
Personalization efforts have been underway at the search engines for some time. As we discussed in Chapter 2, the most basic form of personalization is to perform a reverse IP lookup to determine where the searcher is located, and tweak the results based on the searcher’s location. However, the search engines continue to explore additional ways to expand on this simple concept to deliver better results for each user. It is not yet clear whether personalization has given the engines that have invested in it heavily (namely Google) better results overall or greater user satisfaction, but their continued use of the technology suggests that, at the least, their internal user satisfaction tests have been positive.
The success of Internet search has always relied (and will continue to rely) on search engines’ abilities to identify searcher intent. Microsoft has branded Bing.com, its latest search project, not as a search engine but as a “decision” engine. It chose this label because of what it found in its research and analysis of search sessions. The slide shown in Figure 13-4 was presented by Satya Nadella at the Microsoft Search Summit 2009 in June 2009.
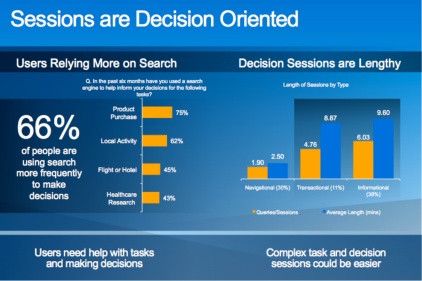
The conclusion was that about two-thirds of searchers frequently use search to make decisions. Microsoft also saw that making these decisions was proving to be hard based on the average length of a search session. What makes this complex is that there are so many different modes that a searcher may be in. Are searchers looking to buy, to research, or just to be entertained? Each of these modes may dictate very different results for the same search.
Google personalization and Universal Search are trying to tap into that intent as well, based on previous search history as well as by serving up a mix of content types, including maps, blog posts, videos, and traditional textual results. Danny Sullivan, editor-in-chief of Search Engine Land, added to the discussion on the importance of relevancy in how the information is presented, such as providing maps for appropriate location searches or the ability to list blog results based on recency as well as relevancy. It is not just about presenting the results, but about presenting them in the format that matches the searcher’s intent.
It could be as easy as letting the user reveal her intent. The now-defunct Yahoo! Labs project Yahoo! Mindset simply had a searcher-operated slider bar with “research” on one end and “buy” on the other. Sliding it reshuffled the results in real time via AJAX.
One area that will see great exploration will be in how users interact with search engines. As RSS adoption continues to grow and the sheer amount of information in its many formats expands, users will continue to look to search engines to be not just a search destination, but also a source of information aggregation; the search engine as portal, pulling and updating news and other content based on the user’s preferences.
Marissa Mayer, Google’s VP of Search User Experience and Interface Design, made a particularly interesting comment that furthers the sense that search engines will continue their evolution beyond search:
I think that people will be annotating search results pages and web pages a lot. They’re going to be rating them, they’re going to be reviewing them. They’re going to be marking them up…
The separate mention of “web pages” may be another reason why the release of Google Chrome (http://www.google.com/chrome) was so important. Tapping into the web browser might lead to that ability to annotate and rate those pages and further help Google identify what content interests the user.
Although Chris Sherman, executive editor of Search Engine Land, feels that advancement within search personalization is still fairly limited, he offered up an interesting interactive approach that the search engines might pursue, as a way to allow users to interact with search engines and help bring about better results:
Until search engines can find a way let us search by example - submitting a page of content and analyzing the full text of that page and then tying that in conjunction with our past behavior…
This is all part of downgrading those things that have been synonymous with SEO, such as rankings, keywords, and optimization, to a much greater focus on the users, tying into their intent and interests at the time of search. Personalization will make site stickiness ever more important. Securing a position in users’ history, becoming an authoritative go-to source for information, will be more critical than ever. Winning in the SERPs will require much more than just position.
Over time, smart marketers will recognize that the attention of a potential customer is a scarce and limited quantity. As the quantity of information available to us grows, the amount of time we have available for each piece of information declines, creating an attention deficit. How people search, and how advertisers interact with them, may change dramatically as a result.
In July 2008, The Atlantic cover article was titled “Is Google Making Us Stupid?” (http://www.theatlantic.com/doc/200807/google). The thrust of this article was that Google was so powerful in its capabilities that humans need to do less (and less!). This is a trend that will continue. After all, who needs memory when you have your “lifestream” captured 24/7 with instant retrieval via something akin to “Google Desktop Search”? When you have instant perfect recall of all of human history?
These types of changes, if and when they occur, could transform what we today call “SEO” into something else, where the SEO of tomorrow remains responsible for helping publishers gain access to potential customers through a vast array of new mechanisms that currently do not exist.
In November 2008 Google announced SearchWiki (http://googleblog.blogspot.com/2008/11/searchwiki-make-search-your-own.html). This was a move by Google to allow individual end users to tweak their search results. You can see the controls on the search results screen shown in Figure 13-5.
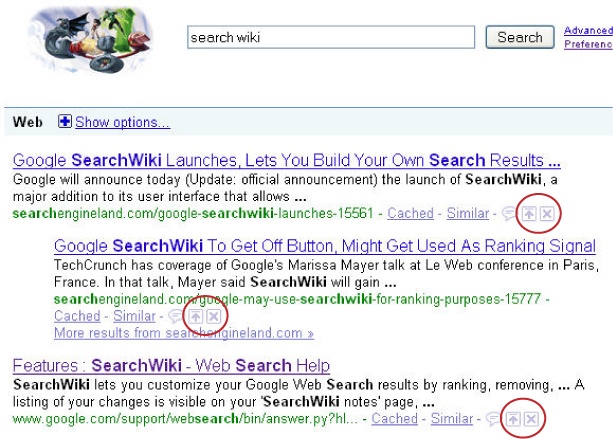
Users must be logged in to use SearchWiki, but if they are, they can move results up, move them back down again, or erase them from the results altogether. SearchWiki will remember their stated preferences in later sessions. There are many other features as well, such as the ability for users to comment on specific search results.
Although Google stated initially that it was not using SearchWiki to drive rankings, it has since clarified that it plans to use that data in the future (http://www.stonetemple.com/articles/interview-cedric-dupont.shtml). SearchWiki will potentially provide Google with a wealth of data directly from end users on what they like and do not like.
Google extended this basic concept in January 2009 with the notion of Preferred Sites. The Google Operating System blog broke the news (http://googlesystem.blogspot.com/2009/01/google-preferred-sites.html), and users who were included in the test program by Google are able to specify sites that they consider authoritative. Those sites are then given greater weight in the results for those users.
This, of course, could be yet another powerful ranking signal for the search engines. The initial SearchWiki announcement was about how users could tailor the results for specific queries. Voting a site up on one query would not affect its results on other search queries.
Now, with Preferred Sites, the user can make a broader sweeping decision that she wants a particular site to be emphasized whenever she enters a search query for which the selected site has a relevant result. A paid subscriber to Encyclopedia Britannica (http://www.britannica.com) could prefer that site over Wikipedia and, using Preferred Sites, can ensure that Wikipedia doesn’t appear at the top of search results, while Britannica does.
Cloud computing is transforming how the Internet-connected population use computers. Oracle founder Larry Ellison’s vision of thin-client computing may yet come to pass, but in the form of a pervasive Google OS “operating system” and its associated, extensive suite of applications. Widespread adoption by users of cloud-based (rather than desktop) software and seemingly limitless data storage, all supplied for free by Google, will usher in a new era of personalized advertising within these apps.
Google is actively advancing the mass migration of desktop computing to the cloud, with initiatives such as Google Docs & Spreadsheets (http://docs.google.com), Gmail (http://mail.google.com), Google Calendar (http://calendar.google.com), Google Reader (http://google.com/reader), and the much anticipated Google Wave and Google Web Drive/Gdrive—all with Google Chrome as the wrapper. These types of services lead to users entrusting their valuable data to the Google cloud. This brings them many benefits (but also concerns around privacy, security, uptime, and data integrity).
For example, most users don’t do a good job of backing up their data, making them susceptible to data loss from hard drive crashes and virus infections. In addition, they can more easily access that information from multiple computers (e.g., their work and home computers).
Google benefits by having a repository of user data available for analysis—which is very helpful in Google’s quest to deliver ever more relevant ads and search results. It also provides multiple additional platforms within which to serve advertising. Furthermore, regular users of a service such as Google Docs are more likely to be logged in a greater percentage of the time when they are on their computers, which is important because Google serves personalized results only when users are logged in.
The inevitable advance of cloud computing will offer more and more services with unrivaled convenience and cost benefits, compelling users to turn to the cloud for their data and their apps. Data portability from and to these services will become a critical issue. OpenID and Open Social are two of the early data portability solutions leading the charge, which will also help shepherd in this era of cloud computing.