
Duplicate content can result from many causes, including licensing of content to or from your site, site architecture flaws due to non-SEO-friendly CMSs, or plagiarism. Over the past five years, however, spammers in desperate need of content began the now much-reviled process of scraping content from legitimate sources, scrambling the words (through many complex processes), and repurposing the text to appear on their own pages in the hopes of attracting long tail searches and serving contextual ads (and various other nefarious purposes).
Thus, today we’re faced with a world of “duplicate content issues” and “duplicate content penalties.” Here are some definitions that are useful for this discussion:
- Unique content
This is written by humans, is completely different from any other combination of letters, symbols, or words on the Web, and is clearly not manipulated through computer text-processing algorithms (such as Markov-chain-employing spam tools).
- Snippets
These are small chunks of content such as quotes that are copied and reused; these are almost never problematic for search engines, especially when included in a larger document with plenty of unique content.
- Shingles
Search engines look at relatively small phrase segments (e.g., five to six words) for the presence of the same segments on other pages on the Web. When there are too many shingles in common between two documents, the search engines may interpret them as duplicate content.
- Duplicate content issues
This is typically used when referring to duplicate content that is not in danger of getting a website penalized, but rather is simply a copy of an existing page that forces the search engines to choose which version to display in the index (a.k.a. duplicate content filter).
- Duplicate content filter
This is when the search engine removes substantially similar content from a search result to provide a better overall user experience.
- Duplicate content penalty
Penalties are applied rarely and only in egregious situations. Engines may devalue or ban other web pages on the site, too, or even the entire website.
Assuming your duplicate content is a result of innocuous oversights on your developer’s part, the search engine will most likely simply filter out all but one of the pages that are duplicates because the search engine wants to display one version of a particular piece of content in a given SERP. In some cases, the search engine may filter out results prior to including them in the index, and in other cases the search engine may allow a page in the index and filter it out when it is assembling the SERPs in response to a specific query. In this latter case, a page may be filtered out in response to some queries and not others.
Searchers want diversity in the results, not the same results repeated again and again. Search engines therefore try to filter out duplicate copies of content, and this has several consequences:
A search engine bot comes to a site with a crawl budget, which is counted in the number of pages it plans to crawl in each particular session. Each time it crawls a page that is a duplicate (which is simply going to be filtered out of search results) you have let the bot waste some of its crawl budget. That means fewer of your “good” pages will get crawled. This can result in fewer of your pages being included in the search engine index.
Links to duplicate content pages represent a waste of link juice. Duplicated pages can gain PageRank, or link juice, and since it does not help them rank, that link juice is misspent.
No search engine has offered a clear explanation for how its algorithm picks which version of a page it does show. In other words, if it discovers three copies of the same content, which two does it filter out? Which one does it still show? Does it vary based on the search query? The bottom line is that the search engine might not favor the version you wanted.
Although some SEO professionals may debate some of the preceding specifics, the general structure will meet with near-universal agreement. However, there are a couple of problems around the edge of this model.
For example, on your site you may have a bunch of product pages and also offer print versions of those pages. The search engine might pick just the printer-friendly page as the one to show in its results. This does happen at times, and it can happen even if the printer-friendly page has lower link juice and will rank less well than the main product page.
The fix for this is to apply the canonical URL tag to all versions of the page
to indicate which version is the original.
A second version of this can occur when you syndicate content to
third parties. The problem is that the search engine may boot your copy
of the article out of the results in favor of the version in use by the
person republishing your article. The best fix for this, other than
NoIndexing the copy of the article
that your partner is using, is to have the partner implement a link back
to the original source page on your site. Search engines nearly always
interpret this correctly and emphasize your version of the content when
you do that.
Some examples will illustrate the process for Google as it finds duplicate content on the Web. In the examples shown in Figures 6-24 through 6-27, three assumptions have been made:
The page with text is assumed to be a page containing duplicate content (not just a snippet, despite the illustration).
Each page of duplicate content is presumed to be on a separate domain.
The steps that follow have been simplified to make the process as easy and clear as possible. This is almost certainly not the exact way in which Google performs (but it conveys the effect).

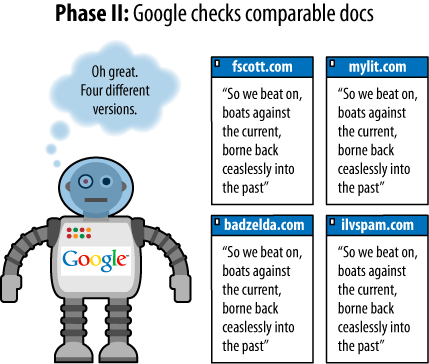
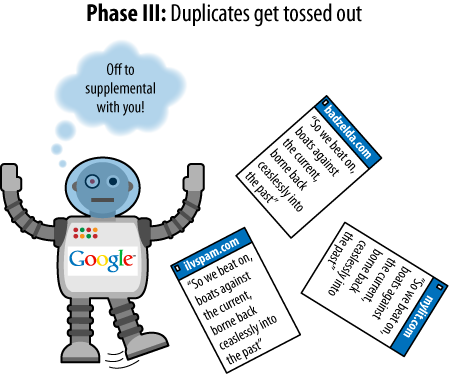
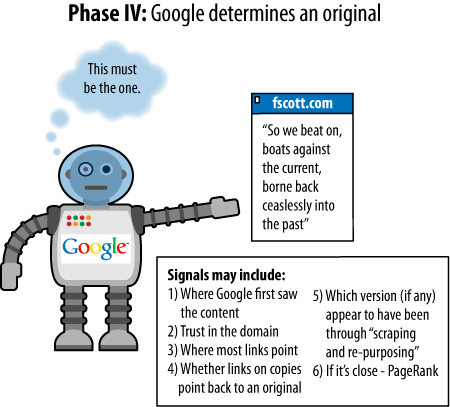
There are a few facts about duplicate content that bear mentioning as they can trip up webmasters who are new to the duplicate content issue:
- Location of the duplicate content
Is it duplicated content if it is all on my site? Yes, in fact, duplicate content can occur within a site or across different sites.
- Percentage of duplicate content
What percentage of a page has to be duplicated before you run into duplicate content filtering? Unfortunately, the search engines would never reveal this information because it would compromise their ability to prevent the problem.
It is also a near certainty that the percentage at each engine fluctuates regularly and that more than one simple direct comparison goes into duplicate content detection. The bottom line is that pages do not need to be identical to be considered duplicates.
- Ratio of code to text
What if your code is huge and there are very few unique HTML elements on the page? Will Google think the pages are all duplicates of one another? No. The search engines do not really care about your code; they are interested in the content on your page. Code size becomes a problem only when it becomes extreme.
- Ratio of navigation elements to unique content
Every page on my site has a huge navigation bar, lots of header and footer items, but only a little bit of content; will Google think these pages are duplicates? No. Google (and Yahoo! and Bing) factor out the common page elements such as navigation before evaluating whether a page is a duplicate. They are very familiar with the layout of websites and recognize that permanent structures on all (or many) of a site’s pages are quite normal. Instead, they’ll pay attention to the “unique” portions of each page and often will largely ignore the rest.
- Licensed content
What should I do if I want to avoid duplicate content problems, but I have licensed content from other web sources to show my visitors? Use
meta name = "robots" content="noindex, follow". Place this in your page’s header and the search engines will know that the content isn’t for them. This is a general best practice, because then humans can still visit the page, link to it, and the links on the page will still carry value.Another alternative is to make sure you have exclusive ownership and publication rights for that content.
One of the best ways to monitor whether your site’s copy is being duplicated elsewhere is to use CopyScape.com, a site that enables you to instantly view pages on the Web that are using your content. Do not worry if the pages of these sites are in the supplemental index or rank far behind your own pages for any relevant queries—if any large, authoritative, content-rich domain tried to fight all the copies of its work on the Web, it would have at least two 40-hour-per-week jobs on its hands. Luckily, the search engines have placed trust in these types of sites to issue high-quality, relevant, worthy content, and therefore recognize them as the original issuer.
If, on the other hand, you have a relatively new site or a site with few inbound links, and the scrapers are consistently ranking ahead of you (or someone with a powerful site is stealing your work), you’ve got some recourse. One option is to file a DMCA infringement request with Google, with Yahoo!, and with Bing (you should also file this request with the site’s hosting company).
The other option is to file a legal suit (or threaten such) against the website in question. If the site republishing your work has an owner in your country, this latter course of action is probably the wisest first step. You may want to try to start with a more informal communication asking them to remove the content before you send a letter from the attorneys, as the DMCA motions can take months to go into effect; but if they are nonresponsive, there is no reason to delay taking stronger action, either.
The preceding examples show duplicate content filters and are not actual penalties, but, for all practical purposes, they have the same impact as a penalty: lower rankings for your pages. But there are scenarios where an actual penalty can occur.
For example, sites that aggregate content from across the Web can be at risk, particularly if little unique content is added from the site itself. In this type of scenario, you might see the site actually penalized.
The only fixes for this are to reduce the number of duplicate
pages accessible to the search engine crawler, either by deleting them
or NoIndexing the pages themselves,
or to add a substantial amount of unique content.
One example of duplicate content that may get filtered out on a broad basis is a thin affiliate site. This nomenclature frequently describes a site promoting the sale of someone else’s products (to earn a commission), yet provides little or no new information. Such a site may have received the descriptions from the manufacturer of the products and simply replicated those descriptions along with an affiliate link (so that it can earn credit when a click/purchase is performed).
Search engineers have observed user data suggesting that, from a searcher’s perspective, these sites add little value to their indexes. Thus, the search engines attempt to filter out this type of site, or even ban it from their index. Plenty of sites operate affiliate models but also provide rich new content, and these sites generally have no problem. It is when duplication of content and a lack of unique, value-adding material come together on a domain that the engines may take action.
As we outlined, duplicate content can be created in many ways. Internal duplication of material requires specific tactics to achieve the best possible results from an SEO perspective. In many cases, the duplicate pages are pages that have no value to either users or search engines. If that is the case, try to eliminate the problem altogether by fixing the implementation so that all pages are referred to by only one URL. Also, 301-redirect the old URLs to the surviving URLs to help the search engines discover what you have done as rapidly as possible, and preserve any link juice the removed pages may have had.
If that process proves to be impossible, there are many options, as we will outline in Content Delivery and Search Spider Control. Here is a summary of the guidelines on the simplest solutions for dealing with a variety of scenarios:
Use the
canonicaltag. This is the next best solution to eliminating the duplicate pages.Use robots.txt to block search engine spiders from crawling the duplicate versions of pages on your site.
Use the
Robots NoIndexmeta tag to tell the search engine to not index the duplicate pages.NoFollowall the links to the duplicate pages to prevent any link juice from going to those pages. If you do this, it is still recommended that youNoIndexthose pages as well.
You can sometimes use these tools in conjunction with one another.
For example, you can NoFollow the
links to a page and also NoIndex the
page itself. This makes sense because you are preventing the page from
getting link juice from your links, and if someone else links to your
page from another site (which you can’t control), you are still ensuring
that the page does not get into the index.
However, if you use robots.txt to prevent a page from being
crawled, be aware that using NoIndex
or NoFollow on the page itself does
not make sense, as the spider can’t read the page, so it will never see
the NoIndex or NoFollow tag. With these tools in mind, here
are some specific duplicate content scenarios:
- HTTPS pages
If you make use of SSL (encrypted communications between the browser and the web server often used for e-commerce purposes), you will have pages on your site that begin with https: instead of http:. The problem arises when the links on your https: pages link back to other pages on the site using relative instead of absolute links, so (for example) the link to your home page becomes https://www.yourdomain.com instead of http://www.yourdomain.com.
If you have this type of issue on your site, you may want to use the
canonicalURL tag, which we describe in Content Delivery and Search Spider Control, or 301 redirects to resolve problems with these types of pages. An alternative solution is to change the links to absolute links (http://www.yourdomain.com/content.html instead of “/content.html”), which also makes life more difficult for content thieves that scrape your site.- CMSs that create duplicate content
Sometimes sites have many versions of identical pages because of limitations in the CMS where it addresses the same content with more than one URL. These are often unnecessary duplications with no end-user value, and the best practice is to figure out how to eliminate the duplicate pages and 301 the eliminated pages to the surviving pages. Failing that, fall back on the other options listed at the beginning of this section.
- Print pages or multiple sort orders
Many sites offer print pages to provide the user with the same content in a more printer-friendly format. Or some e-commerce sites offer their products in multiple sort orders (such as size, color, brand, and price). These pages do have end-user value, but they do not have value to the search engine and will appear to be duplicate content. For that reason, use one of the options listed previously in this subsection.
- Duplicate content in blogs and multiple archiving systems (pagination, etc.)
Blogs present some interesting duplicate content challenges. Blog posts can appear on many different pages, such as the home page of the blog, the Permalink page for the post, date archive pages, and category pages. Each instance of the post represents duplicates of the other instances. Once again, the solutions listed earlier in this subsection are the ones to use in addressing this problem.
- User-generated duplicate content (repostings, etc.)
Many sites implement structures for obtaining user-generated content, such as a blog, forum, or job board. This can be a great way to develop large quantities of content at a very low cost. The challenge is that users may choose to submit the same content on your site and in several other sites at the same time, resulting in duplicate content among those sites. It is hard to control this, but there are two things you can do to reduce the problem:
Have clear policies that notify users that the content they submit to your site must be unique and cannot be, or cannot have been, posted to other sites. This is difficult to enforce, of course, but it will still help some to communicate your expectations.
Implement your forum in a different and unique way that demands different content. Instead of having only the standard fields for entering data, include fields that are likely to be unique over what other sites do, but that will still be interesting and valuable for site visitors to see.