
Chapter 7
Performance Testing
In this chapter—
7.1 INTRODUCTION
In this Internet era, when more and more of business is transacted online, there is a big and understandable expectation that all applications run as fast as possible. When applications run fast, a system can fulfill the business requirements quickly and put it in a position to expand its business and handle future needs as well. A system or a product that is not able to service business transactions due to its slow performance is a big loss for the product organization, its customers, and its customers’ customers. For example, it is estimated that 40% of online marketing/shopping for consumer goods in the USA happens over a period of November—December. Slowness or lack of response during this period may result in losses to the tune of several million dollars to organizations. In yet another example, when examination results are published on the Internet, several hundreds of thousands of people access the educational websites within a very short period. If a given website takes a long time to complete the request or takes more time to display the pages, it may mean a lost business opportunity, as the people may go to other websites to find the results. Hence, performance is a basic requirement for any product and is fast becoming a subject of great interest in the testing community.
7.2 FACTORS GOVERNING PERFORMANCE TESTING
There are many factors that govern performance testing. It is critical to understand the definition and purpose of these factors prior to understanding the methodology for performance testing and for analyzing the results.
As explained in the previous section, a product is expected, to handle multiple transactions in a given period. The capability of the system or the product in handling multiple transactions is determined by a factor called throughput. Throughput represents the number of requests/business transactions processed by the product in a specified time duration. It is important to understand that the throughput (that is, the number of transactions serviced by the product per unit time) varies according to the load the product is subjected to. Figure 7.1 is an example of the throughput of a system at various load conditions. The load to the product can be increased by increasing the number of users or by increasing the number of concurrent operations of the product.
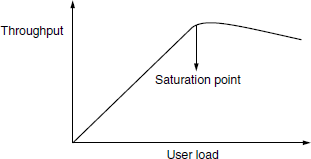
In the above example, it can be noticed that initially the throughput keeps increasing as the user load increases. This is the ideal situation for any product and indicates that the product is capable of delivering more when there are more users trying to use the product. In the second part of the graph, beyond certain user load conditions (after the bend), it can be noticed that the throughput comes down. This is the period when the users of the system notice a lack of satisfactory response and the system starts taking more time to complete business transactions. The “optimum throughput” is represented by the saturation point and is the one that represents the maximum throughput for the product.
Throughput represents how many business transactions can be serviced in a given duration for a given load. It is equally important to find out how much time each of the transactions took to complete. As was explained in the first section, customers might go to a different website or application if a particular request takes more time on this website or application. Hence measuring “response time” becomes an important activity of performance testing. Response time can be defined as the delay between the point of request and the first response from the product. In a typical client-server environment, throughput represents the number of transactions that can be handled by the server and response time represents the delay between the request and response.
In reality, not all the delay that happens between the request and the response is caused by the product. In the networking scenario, the network or other products which are sharing the network resources, can cause the delays. Hence, it is important to know what delay the product causes and what delay the environment causes. This brings up yet another factor for performance—latency. Latency is a delay caused by the application, operating system, and by the environment that are calculated separately. To explain latency, let us take an example of a web application providing a service by talking to a web server and a database server connected in the network. See Figure 7.2.
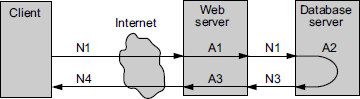
In the above example, latency can be calculated for the product that is running on the client and for the network that represents the infrastructure available for the product. Thus by using the above picture, latency and response time can be calculated as
Network latency = N1 + N2 + N3 + N4
Product latency = A1 + A2 + A3
Actual response time = Network latency + Product latency
The discussion about the latency in performance is very important, as any improvement that is done in the product can only reduce the response time by the improvements made in A1, A2, and A3. If the network latency is more relative to the product latency and if that is affecting the response time, then there is no point in improving the product performance. In such a case it will be worthwhile looking at improving the network infrastructure. In cases where network latency is more or can not be improved, the product can use intelligent approaches of caching and sending multiple requests in one packet and receiving responses as a bunch.
The next factor that governs the performance testing is tuning. Tuning is a procedure by which the product performance is enhanced by setting different values to the parameters (variables) of the product, operating system, and other components. Tuning improves the product performance without having to touch the source code of the product. Each product may have certain parameters or variables that can be set a run time to gain optimum performance. The default values that are assumed by such product parameters may not always give optimum performance for a particular deployment. This necessitates the need for changing the values of parameters or variables to suit the deployment or for a particular configuration. Doing performance testing, tuning of parameters is an important activity that needs to be done before collecting actual numbers.
Yet another factor that needs to be considered for performance testing is performance of competitive products. A very well-improved performance of a product makes no business sense if that performance does not match up to the competitive products. Hence it is very important to compare the throughput and response time of the product with those of the competitive products. This type of performance testing wherein competitive products are compared is called benchmarking. No two products are the same in features, cost, and functionality. Hence, it is not easy to decide which parameters must be compared across two products. A careful analysis is needed to chalk out the list of transactions to be compared across products, so that an apples-to-apples comparison becomes possible. This produces meaningful analysis to improve the performance of the product with respect to competition.
One of the most important factors that affect performance testing is the availability of resources. A right kind of configuration (both hardware and software) is needed to derive the best results from performance testing and for deployments. The exercise to find out what resources and configurations are needed is called capacity planning. The purpose of a capacity planning exercise is to help customers plan for the set of hardware and software resources prior to installation or upgrade of the product. This exercise also sets the expectations on what performance the customer will get with the available hardware and software resources.
The testing performed to evaluate the response time, throughput, and utilization of the system, to execute its required functions in comparison with different versions of the same product(s) or a different competitive product(s) is called performance testing.
To summarize, performance testing is done to ensure that a product
- processes the required number of transactions in any given interval (throughput);
- is available and running under different load conditions (availability);
- responds fast enough for different load conditions (response time);
- delivers worthwhile return on investment for the resources—hardware and software—and deciding what kind of resources are needed for the product for different load conditions (capacity planning); and
- is comparable to and better than that of the competitors for different parameters (competitive analysis and benchmarking).
7.3 METHODOLOGY FOR PERFORMANCE TESTING
Performance testing is complex and expensive due to large resource requirements and the time it takes. Hence, it requires careful planning and a robust methodology. Performance testing is ambiguous because of the different people who are performing the various roles having different expectations. Additionally, a good number of defects that get uncovered during performance testing may require design and architecture change. Finally, a fix for a performance defect may even cause some functionality to stop working, thereby requiring more effort during regression. For these reasons, this section focuses on various steps and guidelines for doing a performance testing in a methodical way. A methodology for performance testing involves the following steps.
- Collecting requirements
- Writing test cases
- Automating performance test cases
- Executing performance test cases
- Analyzing performance test results
- Performance tuning
- Performance benchmarking
- Recommending right configuration for the customers (Capacity Planning)
7.3.1 Collecting Requirements
Collecting requirements is the first step in planning the performance testing. Typically, functionality testing has a definite set of inputs and outputs, with a clear definition of expected results. In contrast, performance testing generally needs elaborate documentation and environment setup and the expected results may not well known in advance. As a result of these differences, collecting requirements for performance testing presents some unique challenges.
Firstly, a performance testing requirement should be testable—not all features/functionality can be performance tested. For example, a feature involving a manual intervention cannot be performance tested as the results depend on how fast a user responds with inputs to the product. Aperformance test can only be carried out for a completely automated product.
Secondly, a performance-testing requirement needs to clearly state what factors needs to be measured and improved. As discussed in the previous section, performance has several factors such as response time, latency, throughput, resource utilization, and others. Hence, a requirement needs to associate the factors or combination of factors that have to be measured and improved as part of performance testing.
Lastly, performance testing requirement needs to be associated with the actual number or percentage of improvement that is desired. For example, if a business transaction, say ATM money withdrawal, should be completed within two minutes, the requirement needs to document the actual response time expected. Only then can the pass/fail status of a performance testing be concluded. Not having the expected numbers for the appropriate parameter (response time, throughput, and so on) renders performance testing completely futile, as there is no quantitative measure of success and nothing can be concluded or improved in the end.
Given the above challenges, a key question is how requirements for performance testing can be derived. There are several sources for deriving performance requirements. Some of them are as follows.
- Performance compared to the previous release of the same product A performance requirement can be something like “an ATM withdrawal transaction will be faster than the previous release by 10%.”
- Performance compared to the competitive product(s) A performance requirement can be documented as “ATM withdrawal will be as fast as or faster than competitive product XYZ.”
- Performance compared to absolute numbers derived from actual need A requirement can be documented such as “ATM machine should be capable of handling 1000 transactions per day with each transaction not taking more than a minute.”
- Performance numbers derived from architecture and design The architect or a designer of a product would normally be in a much better position than anyone else to say what is the performance expected out of the product. The architecture and design goals are based on the performance expected for a particular load. Hence, there is an expectation that the source code is written in such a way that those numbers are met.
There are two types of requirements performance testing focuses on— generic requirements and specific requirements. Generic requirements are those that are common across all products in the product domain area. All products in that area are expected to meet those performance expectations. For some of the products they are mandated by SLAs (Service Level Agreements) and standards. The time taken to load a page, initial response when a mouse is clicked, and time taken to navigate between screens are some examples of generic requirements. Specific requirements are those that depend on implementation for a particular product and differ from one product to another in a given domain. An example of specific performance requirement is the time taken to withdraw cash in an ATM. During performance testing both generic and specific requirements need to be tested.
As discussed earlier, the requirements for performance testing also include the load pattern and resource availability and what is expected from the product under different load conditions. Hence, while documenting the expected response time, throughput, or any other performance factor, it is equally important to map different load conditions as illustrated in the example in Table 7.1.

Beyond a particular load, any product shows some degradation in performance. While it is easy to understand this phenomenon, it will be very difficult to do a performance test without knowing the degree of degradation with respect to load conditions. Massive degradation in performance beyond a degree is not acceptable by users. For example, ATM cash withdrawal taking one hour to complete a transaction (regardless of reason or load) is not acceptable. In such a case, the customer who requested the transaction would have waited and left the ATM and the money may get disbursed to the person who reaches the ATM next! The performance values that are in acceptable limits when the load increases are denoted by a term called “graceful performance degradation.” A performance test conducted for a product needs to validate this graceful degradation also as one of the requirement.
7.3.2 Writing Test Cases
The next step involved in performance testing is writing test cases. As was briefly discussed earlier, a test case for performance testing should have the following details defined.
- List of operations or business transactions to be tested
- Steps for executing those operations/transactions
- List of product, OS parameters that impact the performance testing, and their values
- Loading pattern
- Resource and their configuration (network, hardware, software configurations)
- The expected results (that is, expected response time, throughput, latency)
- The product versions/competitive products to be compared with and related information such as their corresponding fields (steps 2-6 in the above list)
Performance test cases are repetitive in nature. These test cases are normally executed repeatedly for different values of parameters, different load conditions, different configurations, and so on. Hence, the details of what tests are to be repeated for what values should be part of the test case documentation.
While testing the product for different load patterns, it is important to increase the load or scalability gradually to avoid any unnecessary effort in case of failures. For example, if an ATM withdrawal fails for ten concurrent operations, there is no point in trying it for 10, 000 operations. The effort involved in testing for 10 concurrent operations may be several times lesser than that of testing for 10, 000 operations. Hence, a methodical approach is to gradually improve the concurrent operations by say 10, 100, 1000, 10, 000, and so on rather than trying to attempt 10, 000 concurrent operations in the first iteration itself. The test case documentation should clearly reflect this approach.
Performance testing is a laborious process involving time and effort. Not all operations/business transactions can be included in performance testing. Hence, all test cases that are part of performance testing have to be assigned different priorities so that high priority test cases can be completed before others. The priority can be absolute as indicated by the customers or relative within the test cases considered for performance testing. Absolute priority is indicated by the requirements and the test team normally assigns relative priority. While executing the test cases, the absolute and relative priorities are looked at and the test cases are sequenced accordingly.
7.3.3 Automating Performance Test Cases
Automation is an important step in the methodology for performance testing. Performance testing naturally lends itself to automation due to the following characteristics.
- Performance testing is repetitive.
- Performance test cases cannot be effective without automation and in most cases it is, in fact, almost impossible to do performance testing without automation.
- The results of performance testing need to be accurate, and manually calculating the response time, throughput, and so on can introduce inaccuracy.
- Performance testing takes into account several factors. There are far too many permutations and combination of those factors and it will be difficult to remember all these and use them if the tests are done manually.
- The analysis of performance results and failures needs to take into account related information such as resource utilization, log files, trace files, and so on that are collected at regular intervals. It is impossible to do this testing and perform the book-keeping of all related information and analysis manually.
As we will see in the chapter on test automation (Chapter 16), there should not be any hard coded data in automated scripts for performance testing. Such hard coding may impact the repeatability nature of test cases and may require change in automation script, taking more time and effort.
End-to-end automation is required for performance testing. Not only the steps of the test cases, but also the setup required for the test cases, setting different values to parameters, creating different load conditions, setting up and executing the steps for operations/transactions of competitive product, and so on have to be included as part of the automation script. While automating performance test cases, it is important to use standard tools and practices. Since some of the performance test cases involve comparison with the competitive product, the results need to be consistent, repeatable, and accurate due to the high degree of sensitivity involved.
7.3.4 Executing Performance Test Cases
Performance testing generally involves less effort for execution but more effort for planning, data collection, and analysis. As discussed earlier, 100% end-to-end automation is desirable for performance testing and if that is achieved, executing a performance test case may just mean invoking certain automated scripts. However, the most effort-consuming aspect in execution is usually data collection. Data corresponding to the following points needs to be collected while executing performance tests.
- Start and end time of test case execution
- Log and trace/audit files of the product and operating system (for future debugging and repeatability purposes)
- Utilization of resources (CPU, memory, disk, network utilization, and so on) on a periodic basis
- Configuration of all environmental factors (hardware, software, and other components)
- The response time, throughput, latency, and so on as specified in the test case documentation at regular intervals
Another aspect involved in performance test execution is scenario testing. A set of transactions/operations that are usually performed by the user forms the scenario for performance testing. This particular testing is done to ensure whether the mix of operations/transactions concurrently by different users/machines meets the performance criteria. In real life, not all users perform the same operation all the time and hence these tests are performed. For example, not all users withdraw cash from an ATM; some of them query for account balance; some make deposits, and so on. In this case this scenario (with different users executing different transactions) is executed with the existing automation that is available and related data is collected using the existing tools.
What performance a product delivers for different configurations of hardware and network setup, is another aspect that needs to be included during execution. This requirement mandates the need for repeating the tests for different configurations. This is referred to as configuration performance tests. This test ensures that the performance of the product is compatible with different hardware, utilizing the special nature of those configurations and yielding the best performance possible. For a given configuration, the product has to give the best possible performance, and if the configuration is better, it has to get even better. Table 7.2 illustrates an example of this type of test. The performance test case is repeated for each row in the following table and factors such as response time and throughput are recorded and analyzed.
Table 7.2 Sample configuration performance test.
| Transaction | Number of users | Test environment |
|---|---|---|
| Querying ATM account balance | 20 |
RAM 512 MB, P4 Dual Processor; Operating system—Windows NT Server |
| ATM cash withdrawal | 20 |
RAM 128 MB, P4 Single Processor Operating system—Windows 98 |
| ATM user profile query | 40 |
RAM 256 MB, P3 Quad Processor Operating system—Windows 2000 |
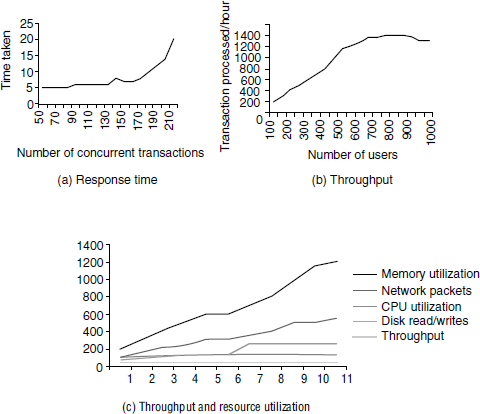
Once performance tests are executed and various data points are collected, the next step is to plot them. As explained earlier, performance test cases are repeated for different configurations and different values of parameters. Hence, it makes sense to group them and plot them in the form of graphs and charts. Plotting the data helps in making a quick analysis which would otherwise be difficult to do with only the raw data. Figure 7.3 above illustrates how performance data can be plotted. The coloured figure is available on Illustrations.
7.3.5 Analyzing the Performance Test Results
Analyzing the performance test results require multi-dimensional thinking. This is the most complex part of performance testing where product knowledge, analytical thinking, and statistical background are all absolutely essential.
Before analyzing the data, some calculations of data and organization of the data are required. The following come under this category.
- Calculating the mean of the performance test result data
- Calculating the standard deviation
- Removing the noise (noise removal) and re-plotting and recalculating the mean and standard deviation
- In terms of caching and other technologies implemented in the product, the data coming from the cache need to be differentiated from the data that gets processed by the product, and presented
- Differentiating the performance data when the resources are available completely as against when some background activities were going on.
For publishing the performance numbers, there is one basic expectation—performance numbers are to be reproducible for the customers. To ensure this, all performance tests are repeated multiple times and the average/mean of those values are taken. This increases the chance that the performance data can be reproduced at a customer site for the same configuration and load condition.
Repeatability not only depends on taking the average/mean of performance data. It also depends on how consistently the product delivers those performance numbers. Standard deviation can help here. It may indicate whether the performance numbers can be reproduced at the customer site. The standard deviation represents how much the data varies from the mean. For example, if the average response time of 100 people withdrawing money from an ATM is 100 seconds and the standard deviation is 2, then there is greater chance that this performance data is repeatable than in a case where the standard deviation is 30. Standard deviation close to zero means the product performance is highly repeatable and performance values are consistent. Higher the standard deviation, more is the variability of the product performance.
When there are a set of performance numbers that came from multiple runs of the same test, there could be situations where in a few of the iterations, some errors were committed by the scripts, software, or a human. Taking such erroneous executions into account may not be appropriate and such values need to be ignored. Moreover, when a set of values is plotted on a chart, one or two values that are out of range may cause the graph to be cluttered and prevent meaningful analysis. Such values can be ignored to produce a smooth curve/graph. The process of removing some unwanted values in a set is called noise removal. When some values are removed from the set, the mean and standard deviation needs to be re-calculated.
The majority of the server-client, Internet, and database applications store the data in a local high-speed buffer when a query is made. This enables them to present the data quickly when the same request is made again. This is called caching. The performance data need to be differentiated according to where the result is coming from—the server or the cache. The data points can be kept as two different data sets—one for cache and one coming from server. Keeping them as two different data sets enables the performance data to be extrapolated in future, based on the hit ratio expected in deployments. For example, assume that data in a cache can produce a response time of 1000 microseconds and a server access takes 1 microsecond and 90% of the time a request is satisfied by the cache. Then the average response time is (0.9) × 1000 + 0.1 × 1 = 900.1 μs. The mean response time is thus calculated as a weighted average rather than a simple mean.
Some “time initiated activities” of the product or background activities of the operating system and network may have an effect on the performance data. An example of one such activity is garbage collection/defragmentation in memory management of the operating system or a compiler. When such activities are initiated in the background, degradation in the performance may be observed. Finding out such background events and separating those data points and making an analysis would help in presenting the right performance data.
Once the data sets are organized (after appropriate noise removal and after appropriate refinement as mentioned above), the analysis of performance data is carried out to conclude the following.
- Whether performance of the product is consistent when tests are executed multiple times
- What performance can be expected for what type of configuration (both hardware and software), resources
- What parameters impact performance and how they can be used to derive better performance (Please refer to the section on performance tuning)
- What is the effect of scenarios involving several mix of operations for the performance factors
- What is the effect of product technologies such as caching on performance improvements (Please refer to the section on performance tuning)
- Up to what load are the performance numbers acceptable and whether the performance of the product meets the criteria of “graceful degradation”
- What is the optimum throughput/response time of the product for a set of factors such as load, resources, and parameters
- What performance requirements are met and how the performance looks when compared to the previous version or the expectations set earlier or the competition
- Sometime high-end configuration may not be available for performance testing. In that case, using the current set of performance data and the charts that are available through performance testing, the performance numbers that are to be expected from a high-end configuration should be extrapolated or predicted.
7.3.6 Performance Tuning
Analyzing performance data helps in narrowing down the list of parameters that really impact the performance results and improving product performance. Once the parameters are narrowed down to a few, the performance test cases are repeated for different values of those parameters to further analyze their effect in getting better performance. This performance-tuning exercise needs a high degree of skill in identifying the list of parameters and their contribution to performance. Understanding each parameter and its impact on the product is not sufficient for performance tuning. The combination of parameters too cause changes in performance. The relationship among various parameters and their impact too becomes very important to performance tuning.
There are two steps involved in getting the optimum mileage from performance tuning. They are
- Tuning the product parameters and
- Tuning the operating system and parameters
There are a set of parameters associated with the product where the administrators or users of the product can set different values to obtain optimum performance. Some of the common practices are providing a number of forked processes for performing parallel transactions, caching and memory size, creating background activities, deferring routine checks to a later point of time, providing better priority to a highly used operation/transaction, disabling low-priority operations, changing the sequence or clubbing a set of operations to suit the resource availability, and so on. Setting different values to these parameters enhances the product performance. The product parameters in isolation as well as in combination have an impact on product performance. Hence it is important to
- Repeat the performance tests for different values of each parameter that impact performance (when changing one parameter you may want to keep the values of other parameters unchanged).
- Sometimes when a particular parameter value is changed, it needs changes in other parameters (as some parameters may be related to each other). Repeat the performance tests for a group of parameters and their different values.
- Repeat the performance tests for default values of all parameters (called factory settings tests).
- Repeat the performance tests for low and high values of each parameter and combinations.
There is one important point that needs to be noted while tuning the product parameters. Performance tuning provides better results only for a particular configuration and for certain transactions. It would have achieved the performance goals, but it may have a side-effect on functionality or on some non-functional aspects. Therefore, tuning may be counter-productive to other situations or scenarios. This side-effect of tuning product parameters needs to be analyzed and such side-effects also should be included as part of the analysis of this performance-tuning exercise.
Tuning the OS parameters is another step towards getting better performance. There are various sets of parameters provided by the operating system under different categories. Those values can be changed using the appropriate tools that come along with the operating system (for example, the Registry in MS-Windows can be edited using regedit.exe). These parameters in the operating system are grouped under different categories to explain their impact, as given below.
- File system related parameters (for example, number of open files permitted)
- Disk management parameters (for example, simultaneous disk reads/writes)
- Memory management parameters (for example, virtual memory page size and number of pages)
- Processor management parameters (for example, enabling/disabling processors in multiprocessor environment)
- Network parameters (for example, setting TCP/IP time out)
As explained earlier, not only each of the in parameters but also their combinations, have different effects on product performance. As before, the performance tests have to be repeated for different values of each and for a combination of OS parameters. While repeating the tests, the OS parameters need to be tuned before application/product tuning is done.
There is one important point that needs to be remembered when tuning the OS parameters for improving product performance. The machine on which the parameter is tuned, may have multiple products and applications that are running. Hence, tuning an OS parameter may give better results for the product under test, but may heavily impact the other products that are running on the same machine. Hence, OS parameters need to be tuned only when the complete impact is known to all applications running in the machine or they need to be tuned only when it is absolutely necessary, giving big performance advantages. Tuning OS parameters for small gains in performance is not the right thing to do.
The products are normally supported on more than one platform. Hence, the performance tuning procedure should consider the OS parameters and their effect on all supported platforms for the product.
The charts in Figure 7.4 are examples of what can be achieved by the performance-tuning exercise. In the charts the expected results (performance requirements), performance results without tuning (represented as normal), and tuned results (represented as high) are plotted together. These charts help in analyzing the effect of tuning with varying resource availability such as CPU and memory. These tests can also be repeated for different load conditions and plotted as yet another set of performance data points.
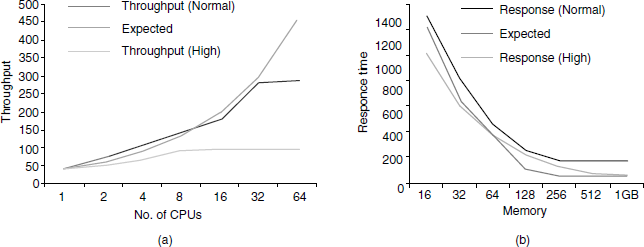
From the throughput chart, Figure 7.4 (a), you can see that the expectations on performance was met after tuning up to 32 CPU configurations and the product has issue with 64 CPU configuration. In the response time graph, Figure 7.4 (b), the expectations of before tuning and after tuning are met in both the cases, as long as the memory is 128 MB or more. Where the expectations are not met, the problems should be analyzed and resolved. The coloured figure is available on Illustrations.
The results of performance tuning are normally published in the form of a guide called the “performance tuning guide” for customers so that they can benefit from this exercise. The guide explains in detail the effect of each product and OS parameter on performance. It also gives a set of guideline values for the combination of parameters and what parameter must be tuned in which situation along with associated warnings of any wrong tuning exercise.
7.3.7 Performance Benchmarking
Performance benchmarking is about comparing the performance of product transactions with that of the competitors. No two products can have the same architecture, design, functionality, and code. The customers and types of deployments can also be different. Hence, it will be very difficult to compare two products on those aspects. End-user transactions/scenarios could be one approach for comparison. In general, an independent test team or an independent organization not related to the organizations of the products being compared does performance benchmarking. This does away with any bias in the test. The person doing the performance benchmarking needs to have the expertise in all the products being
compared for the tests to be executed successfully. The steps involved in performance benchmarking are the following:
- Identifying the transactions/scenarios and the test configuration
- Comparing the performance of different products
- Tuning the parameters of the products being compared fairly to deliver the best performance
- Publishing the results of performance benchmarking
As mentioned earlier, as the first step, comparable (apples-to-apples) transactions/scenarios are selected for performance benchmarking. Normally, the configuration details are determined well in advance and hence test cases are not repeated for different configurations. Generally, the test cases for all the products being compared are executed in the same test bed. However, two to three configurations are considered for performance benchmarking just to ensure that the testing provides the breadth required to cover realistic scenarios.
Once the tests are executed, the next step is to compare the results. This is where the understanding of the products being compared becomes essential. Equal expertise level in all the products is desirable for the person doing the tests. The tunable parameters for the various products may be completely different and understanding those parameters and their impact on performance is very important in doing a fair comparison of results. This is one place where bias can come in. A well tuned product, A, may be compared with a product B with no parameter tuning, to prove that the product A performs better than B. It is important that in performance benchmarking all products should be tuned to the same degree.
From the point of view of a specific product there could be three outcomes from performance benchmarking. The first outcome can be positive, where it can be found that a set of transactions/scenarios outperform with respect to competition. The second outcome can be neutral, where a set of transactions are comparable with that of the competition. The third outcome can be negative, where a set of transaction under-perform compared to that of the competition. The last outcome may be detrimental for the success of the product, hence, the performance tuning exercise described in the previous section needs to be performed for this set of transactions using the same configuration internally by the product organization. If tuning helps in this case, it at least helps in bringing down the criticality of the failure; else it requires the performance defects to be fixed and a subset of test cases for performance benchmarking to be repeated again. Even though it was said that tuning as an exercise needs to be repeated for the third outcome, it need not be limited only to that situation. Tuning can be repeated for all situations of positive, neutral, and negative results to derive the best performance results. Repeating the performance tuning may not be always possible. If neutral agencies (as benchmarks are done) are involved, then they may just bring out the apples-to-apples comparison and may not do tuning. In such cases, the test teams will take care of repeating the tests.
The results of performance benchmarking are published. There are two types of publications that are involved. One is an internal, confidential publication to product teams, containing all the three outcomes described above and the recommended set of actions. The positive outcomes of performance benchmarking are normally published as marketing collateral, which helps as a sales tool for the product. Also benchmarks conducted by independent organizations are published as audited benchmarks.
7.3.8 Capacity Planning
If performance tests are conducted for several configurations, the huge volume of data and analysis that is available can be used to predict the configurations needed for a particular set of transactions and load pattern. This reverse process is the objective of capacity planning. Performance configuration tests are conducted for different configurations and performance data are obtained. In capacity planning, the performance requirements and performance results are taken as input requirements and the configuration needed to satisfy that set of requirements are derived.
Capacity planning necessitates a clear understanding of the resource requirements for transactions/scenarios. Some transactions of the product associated with certain load conditions could be disk intensive, some could be CPU intensive, some of them could be network intensive, and some of them could be memory intensive. Some transactions may require a combination of these resources for performing better. This understanding of what resources are needed for each transaction is a prerequisite for capacity planning.
If capacity planning has to identify the right configuration for the transactions and particular load patterns, then the next question that arises is how to decide the load pattern. The load can be the actual requirement of the customer for immediate need (short term) or the requirements for the next few months (medium term) or for the next few years (long term). Since the load pattern changes according to future requirements, it is critical to consider those requirements during capacity planning. Capacity planning corresponding to short-, medium-, and long-term requirements are called
- Minimum required configuration;
- Typical configuration; and
- Special configuration.
A minimum required configuration denotes that with anything less than this configuration, the product may not even work. Thus, configurations below the minimum required configuration are usually not supported. A typical configuration denotes that under that configuration the product will work fine for meeting the performance requirements of the required load pattern and can also handle a slight increase in the load pattern. A special configuration denotes that capacity planning was done considering all future requirements.
There are two techniques that play a major role in capacity planning. They are load balancing and high availability. Load balancing ensures that the multiple machines available are used equally to service the transactions. This ensures that by adding more machines, more load can be handled by the product. Machine clusters are used to ensure availability. In a cluster there are multiple machines with shared data so that in case one machine goes down, the transactions can be handled by another machine in the cluster. When doing capacity planning, both load balancing and availability factors are included to prescribe the desired configuration.
The majority of capacity planning exercises are only interpretations of data and extrapolation of the available information. A minor mistake in the analysis of performance results or in extrapolation may cause a deviation in expectations when the product is used in deployments. Moreover, capacity planning is based on performance test data generated in the test lab, which is only a simulated environment. In real-life deployment, there could be several other parameters that may impact product performance. As a result of these unforeseen reasons, apart from the skills mentioned earlier, experience is needed to know real-world data and usage patterns for the capacity planning exercise.
7.4 TOOLS FOR PERFORMANCE TESTING
There are two types of tools that can be used for performance testing—functional performance tools and load tools.
Functional performance tools help in recording and playing back the transactions and obtaining performance numbers. This test generally involves very few machines.
Load testing tools simulate the load condition for performance testing without having to keep that many users or machines. The load testing tools simplify the complexities involved in creating the load and without such load tools it may be impossible to perform these kinds of tests. As was mentioned earlier, this is only a simulated load and real-life experience may vary from the simulation.
We list below some popular performance tools:
- Functional performance tools
- WinRunner from Mercury
- QA Partner from Compuware
- Silktest from Segue
- Load testing tools
- Load Runner from Mercury
- QA Load from Compuware
- Silk Performer from Segue
There are many vendors who sell these performance tools. The references at the end of the book point to some of the popular tools.
Performance and load tools can only help in getting performance numbers. The utilization of resources is another important parameter that needs to be collected. “Windows Task Manager” and “top” in Linux are examples of tools that help in collecting resource utilization. Network performance monitoring tools are available with almost all operating systems today to collect network data.
7.5 PROCESS FOR PERFORMANCE TESTING
Performance testing follows the same process as any other testing type. The only difference is in getting more details and analysis. As mentioned earlier, the effort involved in performance testing is more and tests are generally repeated several times. The increased effort reflects in increased costs, as the resources needed for performance testing is quite high. A major challenge involved in performance testing is getting the right process so that the effort can be minimized. A simple process for performance testing tries to address these aspects in Figure 7.5.

Ever-changing requirements for performance is a serious threat to the product as performance can only be improved marginally by fixing it in the code. As mentioned earlier, a majority of the performance issues require rework or changes in architecture and design. Hence, it is important to collect the requirements for performance earlier in the life cycle and address them, because changes to architecture and design late in the cycle are very expensive. While collecting requirements for performance testing, it is important to decide whether they are testable, that is, to ensure that the performance requirements are quantified and validated in an objective way. If so, the quantified expectation of performance is documented. Making the requirements testable and measurable is the first activity needed for the success of performance testing.
The next step in the performance testing process is to create a performance test plan. This test plan needs to have the following details.
- Resource requirements All additional resources that are specifically needed for performance testing need to be planned and obtained. Normally these resources are obtained, used for performance test, and released after performance testing is over. Hence, the resources need to be included as part of the planning and tracked.
- Test bed (simulated and real life), test-lab setup The test lab, with all required equipment and software configuration, has to be set up prior to execution. Performance testing requires a large number of resources and requires special configurations. Hence, setting up both the simulated and real-life environment is time consuming and any mistake in the test-bed setup may mean that the complete performance tests have be repeated. Hence, it has to be a part of the planning exercise and tracked.
- Responsibilities Performance defects, as explained earlier, may cause changes to architecture, design, and code. Additionally, the teams facing the customers normally communicate requirements for performance. Multiple teams are involved in the successful execution of performance tests and all the teams and people performing different roles need to work together if the objectives of performance have to be met. Hence, a matrix containing responsibilities must be worked out as part of the performance test plan and communicated across all teams.
- Setting up product traces, audits, and traces (external and internal) Performance test results need to be associated with traces and audit trails to analyze the results and defects. What traces and audit trials have to be collected is planned in advance and is an associated part of the test plan. This is to be planned in advance, because enabling too many traces and audit traces may start impacting the performance results.
- Entry and exit criteria Performance tests require a stable product due to its complexity and the accuracy that is needed. Changes to the product affect performance numbers and may mean that the tests have to be repeated. It will be counter-productive to execute performance test cases before the product is stable or when changes are being made. Hence, the performance test execution normally starts after the product meets a set of criteria. The set of criteria to be met are defined well in advance and documented as part of the performance test plan. Similarly, a set of exit criteria is defined to conclude the results of performance tests.
Designing and automating the test cases form the next step in the performance test process. Automation deserves a special mention as this step because it is almost impossible to perform performance testing without automation.
Entry and exit criteria play a major role in the process of performance test execution. At regular intervals during product development, the entry criteria are evaluated and the test is started if those criteria are met. There can be a separate set of criteria for each of the performance test cases. The entry criteria need to be evaluated at regular intervals since starting the tests early is counter-productive and starting late may mean that the performance objective is not met on time before the release. At the end of performance test execution, the product is evaluated to see whether it met all the exit criteria. If some of the criteria are not met, improvements are made to the product and the test cases corresponding to the exit criteria are re-executed with an objective to fill the gap. This process is repeated till all the exit criteria are met.
Each of the process steps for the performance tests described above are critical because of the factors involved (that is, cost, effort, time, and effectiveness). Hence, keeping a strong process for performance testing provides a high return on investment.
7.6 CHALLENGES
Performance testing is not a very well understood topic in the testing community. There are several interpretations of performance testing. Some organizations separate performance testing and load testing and conduct them at different phases of testing. While it may be successful in some situations, sometimes separating these two causes complications. When there is a need to compare these functional performance numbers with load testing numbers, it becomes difficult as the build used is different and the timeline (when the timeline is different, the quality of product may also be different) is also different as they were performed at two different phases. In this case, an apples-to-apples comparison is not possible.
The availability of skills is a major problem facing performance testing. As discussed at several places of this chapter, product knowledge, knowledge of competition, tools usage, automation, process, knowledge on statistics, and analytical skills are needed to do performance testing. This is one of the longest lists of skills that are required for any type of testing discussed till now. Training the engineers on these skills and making them available for a long duration for doing performance testing will help in meeting these skills.
Performance testing requires a large number and amount of resources such as hardware, software, effort, time, tools, and people. Even large organizations find these resources that are needed to meet the objectives of performance testing scarce. Even if they are available, it is so only for a short duration. This is yet another challenge in performance testing. Looking at the resources available and trying to meet as many objectives as possible is what is expected from the teams executing performance tests.
Performance test results need to reflect real-life environment and expectations. But due to the nature of tools which only simulate the environment, the test lab that works in a controlled environment, and data sets which may not have all fields populated the same way as the customer has, repeating the performance test results in the real-life customer deployments is a big challenge. Adequate care to create a test bed as close to a customer deployment is another expectation for performance tests.
Selecting the right tool for the performance testing is another challenge. There are many tools available for performance testing but not all of them meet all the requirements. Moreover, performance test tools are expensive and require additional resources to install and use. Performance tools also expect the test engineers to learn additional meta-languages and scripts. This throws up another challenge for performance testing.
Interfacing with different teams that include a set of customers is yet another challenge in performance testing. Not only the customers but also the technologists give performance test requirements and development teams. Performance testing is conducted to meet the expectations of customers, architects, and development team. As a business case, the performance of the product need to match up with the competition. As expectations keep growing from all directions, it will be difficult to meet all of them at one go. Sustained effort is needed if the majority of performance expectations have to be met.
Lack of seriousness on performance tests by the management and development team is another challenge. Once all functionalities are working fine in a product, it is assumed that the product is ready to ship. Due to various reasons specified, performance tests are conducted after the features are stable, and the defects that come out of these tests need to be looked into very seriously by the management. Since it may be too late to fix some defects or due to release pressures or due to fixes needed in design and architecture that may need a big effort in regression or various other reasons, generally some of the defects from these tests are postponed to the next release. It defeats the purpose of performance tests. A high degree of management commitment and directive to fix performance defects before product release are needed for successful execution of performance tests.
Performance testing is a type of testing that is easy to understand but difficult to perform due to amount of information and effort needed. There are several materials available on the web, explaining the cause and method for performance testing. This chapter tries to be unique among those, by covering the process and methodology from practical perspective. More details on the tools and associated information can be obtained from the web sites pointed to in the Bibliography and References at the end of the book.
- In each of the following cases, which performance factor is likely to be most important?
- All the transactions in a bank should be processed by end of each day and by that evening the end of day cash reconciliationshould be done.
- The users coming in to a bank should have their transactionscompleted in under 5 minutes.
- Users are accessing a remote file system from a client that has no processing power and are typing a file name. Since theprocessing is done at the remote file server, every charactertyped in is sent to the server and returned back.
- Each product has different tuning parameters. For each of the following cases, identify the important tuning parameters; Whichdocuments/sources would you go through to find out theseparameters?
- Operating system (e.g., Windows XP)
- Database (e.g., Oracle)
- A network card (e.g., a Wireless LAN card)
- How are collecting requirements for performance testing different from say collecting requirements for functional testing like black box testing? Distinguish by the sources used, methods used, tools used and the skill sets required
- Most product types in software like databases, networks, etc. have standard performance benchmarks. For example, TPCB benchmarks characterize the transaction rates. Look up the Internet and prepare a consolidated report on the industry standard benchmarks for the various types of database transactions, compilers and other types of software that is of interest to you.
- There are a number of performance test automation tools available in the market. For your organization, prepare a checklist of what you would expect from a performance test automation tool. Using this checklist, make a comparison of the various possible automation tools.
- “Staffing people for performance testing is arguably the most difficult” — Justify this statement based on the skill sets, attitude, and other parameters.