial factor for the success of this testing, due to several complexities involved, simulated setup is used for non-functional testing where actual configuration is difficult to get. Setting up a configuration is a challenge for the following reasons.
- Given the high diversity of environments and variety of customers, it is very difficult to predict the type of environment that will be used commonly by the customers.
- Testing a product with different permutations and combinations of configurations may not prove effective since the same combination of environment may not used by the customer and testing for several combinations involves effort and time. Furthermore, because of the diversity of configurations, there is a combinatorial explosion in the number of configurations to be tested.
- The cost involved in setting up such environments is quite high.
- Some of the components of the environment could be from competing companies products and it may not be easy to get these.
- The people may not have the skills to set up the environment.
- It is difficult to predict the exact type and nature of data that the customer may use. Since confidentiality is involved in the data used by the customer, such information is not passed on to the testing team.
In order to create a “near real-life” environment, the details regarding customer's hardware setup, deployment information and test data are collected in advance. Test data is built based on the sample data given. If it is a new product, then information regarding similar or related products is collected. These inputs help in setting up the test environment close to the customer's so that the various quality characteristics of the system can be verified more accurately.
6.5.2 Coming up with Entry/Exit Criteria
Coming up with entry and exit criteria is another critical factor in nonfunctional testing. Table 6.2 gives some examples of how entry/exit criteria can be developed for a set of parameters and for various types of nonfunctional tests. Meeting the entry criteria is the responsibility of the previous test phase (that is, integration testing phase) or it could be the objective of dry-run tests performed by the system testing team, before accepting the product for system testing.

6.5.3 Balancing Key Resources
This section intends to discuss the concepts of non-functional testing with respect to four key resources—CPU, disk, memory, and network. The four resources are related to each other and we need to completely understand their relationship to implement the strategy for non-functional testing.
These four resources in a computer require equal attention as they need to be judiciously balanced to enhance the quality factors of the product. All these resources are interdependent. For example, if the memory requirements in the system are addressed, the need for CPU may become more intensive. This in turn may result in multiple cycles of upgrade as the requirements of the customers keep increasing. The demand for all these resources tends to grow when a new release of the product is produced as software becomes more and more complex. Software is meant not only for computers but also for equipment such as cell phones; hence upgrading the resources is not easy anymore.

Often, customers are perplexed when they are told to increase the number of CPUs, memory, and the network bandwidth for better performance, scalability, and other non-functional aspects. This perception of arbitrariness is created when the rationale and measurable guidelines to specify the level of performance/scalability improvement to be expected when resources are adjusted, is not provided. Hence, when asking customers to upgrade the resources one important aspect return on investment needs to be justified clearly. The question that remains in the customer's mind is, “What will I get when I upgrade?” If the product is well tested, then for every increment of addition to a resource, there will be a corresponding improvement in the product for nonfunctional aspects, thus justifying to the customer the additional requirement.
It is important to understand and acknowledge customers’ views about the resources the product intensively uses and the resources that are critical for product usage. It is easy to tell the customer, “Product A is CPU intensive, product B requires more memory, and product C requires better bandwidth,” and so on. However, some of the products that run on a particular server could be from multiple vendors but they may be expected to run together on the same machine. Hence, it is very difficult for the customer to increase all the resources in the server, as all the products are expected to run in the same server, at the same time. Similarly, multiple applications can run on client machines sharing resources.
It is equally important to analyze from the perspective of the product organization that software is becoming more complex as more and more features get added for every release using different and latest technologies. Unless proper resources are assigned for the product, the better aspects of the product can not be seen.
As there are many perspectives of resources, many relationships between resources and varied requirements for non-functional testing, certain basic assumptions about the resources have to be made by the testing team and validated by the development team and by the customers before starting the testing. Without these assumptions being validated, there cannot be any good conclusion that can be made out of non-functional testing. The following are some examples of basic assumptions that can be made about resources and configuration.
- The CPU can be fully utilized as long as it can be freed when a high priority job comes in.
- The available memory can be completely used by the product as long as the memory is relinquished when another job requires memory.
- The cost of adding CPU or memory is not that expensive as it was earlier. Hence resources can be added easily to get better performance as long as we can quantify and justify the benefits for each added resource.
- The product can generate many network packets as long as the network bandwidth and latency is available and does not cost much. There is a difference in this assumption that most of the packets generated are for LAN and not for WAN. In the case of WAN or routes involving multiple hops, the packets generated by the product need to be reduced.
- More disk space or the complete I/O bandwidth can be used for the product as long as they are available. While disk costs are getting cheaper, IO bandwidth is not.
- The customer gets the maximum return on investment (ROI) only if the resources such as CPU, disk, memory, and network are optimally used. So there is intelligence needed in the software to understand the server configuration and its usage.
- Graceful degradation in non-functional aspects can be expected when resources in the machine are also utilized for different activities in the server.
- Predictable variations in performance or scalability are acceptable for different configurations of the same product.
- Variation in performance and scalability is acceptable when some parameters are tuned, as long as we know the impact of adjusting each of those tunable parameters.
- The product can behave differently for non-functional factors for different configurations such as low-end and high-end servers as long as they support return on investment. This in fact motivates the customers to upgrade their resources.
Once such sample assumptions are validated by the development team and customers, then non-functional testing is conducted.
6.5.4 Scalability Testing
The objective of scalability testing is to find out the maximum capability of the product parameters. As the exercise involves finding the maximum, the resources that are needed for this kind of testing are normally very high. For example, one of the scalability test case could be finding out how many client machines can simultaneously log in to the server to perform some operations. In Internet space, some of the services can get up to a million access to the server. Hence, trying to simulate that kind of real-life scalability parameter is very difficult but at the same time very important.
At the beginning of the scalability exercise, there may not be an obvious clue about the maximum capability of the system. Hence a high-end configuration is selected and the scalability parameter is increased step by step to reach the maximum capability.
The design and architecture give the theoretical values, and requirements from the customers mention the maximum capability that is expected. The scalability exercise first verifies the lower number of these two. When the requirements from the customer are more than what design/architecture can provide, the scalability testing is suspended, the design is reworked, and scalability testing resumed to check the scalability parameters. Hence, the requirements, design, and architecture together provide inputs to the scalability testing on what parameter values are to be tested.
Contrary to other types of testing, scalability testing does not end when the requirements are met. The testing continues till the maximum capability of a scalable parameter is found out for a particular configuration. Having a highly scalable system that considers the future requirements of the customer helps a product to have a long lifetime. Otherwise, each time there are new requirements, a major redesign and overhaul takes place in the product and some stable features may stop working because of those changes, thus creating quality concerns. The cost and effort involved in such product developments are very high.
Failures during scalability test include the system not responding, or the system crashing, and so on. But whether the failure is acceptable or not has to be decided on the basis of business goals and objectives. For example, a product not able to respond to 100 concurrent users while its objective is to serve at least 200 users simultaneously is considered a failure. When a product expected to withstand only 100 users fails when its load is increased to 200, then it is a passed test case and an acceptable situation.
Scalability tests help in identifying the major bottlenecks in a product. When resources are found to be the bottlenecks, they are increased after validating the assumptions mentioned in Section 6.5.3. If the bottlenecks are in the product, they are fixed. However, sometimes the underlying infrastructure such as the operating system or technology can also become bottlenecks. In such cases, the product organization is expected to work with the OS and technology vendors to resolve the issues.
Scalability tests are performed on different configurations to check the product's behavior. For each configuration, data are collected and analyzed. An example of a data collection template is given below.
On completion of the tests, the data collected in the templates are analyzed and appropriate actions are taken. For example, if CPU utilization approaches to 100%, then another server is set up to share the load or another CPU is added to the server. If the results are successful, then the tests are repeated for 200 users and more to find the maximum limit for that configuration.
Some of the data needs analysis on a finer granularity. For example, if the maximum CPU utilization is 100% but only for a short time and if for the rest of the testing it remained at say 40%, then there is no point in adding one more CPU. But, the product still has to be analyzed for the sudden spike in the CPU utilization and it has to be fixed. This exercise requires the utilization data to be collected periodically as in the template given above. By looking at how often the spikes come about, and by analyzing the reasons for these spikes, an idea can be formed of where the bottleneck is and what the corrective action should be. Thus, merely increasing the resources is not an answer to achieving better scalability.

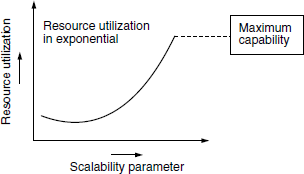
In scalability testing, the demand on resources tends to grow exponentially when the scalability parameter is increased. Resources growth is exponential when the scalability parameter increases. The scalability reaches a saturation point beyond which it cannot be improved (see Figure 6.3). This is called the maximum capability of a scalability parameter. Even though resources may be available, product limitation may not allow scalability. This is called a product bottleneck. Identification of such bottlenecks and removing them in the testing phase as early as possible is a basic requirement for resumption of scalability testing.
As explained earlier, scalability testing may also require an upgrading of resources. When there are no product bottlenecks, resources need to be upgraded to complete scalability testing. As explained earlier, when as the resources are upgraded, the return on investment study is carried out to find out if the returns justify the cost of upgrading the resources. The following are a few assumptions that can be kept in mind to carry out such an ROI study. The numbers and percentages used in the assumptions are only guideline values and will have to be modified depending on the product and context.
- Scalability should increase 50% when the number of CPUs is doubled from minimum requirement and 40% thereafter, till a given number of CPUs are added. Such a test will be applicable if the product is CPU intensive.
- Scalability should increase 40% when memory is doubled from the minimum requirement and 30% thereafter. This will be applicable if the product is memory intensive.
- Scalability should increase by at least 30% when the number of NIC cards or network bandwidth are doubled. This aspect has to be tested if the product is network intensive.
- Scalability should increase by at least 50% when the I/O bandwidth is doubled. This aspect has to be tested if the product is I/O intensive.
There can be some bottlenecks during scalability testing, which will require certain OS parameters and product parameters to be tuned. “Number of open files” and “Number of product threads” are some examples of parameters that may need tuning. When such tuning is performed, it should be appropriately documented. A document containing such tuning parameters and the recommended values of other product and environmental parameters for attaining the scalability numbers is called a sizing guide. This guide is one of the mandatory deliverables from scalability testing.
Fixing scalability defects may have some impact on the other nonfunctional aspects of the product. In such cases reliability testing (discussed in the next section) should take care of monitoring parameters like response time, throughput, and so on, and taking necessary action. Scalability should not be achieved at the cost of any other quality factor. Hence it is advised that the test engineer discusses the results with people who are performing other functional and non-functional testing and aggregate the findings.
Another important aspect of scalability is the experience associated with doing it. Scalability testing requires significant resources and is expensive. It is ideal that the scalability requirements be met in few iterations of testing and in quick time. If, during scalability testing, plenty of “tweaking” is required to be done to the product, tunable parameters, and resources, it indicate lack of planning and lack of understanding of product behavior. A detailed study of the product and a set of problems anticipated along with probable solutions is a prerequisite to getting a good experience/feel for such testing.
6.5.5 Reliability Testing
As defined earlier, reliability testing is done to evaluate the product's ability to perform its required functions under stated conditions for a specified period of time or for a large number of iterations. Examples of reliability include querying a database continuously for 48 hours and performing login operations 10,000 times.

The reliability of a product should not be confused with reliability testing. Producing a reliable product requires sound techniques, good discipline, robust processes, and strong management, and involves a whole gamut of activities for every role or function in a product organization. The reliability of a product deals with the different ways a quality product is produced, with very few defects by focusing on all the phases of product development and the processes. Reliability here is an all-encompassing term used to mean all the quality factors and functionality aspects of the product. This perspective is related more to the overall way the product is developed and has less direct relevance to testing. This product reliability is achieved by focusing on the following activities.
- Defined engineering processes Software reliability can be achieved by following clearly defined processes. The team is mandated to understand requirements for reliability right from the beginning and focuses on creating a reliable design upfront. All the activities (such as design, coding, testing, documentation) are planned, taking into consideration the reliability requirements of the software.
- Review of work products at each stage At the end of each stage of the product development life cycle, the work products produced are reviewed. This ensures early detection of error and their fixes as soon as they are introduced.
- Change management procedures Many errors percolate to the product due to improper impact analysis of changes made to the product. Changes received late during the product development life cycle can prove harmful. There may not be adequate time for regression testing and hence the product is likely to have errors due to changes. Hence, having a clearly defined change management procedure is necessary to deliver reliable software.
- Review of testing coverage Allocating time for the different phases and types of testing can help in catching errors as and when the product is being developed, rather than after the product is developed. All the testing activities are reviewed for adequacy of time allotted, test cases, and effort spent for each type of testing.
- Ongoing monitoring of the product Once the product has been delivered, it is analyzed proactively for any possibly missed errors. In this case the process as well as the product is fixed for missed defects. This prevents the same type of defects from reappearing.
Reliability testing, on the other hand, refers to testing the product for a continuous period of time. Performing good reliability testing does not ensure a reliable product on its own, as there are various other requirements for a product to be reliable, as mentioned in the earlier paragraphs. Reliability testing only delivers a “reliability tested product” but not a reliable product. The main factor that is taken into account for reliability testing is defects. The defects found through testing are closely monitored and they are compared with defects removed in the earlier phases and analyzed for why they were not caught earlier. Defects are tracked in order to guide the product as well as the test process, and also to determine the feasibility of release of the software. At the beginning of the project, a criterion for reliability is set for the maximum number of defects allowed. The actual number of defects found during various durations of running tests are compared to find out how well the product is doing compared with the criterion. This is depicted in Figure 6.4.

In Figure 6.4, it can be seen that the product is very close to meeting the reliability criteria towards the end. Figure 6.4 (a) suggests that the progress towards meeting the criteria is smooth, whereas in Figure 6.4 (b), the transition contains spikes. These spikes indicate that defects in the product for the reliability tests go up and down periodically. This may be a pointer to indicate that the defect fixes are creating new defects in the system. Analyzing the spikes and taking action to avoid the spikes, both from the process and from the product perspective, will help in meeting reliability criteria in an effective and repeatable way.
Reliability should not be achieved at the cost of some other quality factor. For example, when operations are repeated, they may fail sometimes due to race conditions. They may be resolved by introducing “sleep” between statements. This approach has a definite impact on performance. Hence, collecting and analyzing the data of reliability testing should also include other quality factors so that the impact can be analyzed in a holistic manner. Figure 6.5 gives an example of reliability impact on performance.
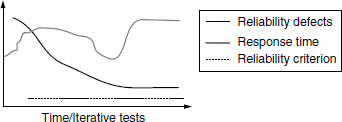
In the above graph, while reliability seems to approach the desired value, response time seems to be erratic. An effective analysis of the system test results should consider not only the (positive) aspect of the convergence of reliability criteria to the desired values but should also analyze why performance is erratic. Reliability testing brings out those errors which arise because of certain operations being repeated. Memory leak is a problem that is normally brought out by reliability testing. At the end of repeated operations sometimes the CPU may not get released or disk and network activity may continue. Hence, it is important to collect data regarding various resources used in the system before, during, and after reliability test execution, and analyze those results. Upon completion of the reliability tests, the resource utilization of the product should drop down to the pretest level of resource utilization. This verifies whether the resources are relinquished after the use by the product. The following table gives an idea on how reliability data can be collected.
The data for the above table is collected periodically and plotted in charts to analyze the behavior of each parameter. The failure data helps in plotting up the reliability chart explained above and are compared against the criteria. Resource data such as CPU, memory, and network data are collected to analyze the impact of reliability on resources.
Figure 6.6 illustrates resource utilization over a period of time the reliability tests are executed.
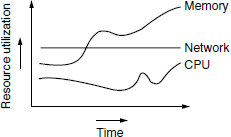

The chart in Figure 6.6 indicates that network utilization is constant during reliability testing whereas the memory and CPU utilization are going up. This needs analysis and the causes need to be fixed. The CPU and memory utilization must be consistent through out the test execution. If they keep on increasing, other applications on the machine can get affected; the machine may even run out of memory, hang, or crash, in which case the machine needs to be restarted. Memory buildup problems are common among most server software. These kinds of problems require a lot of time and effort to get resolved.
There are different ways of expressing reliability defects in charts.
- Mean time between failures is the average time elapsed from between successive product failures. Details on the time a product failed have to be maintained to understand its reliability for a specified time frame. For example, if the product fails, say, for every 72 hours, then appropriate decisions may have to be taken on backing out the current code, fixing the issue, and then deploying the same.
- Failure rate is provided as a function that gives the number of failures occurring per unit time (the graphs above depict this measurement).
- Mean time to discover the next K faults is the measure used to predict the average length of time until the next K faults are encountered. When a product is unstable, the time taken to find K faults will be less and when the product becomes stable, the time taken to find K faults will be more indicating an, increasing trend.
Use of real-life scenario yields more applicable results in reliability. Since reliability is defined as executing operations over a period of time, it should not be taken for granted that all operations need to be repeated. Some operations such as configuration, backup, and restore operations are performed rarely and they should not be selected for reliability. Rather, the operations that are highly and most frequently used and a mix of operations (scenarios) that reflect the daily activities of the customer should be considered for reliability testing. For example, log in-log out operations are important operations that need to be reliability tested. But no real user will keep on doing log in/log out as a sequence. Some operations are normally performed between log in and log out. Typically, a user may check a few mails, sending a few instant messages, and so on. Such a combination of activities represents a typical real-life customer usage. It is this type of combination of activities that must be subjected to reliability testing. When multiple users use the system from different clients, it reflects the scenario on the server side, where some operations are done repeatedly in a loop. Hence, selecting a test for reliability test should consider the scenario closer to real-life usage of the product.
To summarize, a “reliability tested product” will have the following characteristics.
- No errors or very few errors from repeated transactions.
- Zero downtime.
- Optimum utilization of resources.
- Consistent performance and response time of the product for repeated transactions for a specified time duration.
- No side-effects after the repeated transactions are executed.
6.5.6 Stress Testing
Stress testing is done to evaluate a system beyond the limits of specified requirements or resources, to ensure that system does not break. Stress testing is done to find out if the product's behavior degrades under extreme conditions and when it is denied the necessary resources. The product is over-loaded deliberately to simulate the resource crunch and to find out its behavior. It is expected to gracefully degrade on increasing the load, but the system is not expected to crash at any point of time during stress testing.

Stress testing helps in understanding how the system can behave under extreme (insufficient memory, inadequate hardware) and realistic situations. System resources upon being exhausted may cause such situations. This helps to know the conditions under which these tests fail so that the maximum limits, in terms of simultaneous users, search criteria, large number of transactions, and so on can be known.
Extreme situations such as a resource not being available can also be simulated. There are tools that can simulate “hogging of memory,” generate packets for flooding the network bandwidth, create processes that can take all the CPU cycles, keep reading/writing to disks, and so on. When these tools are run along with the product, the number of machines needed for stress testing can be reduced. However, the use of such tools may not bring out all stress-related problems of the product. Hence, after the simulation exercise (using the tools) is over, it is recommended that the tests should be repeated without the use of such tools.
The process, data collection, and analysis required for stress testing are very similar to those of reliability testing. The difference lies in the way the tests are run. Reliability testing is performed by keeping a constant load condition till the test case is completed; the load is increased only in the next iteration of the test case. In stress testing, the load is generally increased through various means such as increasing the number of clients, users, and transactions till and beyond the resources are completely utilized. When the load keeps on increasing, the product reaches a stress point when some of the transactions start failing due to resources not being available. The failure rate may go up beyond this point. To continue the stress testing, the load is slightly reduced below this stress point to see whether the product recovers and whether the failure rate decreases appropriately. This exercise of increasing/decreasing the load is performed two or three times to check for consistency in behavior and expectations.
Sometimes, the product may not recover immediately when the load is decreased. There are several reasons for this.
- Some transactions may be in the wait queue, delaying the recovery.
- Some rejected transactions many need to be purged, delaying the recovery.
- Due to failures, some clean-up operations may be needed by the product, delaying the recovery.
- Certain data structures may have got corrupted and may permanently prevent recovery from stress point.
The time required for the product to quickly recover from those failures is represented by MTTR (Mean time to recover). The recovery time may be different for different operations and they need to be calculated as appropriate. As explained earlier, several iterations of tests/different operations are conducted around the stress point and MTTR is calculated from the mean (average) and plotted as in Figure 6.8.

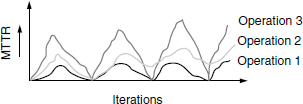
In Figure 6.8, the MTTR peaks and comes down as the load is increased/decreased around the stress point. It can also be noticed that Operation 1 is consistent with recovery time on all iterations (as it touches zero when load is reduced and mean time is consistent across iterations), whereas Operation 2 does not recover fully after first iteration, and recovery time slightly increases over iterations in Operation 3.
Instead of plotting MTTR for each operation, the average recovery time of all operations can be taken and the mean plotted.
As indicated earlier, the same tests, data collection sheets, and processes as used in reliability testing can be used for stress testing as well. One differentiating factor as explained earlier was variable load. Another factor that differentiates stress testing from reliability testing is mixed operations/tests. Different types of tests that utilize the resources are selected and used in stress testing. Hence, numerous tests of various types run on the system in stress testing. However, the tests that are run on the system to create stress point need to be closer to real-life scenario. The following guidelines can be used to select the tests for stress testing.
- Repetitive tests Executing repeated tests ensures that at all times the code works as expected. There are some operations that are repeatedly executed by the customer. A right mix of these operations and transactions need to be considered for stress testing.
- Concurrency Concurrent tests ensure that the code is exercised in multiple paths and simultaneously. The operations that are used by multiple users are selected and performed concurrently for stress testing.
- Magnitude This refers to the amount of load to be applied to the product to stress the system. It can be a single operation being executed for a large volume of users or a mix of operations distributed over different users. The operations that generate the amount of load needed are planned and executed for stress testing.
- Random variation As explained earlier, stress testing depends on increasing/decreasing variable load. Tests that stress the system with random inputs (in terms of number of users, size of data), at random instances and random magnitude are selected and executed as part of stress testing.
Defects that emerge from stress testing are usually not found from any other testing. Defects like memory leaks are easy to detect but difficult to analyze due to varying load and different types/mix of tests executed. Hence, stress tests are normally performed after reliability testing. To detect stress-related errors, tests need to be repeated many times so that resource usage is maximized and significant errors can be noticed. This testing helps in finding out concurrency and synchronization issues like deadlocks, thread leaks, and other synchronization problems.
6.5.7 Interoperability Testing
Interoperability testing is done to ensure the two or more products can exchange information, use information, and work properly together.
Systems can be interoperable unidirectional (the exchange of information is one way) or bi-directional (exchange of information in both ways). For example, the text available in a text editor can be exported into a Microsoft Word application using the “Insert-<File” option. But a picture available in Microsoft Word cannot be exported into text editor. This represents one-way interoperability. The two-way interoperability is represented by exchange of information between email management (Microsoft Outlook) and Microsoft Word, where information can be cut and pasted on both directions.
The terms “interoperability” and “integration” are used interchangeably but this is incorrect. Integration is a method and interoperability is the end result. Integration pertains to only one product and defines interfaces for two or more components. Unless two or more products are designed for exchanging information, interoperability cannot be achieved. As explained in the chapter on integration testing, there is only a thin line of difference between various types of testing. It is reproduced in Table 6.4 with more explanations and specific context.
Table 6.4 Where different types of testing belong.
| Description of testing | Belongs to |
|---|---|
| Testing interfaces between product components | Integration testing |
| Testing information exchange between two or more products | Interoperability testing |
| Testing the product with different infrastructure pieces such as OS, Database, Network | Compatibility testing |
| Testing whether the objects/binaries created with old version of the product work with current version | Backward compatibility testing |
| Testing whether the product interfaces work with future releases of infrastructure pieces | Forward compatibility testing |
| Testing whether the API interfaces of the product work with custom-developed components | API/integration testing |
Interoperability attains more importance in the context of Internet, which is characterized by a seamless co-existence and inter-operation of multiple computers and multiple pieces of software. Hence, it is essential for more and more products to be interoperable so that they can communicate with almost all the operating systems, browsers, development tools, compilers, applications, and so on. Products need to prove that they are interoperable to whatever degree possible so that they can be integrated with other systems.
There are no real standard methodologies developed for interoperability testing. There are different variants of interoperable testing one system with another, one to many, and multi-dimensional interoperability testing. Following technical standards like SOAP (Simple object access protocol), e×tensible Markup Language (×ML) and some more from W3C (World Wide Web Consortium) typically aid in the development of products using common standards and methods. But standards conformance is not enough for interoperability testing, as standards alone do not ensure consistent information exchange and work flow. Some popular products may not have implemented all the standards. But the product under test needs to interoperate with those popular products due to pressing business need.
The following are some guidelines that help in improving interoperability.
- Consistency of information flow across systems When an input is provided to the product, it should be understood consistently by all systems. This would enable a smooth, correct response to be sent back to the user. For example, when data structures are used to pass information across systems, the structure and interpretation of these data structures should be consistent across the system.
- Changes to data representation as per the system requirements When two different systems are integrated to provide a response to the user, data sent from the first system in a particular format must be modified or adjusted to suit the next system's requirement. This would help the request to be understood by the current system. Only then can an appropriate response be sent to the user.
For example, when a littile end-ian machine passes data to a big end-ian machine, the byte ordering would have to be changed.
- Correlated interchange of messages and receiving appropriate responses When one system sends an input in the form of a message, the next system is in the waiting mode or listening mode to receive the input. When multiple machines are involved in information exchange, there could be clashes, wrong response, deadlocks, or delays in communication. These aspects should be considered in architecting/designing the product, rather than leave it to be found as a surprise during the later phases.
- Communication and messages When a message is passed on from a system A to system B, if any and the message is lost or gets garbled the product should be tested to check how it responds to such erroneous messages. The product must not crash or hang. It should give useful error messages to the user requesting him to wait for sometime until it recovers the connection. As multiple products are involved, a generic error message such as “Error from remote machine” will be misleading and not value adding. The user need not know where the message is coming from but needs to understand the cause of the message and the necessary corrective action.
- Meeting quality factors When two or more products are put together, there is an additional requirement of information exchange between them. This requirement should not take away the quality of the products that would have been already met individually by the products. Interoperability testing needs to verify this perspective.
The responsibility for interoperability lies more on the architecture, design, and standards of various products involved in the domain. Hence, testing for interoperability yields better results only if the requirements are met by development activities such as architecture, design, and coding. Interoperability testing should be restricted to qualify the information exchange rather than finding defects and fixing them one after another.
Interoperability among products is a collective responsibility and the effort of many product organizations. All product organizations are expected to work together to meet the purpose of interoperability. There are standards organizations that focus on interoperability standards which help the product organizations to minimize the effort involved in collaborations. They also assist in defining, implementing, and certifying the standards implementation for interoperability.
6.6 ACCEPTANCE TESTING
Acceptance testing is a phase after system testing that is normally done by the customers or representatives of the customer. The customer defines a set of test cases that will be executed to qualify and accept the product. These test cases are executed by the customers themselves to quickly judge the quality of the product before deciding to buy the product. Acceptance test cases are normally small in number and are not written with the intention of finding defects. More detailed testing (which is intended to uncover defects) is expected to have been completed in the component, integration, and system testing phases, prior to product delivery to the customer. Sometimes, acceptance test cases are developed jointly by the customers and product organization. In this case, the product organization will have complete understanding of what will be tested by the customer for acceptance testing. In such cases, the product organization tests those test cases in advance as part of the system test cycle itself to avoid any later surprises when those test cases are executed by the customer.
In cases where the acceptance tests are performed by the product organization alone, acceptance tests are executed to verify if the product meets the acceptance criteria defined during the requirements definition phase of the project. Acceptance test cases are black box type of test cases. They are directed at verifying one or more acceptance criteria.
Acceptance tests are written to execute near real-life scenarios. Apart from verifying the functional requirements, acceptance tests are run to verify the non-functional aspects of the system also.
Acceptance test cases failing in a customer site may cause the product to be rejected and may mean financial loss or may mean rework of product involving effort and time.
6.6.1 Acceptance Criteria
6.6.1.1 Acceptance criteria-Product acceptance
During the requirements phase, each requirement is associated with acceptance criteria. It is possible that one or more requirements may be mapped to form acceptance criteria (for example, all high priority requirements should pass 100%). Whenever there are changes to requirements, the acceptance criteria are accordingly modified and maintained.
Acceptance testing is not meant for executing test cases that have not been executed before. Hence, the existing test cases are looked at and certain categories of test cases can be grouped to form acceptance criteria (for example, all performance test cases should pass meeting the response time requirements).
Testing for adherence to any specific legal or contractual terms is included in the acceptance criteria. Testing for compliance to specific laws like Sarbanes–Oxley can be part of the acceptance criteria.
6.6.1.2 Acceptance criteria—Procedure acceptance
Acceptance criteria can be defined based on the procedures followed for delivery. An example of procedure acceptance could be documentation and release media. Some examples of acceptance criteria of this nature are as follows.
- User, administration and troubleshooting documentation should be part of the release.
- Along with binary code, the source code of the product with build scripts to be delivered in a CD.
- A minimum of 20 employees are trained on the product usage prior to deployment.
These procedural acceptance criteria are verified/tested as part of acceptance testing.
6.6.1.3 Acceptance criteria–Service level agreements
Service level agreements (SLA) can become part of acceptance criteria. Service level agreements are generally part of a contract signed by the customer and product organization. The important contract items are taken and verified as part of acceptance testing. For example, time limits to resolve those defects can be mentioned part of SLA such as
- All major defects that come up during first three months of deployment need to be fixed free of cost;
- Downtime of the implemented system should be less than 0.1%;
- All major defects are to be fixed within 48 hours of reporting.
With some criteria as above (except for downtime), it may look as though there is nothing to be tested or verified. But the idea of acceptance testing here is to ensure that the resources are available for meeting those SLAs.
6.6.2 Selecting Test Cases for Acceptance Testing
As mentioned earlier, the test cases for acceptance testing are selected from the existing set of test cases from different phases of testing. This section gives some guideline on what test cases can be included for acceptance testing.
- End-to-end functionality verification Test cases that include the end-to-end functionality of the product are taken up for acceptance testing. This ensures that all the business transactions are tested as a whole and those transactions are completed successfully. Real-life test scenarios are tested when the product is tested end-to-end.
- Domain tests Since acceptance tests focus on business scenarios, the product domain tests are included. Test cases that reflect business domain knowledge are included.
- User scenario tests Acceptance tests reflect the real-life user scenario verification. As a result, test cases that portray them are included.
- Basic sanity tests Tests that verify the basic existing behavior of the product are included. These tests ensure that the system performs the basic operations that it was intended to do. Such tests may gain more attention when a product undergoes changes or modifications. It is necessary to verify that the existing behavior is retained without any breaks.
- New functionality When the product undergoes modifications or changes, the acceptance test cases focus on verifying the new features.
- A few non-functional tests Some non-functional tests are included and executed as part of acceptance testing to double-check that the non-functional aspects of the product meet the expectations.
- Tests pertaining to legal obligations and service level agreements Tests that are written to check if the product complies with certain legal obligations and SLAs are included in the acceptance test criteria.
- Acceptance test data Test cases that make use of customer real-life data are included for acceptance testing.
6.6.3 Executing Acceptance Tests
As explained before, sometimes the customers themselves do the acceptance tests. In such cases, the job of the product organization is to assist the customers in acceptance testing and resolve the issues that come out of it. If the acceptance testing is done by the product organization, forming the acceptance test team becomes an important activity.
Acceptance testing is done by the customer or by the representative of the customer to check whether the product is ready for use in the real-life environment.
An acceptance test team usually comprises members who are involved in the day-to-day activities of the product usage or are familiar with such scenarios. The product management, support, and consulting team, who have good knowledge of the customers, contribute to the acceptance testing definition and execution. They may not be familiar with the testing process or the technical aspect of the software. But they know whether the product does what it is intended to do. An acceptance test team may be formed with 90% of them possessing the required business process knowledge of the product and 10% being representatives of the technical testing team. The number of test team members needed to perform acceptance testing is very less, as the scope and effort involved in acceptance testing is not much when compared to other phases of testing.
As mentioned earlier, acceptance test team members may or may not be aware of testing or the process. Hence, before acceptance testing, appropriate training on the product and the process needs to be provided to the team. This training can be given to customers and other support functions irrespective of who does the acceptance tests, as the effort involved is the same. The acceptance test team may get the help of team members who developed/tested the software to obtain the required product knowledge. There could also be in-house training material that could serve the purpose.
The role of the testing team members during and prior to acceptance test is crucial since they may constantly interact with the acceptance team members. Test team members help the acceptance members to get the required test data, select and identify test cases, and analyze the acceptance test results. During test execution, the acceptance test team reports its progress regularly. The defect reports are generated on a periodic basis.
Defects reported during acceptance tests could be of different priorities. Test teams help acceptance test team report defects. Showstopper and high-priority defects are necessarily fixed before software is released. In case major defects are identified during acceptance testing, then there is a risk of missing the release date. When the defect fixes point to scope or requirement changes, then it may either result in the extension of the release date to include the feature in the current release or get postponed to subsequent releases. All resolution of those defects (and unresolved defects) are discussed with the acceptance test team and their approval is obtained for concluding the completion of acceptance testing.
6.7 SUMMARY OF TESTING PHASES
The purpose of this section is to summarize all the phases of testing and testing types we have seen so far in different chapters.
6.7.1 Multiphase Testing Model
Various phases of testing have been discussed in this chapter and previous chapters. When these phases of testing are performed by different test teams, the effectiveness of the model increases. However the big question in front of this model is in knowing when to start and finish each of the testing phases. This section addresses some guidelines that can be used to start/complete each of the testing phases. The transition to each of the testing phase is determined by a set of entry and exit criteria. The objective of the entry and exit criteria is to allow parallelism in testing and, at the same time, give importance to the quality of the product to decide the transitions. Having very mild entry criteria or very strict entry criteria have their own disadvantages. When the criteria are too mild, all the testing phases start at the same time representing one extreme where the same problem is reported by multiple teams, increasing the duplication of defects and making multiple teams wait for bug fixes. This results in releasing a bad quality product and lack of ownership on issues. It also creates a repetition of test cases at various phases when a new build arrives. It may prove counter-productive to the next phase of testing in case the quality requirements of that phase are not met. Having too strict entry criteria solves this problem but a lack of parallelism in this case creates a delay in the release of the product. These two extreme situations are depicted in the Figure 6.9. The coloured figure is available on Illustrations.

The right approach is to allow product quality to decide when to start a phase and entry criteria should facilitate both the quality requirements for a particular phase and utilize the earliest opportunity for starting a particular phase. The team performing the earlier phase has the ownership to meet the entry criteria of the following phase. This is depicted in Figure 6.10. The coloured figure is available on Illustrations.

Some sample entry and exit criteria are given in tables 6.5, 6.6, and 6.7. Please note that there are no entry and exit criteria for unit testing as it starts soon after the code is ready to compile and the entry criteria for component testing can serve as exit criteria for unit testing. However, unit test regression continues till the product is released. The criteria given below enables the product quality to decide on starting/completing test phases at the same time and creates many avenues for allowing parallelism among test phases.
Table 6.5 Sample entry and exit criteria for component testing.
| Entry criteria | Exit criteria |
|---|---|
Component testing Periodic unit test progress report showing 70% completion rate |
No extreme and critical outstanding defects in features |
Stable build (installable) with basic features working |
All 100% component test cases executed with at least 98% pass ratio |
Component test cases ready for execution |
Component test progress report (periodic) and defect trend sorted based on features and analyzed. |
Component level performance and load testing report and analysis of the same. |
Table 6.6 Sample entry and exit criteria for integration testing.
| Entry criteria | Exit criteria |
|---|---|
Integration testing Periodic component test progress report (with at least 50% completion ratio) with at least 70% pass rate |
No extreme and critical defects outstanding to be fixed |
Stable build (installable/upgradeable) with all features integrated |
All 100% integration test cases executed with at least 98% pass ratio |
Defect arrival showing downward trend |
Integration test progress report showing good progress and defects showing consistent downward trend |
Performance, load test report for all critical features within acceptable range |
|
Product in release format (including documents, media, and so on) |
Table 6.7 Sample entry and exit criteria for system and acceptance testing.
| Entry criteria | Exit criteria |
|---|---|
Acceptance testing Periodic integration test progress report with at least 50% pass rate for starting system testing, 90% pass rate for starting acceptance testing |
All 100% system test cases executed with at least 98% pass ratio All 100% acceptance test cases executed with 100% pass rate |
Stable build (production format) with all features integrated |
Test summary report all phases consolidated (periodic) and they are analyzed and defect trend showing downward trend for last four weeks |
Defect arrival trend showing downward movement |
Metrics (quality and progress metrics) showing product readiness for release |
No extreme and critical defects outstanding |
Performance, load test report for all critical features, system |
6.7.2 Working Across Multiple Releases
As explained earlier, separate test teams for each phase of testing increases effectiveness. It also creates an opportunity for a test team to work on multiple releases at the same time. This way the test teams can be utilized completely. For example, when exit criteria is met for component test team, they can get on to next release of component testing while the integration and system test teams are focusing the on current release. This allows a part of the test team to work on the next release while the testing for current release is in progress. This is one way to reduce the overall elapsed time for releases, exploiting the overlap and parallelism among the test phases. Figure 6.11 depicts this concept. This figure takes into account only a few major activities of a testing team such as automation, test case creation, and test execution to explain the concept. The coloured figure is available on Illustrations.

6.7.3 Who Does What and When
Table 6.8 gives an overview of when what tests are executed.


- Full
- Partial
There are several terminologies and definitions that associated with system and acceptance testing. The glossary of terms found in [IEEE-1994] is a step closer to what is being discussed as a topic and definition in this chapter. This chapter tries to take a practical approach with several types of testing. The methodology for reliability testing in [UMES-2002] is used in this chapter with more examples and details.
- Which category of system testing applies to each of the following cases:
- A customer has given his transaction load and throughput requirements. You are to recommend an appropriate hardware and software configuration for the customer.
- Your product is a web-based product with a highly seasonal usage. You want to understand the product behavior and performance even at loads much more than the maximum expected usage so as to prepare for future expansion.
- Your product is expected to run continuously and never stop functioning.
- You have bought a special reporting software that runs on top of an Oracle database. Recently Oracle came up with a new version and the reporting software should be tested to work with this new version.
- ou are to measure and publish performance characteristics of your product:
- Classify the following as functional and non-functional testing:
- Testing of documentation of the product to match the product behavior
- Verification that a payroll system satisfies local tax laws
- Testing of the screens for user friendliness
- Performance qualification of a product
- Ensuring a certain percentage of code coverage for a product
- Which of the following are “product level tests cases” as explained in the text? If not, identify which level it belongs
- This test is to ensure that the customizations made on top of an ERP package which in turn runs on a particular version of a database are working correctly.
- In a payroll system, tests are done only for the tax calculation module.
- In a database package, there are options to specify different sort algorithms. The correct behavior of each of these algorithms has to be verified.
- Consider a revolutionary, path-breaking product that comes about which opens up completely new methods of usage that the users are not used to. How would you characterize “acceptance testing” in such a case? What are some of the challenges do you foresee in such acceptance testing? How would you overcome such challenges?
- You are advising a customer, “based on the tests conducted, the memory should be doubled and the network bandwidth has to be quadrupled.” What kind of objective data would you give to substantiate your recommendation? If the customer asks you to justify your answer in a tabular or graphical form, stating all your assumptions, how would you go about?
- Your initial tests indicated that a product went through a spike in CPU usage, but in general otherwise, the CPU usage was below average. What tests would you do to further narrow down and identify the cause for the spike?
- Which of the following test scenarios would you subject to stress tests:
- Users making ad hoc queries to a database
- Students logging on to find results of examinations on the net on the result day
- Users in a customer service center taking orders for various customers, entering credit notes, handling complaints, etc.
- In the Internet space, we talk of “e services,” wherein, there are different “services” registered on the net (like travel service, hotel booking services, etc.). Consider the testing challenges of putting together a “bigger” service composed of these atomic services. For example, consider putting together a comprehensive travel booking that uses airline booking from (the existing) travel service, and from the (existing) hotel booking service. What kind of testing challenges should you expect when you put together and use such composite services? Consider all phases/types of testing, given that a user who buys your comprehensive service may hold you responsible for the end-to-end functionality.
- Consider a piece of embedded software that is part of a consumer gadget like a TV. Which of the types of system testing discussed in this chapter would you perform and at what times? What extra challenges would you foresee vis à vis say testing a conventional financial application or a system software product like a database or operating system?