
Making your site friendly to search engine crawlers also requires that you put some thought into your site information architecture. A well-designed architecture can bring many benefits for both users and search engines.
The search engines face myriad technical challenges in understanding your site. Crawlers are not able to perceive web pages in the way that humans do, and thus significant limitations for both accessibility and indexing exist. A logical and properly constructed website architecture can help overcome these issues and bring great benefits in search traffic and usability.
At the core of website organization are two critical principles: usability, or making a site easy to use; and information architecture, or crafting a logical, hierarchical structure for content.
One of the very early proponents of information architecture, Richard Saul Wurman, developed the following definition for information architect:
information architect. 1) the individual who organizes the patterns inherent in data, making the complex clear. 2) a person who creates the structure or map of information which allows others to find their personal paths to knowledge. 3) the emerging 21st century professional occupation addressing the needs of the age focused upon clarity, human understanding, and the science of the organization of information.
Search engines are trying to reproduce the human process of sorting relevant web pages by quality. If a real human were to do this job, usability and user experience would surely play a large role in determining the rankings. Given that search engines are machines and they don’t have the ability to segregate by this metric quite so easily, they are forced to employ a variety of alternative, secondary metrics to assist in the process. The most well known and well publicized among these is link measurement (see Figure 6-3), and a well-organized site is more likely to receive links.
Since Google launched in the late 1990s, search engines have strived to analyze every facet of the link structure on the Web and have extraordinary abilities to infer trust, quality, reliability, and authority via links. If you push back the curtain and examine why links between websites exist and how they come into place, you can see that a human being (or several humans, if the organization suffers from bureaucracy) is almost always responsible for the creation of links.
The engines hypothesize that high-quality links will point to high-quality content, and that great content and positive user experiences will be rewarded with more links than poor user experiences. In practice, the theory holds up well. Modern search engines have done a very good job of placing good-quality, usable sites in top positions for queries.
Look at how a standard filing cabinet is organized. You have the individual cabinet, drawers in the cabinet, folders within the drawers, files within the folders, and documents within the files (see Figure 6-4).
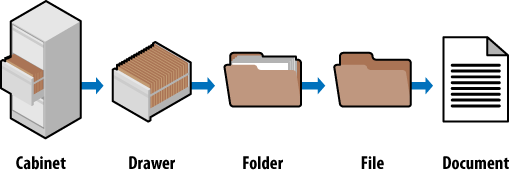
There is only one copy of any individual document, and it is located in a particular spot. There is a very clear navigation path to get to it.
If you want to find the January 2008 invoice for a client (Amalgamated Glove & Spat), you would go to the cabinet, open the drawer marked Client Accounts, find the Amalgamated Glove & Spat folder, look for the Invoices file, and then flip through the documents until you come to the January 2008 invoice (again, there is only one copy of this; you won’t find it anywhere else).
Figure 6-5 shows what it looks like when you apply this logic to the popular website, Craigslist.org.
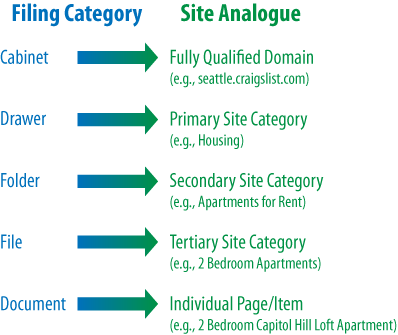
If you’re seeking an apartment on Capitol Hill in Seattle, you’d navigate to Seattle.Craigslist.org, choose Housing and then Apartments, narrow that down to two bedrooms, and pick the two-bedroom loft from the list of available postings. Craigslist’s simple, logical information architecture has made it easy to reach the desired post in four clicks, without having to think too hard at any step about where to go. This principle applies perfectly to the process of SEO, where good information architecture dictates:
As few clicks as possible to any given page
One hundred or fewer links per page (so as not to overwhelm either crawlers or visitors)
A logical, semantic flow of links from home page to categories to detail pages
Here is a brief look at how this basic filing cabinet approach can work for some more complex information architecture issues.
You should think of subdomains as completely separate filing cabinets within one big room. They may share similar architecture, but they shouldn’t share the same content; and more importantly, if someone points you to one cabinet to find something, he is indicating that that cabinet is the authority, not the other cabinets in the room. Why is this important? It will help you remember that links (i.e., votes or references) to subdomains may not pass all, or any, of their authority to other subdomains within the room (e.g., “*.craigslist.com,” wherein “*” is a variable subdomain name).
Those cabinets, their contents, and their authority are isolated from each other and may not be considered to be in concert with each other. This is why, in most cases, it is best to have one large, well-organized filing cabinet instead of several that may prevent users and bots from finding what they want.
If you have an organized administrative assistant, he probably uses 301 redirects inside his literal, metal filing cabinet. If he finds himself looking for something in the wrong place, he might place a sticky note in there reminding him of the correct location the next time he needs to look for that item. Anytime you looked for something in those cabinets, you could always find it because if you navigated improperly, you would inevitably find a note pointing you in the right direction. One copy. One. Only. Ever.
Redirect irrelevant, outdated, or misplaced content to the proper spot in your filing cabinet and both your users and the engines will know what qualities and keywords you think it should be associated with.
It would be tremendously difficult to find something in a filing cabinet if every time you went to look for it, it had a different name, or if that name resembled “jklhj25br3g452ikbr52k”. Static, keyword-targeted URLs are best for users and best for bots. They can always be found in the same place, and they give semantic clues as to the nature of the content.
These specifics aside, thinking of your site information architecture in terms of a filing cabinet is a good way to make sense of best practices. It’ll help keep you focused on a simple, easily navigated, easily crawled, well-organized structure. It is also a great way to explain an often complicated set of concepts to clients and co-workers.
Since search engines rely on links to crawl the Web and organize its content, the architecture of your site is critical to optimization. Many websites grow organically and, like poorly planned filing systems, become complex, illogical structures that force people (and spiders) looking for something to struggle to find what they want.
In conducting website planning, remember that nearly every user will initially be confused about where to go, what to do, and how to find what he wants. An architecture that recognizes this difficulty and leverages familiar standards of usability with an intuitive link structure will have the best chance of making a visit to the site a positive experience. A well-organized site architecture helps solve these problems and provides semantic and usability benefits to both users and search engines.
In Figure 6-6, a recipes website can use intelligent architecture to fulfill visitors’ expectations about content and create a positive browsing experience. This structure not only helps humans navigate a site more easily, but also helps the search engines to see that your content fits into logical concept groups. You can use this approach to help you rank for applications of your product in addition to attributes of your product.
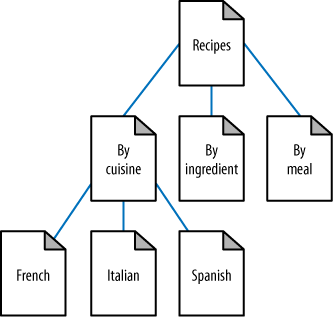
Although site architecture accounts for a small part of the algorithms, the engines do make use of relationships between subjects and give value to content that has been organized in a sensible fashion. For example, if in Figure 6-6 you were to randomly jumble the subpages into incorrect categories, your rankings could suffer. Search engines, through their massive experience with crawling the Web, recognize patterns in subject architecture and reward sites that embrace an intuitive content flow.
Although site architecture—the creation structure and flow in a website’s topical hierarchy—is typically the territory of information architects or is created without assistance from a company’s internal content team, its impact on search engine rankings, particularly in the long run, is substantial, thus making it wise to follow basic guidelines of search friendliness. The process itself should not be overly arduous, if you follow this simple protocol:
List all of the requisite content pages (blog posts, articles, product detail pages, etc.).
Create top-level navigation that can comfortably hold all of the unique types of detailed content for the site.
Reverse the traditional top-down process by starting with the detailed content and working your way up to an organizational structure capable of holding each page.
Once you understand the bottom, fill in the middle. Build out a structure for subnavigation to sensibly connect top-level pages with detailed content. In small sites, there may be no need for this level, whereas in larger sites, two or even three levels of subnavigation may be required.
Include secondary pages such as copyright, contact information, and other non-essentials.
Build a visual hierarchy that shows (to at least the last level of subnavigation) each page on the site.
Figure 6-7 shows an example of a structured site architecture.
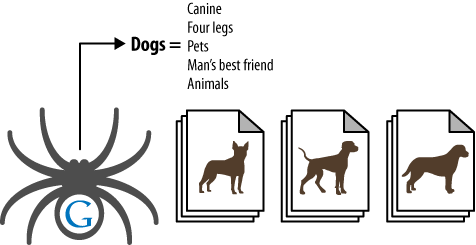
As search engines crawl the Web, they collect an incredible amount of data (millions of gigabytes) on the structure of language, subject matter, and relationships between content. Though not technically an attempt at artificial intelligence, the engines have built a repository capable of making sophisticated determinations based on common patterns. As shown in Figure 6-8, search engine spiders can learn semantic relationships as they crawl thousands of pages that cover a related topic (in this case, dogs).
Although content need not always be structured along the most predictable patterns, particularly when a different method of sorting can provide value or interest to a visitor, organizing subjects logically assists both humans (who will find your site easier to use) and engines (which will award you with greater rankings based on increased subject relevance).
Naturally, this pattern of relevance-based scoring extends from single relationships between documents to the entire category structure of a website. Site creators can take advantage of this best by building hierarchies that flow from broad, encompassing subject matter down to more detailed, specific content. Obviously, in any categorization system, there’s a natural level of subjectivity. Don’t get too hung up on perfecting what the engines want here—instead, think first of your visitors and use these guidelines to ensure that your creativity doesn’t overwhelm the project.
In designing a website, you should also consider the taxonomy and ontology of the website. Taxonomy is essentially a two-dimensional hierarchical model of the architecture of the site. You can think of ontology as mapping the way the human mind thinks about a topic area. It can be much more complex than taxonomy, because a larger number of relationship types can be involved.
One effective technique for coming up with an ontology is called card sorting. This is a user-testing technique whereby users are asked to group items together so that you can organize your site as intuitively as possible. Card sorting can help identify not only the most logical paths through your site, but also ambiguous or cryptic terminology that should be reworded.
With card sorting, you write all the major concepts onto a set of cards that are large enough for participants to read, manipulate, and organize. Your test group assembles the cards in the order they believe provides the most logical flow, as well as into groups that seem to fit together.
By itself, building an ontology is not part of SEO, but when you do it properly it will impact your site architecture, and therefore it interacts with SEO. Coming up with the right site architecture should involve both disciplines.
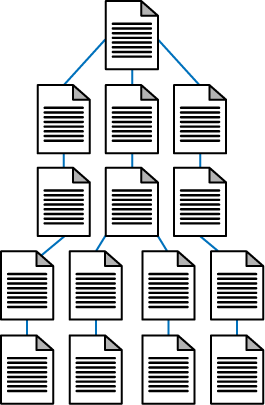
One very strict rule for search friendliness is the creation of flat site architecture. Flat sites require a minimal number of clicks to access any given page, whereas deep sites create long paths of links required to access detailed content. For nearly every site with fewer than 10,000 pages, all content should be accessible through a maximum of three clicks from the home page and/or sitemap page. At 100 links per page, even sites with millions of pages can have every page accessible in five to six clicks if proper link and navigation structures are employed. If a site is not built to be flat, it can take too many clicks to reach the desired content, as shown in Figure 6-9. In contrast, a flat site (see Figure 6-10) allows users and search engines to reach most content in just a few clicks.
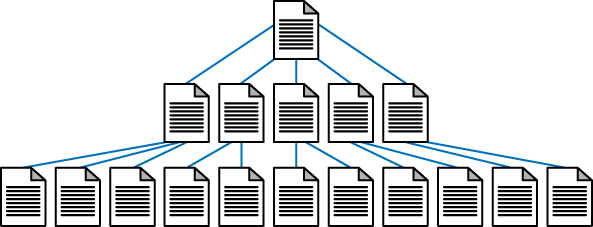
Flat sites aren’t just easier for search engines to crawl; they are also simpler for users, as they limit the number of page visits the user requires to reach his destination. This reduces the abandonment rate and encourages repeat visits.
When creating flat sites, be aware that the engines are known to limit the number of links they crawl from a given page. Representatives from several of the major engines have said that more than 100 individual links from a single page might not be followed unless that page is of particular importance (i.e., many external sites link to it).
Following this guideline means limiting links on category pages to 100 or fewer, meaning that with the three-clicks-to-any-page rule, 10,000 pages is the maximum number possible (unless the home page is also used as a Sitemap-style link guide, which can increase the max, technically, to 1 million).
The 100-links-per-page issue relates directly to another rule for site architects: avoid pagination wherever possible. Pagination, the practice of creating a list of elements on pages separated solely by numbers (e.g., some e-commerce sites use pagination for product catalogs that have more products than they wish to show on a single page), is problematic for many reasons. First, pagination provides virtually no topical relevance. Second, content that moves into different pagination can create duplicate content issues. Last, pagination can create spider traps and hundreds or thousands of extraneous, low-quality pages that can be detrimental to search visibility. Figure 6-11 shows how pagination structures do not benefit search engines.
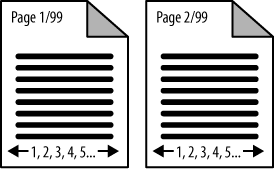
So, make sure you implement flat structures and stay within sensible guidelines for the number of links per page, while retaining a contextually rich link structure. This is not always as easy as it sounds. Accomplishing this may require quite a bit of thought and planning to build a contextually rich structure on some sites. Consider a site with 10,000 different men’s running shoes. Defining an optimal structure for that site could be a very large effort, but that effort will pay serious dividends in return.
Site navigation is something that web designers have been putting considerable thought and effort into since websites came into existence. Even before search engines were significant, navigation played an important role in helping users find what they wanted. It plays an important role in helping search engines understand your site as well.
The search engine spiders need to be able to read and interpret your website’s code to properly spider and index the content on your web pages. Do not confuse this with the rules of organizations such as the W3C, which issues guidelines on HTML construction. Although following the W3C guidelines can be a good idea, the great majority of sites do not follow these guidelines, so search engines generally overlook violations of these rules as long as their spiders can parse the code.
Unfortunately, there are also a number of ways that navigation and content can be rendered on web pages that function for humans, but are invisible (or challenging) for search engine spiders.
For example, there are numerous ways to incorporate content and navigation on the pages of a website. For the most part, all of these are designed for humans. Basic HTML text and HTML links such as those shown in Figure 6-12 work equally well for humans and search engine crawlers.

The text and the link that are indicated on the page shown in Figure 6-12 (the Alchemist Media home page) are in simple HTML format.
However, many other types of content may appear on a web page and may work well for humans but not so well for search engines. Here are some of the most common ones.
Many sites incorporate search functionality. These “site search” elements are specialized search engines that index and provide access to one site’s content.
This is a popular method of helping users rapidly find their way around complex sites. For example, the Pew Internet website provides Site Search in the top-right corner; this is a great tool for users, but search engines will be stymied by it. Search engines operate by crawling the Web’s link structure—they don’t submit forms or attempt random queries into search fields, and thus, any URLs or content solely accessible via a “site search” function will remain invisible to Google, Yahoo!, and Bing.
Forms are a popular way to provide interactivity, and one of the simplest applications is the “contact us” form many websites have.
Unfortunately, crawlers will not fill out or submit forms such as these; thus, any content restricted to those who employ them is inaccessible to the engines. In the case of a “contact us” form, this is likely to have little impact, but other types of forms can lead to bigger problems.
Websites that have content behind logins will either need to provide text links to the content behind the login (which defeats the purpose of the login) or implement First Click Free (discussed in Content Delivery and Search Spider Control).
Adobe Shockwave files, Java embeds, audio, and video (in any format) present content that is largely uncrawlable by the major engines. With some notable exceptions that we will discuss later, search engines can read text only when it is presented in HTML format. Embedding important keywords or entire paragraphs in an image or a Java console renders them invisible to the spiders. Likewise, words spoken in an audio file or video cannot be read by the search engines.
Alt attributes, originally
created as metadata for markup and an accessibility tag for
vision-impaired users, is a good way to present at least some text
content to the engines when displaying images or embedded, nontext
content. Note that the alt
attribute is not a strong signal, and using the alt attribute on an image link is no
substitute for implementing a simple text link with targeted anchor
text. A good alternative is to employ captions and text descriptions
in the HTML content wherever possible.
In the past few years, a number of companies offering transcription services have cropped up, providing automated text creation for the words spoken in audio or video. Providing these transcripts on rich media pages makes your content accessible to the search engines and findable by keyword-searching visitors. You can also use software such as Dragon Naturally Speaking and dictate your “transcript” to your computer.
JavaScript enables many dynamic functions inside a website, most of which interfere very minimally with the operations of a search engine spider. The exception comes when a page must use a JavaScript call to reach another page, or to pull content that the spiders can’t see in the HTML. Though these instances are relatively rare, it pays to be aware of how the robots spider and index—both content and links need to be accessible in the raw HTML of a page to avoid problems.
Asynchronous JavaScript and XML (AJAX) presents similar problems, most notably in the delivery of content that search engines cannot spider. Since AJAX uses database calls to retrieve data without refreshing a page or changing URLs, the content contained behind these technologies is frequently completely hidden from the search engines (see Figure 6-13).
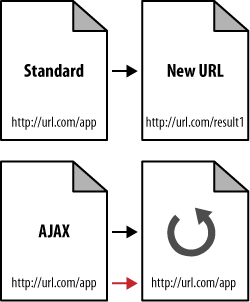
When AJAX is used you may want to consider implementing an alternative spidering system for search engines to follow. AJAX applications are so user-friendly and appealing that for many publishers foregoing them is simply impractical. Building out a directory of links and pages that the engines can follow is a far better solution.
When you build these secondary structures of links and pages, make sure to provide users with access to them as well. Inside the AJAX application itself, give your visitors the option to “directly link to this page” and connect that URL with the URL you provide to search spiders through your link structures. AJAX apps not only suffer from unspiderable content, but often don’t receive accurate links from users since the URL doesn’t change.
Newer versions of AJAX use a # delimiter, which acts as a query string
into the AJAX application. This does allow you to link directly to
different pages within the application. However, the #, which is used for HTML bookmarking, and
everything past it, is ignored by search engines.
This is largely because web browsers use only what’s after the
# to jump to the anchor within
the page, and that’s done locally within the browser. In other
words, the browser doesn’t send the full URL, so the parameter
information (i.e., any text after the #) is not passed back to the
server.
So, don’t use your ability to link to different pages within
the AJAX application as a solution to the problem of exposing
multiple pages within the application to search engines. All of the
pages exposed in this way will be seen as residing on the same URL
(everything preceding the #).
Make sure you create discrete web pages that have unique URLs for
the benefit of search engines.
Frames emerged in the mid-1990s as a popular way to make easy navigation systems. Unfortunately, both their usability (in 99% of cases) and their search friendliness (in 99.99% of cases) were exceptionally poor. Today, iframes and CSS can replace the need for frames, even when a site’s demands call for similar functionality.
For search engines, the biggest problem with frames and iframes is that they often hold the content from two or more URLs on a single page. For users, search engines, which direct searchers to only a single URL, may get confused by frames and direct visitors to single pages (orphan pages) inside a site intended to show multiple URLs at once.
Additionally, since search engines rely on links, and frame pages will often change content for users without changing the URL, external links often point to the wrong URL unintentionally. As a consequence, links to the page containing the frame or iframe may actually not point to the content the linker wanted to point to. Figure 6-14 shows an example page that illustrates how multiple pages are combined into a single URL with frames, which results in link distribution and spidering issues.
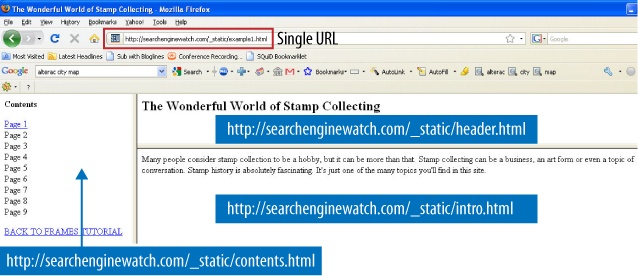
Although search engine spiders have become more advanced over the years, the basic premise and goals remain the same: spiders find web pages by following links and record the content of the pages they find in the search engine’s index (a giant repository of data about websites and pages).
In addition to avoiding the techniques we just discussed, there are some additional guidelines for developing search-engine-friendly navigation:
- Implement a text-link-based navigational structure
If you choose to create navigation in Flash, JavaScript, or other technologies, make sure to offer alternative text links in HTML for spiders to ensure that automated robots (and visitors who may not have the required browser plug-ins) can reach your pages.
- Beware of “spider traps”
Even intelligently coded search engine spiders can get lost in infinite loops of links that pass between pages on a site. Intelligent architecture that avoids looping 301 or 302 server codes (or other redirection protocols) should negate this issue, but sometimes online calendar links, infinite pagination that loops, or massive numbers of ways in which content is accessible or sorted can create tens of thousands of pages for search engine spiders when you intended to have only a few dozen true pages of content. You can read more about Google’s viewpoint on this at http://googlewebmastercentral.blogspot.com/2008/08/to-infinity-and-beyond-no.html.
- Watch out for session IDs and cookies
As we just discussed, if you limit the ability of a user to view pages or redirect based on a cookie setting or session ID, search engines may be unable to crawl your content. The bots do not have cookies enabled, nor can they deal with session IDs properly (each visit by the crawler gets a URL with a different session ID and the search engine sees these URLs with session IDs as different URLs). Although restricting form submissions is fine (as search spiders can’t submit forms anyway), limiting content access via cookies and session IDs is a bad idea. Does Google allow you to specify parameters in URLs? Yahoo! does. You can read more about it on seroundtable.com.
- Server, hosting, and IP issues
Server issues rarely cause search engine ranking problems—but when they do, disastrous consequences can follow. The engines are acutely aware of common server problems, such as downtime or overloading, and will give you the benefit of the doubt (though this will mean your content cannot be spidered during periods of server dysfunction).
The IP address of your host can be of concern in some instances. IPs once belonging to sites that have spammed the search engines may carry with them negative associations that can hinder spidering and ranking. The engines aren’t especially picky about shared hosting versus separate boxes, or about server platforms, but you should be cautious and find a host you trust.
Search engines have become paranoid about the use of certain domains, hosting problems, IP addresses, and blocks of IPs. Experience tells them that many of these have strong correlations with spam, and thus, removing them from the index can have great benefits for users. As a site owner not engaging in these practices, it pays to investigate your web host prior to getting into trouble.
You can read more about server and hosting issues in Identifying Current Server Statistics Software and Gaining Access in Chapter 4.