
Modern commercial search engines rely on the science of information retrieval (IR). This science has existed since the middle of the twentieth century, when retrieval systems powered computers in libraries, research facilities, and government labs. Early in the development of search systems, IR scientists realized that two critical components comprised the majority of search functionality: relevance and importance (which we defined earlier in this chapter). To measure these factors, search engines perform document analysis (including semantic analysis of concepts across documents) and link (or citation) analysis.
In document analysis, search engines look at whether they find the search terms in important areas of the document—the title, the metadata, the heading tags, and the body of the text. They also attempt to automatically measure the quality of the document based on document analysis, as well as many other factors.
Reliance on document analysis alone is not enough for today’s search engines, so they also look at semantic connectivity. Semantic connectivity refers to words or phrases that are commonly associated with one another. For example, if you see the word aloha you associate it with Hawaii, not Florida. Search engines actively build their own thesaurus and dictionary to help them determine how certain terms and topics are related. By simply scanning their massive databases of content on the Web, they can use Fuzzy Set Theory and certain equations (described at http://forums.searchenginewatch.com/showthread.php?threadid=48) to connect terms and start to understand web pages/sites more like a human does.
The professional SEO practitioner does not necessarily need to use semantic connectivity measurement tools to optimize websites, but for those advanced practitioners who seek every advantage, semantic connectivity measurements can help in each of the following sectors:
Measuring which keyword phrases to target
Measuring which keyword phrases to include on a page about a certain topic
Measuring the relationships of text on other high-ranking sites/pages
Finding pages that provide “relevant” themed links
Although the source for this material is highly technical, SEO specialists need only know the principles to obtain valuable information. It is important to keep in mind that although the world of IR has hundreds of technical and often difficult-to-comprehend terms, these can be broken down and understood even by an SEO novice.
Table 2-1 explains some common types of searches in the IR field.
Table 2-1. Common types of searches
Proximity searches | A proximity search uses the order of the search phrase to find related documents. For example, when you search for “sweet German mustard” you are specifying only a precise proximity match. If the quotes are removed, the proximity of the search terms still matters to the search engine, but it will now show documents that don’t exactly match the order of the search phrase, such as Sweet Mustard—German. |
Fuzzy logic | Fuzzy logic technically refers to logic that is not categorically true or false. A common example is whether a day is sunny (is 50% cloud cover a sunny day, etc.). In search, fuzzy logic is often used for misspellings. |
Boolean searches | These are searches that use Boolean terms such as AND, OR, and NOT. This type of logic is used to expand or restrict which documents are returned in a search. |
Term weighting | Term weighting refers to the importance of a particular search term to the query. The idea is to weight particular terms more heavily than others to produce superior search results. For example, the appearance of the word the in a query will receive very little weight in selecting the results because it appears in nearly all English language documents. There is nothing unique about it, and it does not help in document selection. |
IR models (search engines) use Fuzzy Set Theory (an offshoot of fuzzy logic created by Dr. Lotfi Zadeh in 1969) to discover the semantic connectivity between two words. Rather than using a thesaurus or dictionary to try to reason whether two words are related to each other, an IR system can use its massive database of content to puzzle out the relationships.
Although this process may sound complicated, the foundations are simple. Search engines need to rely on machine logic (true/false, yes/no, etc.). Machine logic has some advantages over humans, but machine logic doesn’t have a way of thinking like humans, and things that are intuitive to humans can be quite hard for a computer to understand. For example, both oranges and bananas are fruits, but both oranges and bananas are not round. To a human this is intuitive.
For a machine to understand this concept and pick up on others like it, semantic connectivity can be the key. The massive human knowledge on the Web can be captured in the system’s index and analyzed to artificially create the relationships humans have made. Thus, a machine knows an orange is round and a banana is not by scanning thousands of occurrences of the words banana and orange in its index and noting that round and banana do not have great concurrence, while orange and round do.
This is how the use of fuzzy logic comes into play, and the use of Fuzzy Set Theory helps the computer to understand how terms are related simply by measuring how often and in what context they are used together.
A related concept that expands on this notion is latent semantic analysis (LSA). The idea behind this is that by taking a huge composite (index) of billions of web pages, the search engines can “learn” which words are related and which noun concepts relate to one another.
For example, using LSA, a search engine would recognize that trips to the zoo often include viewing wildlife and animals, possibly as part of a tour.
Now, conduct a search on Google for ~zoo ~trips (the tilde is a search operator; more on this later in this chapter). Note that the boldface words that are returned match the terms that are italicized in the preceding paragraph. Google is setting “related” terms in boldface and recognizing which terms frequently occur concurrently (together, on the same page, or in close proximity) in their indexes.
Some forms of LSA are too computationally expensive. For example, currently the search engines are not smart enough to “learn” the way some of the newer learning computers do at MIT. They cannot, for example, learn through their index that zebras and tigers are examples of striped animals, although they may realize that stripes and zebras are more semantically connected than stripes and ducks.
Latent semantic indexing (LSI) takes this a step further by using semantic analysis to identify related web pages. For example, the search engine may notice one page that talks about doctors and another one that talks about physicians, and determine that there is a relationship between the pages based on the other words in common between the pages. As a result, the page referring to doctors may still show up for a search query that uses the word physician instead.
Search engines have been investing in these types of technologies for many years. For example, in April 2003 Google acquired Applied Semantics, a company known for its semantic-text-processing technology. This technology currently powers Google’s AdSense advertising program, and has most likely made its way into the core search algorithms as well.
For SEO purposes, this usage opens our eyes to realizing how search engines recognize the connections between words, phrases, and ideas on the Web. As semantic connectivity becomes a bigger part of search engine algorithms, you can expect greater emphasis on the theme of pages, sites, and links. It will be important going into the future to realize the search engines’ ability to pick up on ideas and themes and recognize content, links, and pages that don’t fit well into the scheme of a website.
In link analysis, search engines measure who is linking to a site or page and what they are saying about that site/page. They also have a good grasp on who is affiliated with whom (through historical link data, the site’s registration records, and other sources), who is worthy of being trusted based on the authority of sites linking to them, and contextual data about the site on which the page is hosted (who links to that site, what they say about the site, etc.).
Link analysis goes much deeper than counting the number of links a web page or website has, as links are not created equal. Links from a highly authoritative page on a highly authoritative site will count more than other links of lesser authority. A website or page can be determined to be authoritative by combining an analysis of the linking patterns and semantic analysis.
For example, perhaps you are interested in sites about dog grooming. Search engines can use semantic analysis to identify the collection of web pages that focus on the topic of dog grooming. The search engines can then determine which of these sites about dog grooming have the most links from the set of dog grooming sites. These sites are most likely more authoritative on the topic than the others.
The actual analysis is a bit more complicated than that. For example, imagine that there are five sites about dog grooming with a lot of links from pages across the Web on the topic, as follows:
Site A has 213 topically related links.
Site B has 192 topically related links.
Site C has 203 topically related links.
Site D has 113 topically related links.
Site E has 122 topically related links.
Further, it may be that Site A, Site B, Site D, and Site E all link to each other, but none of them link to Site C. In fact, Site C appears to have the great majority of its relevant links from other pages that are topically relevant but have few links to them. In this scenario, Site C is definitively not authoritative because it is not linked to by the right sites.
This concept of grouping sites based on their relevance is referred to as a link neighborhood. The neighborhood you are in says something about the subject matter of your site, and the number and quality of the links you get from sites in that neighborhood say something about how important your site is to that topic.
The degree to which search engines rely on evaluating link neighborhoods is not clear, and is likely to differ among search engines. In addition, links from nonrelevant pages are still believed to help the rankings of the target pages. Nonetheless, the basic idea remains that a link from a relevant site should count for more than a link from a nonrelevant site.
Another factor in determining the value of a link is the way the link is implemented and where it is placed. For example, the text used in the link itself (i.e., the actual text that will go to your web page when the user clicks on it) is also a strong signal to the search engines.
This is referred to as anchor text, and if that text is keyword-rich (with keywords relevant to your targeted search terms), it will do more for your rankings in the search engines than if the link is not keyword-rich. For example, anchor text of “Dog Grooming Salon” will bring more value to a dog grooming salon’s website than anchor text of “Click here”. However, take care. If you get 10,000 links using the anchor text “Dog Grooming Salon” and you have few other links to your site, this definitely does not look natural and could lead to problems in your rankings.
The semantic analysis of a link’s value does go deeper than just the anchor text. For example, if you have that “Dog Grooming Salon” anchor text on a web page that is not really about dog grooming at all, the value of the link is less than if the page is about dog grooming. Search engines also look at the content on the page immediately surrounding the link, as well as the overall context and authority of the website that is providing the link.
All of these factors are components of link analysis, which we will discuss in greater detail in Chapter 7.
On the opposite side of the coin are words that present an ongoing challenge for the search engines. One of the greatest challenges comes in the form of disambiguation. For example, when someone types in boxers, does he mean the prize fighter, the breed of dog, or the type of underwear? Another example of this is jaguar, which is at once a jungle cat, a car, a football team, an operating system, and a guitar. Which does the user mean?
Search engines deal with these types of ambiguous queries all the time. The two examples offered here have inherent problems built into them, but the problem is much bigger than that. For example, if someone types in a query such as cars, does he:
Want to read reviews?
Want to go to a car show?
Want to buy one?
Want to read about new car technologies?
The query cars is so general that there is no real way to get to the bottom of the searcher’s intent based on this one query alone. (The exception is cases where prior queries by the same searcher may provide additional clues that the search engine can use to better determine the searcher’s intent.)
This is the reason the search engines offer diverse results. As an example, Figure 2-22 shows another generic search, this time using gdp.
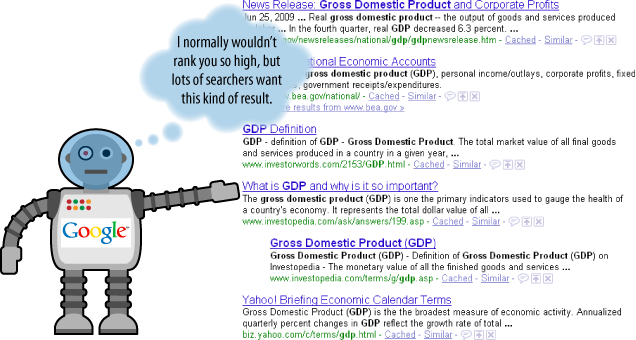
This brings up an important ranking concept. It is possible that a strict analysis of the relevance and link popularity scores in Figure 2-22 would not have resulted by itself in the Investopedia.com page being on the first page, but the need for diversity caused the ranking of the page to be elevated.
A strict relevance- and importance-based ranking system might have shown a variety of additional government pages discussing the GDP of the United States. However, a large percentage of users will likely be satisfied by the government pages already shown, and showing more of them is not likely to raise the level of satisfaction with the results.
Introducing a bit of variety allows Google to also provide a satisfactory answer to those who are looking for something different from the government pages. Google’s testing has shown that this diversity-based approach has resulted in a higher level of satisfaction among its users.
For example, the testing data for the nondiversified results may have shown lower click-through rates in the SERPs, greater numbers of query refinements, and even a high percentage of related searches performed subsequently.
When Google wants to get really serious about disambiguation, it goes a different route. Check out the SERPs in Figure 2-23.
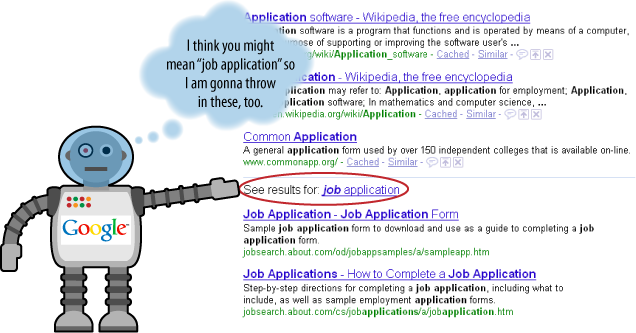
These “horizontal line,” disambiguation-style results appear on many searches where Google thinks the searcher is probably seeking something that his query isn’t producing. They’re especially likely to appear for very general search phrases.
The idea to deliberately introduce diversity into the result algorithm makes sense and can enhance searcher satisfaction for queries such as:
Company names (where searchers might want to get positive and negative press, as well as official company domains)
Product searches (where e-commerce-style results might ordinarily fill up the SERPs, but Google tries to provide some reviews and noncommercial, relevant content)
News and political searches (where it might be prudent to display “all sides” of an issue, rather than just the left- or right-wing blogs that did the best job of baiting links)
Much of the time, it makes sense for the search engines to deliver results from older sources that have stood the test of time. However, other times the response should be from newer sources of information.
For example, when there is breaking news, such as an earthquake, the search engines begin to receive queries within seconds, and the first articles begin to appear on the Web within 15 minutes.
In these types of scenarios, there is a need to discover and index new information in near-real time. Google refers to this concept as query deserves freshness (QDF). According to the New York Times (http://www.nytimes.com/2007/06/03/business/yourmoney/03google.html?pagewanted=3), QDF takes several factors into account, such as:
Search volume
News coverage
Blog coverage
Toolbar data (maybe)
QDF applies to up-to-the-minute news coverage, but also to other scenarios such as hot, new discount deals or new product releases that get strong search volume and media coverage.
As we’ve outlined in this chapter, the search engines do some amazing stuff. Nonetheless, there are times when the process does not work as well as you would like to think. Part of this is because users often type in search phrases that provide very little information about their intent (e.g., if they search on car, do they want to buy one, read reviews, learn how to drive one, learn how to design one, or something else?). Another reason is that some words have multiple meanings, such as jaguar (which is an animal, a car, a guitar, and in its plural form, a football team).
For more information on reasons why search algorithms sometimes fail, you can read the following SEOmoz article, which was written by Hamlet Batista:
| http://www.seomoz.org/blog/7-reasons-why-search-engines-dont-return-relevant-results-100-of-the-time |