
Chapter 8
Regression Testing
In this chapter—
8.1 WHAT IS REGRESSION TESTING?
Doctor: Congratulations! The stomach ulcer that was bothering you and preventing digestion is now completely cured!
Patient: That is fine, doctor, but I have got such a bad mouth ulcer that I can't eat anything. So there is nothing to digest!

Software undergoes constant changes. Such changes are necessitated because of defects to be fixed, enhancements to be made to existing functionality, or new functionality to be added. Anytime such changes are made, it is important to ensure that
- The changes or additions work as designed; and
- The changes or additions do not break something that is already working and should continue to work.
Regression testing is designed to address the above two purposes. Let us illustrate this with a simple example.
Regression testing is done to ensure that enhancements or defect fixes made to the software works properly and does not affect the existing functionality.
Assume that in a given release of a product, there were three defects—D1, D2, and D3. When these defects are reported, presumably the development team will fix these defects and the testing team will perform tests to ensure that these defects are indeed fixed. When the customers start using the product (modified to fix defects D1, D2, and D3), they may encounter new defects—D4 and D5. Again, the development and testing teams will fix and test these new defect fixes. But, in the process of fixing D4 and D5, as an unintended side-effect, D1 may resurface. Thus, the testing team should not only ensure that the fixes take care of the defects they are supposed to fix, but also that they do not break anything else that was already working.
Regression testing enables the test team to meet this objective. Regression testing is important in today's context since software is being released very often to keep up with the competition and increasing customer awareness. It is essential to make quick and frequent releases and also deliver stable software. Regression testing enables that any new feature introduced to the existing product does not adversely affect the current functionality.
Regression testing follows selective re-testing technique. Whenever the defect fixes are done, a set of test cases that need to be run to verify the defect fixes are selected by the test team. An impact analysis is done to find out what areas may get impacted due to those defect fixes. Based on the impact analysis, some more test cases are selected to take care of the impacted areas. Since this testing technique focuses on reuse of existing test cases that have already been executed, the technique is called selective re-testing. There may be situations where new test cases need to be developed to take care of some impacted areas. However, by and large, regression testing reuses the test cases that are available, as it focuses on testing the features that are already available and tested at least once already.
8.2 TYPES OF REGRESSION TESTING
Before going into the types of regression testing, let us understand what a “build” means. When internal or external test teams or customers begin using a product, they report defects. These defects are analyzed by each developer who make individual defect fixes. The developers then do appropriate unit testing and check the defect fixes into a Configuration Management (CM) System. The source code for the complete product is then compiled and these defect fixes along with the existing features get consolidated into the build. A build thus becomes an aggregation of all the defect fixes and features that are present in the product.
There are two types of regression testing in practice.
- Regular regression testing
- Final regression testing
A regular regression testing is done between test cycles to ensure that the defect fixes that are done and the functionality that were working with the earlier test cycles continue to work. A regular regression testing can use more than one product build for the test cases to be executed.
A “final regression testing” is done to validate the final build before release. The CM engineer delivers the final build with the media and other contents exactly as it would go to the customer. The final regression test cycle is conducted for a specific period of duration, which is mutually agreed upon between the development and testing teams. This is called the “cook time” for regression testing. Cook time is necessary to keep testing the product for a certain duration, since some of the defects (for example, Memory leaks) can be unearthed only after the product has been used for a certain time duration. The product is continuously exercised for the complete duration of the cook time to ensure that such time-bound defects are identified. Some of the test cases are repeated to find out whether there are failures in the final product that will reach the customer. All the defect fixes for the release should have been completed for the build used for the final regression test cycle. The final regression test cycle is more critical than any other type or phase of testing, as this is the only testing that ensures the same build of the product that was tested reaches the customer.
The regression testing types discussed above are represented in Figure 8.1. The coloured figure is available on Illustrations. Reg. 1 and Reg. 2 are regular regression test cycles and final regression is shown as Final Reg. in the figure.

8.3 WHEN TO DO REGRESSION TESTING?
Whenever changes happen to software, regression testing is done to ensure that these do not adversely affect adversely the existing functionality. A regular regression testing can use multiple builds for the test cases to be executed. However, an unchanged build is highly recommended for final regression testing. The test cases that failed due to the defects should be included for future regression testing.
Regression testing is done between test cycles to find out if the software delivered is as good or better than the builds received in the past. As testing involves large amount of resources (hardware, software, and people), a quick testing is needed to assess the quality of build and changes to software. Initially a few test engineers with very few machines do regression testing. This prevents a huge loss of effort in situations where the defect fixes or build process affects the existing/working functionality, taking the quality or progress in a negative direction. These kind of side-effects need to be fixed immediately before a large number of people get involved in testing. Regression testing is done whenever such a requirement arises.
It is necessary to perform regression testing when
- A reasonable amount of initial testing is already carried out.
- A good number of defects have been fixed.
- Defect fixes that can produce side-effects are taken care of.
Regression testing may also be performed periodically, as a pro-active measure.
Regression testing can be performed irrespective of which test phase the product is in.
As we will see in Chapter 15, a defect tracking system is used to communicate the status of defect fixes amongst the various stake holders. When a developer fixes a defect, the defect is sent back to the test engineer for verification using the defect tracking system. The test engineer needs to take the appropriate action of closing the defect if it is fixed or reopening it if it has not been fixed properly. In this process what may get missed out are the side-effects, where a fix would have fixed the particular defect but some functionality which was working before has stopped working now. Regression testing needs to be done when a set of defect fixes are provided.To ensure that there are no side-effects, some more test cases have to be selected and defect fixes verified in the regression test cycle. Thus, before a tester can close the defect as fixed, it is important to ensure that appropriate regression tests are run and the fix produces no side-effects. It is always a good practice to initiate regression testing and verify the defect fixes. Else, when there is a side-effect or loss of functionality observed at a later point of time through testing, it will become very difficult to identify which defect fix has caused it.
From the above discussion it is clear that regression testing is both a planned test activity and a need-based activity and it is done between builds and test cycles. Hence, regression test is applicable to all phases in a software development life cycle (SDLC) and also to component, integration, system, and acceptance test phases.
Figure 8.2 summarizes the contents of the above-mentioned sections.

8.4 HOW TO DO REGRESSION TESTING?
A well-defined methodology for regression testing is very important as this among is the final type of testing that is normally performed just before release. If regression testing is not done right, it will enable the defects to seep through and may result in customers facing some serious issues not found by test teams.
The failure of regression can only be found very late in the cycle or found by the customers. Having a well-defined methodology for regression can prevent such costly misses.
There are several methodologies for regression testing that are used by different organizations. The objective of this section is to explain a methodology that encompasses the majority of them. The methodology here is made of the following steps.
- Performing an initial “Smoke” or “Sanity” test
- Understanding the criteria for selecting the test cases
- Classifying the test cases into different priorities
- A methodology for selecting test cases
- Resetting the test cases for test execution
- Concluding the results of a regression cycle
8.4.1 Performing an Initial “Smoke” or “Sanity” Test
Whenever changes are made to a product, it should first be made sure that nothing basic breaks. For example, if you are building a database, then any build of the database should be able to start it up; perform basic operations such as queries, data definition, data manipulation; and shutdown the database. In addition, you may want to ensure that the key interfaces to other products also work properly. This has to be done before performing any of the other more detailed tests on the product. If, for example, a given build fails to bring up a database, then it is of no use at all. The code has to be corrected to solve this (and any other such basic) problem first, before one can even consider testing other functionality.
Smoke testing consists of
- Identifying the basic functionality that a product must satisfy;
- Designing test cases to ensure that these basic functionality work and packaging them into a smoke test suite;
- Ensuring that every time a product is built, this suite is run successfully before anything else is run; and
- If this suite fails, escalating to the developers to identify the changes and perhaps change or roll back the changes to a state where the smoke test suite succeeds.
To make sure that problems in smoke testing are detected upfront, some organizations mandate that anytime a developer makes a change, he or she should run the smoke test suite successfully on that build before checking the code into the Configuration Management repository.
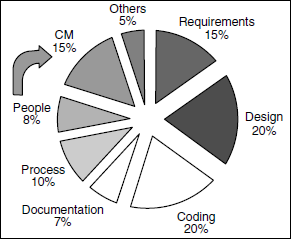
Defects in the product can get introduced not only by the code, but also by the build scripts that are used for compiling and linking the programs. Smoke testing enables the uncovering of such errors introduced by (also) the build procedures. This is important, as a research conducted in the past revealed that 15% of defects are introduced by Configuration Management or build-related procedures. This is shown in Figure 8.3. The coloured figure is available on Illustrations.
8.4.2 Understanding the Criteria for Selecting the Test Cases
Having performed a smoke test, the product can be assumed worthy of being subjected to further detailed tests. The question now is what tests should be run to achieve the dual objective of ensuring that the fixes work and that they do not cause unintended side-effects.
There are two approaches to selecting the test cases for a regression run. First, an organization can choose to have a constant set of regression tests that are run for every build or change. In such a case, deciding what tests to run is simple. But this approach is likely to be sub-optimal because
- In order to cover all fixes, the constant set of tests will encompass all features and tests which are not required may be run every time; and
- A given set of defect fixes or changes may introduce problems for which there may not be ready-made test cases in the constant set. Hence, even after running all the regression test cases, introduced defects will continue to exist.
A second approach is to select the test cases dynamically for each build by making judicious choices of the test cases. The selection of test cases for regression testing requires knowledge of
- The defect fixes and changes made in the current build;
- The ways to test the current changes;
- The impact that the current changes may have on other parts of the system; and
- he ways of testing the other impacted parts.
Some of the criteria to select test cases for regression testing are as follows.
- Include test cases that have produced the maximum defects in the past
- Include test cases for a functionality in which a change has been made
- Include test cases in which problems are reported
- Include test cases that test the basic functionality or the core features of the product which are mandatory requirements of the customer
- Include test cases that test the end-to-end behavior of the application or the product
- Include test cases to test the positive test conditions
- Includes the area which is highly visible to the users
When selecting test cases, do not select more test cases which are bound to fail and have little or less relevance to the defect fixes. Select more positive test cases than negative test cases for the final regression test cycle. Selecting negative test cases—that is, test cases introduced afresh with the intent of breaking the system—may create some confusion with respect to pinpointing the cause of the failure. It is also recommended that the regular test cycles before regression testing should have the right mix of both positive and negative test cases.
The selection of test cases for regression testing depends more on the impact of defect fixes than the criticality of the defect itself. A minor defect can result in a major side-effect and a defect fix for a critical defect can have little or minor side-effect. Hence the test engineer needs to balance these aspects while selecting test cases for regression testing.
Selecting regression test cases is a continuous process. Each time a set of regression tests (also called regression test bed) is to be executed, the test cases need to be evaluated for their suitability, based on the above conditions.
Regression testing should focus more on the impact of defect fixes than on the criticality of the defect itself.
8.4.3 Classifying Test Cases
When the test cases have to be selected dynamically for each regression run, it would be worthwhile to plan for regression testing from the beginning of project, even before the test cycles start. To enable choosing the right tests for a regression run, the test cases can be classified into various priorities based on importance and customer usage. As an example, we can classify the test cases into three categories. See Figure 8.4. The coloured figure is available on Illustrations.
It is important to know the relative priority of test cases for a successful test execution.

- Priority-0 These test cases can be called sanity test cases which check basic functionality and are run for accepting the build for further testing. They are also run when a product goes through a major change. These test cases deliver a very high project value to both to product development teams and to the customers.
- Priority-1 Uses the basic and normal setup and these test cases deliver high project value to both development team and to customers.
- Priority-2 These test cases deliver moderate project value. They are executed as part of the testing cycle and selected for regression testing on a need basis.
8.4.4 Methodology for Selecting Test Cases
Once the test cases are classified into different priorities, the test cases can be selected. There could be several right approaches to regression testing which need to be decided on “case to case” basis. There are several methodologies available in the industry for selecting regression test cases. The methodology discussed in this section takes into account the criticality and impact of defect fixes after test cases are classified into several priorities as explained in the previous section.
Case 1 If the criticality and impact of the defect fixes are low, then it is enough that a test engineer selects a few test cases from test case database (TCDB), (a repository that stores all the test cases that can be used for testing a product. More information about TCDB in Chapter 15 of this book) and executes them. These test cases can fall under any priority (0, 1, or 2).
Case 2 If the criticality and the impact of the defect fixes are medium, then we need to execute all Priority-0 and Priority-1 test cases. If defect fixes need additional test cases (few) from Priority-2, then those test cases can also be selected and used for regression testing. Selecting Priority-2 test cases in this case is desirable but not necessary.
Case 3 If the criticality and impact of the defect fixes are high, then we need to execute all Priority-0, Priority-1 and a carefully selected subset of Priority-2 test cases
The cases discussed above are illustrated in Figure 8.5. The coloured figure is available on Illustrations.

The above methodology requires that the impact of defect fixes be analyzed for all defects. This can be a time-consuming procedure. If, for some reason, there is not enough time and the risk of not doing an impact analysis is low, then the alternative methodologies given below can be considered.
- Regress all For regression testing, all priority 0, 1, and 2 test cases are rerun. This means all the test cases in the regression test bed/suite are executed.
- Priority based regression For regression testing based on this priority, all priority 0, 1, and 2 test cases are run in order, based on the availability of time. Deciding when to stop the regression testing is based on the availability of time.
- Regress changes For regression testing using this methodology code changes are compared to the last cycle of testing and test cases are selected based on their impact on the code (gra box testing)
- Random regression Random test cases are selected and executed for this regression methodology.
- Context based dynamic regression A few Priority-0 test cases are selected, and based on the context created by the analysis of those test cases after the execution (for example, findnew defects, boundary value) and outcome, additional related cases are selected for continuing the regression testing.
An effective regression strategy is usually a combination of all of the above and not necessarily any of these in isolation.
8.4.5 Resetting the Test Cases for Regression Testing
After selecting the test cases using the above methodology, the next step is to prepare the test cases for execution. For proceeding with this step, a “test case result history” is needed.
In a large product release involving several rounds of testing, it is very important to record what test cases were executed in which cycle, their results, and related information. This is called test case result history. This is part of the test case database discussed in Chapter 15.
In many organizations, not all the types of testing nor all the test cases are repeated for each cycle. As mentioned, test case result history provides a wealth of information on what test cases were executed and when. A method or procedure that uses test case result history to indicate some of the test cases be selected for regression testing is called a reset procedure. Resetting a test case is nothing but setting a flag called not run or execute again in test case database (TCDB). The reset procedure also hides the test case results of previous builds for the test cases, so that the test engineer executing the test cases may not be biased by the result history.
Resetting test cases reduces the risk involved in testing defect fixes by making the testers go through all the test cases and selecting appropriate test cases based on the impact of those defect fixes. If there are defect fixes that are done just before the release, the risk is more; hence, more test cases have to be selected.
Resetting of test cases, is not expected to be done often, and it needs to be done with the following considerations in mind.
- When there is a major change in the product.
- When there is a change in the build procedure which affects the product.
- Large release cycle where some test cases were not executed for a long time.
- When the prodcut is in the final regression test cycle with a few selected test cases.
- Where there is a situation, that the expected results of the test cases could be quite different from the previous cycles.
- The test cases relating to defect fixes and production problems need to be evaluated release after release.In case they are found to be working fine, they can be reset.
- Whenever existing application functionality is removed, the related test cases can be reset.
- Test cases that consistently produce a positive result can be removed.
- Test cases relating to a few negative test conditions (not producing any defects) can be removed.
When the above guidelines are not met, we may want to rerun the test cases rather than reset the results of the test cases. There are only a few differences between the rerun and reset states in test cases. In both instances, the test cases are executed but in the case of “reset” we can expect a different result from what was obtained in the earlier cycles. In the case of rerun, the test cases are expected to give the same test result as in the past; hence, the management need not be unduly worried because those test cases are executed as a formality and are not expected to reveal any major problem. Test cases belonging to the “rerun” state help to gain confidence in the product by testing for more time. Such test cases are not expected to fail or affect the release. Test cases belonging to the “reset” state say that the test results can be different from the past, and only after these test cases are executed can we know the result of regression and the release status.
For example, if there is a change in the installation of a product, which does not affect product functionality, then the change can be tested independently by rerunning some test cases and the test cases do not have to be “reset." Similarly, if there is a functionality that underwent a major change (design or architecture or code revamp), then all the related test cases for that functionality need to be “reset," and these test cases have to be executed again. By resetting test cases, the test engineer has no way of knowing their past results. This removes bias and forces the test engineer to pick up those test cases and execute them.
A rerun state in a test case indicates low risk and reset status represents medium to high risk for a release. Hence, close to the product release, it is a good practice to execute the “reset” test cases first before executing the “rerun” test cases.
Reset is also decided on the basis of the stability of the functionalities. If you are in Priority-1 and have reached a stage of comfort level in Priority-0 (say, for example, more than 95% pass rate), then you do not reset Priority-0 test cases unless there is a major change. This is true with Priority-1 test cases when you are in the Priority-2 test phase.
We will now see illustrate the use of the “reset” flag for regression testing in the various phases.
8.4.5.1 Component test cycle phase
Regression testing between component test cycles uses only Priority-0 test cases. For each build that enters the test, the build number is selected and all test cases in Priority-0 are reset. The test cycle starts only if all Priority-0 test cases pass.
8.4.5.2 Integration testing phase
After component testing is over, if regression is performed between integration test cycles Priority-0 and Priority-1 test cases are executed. Priority-1 testing can use multiple builds. In this phase, the test cases are “reset” only if the criticality and impact of the defect fixes and feature additions are high. A “reset” procedure during this phase may affect all Priority-0 and Priority-1 test cases.
8.4.5.3 System test phase
Priority-2 testing starts after all test cases in Priority-1 are executed with an acceptable pass percentage as defined in the test plan. In this phase, the test cases are “reset” only if the criticality and impact of the defect fixes and feature additions are very high. A “reset” procedure during this phase may affect Priority-0, Priority-1, and Priority-2 test cases.
8.4.5.4 Why reset test cases
Regression testing uses a good number of test cases which have already been executed and are associated with some results and assumptions on the result. A “reset” procedure gives a clear picture of how much of testing still remains, and reflects the status of regression testing.
If test cases are not “reset," then the test engineers tend to report a completion rate and other results based on previous builds. This is because of the basic assumption that multiple builds are used in each phase of the testing and a gut feeling that if something passed in the past builds, it will pass in future builds also. Regression testing does not go with an assumption that “Future is an extension of the past." Resetting as a procedure removes any bias towards test cases because resetting test case results prevents the history of test cases being viewed by testers.
8.4.6 Concluding the Results of Regression Testing
Apart from test teams, regression test results are monitored by many people in an organization as it is done after test cycles and sometimes very close to the release date. Developers also monitor the results from regression as they would like to know how well their defect fixes work in the product. Hence, there is a need to understand a method for concluding the results of regression.
Everyone monitors regression test results as this testing not only indicates about defects and but also their fixes.
Since regression uses test cases that have already executed more than once, it is expected that 100% of those test cases pass using the same build, if defect fixes are done right. In situations where the pass percentage is not 100, the test manager can compare with the previous results of the test case to conclude whether regression was successful or not.
- If the result of a particular test case was a pass using the previous builds and a fail in the current build, then regression has failed. A new build is required and the testing must start from scratch after resetting the test cases.
- If the result of a particular test case was a fail using the previous builds and a pass in the current build, then it is safe to assume the defect fixes worked.
- If the result of a particular test case was a fail using the previous builds and a fail in the current build and if there are no defect fixes for this particular test case, it may mean that the result of this test case should not be considered for the pass percentage. This may also mean that such test cases should not be selected for regression.
- If the result of a particular test case is a fail using the previous builds but works with a documented workaround and if you are satisfied with the workaround, then it should considered as a pass for both the system test cycle and regression test cycle.
- If you are not satisfied with the workaround, then it should be considered as a fail for a system test cycle but may be considered as a pass for regression test cycle.
This is illustrated in Table 8.1.

8.5 BEST PRACTICES IN REGRESSION TESTING
Regression methodology can be applied when
- We need to assess the quality of product between test cycles (both planned and need based);
- We are doing a major release of a product, have executed all test cycles, and are planning a regression test cycle for defect fixes; and
- We are doing a minor release of a product (support packs, patches, and so on) having only defect fixes, and we can plan for regression test cycles to take care of those defect fixes.
Practice 1:Regression can be used for all types of releases.
There can be multiple cycles of regression testing that can be planned for every release. This applies if defect fixes come in phases or to take care of some defect fixes not working with a specific build.
Practice 2: Mapping defect identifiers with test cases improves regression Quality.
When assigning a fail result to a test case during test execution, it is a good practice to enter the defect identifier(s) (from the defect tracking system) along so that you will know what test cases to be executed when a defect fix arrives. Please note that there can be multiple defects that can come out of a particular test case and a particular defect can affect more than one test case.
Even though ideally one would like to have a mapping between test cases and defects, the choice of test cases that are to be executed for taking care of side-effects of defect fixes may still remain largely a manual process as this requires knowledge of the interdependences amongst the various defect fixes.
As the time passes by and with each release of the product, the size of the regression test cases to be executed grows. It has been found that some of the defects reported by customers in the past were due to last-minute defect fixes creating side-effects. Hence, selecting the test case for regression testing is really an art and not that easy. To add to this complexity, most people want maximum returns with minimum investment on regression testing.
Practice 3: Create and execute regression test bed daily.
To solve this problem, as and when there are changes made to a product, regression test cases are added or removed from an existing suite of test cases.This suite of test cases, called regression suite or regression test bed, is run when a new change is introduced to an application or a product. The automated test cases in the regression test bed can be executed along with nightly builds to ensure that the quality of the product is maintained during product development phases.
Practice 4: Ask your best test engineer to select the test cases.
It was mentioned earlier that the knowledge of defects, products, their interdependences and a well-structured methodology are all very important to select test cases. These points stress the need for selecting the right person for the right job. The most experienced person in the team or the most talented person in the team may do a much better job of selecting the right test cases for regression than someone with less experience. Experience and talent can bring in knowledge of fragile areas in the product and impact the analysis of defects.
Please look at the pictures below. In the first picture, the tiger has been put in a cage to prevent harm to human kind. In the second picture, some members of a family are lie inside the mosquito net as prevention against from mosquitoes.
The same strategy has to be adopted for regression. Like the tiger in the cage, all defects in the product have to be identified and fixed. This is what “detecting defects in your product” means. All the testing types discussed in the earlier chapters and regression testing adopt this technique to find each defect and fix it.
The photograph of the family under the mosquito net signifies “protecting your product from defects.” The strategy followed here is of defect prevention. There are many verification and quality assurance activities such as reviews and inspections (discussed in Chapter 3), that try to do this.

Practice 5: Detect defects, and protect your product from defects and defect fixes.
Another aspect related to regression testing is “protecting your product from defect fixes.” As discussed earlier, a defect that is classified as a minor defect may create a major impact on the product when it gets fixed into the code. It is similar to what a mosquito can do to humans (impact), even though its size is small. Hence, it is a good practice to analyze the impact of defect fixes, irrespective of size and criticality, before they are incorporated into the code. The analysis of an impact due to defect fixes is difficult due to lack of time and the complex nature of the products. Hence, it is a good practice to limit the amount of changes in the product when close to the release date. This will prevent the product from defects that may seep in through the defect fixes route, just as mosquitoes can get into the mosquito net through a small hole there. If you make a hole for a mosquito to get out of the net, it also opens the doors for new mosquitoes to come into the net. Fixing a problem without analyzing the impact can introduce a large number of defects in the product. Hence, it is important to insulate the product from defects as well as defect fixes.
If defects are detected and the product is protected from defects and defect fixes, then regression testing becomes effective and efficient.
This chapter is written based on one of earlier paper published as in [SRINI-2003]. Some of the definitions used in this chapter are closer to [IEEE-1994] and may be a good place to look for templates and guidelines for performing regression testing.
- A product for automating payroll is slated to be released in March. The following are some of the features. For these, identify which of them would you put through smoke tests in the three months leading up to the product release in March, assuming that there will be one more maintenance release in September.
- Screens for entering employee information
- Statutory year-end reports
- Calculating the pay slip details for a month
- Screens for maintaining address of the employee
- A product has some test cases that are rarely run, ostensibly “because of lack of time." Discuss the pros and cons of running such dormant tests as a part of regression.
- Which of the test cases given below for inclusion in a given regression cycle?
- Version 7 of the product is being released and there are tests cases for new features to be introduced in this version.
- Version 6 had a number of defects in the buffer management module and Version 7 builds on top of this module.
- Version 6 had a fairly stable (i.e., very few defects) in the user interface module and there have been very little changes in this module in Version 7.
- Version 7 went through a Beta test cycle and during Beta tests, some important customer usage scenarios were found to uncover defects in the product.
- The product is a database software and has features like database startup, basic SQL query and multi-site query.
- We discussed ways of prioritizing test cases. Using the suggestions given in the text, prioritize the test cases as P0/Pl/P2.
- A test cases for a network product that tests basic flow control and error control.
- A test case for a database software that tests all the options of a join query.
- A test case for a file system that checks allocation of space that is not contiguous.
- A test case that tests the startup of OS with normal parameters
- A test case that tests the startup of an application in a “safe mode," something that is not done very often.
- A test case corresponding to a feature that has undergone significant change in the current version.
- A test case corresponding to a stable feature that has not uncovered any major defects.
- If during regression run, you are hard pressed for time, discuss the pros and cons of the various methodologies of regress (regress all, regress changes, etc) discussed in the text.
- A regression test engineer presented the following results. Discuss the efficacy of the choice of regression tests and of the development process:
- The tests for print facility produced no defects in the previous version and has not produced any defects in this version.
- The defects in tests for multi-currency continue in the current version.
- The feature expedited delivery had new defects in the current version.
- Discuss the difference in regression testing for a major release versus minor release of a product.
- We have discussed in this chapter as well as in Chapter 15, details of Test Case Data Base and Configuration Management Repository and a Defect Repository. Discuss how you can establish a link between these three repositories to automatically choose the most optimal regression tests for a given release.