
Chapter 11
Testing of Object-Oriented Systems
In this chapter—
11.1 INTRODUCTION
In the previous chapters, we have considered the various phases and types of testing. The tools, techniques, and processes discussed encompass most types of software. In this chapter, we will address the adaptations of these to a specific type of software systems—Object-Oriented (OO) systems. We provide an introduction to the terminology and concepts of OO in Section 11.2. This section is not intended to be an exhaustive coverage of OO concepts, rather just set the context quickly. This can be skipped by readers already familiar with OO terminology. Section 11.3 takes each of the basic OO concepts and addresses what needs to be done differently from the testing perspective.
11.2 PRIMER ON OBJECT-ORIENTED SOFTWARE
In this section, we will look at some of the basic concepts of OO systems that are relevant for testing. It is not the aim of this section to provide an exhaustive coverage of all OO concepts. Rather, the goal is to highlight the major concepts that cause some modifications and additions to the approach of testing that we have seen so far.
Earlier languages such as C—called procedure-oriented languages—are best characterized by the title of a book [WIRT-70] that came in the 1970s called Algorithms + Data Structures=Programs.
These programming languages were algorithm-centric in that they viewed the program as being driven by an algorithm that traced its execution from start to finish, as shown in Figure 11.1. Data was an external entity that was operated upon by the algorithm. Fundamentally, this class of programming languages was characterized by
- Data being considered as separate from the operations or program and
- Algorithm being the driver, with data being subsidiary to the algorithm.
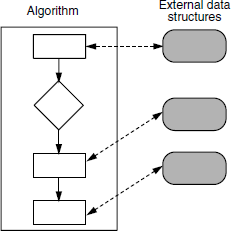
From a testing perspective, testing a conventional procedure-oriented system therefore entailed testing the algorithm, treating data as secondary to testing the algorithm flow.
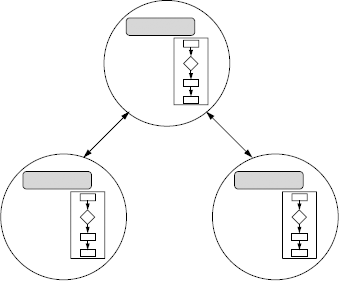
As against this, there are two fundamental paradigm shifts in OO languages and programming: First, the language is data- or object-centric. Second, as shown in Figure 11.2, there is no separation between data and the methods that operate on the data. The data and the methods that operate on the data go together as one indivisible unit.
Classes form the fundamental building blocks for OO systems. A class is a representation of a real-life object. Each class (or the real-life object it represents) is made up of attributes or variables and methods that operate on the variables. For example, a real-life object called a rectangle is characterized by two attributes, length and breadth. Area and perimeter are two of the operations or methods that can be performed on the rectangle object. The variables and the methods together define a rectangle class.
For the moment, let us not focus too much on the syntax and semantics of the code segment given below. A class definition like the below just provides a template that indicates the attributes and functions of an object. These attributes and methods (that is, the template) apply to all the objects of that class. A specific instance of the object is created by a new instantiation. Objects are the dynamic instantiation of a class. Multiple objects are instantiated using a given (static) class definition. Such specific instantiations are done using a constructor function. Most classes have a method (for example, called new) that is supposed to create a new instantiation of the class. After a new instantiation is created, the various methods of the class are invoked by passing messages to the instantiated objects using the appropriate parameters, for example,
Example 11.1: Simple class definition
Class rectangle
{
private int length, breadth;
public:
new(float length, float breadth)
{
this–>length=length;
this–>breadth=breadth;
}
float area()
{
return (length*breadth);
}
float perimeter()
{
return (2*(length+breadth));
};rect1.area() or rect2.new(11,b1). In the case of the first example, the method called area does not require any parameters whereas in the second example, creating a new rectangle requires specification of its length and breadth.
Example 11.2: Constructor function
A constructor function brings to life an instance of the class. In the above example, new is a constructor function. Each class can have more than one constructor function. Depending on the parameters passed or the signature of the function, the right constructor is called.
Thus, there can be as many instantiations of the rectangle class in a program as there are distinct rectangles. This means that the length, breadth, area, and perimeter of one instantiation rect1 are different from the corresponding variables and methods of another instantiation rect2. Thus they are referred to (for example) as rect1.length, rect2.area, and so on.
A question may arise as to what is the big deal about this “object orientation?” Why can we not just use traditional programming languages and have two functions (or subroutines) called area and perimeter and call these from anywhere else in the code? The basic difference is that in an object-oriented language, the functions area and perimeter (and the variables length and breadth) do not havea life of existence without a specific instantiation rect1 of the class Rectangle. In the case of a conventional programming language representing Area and Perimeter as two functions (and the variables length and breadth as parts of some global data structure) gives them existence independent of an instantiation of the object Rectangle. This may cause unpredictable results. For example, the variables length and breadth can be manipulated in unexpected (and incorrect) ways. Or, the functions Perimeter and Area may be called for inappropriate objects. In contrast, in an object-oriented language, since the variables and methods are specific to a particular instantiation of the object, it achieves better protection for the variables and methods.
Not all the data and not all the methods become publicly visible outside of the class. Some of the data and some of the methods are encapsulated within the class. This makes sure that the data and methods that are private to the implementation of the method is not accessible to the outside world. This increases the predictability of what transformations can happen to a data item. Also, the public methods provide the only operations that can be applied on the contents of the objects. This further minimizes the chances of any accidental or malicious changes to the contents of objects.
The methods are glued onto the object and do not stand out independently. Thus, the methods provide the only operations that can be done on the object. In other words, a user of the classes knows only the external interface of the calculation of area or perimeter, but has no details about the implementation of the methods. That is, the implementation of the methods is hidden from the user. This enables the person writing the methods to optimize the implementation without changing the external behavior. This is called encapsulation.
Both the methods and the variables (or data structures) that make up an object can be encapsulated. When variables are encapsulated, the only way to access the encapsulated variables are from within the object. Such private variables are not visible outside the object. This provides further protection against accidental modification of variables.
Different objects in real life have different traits that characterize each object. For example, while a rectangle requires two parameters (length and breadth) to characterize it, a square is characterized by just one value—its side. Similarly, a circle is also characterized by one value—its radius. But all these objects, despite their differences, also have some common characteristics—all these are plane figures and all these have two characteristics called perimeter (which measures the sum of the lengths of the object's boundaries) and area (which measures the plane area occupied by the figure). The specific ways in which area or perimeter is calculated varies from shape to shape. Thus, a general object (class) called plane objects has two attributes called perimeter and area that apply to all plane objects, even if the method of calculating the area and perimeter are different for different plane objects. A specific type of plane figure (for example, Rectangle) inherits these functions from the parent object (plane objects) and modifies them as needed to suit its specific needs. Similarly, another plane figure, circle, inherits the two functions and redefines them to suit its need (for example, perimeter=2*π*r and area=π*r2).
Example 11.3: Encapsulation
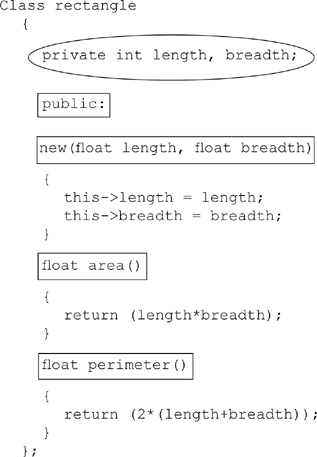
Encapsulation provides the right level of abstraction about the variables and methods to the outside world. In the example given below, the length and breadth (surrounded by ovals) are private variables, which means that they cannot be directly accessed from a calling program. The methods new, area, and perimeter (shown in rectangles) are public methods, in that they can be called from outside the class.
A major strength of OO systems lies in its ability to define new classes from existing classes, with some of the properties of the new class being similar to the existing class and some of the properties being different. This ability is called inheritance. The original class is called the parent class (or super-class) and the new class is called a child class (or derived class, or sub-class).
Example 11.4: Example to show inheritance
Inheritance enables the derivation of one class from another without losing sight of the common features. Rather than view rectangle, circle, and so on as unrelated shapes, the example below looks at these as derived from a class called plane objects. Regardless of the object, they all have attributes called area and perimeter.
Class plane objects
{
public float area();
public float perimeter();
Class rectangle
{
private float length, breadth;
public:
new(float length, float breadth)
{
this–>length=length;
this–>breadth=breadth;
}
float area()
{
return (length*breadth);
}
float perimeter()
{
return (2*(length+breadth));
}
};
Class circle
{
private float radius;
public:
new(float radius)
{
this–>radius=radius;
}
float area()
{
return (22/7*radius*radius);
}
float perimeter()
{
return (2*22/7*radius)
}
};
}
Inheritance allows objects (or at least parts of the object) to be reused. A derived class inherits the properties of the parent class—in fact, of all the parent classes, as there can be a hierarchy of classes. Thus, for those properties of the parent class that are inherited and used as is, the development and testing costs can be saved.
In the above example of an object rectangle being inherited from a general class called plane figure, we saw that the two derived classes (rectangle and circle) both have methods named area and perimeter. The specific inputs and logic of course is different for the methods in the circle class vis-a-vis those in the rectangle class, even though the names of the methods are the same. This means that even though the method names are the same for circle and rectangle, their actual meaning is dependent on the context of the class from which they are called. This property of two methods—in different classes—having the same name but performing different functions is called polymorphism.
As can be inferred from the above discussion, a method is to be associated with an object. One way to specify the object associated with the method is to specify it directly. For example, recti.area(). In this case, it is easy to see which specific method is being called on what class. A more subtle variation is the case of dynamic binding.
Assume there is a variable called ptr and it is assigned the address of an object at run time. In this case, we will not be able to ascertain which method is being called by just looking at the code. The value of ptr is known only at run-time and hence defies any static analysis of the code for testing. We will revisit the challenges posed by polymorphism and dynamic binding for testing in the next section.
As mentioned earlier, procedure-oriented programming are algorithm-centric. Control flows from top to bottom of a “main” program, operating on data structures as they proceed. However, an object-oriented program integrates data and methods. Control flow takes place by passing messages across the different objects. A message is nothing but an invocation of a method of an instantiation of a class (i.e. an object) by passing appropriate parameters.
The paradigm shift from algorithm-centric, control-based approach of procedure-oriented programming to object-centric, message-based approach of object-oriented programming changes the way the programs are to be written or tested.
A second difference that the message-based approach brings in is that these messages can be passed to the instantiations only after the instantiation is created. Messages passed to objects that are not instantiated can result in run-time errors. Such errors are difficult to catch by the static testing methods we have discussed so far.
Yet another difference in control flow and testing of OO systems arises from exceptions. Each class may have a set of exceptions that are raised as error conditions, in response to erroneous messages and conditions. For example, when a parameter passed to an object is invalid, the object may raise an exception. Such transfer of control to the exception code may cause a break in the sequence of program flow, which needs to be tested. When a class is nested into other classes, there may be a nested exceptions. It is important for an object to follow the code corresponding to the right exception by going up the nesting hierarchy. When a programmer is not aware of the interaction between the multiple levels of nesting, these exceptions can produce undesirable results. It is important to test the various nesting of exceptions.
11.3 DIFFERENCES IN OO TESTING
We looked at various salient aspects of object-oriented programming in the previous section. We will now go into the details of how these aspects affect testing.
From a testing perspective, the implication is that testing an OO system should tightly integrate data and algorithms. The dichotomy between data and algorithm that drove the types of testing in procedure-oriented languages has to be broken.
Testing OO systems broadly covers the following topics.
- Unit testing a class
- Putting classes to work together (integration testing of classes)
- System testing
- Regression testing
- Tools for testing OO systems
11.3.1 Unit Testing a Set of Classes
As a class is built before it is “published” for use by others, it has to be tested to see if it is ready for use. Classes are the building blocks for an entire OO system. Just as the building blocks of a procedure-oriented system have to be unit tested individually before being put together, so also the classes have to be unit tested. In this section, we will see the special reasons why these building blocks should be unit tested even more thoroughly for OO and then look at the conventional methods that apply to OO systems and proceed to techniques and methods that are unique to OO systems.
11.3.1.1 Why classes have to be tested individually first
In the case of OO systems, it is even more important (than in the case of procedure-oriented systems) to unit test the building blocks (classes) thoroughly for the following reasons.
- A class is intended for heavy reuse. A residual defect in a class can, therefore, potentially affect every instance of reuse.
- Many defects get introduced at the time a class (that is, its attributes and methods) gets defined. A delay in catching these defects makes them go into the clients of these classes. Thus, the fix for the defect would have to be reflected in multiple places, giving rise to inconsistencies.
- A class may have different features; different clients of the class may pick up different pieces of the class. No one single client may use all the pieces of the class. Thus, unless the class is tested as a unit first, there may be pieces of a class that may never get tested.
- A class is a combination of data and methods. If the data and methods do not work in sync at a unit test level, it may cause defects that are potentially very difficult to narrow down later on.
- Unlike procedural language building blocks, an OO system has special features like inheritance, which puts more “context” into the building blocks. Thus, unless the building blocks are thoroughly tested stand-alone, defects arising out of these contexts may surface, magnified many times, later in the cycle. We will see details of these later in the chapter.
11.3.1.2 Conventional methods that apply to testing classes
Some of the methods for unit testing that we have discussed earlier apply directly to testing classes. For example:
- Every class has certain variables. The techniques of boundary value analysis and equivalence partitioning discussed in black box testing can be applied to make sure the most effective test data is used to find as many defects as possible.
- As mentioned earlier, not all methods are exercised by all the clients, The methods of function coverage that were discussed in white box testing can be used to ensure that every method (function) is exercised.
- Every class will have methods that have procedural logic. The techniques of condition coverage, branch coverage, code complexity, and so on that we discussed in white box testing can be used to make sure as many branches and conditions are covered as possible and to increase the maintainability of the code.
- Since a class is meant to be instantiated multiple times by different clients, the various techniques of stress testing discussed in Chapter 6, System and Acceptance Testing, can be performed for early detection of stress-related problems such as memory leaks.
We had discussed state based testing in Chapter 4, Black Box Testing. This is especially useful for testing classes. Since a class is a combination of data and methods that operate on the data, in some cases, it can be visualized as an object going through different states. The messages that are passed to the class act as inputs to trigger the state transition. It is useful to capture this view of a class during the design phase so that testing can be more natural. Some of the criteria that can be used for testing are:
- Is every state reached at least once?
- Is every message (that is, input that causes a state transition) generated and tested?
- Is every state transition achieved at least once?
- Are illegal state transitions tested?
11.3.1.3 Special considerations for testing classes
The above methods were the common ones applicable from procedure-oriented systems. Given the nature of objects that are instantiated by classes (that these objects have to be tested via message passing), how do we test these instantiations at the unit level?
In order to test an instantiated object, messages have to be passed to various methods. In what sequence does one pass the messages to the objects? One of the methods that is effective for this purpose is the Alpha-Omega method. This method works on the following principles.
- Test the object through its life cycle from “birth to death” (that is, from instantiation to destruction). An instance gets instantiated by a constructor method; then the variables get set to their values. During the course of execution, the values may get modified and various methods executed. Finally, the instantiation is destroyed by a destructor method.
- Test the simple methods first and then the more complex methods. Since the philosophy of building OO systems is to have a number of reusable objects, it is likely that the more complex methods will build upon the simpler methods. Thus, it makes sense to test the simpler methods first, before testing the more complex methods.
- Test the methods from private through public methods. Private methods are methods that are not visible outside the object/class. Thus, these are the implementation-oriented methods, which deal with the logic of the method and are the building blocks of the entire system. Also, private methods are insulated from the callers (or clients). This reduces the dependencies in testing and gets the building blocks in a more robust state before they are used by clients.
- Send a message to every method at least once. This ensures that every method is tested at least once.
The Alpha-Omega method achieves the above objective by the following steps.
- Test the constructor methods first. Each class may get constructed by multiple constructor messages, based on its signatures. These are different ways of creating instances of the object. When there are multiple constructors, all the constructor methods should be tested individually.
- Test the get methods or accessor methods. Accessor methods are those that retrieve the values of variables in an object for use by the calling programs. This ensures that the variables in the class definition are accessible by the appropriate methods.
- Test the methods that modify the object variables. There are methods that test the contents of variables, methods that set/update the contents of variables, and methods that loop through the various variables. As can be inferred, these methods are increasingly complex, keeping in mind the principles laid down earlier.
- Finally, the object has to be destroyed and when the object is destroyed, no further accidental access should be possible. Also, all the resources used by the object instantiation should be released. These tests conclude the lifetime of an instantiated object.
There are also other special challenges that are unique to testing classes that do not arise for unit testing procedure-oriented systems. We will discuss these now.
As discussed earlier, encapsulation is meant to hide the details of a class from the clients of the class. While this is good from an implementation and usage perspective, it makes things difficult from a testing perspective, because the inside behavior of the encapsulated part is less visible to the tester. In the case of a procedure-oriented language, one can “get under the hood” of the implementation and get more visibility into the program behavior. Deprived of this flexibility, white box testing of classes with encapsulation becomes difficult.
As mentioned earlier, a class can actually be a part of a class hierarchy. A class can
- Inherit certain variables and methods from its parent class;
- Redefine certain variables and methods from its parent class; and
- Define new variables and methods that are specific to it and not applicable to the parent.
Since a class is made up of all three of the above categories of variables and methods, strictly speaking, every new class will have to be tested for all the variables and methods. However, in reality, a more incremental method may be more effective and sufficient. When a class is introduced for the first time, all the variables and methods have to be tested fully, using the conventional unit testing means discussed. From then on, whenever a class is derived from a parent class, the following will have to be tested because they are appearing for the first time.
- The changes made to the base class variables methods and attributes have to be tested again, as these have changed.
- New variables and methods that have been introduced in an inherited class have to be tested afresh.
For the first case, that is, modified attributes, the existing test cases for the parent may or may not be reusable. In the plane figures examples discussed earlier, even when the area and perimeter of a circle are tested, it does not tell anything about the same methods for a rectangle, even though both are derived from the same parent class.
While it is obvious that any changes or additions to class attributes in a child class have to be independently tested, the question that is arises, what do we do about testing the attributes that are inherited from a parent and not changed by a child class? Strictly speaking, it should not be necessary to test these again, because in theory, these have not changed. However, given that these unchanged variables and methods could have undesirable side-effects when mixed with the changes, some selective re-testing of the (unmodified) parent class elements will also have to be done with a derived class. How does one decide which of the unchanged elements should be re-tested? Some possible choices are as follows.
- Whenever an unmodified variable is referenced in a new or modified method, test cases for the unmodified variable can become a possible candidate for re-testing. This helps to find out any unintended use of the unmodified variable.
- Whenever an unmodified method is called in a new or modified method, this unmodified method is a candidate for re-test. If the new or modified method does not yield the correct results, it may indicate that the unmodified method probably has to be redefined in the child class containing the new method. Alternatively, the original method may have to be generalized to be able to accommodate the requirements of the new child class.
The above method of testing all the changes or new additions thoroughly at the point of creation and selective re-testing of other unchanged attributes is called incremental class testing. Such an approach strives to balance the need for exhaustive testing with the risks associated with not testing something that has (apparently) not changed.
While inheritance is supposed to make it easier to define new objects in terms of existing ones, it also introduces a potential source of defect. Consider a class with several levels of nesting. The innermost class may have very little code but might inherit a lot of variables and methods from the classes higher up in the hierarchy. This means that there is a lot of context that makes up the child class and this context cannot be ascertained by looking at the class in question in isolation. This is similar to the case of using global variables in a procedure-oriented languages. Since a nested class may freely access its parent's methods and variables, tests for nested classes should necessarily have access to information about the parent classes.
There are two other forms of classes and inheritance that pose special challenges for testing—multiple inheritance and abstract classes.
The examples discussed so far have assumed that a child class can be derived from only one immediate parent class. Certain languages support what is called multiple inheritance—where a child class is derived from two parent classes, much as a human child derives its nature from the genes of both the parents. This property of multiple inheritance presents some interesting testing issues. For example, consider a child class A that is derived from its two parent classes P1 and P2. It is quite possible that both P1 and P2 will have variables and methods of the same name but performing different functions. Assume there is a method with name X in both P1 and P2 (performing different functions). When a child class is inherited from these two parent classes, the child class may
- Use X from either P1 or P2, or
- Modify X by itself, thus making the modified X as the default meaning for X, overriding in X from both P1 and P2.
The second case is similar to changed classes in single inheritance and therefore definitely needs to be tested. For the first case, × has not changed, but it may be considered as a candidate for re-testing. Given that the possibility of side-effects has doubled because of the multiple inheritance, there is a greater scope for defects in this case. Thus, from a testing perspective, multiple inheritance requires more thorough testing.
There are cases where a particular method with a published interface must exist for any redefinition of a class, but the specific implementation of the method is completely left to the implementer. For example, consider a method that sorts a given array of integers and returns the sorted list in another array. The interfaces to the sort routine are clearly defined—an input array of integers and an output array of integers. Such a method is called virtual method. A class that has a virtual method is called an abstract class. A virtual method has to be implemented afresh for every new child class inherited from the parent class.
What implications do abstract class and virtual functions pose for testing? An abstract class cannot be instantiated directly because it is not complete and only has placeholders for the virtual functions. A concrete class with no abstract functions has to be redefined from the abstract class and it is those instances of concrete classes that have to be tested. Since the same virtual function may be implemented differently for different concrete classes, test cases for the different implementations of an abstract class cannot, in general, be reused. However, the advantage that virtual functions and abstract classes bring to testing is that they provide definitions of the interfaces that the function should satisfy. This interface should be unchanged for different implementations. Thus, this interface provides a good starting point for testing the concrete classes.
11.3.2 Putting Classes to Work Together—Integration Testing
In all of the above discussion, we have taken testing at a class level. An OO system is not a collection of discrete objects or classes but these objects or classes should coexist, integrate, and communicate with another. Since OO systems are designed to be made up of a number of smaller components or classes that are meant to be reused (with necessary redefinitions), testing that classes work together becomes the next step, once the basic classes themselves are found to be tested thoroughly. More often than not, it is not an individual class that is tested individually as a unit, but a collection of related classes that always go together. This is not very different from procedure-oriented languages, where it may not always be a single source file, but a collection of related files performing related functions that is tested as a unit. In the case of OO systems, because of the emphasis on reuse and classes, testing this integration unit becomes crucial.
In the case of a procedure-oriented system, testing is done by giving different data to exercise the control flow path. The control flow path is determined by the functions called by the program, from start to finish. As has been discussed before, in an OO system, the way in which the various classes communicate with each other is through messages. A message of the format
<instance name> . <method name> . <variables>
calls the method of the specified name, in the named instance, or object (of the appropriate class) with the appropriate variables. Thus, it is not possible to describe the flow of testing by merely listing out the function names through which execution proceeds. In fact, the name of the method does not uniquely identify the control flow while testing an OO system. Methods with the same name perform different functions. As we saw earlier, this property by which the meaning of a function or an operator varies with context and the same operation behaves differently in different circumstances is called polymorphism. From a testing perspective, polymorphism is especially challenging because it defies the conventional definition of code coverage and static inspection of code. For example, if there are two classes called square and circle, both may have a method called area. Even though the function is called area in both cases, and even though both the functions accept only one parameter, the meaning of the parameter is different depending on the context of the method called (radius for a circle and side for a square). The behavior of the method is also entirely different for the two cases. Thus, if we have tested the method area for a square, it has no implication on the behavior of area of a circle. They have to be independently tested.
A variant of polymorphism called dynamic binding creates special challenges for testing. If, in the program code, we were to explicitly refer to square.area and circle.area, then it will be obvious to the tester that these are two different functions and hence have to be tested according to the context where each is being used. In dynamic binding, the specific class for which a message is intended is specified at run time. This is especially challenging to test in languages that allow the use of pointers (for example, C++). Assuming that the pointer to a specific object is stored in a pointer variable called ptr, then ptr–>area(i) will resolve at run time to the method area of the appropriate object type pointed to by ptr. If ptr were to point to a square object, then the method invoked will be square.area(i) (and i is considered as the side of the square). If ptr points to a circle object, the methods invoked will be circle.area(i) (and i is considered as the radius of the circle). What this means is that typical white box testing strategies like code coverage will not be of much use in this case. In the above example, one can achieve code coverage of the line
ptr–>area(i) with ptr pointing to a square object. But if ptr is not tested pointing to a circle object, it leaves that part of the code which calculates the area of a circle completely untested, even though the lines of code in the calling program have already been covered by tests.
In addition to addressing encapsulation and polymorphism, another question that arises is in what order do we put the classes together for testing? This question is similar to what was encountered in integration testing of procedure-oriented systems. The various methods of integration like top-down, bottom-up, big bang, and so on can all be applicable here. The extra points to be noted about integration testing OO systems are that
- OO systems are inherently meant to be built out of small, reusable components. Hence integration testing will be even more critical for OO systems.
- There is typically more parallelism in the development of the underlying components of OO systems; thus the need for frequent integration is higher.
- Given the parallelism in development, the sequence of availability of the classes will have to be taken into consideration while performing integration testing. This would also require the design of stubs and harnesses to simulate the function of yet-unavailable classes.
11.3.3 System Testing and Interoperability of OO Systems
Object oriented systems are by design meant to be built using smaller reusable components (i.e. the classes). This heavy emphasis on reuse of existing building blocks makes system testing even more important for OO systems than for traditional systems. Some of the reasons for this added importance are:
- A class may have different parts, not all of which are used at the same time. When different clients start using a class, they may be using different parts of a class and this may introduce defects at a later (system testing) phase
- Different classes may be combined together by a client and this combination may lead to new defects that are hitherto uncovered.
- An instantiated object may not free all its allocated resource, thus causing memory leaks and such related problems, which will show up only in the system testing phase.
The different types of integration that we saw in Chapter 5 also apply to OO systems. It is important to ensure that the classes and objects interoperate and work together as a system. Since the complexity of interactions among the classes can be substantial, it is important to ensure that proper unit and component testing is done before attempting system testing. Thus, proper entry and exit criteria should be set for the various test phases before system testing so as to maximize the effectiveness of system testing.
11.3.4 Regression Testing of OO Systems
Taking the discussion of integration testing further, regression testing becomes very crucial for OO systems. As a result of the heavy reliance of OO systems on reusable components, changes to any one component could have potentially unintended side-effects on the clients that use the component. Hence, frequent integration and regression runs become very essential for testing OO systems. Also, because of the cascaded effects of changes resulting from properties like inheritance, it makes sense to catch the defects as early as possible.
11.3.5 Tools for Testing of OO Systems
There are several tools that aid in testing OO systems. Some of these are
- Use cases
- Class diagrams
- Sequence diagrams
- State charts
We will now look into the details of each of these.
11.3.5.1 Use cases
We have covered use cases in Chapter 4, on Black Box Testing. To recap, use cases represent the various tasks that a user will perform when interacting with the system. Use cases go into the details of the specific steps that the user will go through in accomplishing each task and the system responses for each steps. This fits in place for the object oriented paradigm, as the tasks and responses are akin to messages passed to the various objects.
11.3.5.2 Class diagrams
Class diagrams represent the different entities and the relationship that exists among the entities. Since a class is a basic building block for an OO system, a class diagram builds upon the classes of a system. There are a number of parts in a class diagram. We list a few here that are important from the testing perspective.
A class diagram has the following elements.
Boxes Each rectangular box represents a class. The various elements that make up a class are shown in the compartments within the class rectangle.
Association It represents a relationship between two classes by a line. A relationship may be something like “every employee works in one and only department” or “an employee may participate in zero or more projects.” Thus, an association can be 1-1, 1-many, many-1, and so on. The multiplicity factor for either side is shown on either side of the association line.
Generalization It represents child classes that are derived from parent classes, as discussed in inheritance earlier in the chapter.
A class diagram is useful for testing in several ways.
- It identifies the elements of a class and hence enables the identification of the boundary value analysis, equivalence partitioning, and such tests.
- The associations help in identifying tests for referential integrity constraints across classes.
- Generalizations help in identifying class hierarchies and thus help in planning incremental class testing as and when new variables and methods are introduced in child classes.
11.3.5.3 Sequence diagrams
We saw earlier that an OO system works by communicating messages across the various objects. A sequence diagram represents a sequence of messages passed among objects to accomplish a given application scenario or use case.
The objects that participate in a task or use case are listed horizontally. The lifetime of an object is represented by a vertical line from top to bottom. A dashed line on top represents object construction/activation, while an × in the end indicates destruction of the object.
The messages are represented by horizontal lines between two objects. There are different types of messages. They can be blocking or non-blocking. Some messages are passed conditionally. Like an IF statement in a programming language, a conditional message gets passed to different objects, based on certain Boolean conditions.
Time progresses as we go down from top to bottom in a sequence diagram.
A sequence diagram helps in testing by
- Identifying temporal end-to-end messages.
- Tracing the intermediate points in an end-to-end transaction, thereby enabling easier narrowing down of problems.
- Providing for several typical message-calling sequences like blocking call, non-blocking call, and so on.
Sequence diagrams also have their limitations for testing—complex interactions become messy, if not impossible, to represent; dynamic binding cannot be represented easily.
11.3.5.4 Activity diagram
While a sequence diagram looks at the sequence of messages, an activity diagram depicts the sequence of activities that take place. It is used for modeling a typical work flow in an application and brings out the elements of interaction between manual and automated processes. Since an activity diagram represents a sequence of activities, it is very similar to a flow chart and has parallels to most of the elements of a conventional flow chart.
The entire work flow is visualized as a set of action states, each action state representing an intermediate state of result that makes sense for the application. This is akin to a standard flow chart element of a sequence of steps with no conditional branching in between. Just as in conventional flow charts, decision boxes are diamond-shaped boxes, with each box having two exit paths (one when the Boolean condition in the decision is TRUE and the other when it is FALSE), only one of which will be chosen at run time. Since objects are the target for messages and cause for action, objects are also represented in an activity diagram. The activities are related to each other by control flows, with control flowing from the previous activity to the next, or a message flow, with a message being sent from one action state to an object. Since a decision or multiple control flows potentially cause multiple branches, they are synchronized later.
Given that an activity diagram represents control flow, its relevance for testing comes from
- The ability to derive various paths through execution. Similar to the flow graph discussed in white box testing, an activity diagram can be used to arrive at the code complexity and independent paths through a program code.
- Ability to identify the possible message flows between an activity and an object, thereby making the message-based testing discussed earlier more robust and effective.
11.3.5.5 State diagrams
We already saw the usefulness of state transition diagrams earlier in this chapter. When an object can be modeled as a state machine, then the techniques of state-based testing, discussed in black box testing and earlier in this chapter, can be directly applied.
11.3.6 Summary
We have discussed in this chapter the concepts of OO systems as they pertain to testing. We have seen how the general techniques of testing discussed in earlier chapters can be adapted for OO testing. Table 11.1 below summarizes these discussions.
Table 11.1 Testing methods and tools for key OO concepts
| Key OO concept | Testing methods and tools |
|---|---|
| Object orientation |
|
| Unit testing of classes |
|
| Encapsulation and inheritance |
|
| Abstract classes |
|
| Polymorphism |
|
| Dynamic binding |
|
| Inter-objectcommunication via messages |
|
| Object reuse and parallel development of objects |
|
[BOOC-94] provides the required foundations to object orientation concepts. [BOOC-99] covers the various diagrams like collaboration diagram and also integrates these use cases, UML, and other key concepts into a unified process. [GRAH-94] is one of the sources for the methods for testing classes like Alpha-Omega method. [BIND-2000] provides a very comprehensive and detailed coverage of all the issues pertaining to testing object oriented systems.
- The idea of not decoupling data and algorithms was given as a key differentiator between algorithm centric systems and object centric systems. What special challenges does this approach present from a testing perspective?
- What role would test data generators play in testing object oriented systems?
- In the example of plane figures given in the text, there was no redefinition of a method. Consider a case when a child class redefines a method of a parent class. What considerations would this introduce for testing?
- “OO languages that do not support the use of pointers make testing easier”—comment on this statement
- Consider a class that is nested five levels deep and the each level just redefines one method. What kind of problems do you anticipate in testing such classes and the instantiated objects?
- Why do integration and system testing assume special importance for an object oriented system?
- What are some of the differences in the approaches to regression testing that one can expect for object oriented systems vis-a-vis traditional/procedure-oriented systems?