
Chapter 9
Internationalization [I18n] Testing
In this chapter—
9.1 INTRODUCTION
The market for software is becoming truly global. The advent of Internet has removed some of the technology barriers on widespread usage of software products and has simplified the distribution of software products across the globe. However, the ability of a software product to be available and usable in the local languages of different countries will significantly influence its rate of adoption. Thus, there is a paradoxical yet reasonable requirement for a software to support different languages (such as Chinese, Japanese, Spanish) and follow their conventions. This chapter deals with what needs to be done, both from development and testing perspectives in order to make a software product usable in different languages and countries. Building software for the international market, supporting multiple languages, in a cost-effective and timely manner is a matter of using internationalization standards throughout the software development life cycle—from requirements capture through design, development, testing, and maintenance. The guidelines given in this chapter help in reducing the time and effort required to make a software product support multiple languages, by building it right the first time with sufficient flexibility to support multiple languages.
If some of the guidelines are not followed in the software life cycle for internationalization, the effort and additional costs to support every new language will increase significantly over time. Testing for internationalization is done to ensure that the software does not assume any specific language or conventions associated with a specific language. Testing for internationalization has to be done in various phases of the software life cycle. We will go into the details of these in Section 9.3. We will first provide a basic primer on the terminology used in internationalization.
9.2 PRIMER ON INTERNATIONALIZATION
9.2.1 Definition of Language
To explain the terms that are used for internationalization, we need to understand what a language is. A language is a tool used for communication Internationalization—and this chapter—focuses mostly on human languages (such as Japanese, English, and so on) and not on computer languages (such as Java, C, and so on), which has a set of characters (alphabet), a set of (valid) words formed from these characters, and grammar (rules on how to coin words and sentences). In addition, a language also has semantics or the meaning associated with the sentences. For the same language, the spoken usage, word usage, and grammar could vary from one country to another. However, the characters/alphabet may remain the same in most cases. Words can have a different set of characters to mean the same thing for different countries that speak the same language. For example, “color” is spelt thus in US English while it is spelt as “colour” in UK English.
9.2.2 Character Set
This section outlines some of the standards that are used to represent characters of different languages in the computer. The purpose of this section is to introduce the idea of different character representations. A detailed understanding of how exactly each character is represented and a knowledge of internals are not required for understanding this chapter.
ASCII ASCII stands for American Standard Code for Information Interchange. It is a byte representation (8 bits) for characters that is used in computers. ASCII used seven bits to represent all characters that were used by the computer. Using this method, 128 (27 = 128) characters were represented in binary. ASCII was one of the earliest binary character representation for computers. Later ASCII was extended to include the unused eighth bit, that enabled 256 (28 = 256) characters to be represented in the binary. This representation included more punctuation symbols, European characters and special characters. Extended ASCII also helped accented characters (for example, ñàéíóú) to be represented. Accented characters are those English-like ASCII characters which have special meaning in European and western languages.
Double-Byte Character Set (DBCS) English characters were represented using a single byte in ASCII. Some languages such as Chinese and Japanese have many different characters that cannot be represented in a byte. They use two bytes to represent each character; hence the name DBCS. In a single-byte notation, only 256 different characters can be represented (in binary), whereas in the DBCS scheme, 65,536 (216) different characters can be represented.
Unicode ASCII or DBCS may be sufficient to encode all the characters of a single language. But they are certainly not sufficient to represent all the characters of all the languages in the world. The characters for all the languages need to be stored, interpreted, and transmitted in a standard way. Unicode fills this need effectively. Unicode provides a unique number to every character no matter what platform, program or language. Unicode uses fixed-width, 16-bit worldwide character encoding that was developed, maintained, and promoted by the Unicode Consortium. This allows unique encoding for each language by representing the characters, thereby allowing it to be handled the same way—sorted, searched, and manipulated. Unicode Transformation Format (UTF) specifies the algorithmic mapping for the language characters of different languages to be converted into Unicode. The Unicode Consortium recognizes many of the languages and locales (discussed in the next sub-section) existing in the world. Each character of every language is assigned a unique number. Such a provision aids greatly in internationalizing software. All software applications and platforms are moving towards Unicode. As an example, the information in Table 9.1 explains the path taken by various versions of Microsoft Windows to Unicode.
Table 9.1 Move towards Unicode for Windows operating system.
| Microsoft operating system | Path to internationalization |
|---|---|
| Windows 3.1 | ANSI |
| Windows 95 | ANSI and limited Unicode |
| Windows NT 3.1 | First OS based on Unicode |
| Windows NT 4.0 | Display of Unicode characters |
| Windows NT 5.0 | Display and input of Unicode characters |
9.2.3 Locale
Commercial software not only needs to remember the language but also the country in which it is spoken. There are conventions associated with the language which need to be taken care of in the software. There could be two countries speaking the same language with identical grammar, words, and character set. However, there could still be variations, such as currency and date formats. A locale is a term used to differentiate these parameters and conventions. A locale can be considered as a subset of a language that defines its behavior in different countries or regions. For example, English is a language spoken in USA and India. However, the currency symbol used in the two countries are different ($ and Rs respectively). The punctuation symbols used in numbers are also different. For example, 1,000,000 is represented in USA as 1,000,000 and as 10,00,000 in India.
Software needs to remember the locale, apart from language, for it to function properly. There could also be several currencies used in a country speaking the same language (for example, Euro and Franc are two currencies used in France, where the language is French). There could be several date formats also. A locale is a term which means all of these and more that may be important. For these reasons, a language can have multiple locales.
9.2.4 Terms Used in This Chapter
Internationalization (I18n) is predominantly used as an umbrella term to mean all activities that are required to make the software available for international market. This includes both development and testing activities. In the short form I18n, the subscript 18 is used to mean that there are 18 characters between “I” and the last “n” in the word “internationalization.” The testing that is done in various phases to ensure that all those activities are done right is called internationalization testing or I18n testing.
Localization (L10n) is a term used to mean the translation work of all software resources such as messages to the target language and conventions. In the short form L10n, the subscript 10 is used to indicate that there are 10 characters between “L” and “n” in the word “localization.” This translation of messages and documentation is done by a set of language experts who understand English (by default, all messages of the software are in English) and the target language into which the software is translated. In cases where an accurate translation is needed, the messages along with the context of usage is given to the L10n team.
Globalization (G11n) is a term that is not very popular but used to mean internationalization and localization. This term is used by a set of organizations, which would like to separate the internationalization from the localization set of activities. This separation may be needed because the localization activities are handled by a totally different set of language experts (per language), and these activities are generally outsourced. Some companies use the term I18n, to mean only the coding and testing activities, not the translation.
Globalization = Internationalization + Localization
9.3 TEST PHASES FOR INTERNATIONALIZATION TESTING
Testing for internationalization requires a clear understanding of all activities involved and their sequence. Since the job of testing is to ensure the correctness of activities done earlier by other teams, this section also elaborates on activities that are done outside the testing teams. Figure 9.1 depicts the various major activities involved in internationalization testing, using different colored boxes. The coloured figure is available on Illustrations. The boxes in yellow are the testing activities done by test engineers, the activity in the blue box is done by developers; and the activities in the pink boxes are done by a team called the localization team (which we will revisit later in this chapter). We will now go into details of each of these activities.
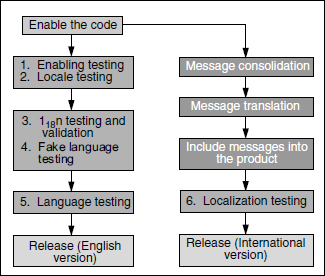
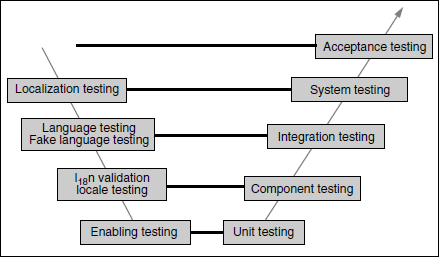
The testing for internationalization is done in multiple phases in the project life cycle. Figure 9.2 further elaborates the SDLC V model described in Chapter 2, and how the different phases of this model are related to various I18n testing activities. The coloured figure is available on Illustrations. Please note that the enabling testing is done by the developer as part of the unit testing phase.
Some important aspects of internationalization testing are
- Testing the code for how it handles input, strings, and sorting items;
- Display of messages for various languages; and
- Processing of messages for various languages and conventions.
These aspects are the main points of discussion in the following sections.
9.4 ENABLING TESTING
Enabling testing is a white box testing methodology, which is done to ensure that the source code used in the software allows internationalization. A source code, which has hard-coded currency format and date format, fixed length GUI screens or dialog boxes, read-and-print messages directly on the media is not considered enabled code. An activity of code review or code inspection mixed with some test cases for unit testing, with an objective to catch I18n defects is called enabling testing. The majority of the defects found during Year 2000 were I18n defects as they used hard-coded formats. Enabling testing uses a checklist. Some items to be kept in the review checklist for enabling testing are as follows.
- Check the code for APIs/function calls that are not part of the I18n API set. For example, printf () and scanf () are functions in C which are not I18n enabled calls. NLSAPI, Unicode and GNU gettxt define some set of calls which are to be used. (Some companies use prewritten parser/scripts to catch those obvious problems of non-internationalized functions used.)
- Check the code for hard-coded date, currency formats, ASCII code, or character constants.
- Check the code to see that there are no computations (addition, subtraction) done on date variables or a different format forced to the date in the code.
- Check the dialog boxes and screens to see whether they leave at least 0.5 times more space for expansion (as the translated text can take more space).
- Ensure region-cultural-based messages and slang are not in the code (region-based messages are hard to translate into other languages).
- Ensure that no string operations are performed in the code (substring searches, concatenation, and so on) and that only system-provided internationalization APIs used for this purpose.
- Verify that the code does not assume any predefined path, file names. or directory names in a particular language for it to function.
- Check that the code does not assume that the language characters can be represented in 8 bits, 16 bits, or 32 bits (some programs use bit shift operations of C language to read the next character, which are not allowed).
- Ensure that adequate size is provided for buffers and variables to contain translated messages.
- Check that bitmaps and diagrams do not have embedded translatable text (that needs to be translated).
- Ensure that all the messages are documented along with usage context, for the use of translators.
- Ensure that all the resources (such as bitmaps, icons, screens, dialog boxes) are separated from the code and stored in resource files.
- Check that no message contains technical jargon and that all messages are understood even by the least experienced user of the product. This also helps in translating messages properly.
- If the code uses scrolling of text, then the screen and dialog boxes must allow adequate provisions for direction change in scrolling such as top to bottom, right to left, left to right, bottom to top, and so on as conventions are different in different languages. For example, Arabic uses “right to left” direction for reading and “left to right” for scrolling. [Please note that scrolling direction is generally opposite to reading direction as indicated in Figure 9.3. The coloured figure is available on Illustrations.]

Of all the phases in internationalization testing, the enabling testing phase generally finds the largest number of I18n defects, if done right. At the time of design and initial coding itself, adequate care has to be taken to ensure that all items in the checklist and other requirements for I18n are met. Code enabling for I18n should not be postponed beyond the coding phase. If the product development team follows the approach of first developing (coding) the product and then incorporating II18n requirements as a separate phase, it would prove counter-productive and inefficient. This is so because in such cases the code would have to be modified to a large extent for I18n (after the basic functionality is incorporated). Hence, all the testing phases, starting from unit testing to final acceptance testing, need to be repeated as the changes would impact the basic functionality of the software.
The objective of enabling testing is to verify the code for I18n standards during unit testing.
9.5 LOCALE TESTING
Once the code has been verified for I18n and the enabling test is completed, the next step is to validate the effects of locale change in the product. A locale change affects date, currency format, and the display of items on screen, in dialog boxes and text. Changing the different locales using the system settings or environment variables, and testing the software functionality, number, date, time, and currency format is called locale testing. As explained earlier, each language can have multiple locales, and all such combinations need to be taken into account for locale testing. The locale settings in the machine need to be changed every time for each combination to test functionality and display.
Whenever a locale is changed, the tester needs to understand the changes to software functionality. It requires knowledge of code enabling. If the code is not enabled correctly, each and every feature of the product with each locale has to be tested. However, in a practical scenario, every functionality is assigned a priority (high, medium, and low) and the tests are executed based on the priority of the functionality. The priority is assigned keeping in mind the importance of the functionality to international customers and the impact. Since locale testing is performed as part of the component testing phase in the SDLC V model (see Figure 9.2 above), relative priority can be assigned to each component for I18n testing. This allows more focus for locale testing of those functionality which are important to customers and to the components that are not enabled right. Some of the items to be checked in locale testing are as follows.
- All features that are applicable to I18n are tested with different locales of the software for which they are intended. Some activities that need not be considered for I18n testing are auditing, debug code, log of activities, and such features which are used only by English administrators and programmers.
- Hot keys, function keys, and help screens are tested with different applicable locales. (This is to check whether a locale change would affect the keyboard settings.)
- Date and time format are in line with the defined locale of the language. For example, if US English locale is selected, the software should show mm/dd/yyyy date format.
- Currency is in line with the selected locale and language. For example, currency should be AUS$ if the language is AUS English.
- Number format is in line with selected locale and language. For example, the correct decimal punctuations are used and the punctuation is put at the right places.
- Time zone information and daylight saving time calculations (if used by the software) are consistent and correct.
Locale testing is not as elaborate procedure as enabling testing or other phases of testing which are discussed in this chapter. The focus of locale testing is limited to changing the locales and testing the date, currency formats, and the keyboard hot keys for the functionality that are important. Note that one can change the locale of the server or client by using the setup of the operating system. For example, in Microsoft Windows 2000, the locale can be changed by clicking “Start->Settings->Control Panel->Regional options.”
Locale testing focuses on testing the conventions for number, punctuations, date and time, and currency formats.
9.6 INTERNATIONALIZATION VALIDATION
I18n validation is different from I18n testing. I18n testing is the superset of all types of testing that are discussed in this chapter. I18n validation is performed with the following objectives.
- The software is tested for functionality with ASCII, DBCS, and European characters.
- The software handles string operations, sorting, sequencing operations as per the language and characters selected.
- The software display is consistent with characters which are non-ASCII in GUI and menus.
- The software messages are handled properly.
Here the real challenge of testing is with the non-ASCII characters and how they impact the software. For this purpose, language-specific keyboards and tools that can generate non-ASCII characters are used. IME (Input Method Editor) is a software tool available on Microsoft platforms. This tool can be used for entering non-English characters into a software. It helps in generating non-English ASCII characters. On Unix/Linux platforms, there are plenty of such tools available for free downloads. Many of the tools come with a “soft keyboard,” which enables the users to type the characters in the target language. Figure 9.4 below, shows an IME soft keyboard layout for entering Japanese (Katakana) characters. The coloured figure is available on Illustrations.

A checklist for the I18n validation includes the following.
- The functionality in all languages and locales are the same.
- Sorting and sequencing the items to be as per the conventions of language and locale.
- The input to the software can be in non-ASCII or special characters using tools such as IME and can be entered and functionality must be consistent.
- The display of the non-ASCII characters in the name are displayed as they were entered.
- The cut or copy-and-paste of non-ASCII characters retain their style after pasting, and the software functions as expected.
- The software functions correctly with different languages words/names generated with IME and other tools. For example, log in should work with English user name and German user name with some accented characters.
- The documentation contains consistent documentation style, punctuations, and all language/locale conventions are followed for every target audience.
- All the runtime messages in the software are as per the language, country terminology and usage along with proper punctuations; for example, the punctuations for numbers are different for different countries The currency amount 123456789.00 should get formatted as 123,456,789.00 in USA and as 12,34,56,789.00 in India).
The internationalization validation phase is introduced to take care of all interface-related issues on messages and functionality in all the components as the next phase involves integration of all components. It is important that the above testing is performed on all the components prior to proceeding to the next level of testing which is fake language testing.
I18n validation focuses on component functionality for input/output of non-English messages.
9.7 FAKE LANGUAGE TESTING
Fake language testing uses software translators to catch the translation and localization issues early. This also ensures that switching between languages works properly and correct messages are picked up from proper directories that have the translated messages. Fake language testing helps in identifying the issues proactively before the product is localized. For this purpose, all messages are consolidated from the software, and fake language conversions are done by tools and tested. The fake language translators use English-like target languages, which are easy to understand and test. This type of testing helps English testers to find the defects that may otherwise be found only by language experts during localization testing. Figure 9.5 illustrates fake language testing. The coloured figure is available on Illustrations.
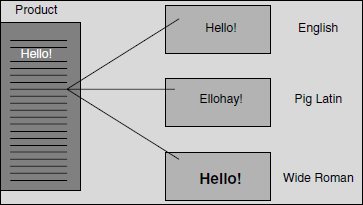
Fake language testing helps in simulating the functionality of the localized product for a different language, using software translators.
In the figure, there are two English-like fake languages used (Pig Latin and Wide Roman). A message in the program, “Hello,” is displayed as “Ellohay” in Pig Latin and “Hello” in Wide Roman. This helps in identifying whether the proper target language has been picked up by the software when language is changed dynamically using system settings.
The following items in the checklist can be used for fake language testing.
- Ensure software functionality is tested for at least one of the European single-byte fake language (Pig Latin).
- Ensure software functionality is tested for at least one double-byte language (Wide Roman).
- Ensure all strings are displayed properly on the screen.
- Ensure that screen width, size of pop-ups, and dialog boxes are adequate for string display with the fake languages.
9.8 LANGUAGE TESTING
Language testing is the short form of “language compatibility testing.” This ensures that software created in English can work with platforms and environments that are English and non-English. For example, if a software application was developed for Microsoft Windows, then the software is tested with different available language settings of Microsoft Windows. Since the software is not localized at this stage, it still continues to print and interact using English messages. This testing is done to ensure that the functionality of the software is not broken on other language settings and it is still compatible.
Language testing focuses on testing the English product with a global environment of products and services functioning in non-English.
Figure 9.6 illustrates the language testing and various combinations of locales that have to be tested in a client-server architecture. As shown in the figure, for language testing, one of the European languages is selected to represent accented character, one language for double-byte representation, and one default language which is English. The coloured figure is available on Illustrations.

Figure 9.6 Language testing and locale combinations that have to be tested in a client server architecture.
Testing majority of the combinations illustrated in the figure ensures compatibility for the English software to work in different language platforms. While testing, it is important to look for locale-related issues, as some of the defects that escaped from locale testing may show up in this testing.
It is also important to understand that there are many code page, bit stream, and message conversions taking place for internationalization when data is transmitted between machines or between software and operating system. This may cause some issues in functionality. Since data conversions are taking place, it is a good practice to have some performance test cases associated with language testing. The software is expected to give similar performance, irrespective of the language used for the software, operating system, or their combinations. This needs to be verified during language testing.
Language testing should at least have the following checklist
- Check the functionality on English, one non-English, and one double-byte language platform combination.
- Check the performance of key functionality on different language platforms and across different machines connected in the network.
9.9 LOCALIZATION TESTING
When the software is approaching the release date, messages are consolidated into a separate file and sent to multilingual experts for translation. A set of build tools consolidates all the messages and other resources (such as GUI screens, pictures) automatically, and puts them in separate files. In Microsoft terminology these are called resource files, on some other platforms these are called as message database. As discussed before, the messages for translation need to be sent along with the context in which they are used, so that they can get translated better. The multilingual experts may not be aware of the software or their target customers; it is, therefore, better that the messages do not contain any technology jargons.
Localization is a very expensive and labor-intensive process. Not all messages that belong to the software need to be translated. Some of the messages could be for administrators and developers and may not be for the target user. Such messages need not be translated and should be excluded from the file used for translation. While translating, not only the messages but also resources such as GUI screens, dialog boxes, icons, and bitmaps need to be included for localization, as resizing and customization are needed to fit in the translated messages. Customization is important as scroll directions and read directions are different in some languages. Figure 9.7 and the following explanation helps to understand how important customization is for different conventions.
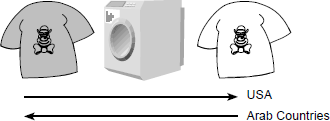
When the picture in Figure 9.7 is shown to people in English-speaking countries, they understand that the dirty t-shirt on the left-hand side when put inside the washing machine becomes a clean t-shirt as shown on the right-hand side. This is so because conventionally these countries read from left to right. If the same picture is shown to people in Arab countries, they may understand that a clean t-shirt when put inside the washing machine becomes dirty, as their reading direction from is right to left! The coloured figure is available on Illustrations.
After L10n, the product becomes truly global, functioning in different languages and works with other global products.
Hence customization of resources is very critical for localizing the software. Not only the software but also the documentation needs to be localized for the target language and conventions.
The next step after localization is to conduct localization testing. As explained earlier, after translating the messages, documents, and customizing the resources, a cycle of testing is conducted to check whether the software functions as expected in the localized environment. This is called localization testing. This testing requires language experts who can understand English, the target language, and have knowledge of the software and how it functions. The following checklist may help in doing localization testing.
- All the messages, documents, pictures, screens are localized to reflect the native users and the conventions of the country, locale, and language.
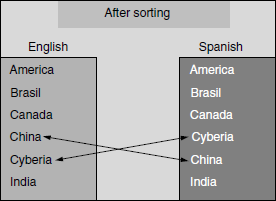
- Sorting and case conversions are right as per language convention. For example, sort order in English is A, B, C, D, E, whereas in Spanish the sort order is A, B, C, CH, D, E. See Figure 9.8. The coloured figure is available on Illustrations.
- Font sizes and hot keys are working correctly in the translated messages, documents, and screens.
- Filtering and searching capabilities of the software work as per the language and locale conventions.
- Addresses, phone numbers, numbers, and postal codes in the localized software are as per the conventions of the target user.
9.10 TOOLS USED FOR INTERNATIONALIZATION
There are several tools available for internationalization. These largely depend on the technology and platform used. For example, the tools used for client-server technology is different from those for web services technology using Java. Table 9.2 gives some sample free tools available. The requirements for I18n testing can vary with product and platform. Therefore, an organization should conduct a detailed study of the available tools before choosing an appropriate one.

9.11 CHALLENGES AND ISSUES
There are many challenges and issues att ached to the activities listed in this chapter. The first issue is regarding ownership. A number of software engineering professionals think that I18n and L10n are the issues of the translation team. This is not true. The ownership of making the product available in the market with or without I18n is with everyone developing the software. As we saw through this chapter, the effort for internationalization is spread all through the software development life cycle. Hence, the responsibility is not confined to a single translation team. Many organizations assume that they can afford to have a separate effort planned to make the necessary modification for I18n once developed in English. Again, as we have seen in this chapter, this will prove counter-productive and inefficient in the long run.
I18n believes in “Doing it right the first time.” Doing it later or releasing a support pack or a patch or a fix at a later point of time cannot be considered as the same software, release, or even feasible. The I18n effort of ensuring the software works in different languages cannot be carried over to the next release. Similarly, localization testing is the only testing phase which can be postponed to the next release, if the English version of the product has been released.
There are several interpretations of the terminology, activities, and phases. The variations are fine, as long as the objectives of the discussions in the chapter are met. There is only a thin line of difference among the several testing activities described in this chapter. Test engineers can merge two or three types of I18n testing and do them together. For example, locale testing, internationalization validation, and fake language testing can be merged to mean “I18n testing.”
I18n testing is not a subject which is as well understood as are other types of testing. Lack of standard tools and clarity for I18n testing further complicates the subject. The development community has similar challenges as there are many variations. This gives rise to a challenge as well as an opportunity to research and develop models and methodologies which will resolve these issues. This chapter is only the proverbial tip of the iceberg in this area.
Internationalization (I18n) is still not a term which is well understood by students and practitioners. This chapter take additional care to introduce those terminologies and explains various activities involved in detail. To understand I18n, [uni-2005] is a good site. This site has useful information for reading and understanding the concepts and procedures involved in I18n testing.
- Identify at least one language each where the text scrolling is from bottom to top, left to right and right to left.
- Why Internationalization and localization are denoted as I18n and L11n
- What is the specific role of configuration management in internationalization?
- List two of the fake languages and the corresponding tools that can be used for them?
- What is the primary skill that is needed for doing localization testing?
- Why is the role of Unicode very unique in internationalization?
- List the activities of Internationalization in unit, component, integration and system test phases.