
Chapter 4
Understanding Table Relationships
IN THIS CHAPTER
- Understanding bulletproof database design
- Normalizing database data
- Looking at common table relationships
- Understanding integrity rules
- Adding key fields to tables
We've already covered one of the most basic assumptions about relational database systems—that data is spread across a number of tables that are related through primary and foreign keys. Although this basic principle is easy to understand, it can be much more difficult to understand why and when data should be broken into separate tables.
Because the data managed by a relational database such as Access exists in a number of different tables, there must be some way to connect the data. The more efficiently the database performs these connections, the better and more flexible the database application as a whole will function.
Although databases are meant to model real-world situations, or at least manage the data involved in real-world situations, even the most complex situation is reduced to a number of relationships between pairs of tables. As the data managed by the database becomes more complex, you may need to add more tables to the design. For example, a database to manage employee affairs for a company will include tables for employee information (name, Social Security number, address, hire date, and so on), payroll information, benefits programs the employee belongs to, and so on.
This chapter uses a variety of data from different business situations, including Northwind Traders (the traditional Access example database), a small bookstore, and the Collectible Mini Cars application used in other chapters of this book. Each dataset has somewhat different objectives from the others and is used to emphasize different aspects of relational theory. All the tables described in this chapter are contained in the Chapter04.accdb database.
When working with the actual data, however, you concentrate on the relationship between two tables at a time. You might create the Employees and Payroll tables first, connecting these tables with a relationship to make it easy to find all the payroll information for an employee.
Building Bulletproof Databases
In Chapters 1, 2, and 3, you saw examples of common relationships found in many Access databases. By far the most common type of table relationship is the one-to-many. The Collectible Mini Cars application has many such relationships: Each record in the Customers table is related to one or more records in the Sales table. (Each contact may have purchased more than one item through Collectible Mini Cars.)
You can easily imagine an arrangement that would permit the data contained in the Customers and Sales tables to be combined within a single table. All that would be needed is a separate row for each order placed by each of the contacts. As new orders come in, new rows containing the customer and order information would be added to the table.
The Access table shown in Figure 4.1, tblCustomersAndOrders, is an example of such an arrangement. In this figure, the OrderID column contains the order number placed by the contact (the data in this table has been sorted by CustomerID to show how many orders have been placed by each contact). The table in Figure 4.1 was created by combining data from the Customers and Orders tables in the Northwind Traders sample database and is included in the Chapter04.accdb database file on this book's website.

Figure 4.1 An Access table containing contact and orders data.
Notice the OrderID column to the right of the CompanyName column. Each contact (like Alfreds Futterkiste) has placed a number of orders. Columns to the far right in this table (beyond the right edge of the figure) contain more information about each contact, including address and phone numbers, while columns beyond the company information contain the specific order information. In all, this table contains 24 different fields.
The design shown in Figure 4.1 is what happens when a spreadsheet application such as Excel is used for database purposes. Because Excel is entirely spreadsheet oriented, there is no provision for breaking up data into separate tables, encouraging users to keep everything in one massive spreadsheet.
Such an arrangement has several problems:
- The table quickly becomes unmanageably large. The Northwind Traders Contacts table contains 11 different fields, while the Orders table contains 14 more. One field, OrderID, overlaps both tables. Each time an order is placed, all 24 data fields in the combined table would be added for each record added to the table, including a lot of data (such as the Contact Name and Contact Title) not directly relevant to an order.
- Data is difficult to maintain and update. Making simple changes to the data in the large table—for example, changing a contact's phone or fax number—involves searching through all records in the table and changing every occurrence of the phone number. It's easy to make an erroneous entry or miss one or more instances. The fewer records needing changes, the better off the user will be.
- A monolithic table design is wasteful of disk space and other resources. Because the combined table contains a huge amount of redundant data (for example, a contact's address is repeated for every sale), a large amount of hard disk space is consumed by the redundant information. In addition to wasted disk space, network traffic, computer memory, and other resources would be poorly utilized.
A much better design—the relational design—moves the repeated data into a separate table, leaving a field in the first table to serve as a reference to the data in the second table. The additional field required by the relational model is a small price to pay for the efficiencies gained by moving redundant data out of the table.
A second huge advantage of normalizing data and applying strict database design rules to Access applications is that the data becomes virtually bulletproof. In an appropriately designed and managed database, users are ensured that the information displayed on forms and reports truly reflects the data stored in the underlying tables. Poorly designed databases are prone to data corruption, which means that records are sometimes “lost” and never appear on forms and reports, even though users added the data to the application, or the wrong data is returned by the application's queries. In either case, the database can't be trusted because users are never sure that what they're seeing in forms and reports is correct.
Users tend to trust what they see on the screen and printed on paper. Imagine the problems that would occur if a customer were never billed for a purchase or inventory were incorrectly updated. Nothing good can come from a weak database design. As database developers, we're responsible for making sure the applications we design are as strong and resilient as possible. Following proper data normalization rules can help us achieve that goal.
Data Normalization and Denormalization
The process of splitting data across multiple tables is called normalizing the data. There are several stages of normalization; the first through the third stages are the easiest to understand and implement and are generally sufficient for the majority of applications. Although higher levels of normalization are possible, they're usually ignored by all but the most experienced and fastidious developers.
To illustrate the normalization process, I'll use a little database that a book wholesaler might use to track book orders placed by small bookstores in the local area. This database must handle the following information:
- The dates on which the books were ordered
- The customers who placed the orders
- The quantity of each book ordered
- The title of each book ordered
Although this dataset is very simple, it's typical of the type of data you might manage with an Access database application, and it provides a valid demonstration of normalizing a set of data.
First normal form
The initial stage of normalization, called first normal form (1NF), requires that the table conform to the following rule:
Each field of a table must contain only a single value, and the table must not contain repeating groups of data.
A table is meant to be a two-dimensional storage object, and storing multiple values within a field or permitting repeating groups within the table implies a third dimension to the data. Figure 4.2 shows the first attempt at building a table to manage bookstore orders (tblBookOrders1). Notice that some bookstores have ordered more than one book. A value like 7 Cookie Magic in the BookTitle field means that the contact has ordered seven copies of the cookbook titled Cookie Magic. Storing both a quantity and the item's name in the same cell is just one of several ways that this table violates first normal form.

Figure 4.2 An unnormalized tblBookOrders table.
The table in Figure 4.2 is typical of a flat-file approach to building a database. Data in a flat-file database is stored in two dimensions (rows and columns) and neglects the third dimension (related tables) possible in a relational database system such as Access.
Notice how the table in Figure 4.2 violates the first rule of normalization. Many of the records in this table contain multiple values in the BookTitle field. For example, the book titled Smokin' Hams appears in records 7 and 8. There is no way for the database to handle this data easily—if you want to cross-reference the books ordered by the bookstores, you'd have to parse the data contained in the BookTitle field to determine which books have been ordered by which contacts.
A slightly better design is shown in Figure 4.3 (tblBookOrders2). The books' quantities and titles have been separated into individual columns. Each row still contains all the data for a single order. This arrangement makes it somewhat easier to retrieve quantity and title information, but the repeating groups for quantity and title (the columns Quant1, Title1, Quant2, Title2, and so on) continue to violate the first rule of normalization. (The row height in Figure 4.3 has been adjusted to make it easier to see the table's arrangement.)

Figure 4.3 Only a slight improvement over the previous design.
The design in Figure 4.3 is still clumsy and difficult to work with. The columns to hold the book quantities and titles are permanent features of the table. The developer must add enough columns to accommodate the maximum number of books that could be purchased on a single order. For example, let's assume that the developer anticipates that no bookstore will ever order more than 50 books at a time. This means that 100 columns are added to the table (two columns—Quantity and Title—are required for each book title ordered). If a bookstore orders a single book, 98 columns would sit empty in the table, a very wasteful and inefficient situation.
Based on the design shown in Figure 4.3, it would be exceedingly difficult to query tblBookOrders2 to get the sales figure for a particular book. The quantity sold for any book is scattered all over the table, in different rows and different columns, making it very difficult to know where to look for a book's sales data.
Also, if any book order exceeds 50 books, the table has to be redesigned to accommodate the additional columns needed by the order. Of course, the user might add a second row for the order, making the data in the table more difficult to work with than intended.
Figure 4.4 shows tblBookOrders3, a new table created from the data in Figure 4.3 in first normal form. Instead of stacking multiple book orders within a single record, in tblBookOrders3 each record contains a single book ordered by a customer. More records are required, but the data is handled much more easily. First normal form is much more efficient because the table contains no unused fields. Every field is meaningful to the table's purpose.
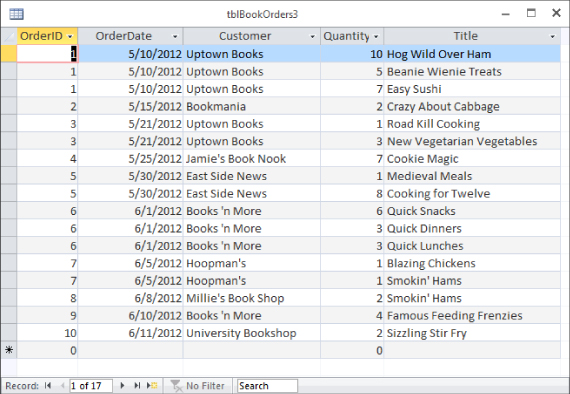
Figure 4.4 First normal form at last!
The table in Figure 4.4 contains the same data as shown in Figure 4.2 and Figure 4.3. The new arrangement, however, makes it much easier to work with the data. For example, queries are easily constructed to return the total number of a particular book ordered by contacts, or to determine which titles have been ordered by a particular bookstore.
The table design optimization is not complete at this point, however. Much remains to be done with the BookOrders data and the other tables in this application. In particular, the table shown in Figure 4.4 contains redundant information. The book titles are repeated each time customers order the same book, and the order number and order date are repeated for all the rows for an order.
A more subtle issue is the fact that the OrderID can no longer be used as the table's primary key. Because the OrderID is duplicated for each book title in an order, it can't be used to identify individual records in the table. Instead, the OrderID field is now a key field for the table and can be used to locate all the records relevant to a particular order. The next step of optimization corrects this situation.
Second normal form
A more efficient design results from splitting the data in tblBookOrders into multiple tables to achieve second normal form (2NF). The second rule of normalization states the following:
Data not directly dependent on the table's primary key is moved into another table.
This rule means that a table should contain data that represents a single entity. Because we're gradually turning one unnormalized table into normalized data, tblBookOrders3 doesn't have a primary key. We'll ignore that fact for the time being and think of each row in a table as an entity. All the data in that row that isn't an integral part of the entity is moved to a different table. In tblBookOrders3, neither the Customer field nor the Title field is integral to the order and should be moved to a different table.
Identifying entities
But aren't customers integral to an order? Yes, they are. However, the data that's stored in tblBookOrders3 in the Customer field is the customer's name. If the customer were to change names, it would not fundamentally change the order. Similarly, while the book is integral to the order, the book's title is not.
To remedy this situation, we need separate tables for customers and books. First, create a new table named tblBookStores, as shown in Figure 4.5.

Figure 4.5 Moving customer data to its own table.
To create tblBookStores follow these steps:
- Click Table Design on the Create tab of the Ribbon.
- Add an AutoNumber field named BookStoreID.
- Click Primary Key on the Table Tools Design tab of the Ribbon.
- Add a Short Text field named StoreName.
- Set the length of StoreName to 50.
- Save the table as tblBookStores.
You can imagine that we want to store some more information about customers, such as their mailing addresses and phone numbers. For now, we're getting our data into 2NF by moving data that isn't integral to an order to its own table.
Next create a table for books by following these steps:
- Click Table Design on the Create tab of the Ribbon.
- Add an AutoNumber field named BookID.
- Click Primary Key on the Table Tools Design tab of the Ribbon.
- Add a Short Text field named BookTitle.
- Save the table as tblBooks.
The customer and the book are still integral to the order (just not the name and title) and we need a way to relate the tables to each other. While the customer may change names, the customer can't change the BookStoreID because we created it and we control it. Similarly, the publisher may change the book's title but not the BookID. The primary keys of tblBookStores and tblBooks are reliable pointers to the objects they identify, regardless of what other information may change.
Figure 4.6 shows our three tables, but instead of a customer name and a book title, tblBookOrder3 now contains the primary key of its related record in both tblBookStores and tblBooks. When the primary key of one table is used as a field in another table, it's called a foreign key.

Figure 4.6 The first step in making our table 2NF.
Before we split out the customer data to its own table, if Uptown Books changed its name to Uptown Books and Periodicals, we would have to identify all the rows in tblBookOrders3 that had a customer of Uptown Books and change the field's value for each row identified.
Overlooking an instance of the customer's name during this process is called an update anomaly and results in records that are inconsistent with the other records in the database. From the database's perspective, Uptown Books and Uptown Books and Periodicals are two completely different organizations, even if we know that they're the same store. A query to retrieve all the orders placed by Uptown Books and Periodicals will miss any records that still have Uptown Books in the Customer field because of the update anomaly.
Another advantage of removing the customer name from the orders table is that the name now exists in only one location in the database. If Uptown Books changes its name to Uptown Books and Periodicals, we now only have to change its entry in the tblBookStores table. This single change is reflected throughout the database, including all forms and reports that use the customer name information.
Identifying separate entities and putting their data into separate tables is a great first step to achieving second normal form. But we're not quite done. Our orders table still doesn't have a unique field that we can use as the primary key. The OrderID field has repeating values that provide a clue that there is more work to be done to achieve 2NF.
Less obvious entities
Customers and books are physical objects that are easy to identify as separate entities. The next step is a little more abstract. Our orders table, now called tblBookOrders4, still contains information about two separate, but related, entities. The order is one entity, and the order details (the individual lines on the order) are entities all their own.
The first three records of tblBookOrders4, shown in Figure 4.6, contain the same OrderID, OrderDate, and BookStoreID. These three fields are characteristics of the order as a whole, not of each individual line on the order. The Quantity and BookID fields contain different values in those three first records. Quantity and BookID are characteristics of a particular line on the order.
The last step to get our order data into second normal form is to put the information integral to the order as a whole into a separate table from the information for each line on the order. Create a new table named tblBookOrderDetails with the fields BookOrderDetailID, Quantity, and BookID. BookOrderDetailID is an AutoNumber field that will serve as the primary key, and BookID is a foreign key field that we use to relate the two tables. Figure 4.7 shows our new orders table, tblBookOrders5, and our new details table, tblBookOrderDetails.
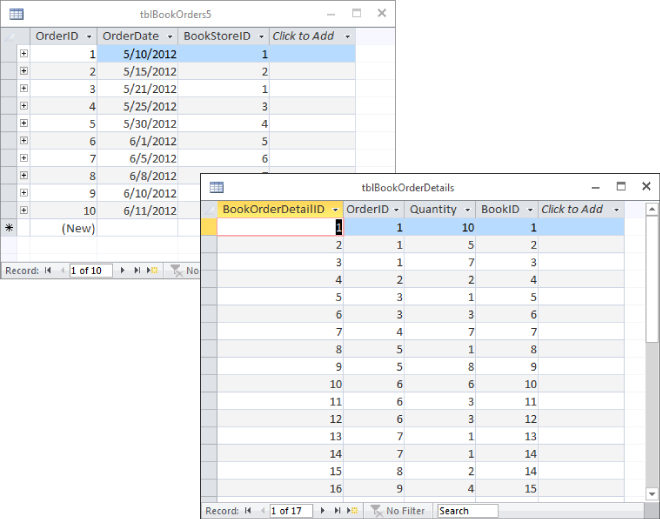
Figure 4.7 We have achieved second normal form.
The OrderID field in tblBookOrders5 was deleted and a new AutoNumber field named OrderID was created. Now that we have a unique field in the orders table, we can set OrderID as the primary key. All the data in each record of tblBookOrders5 directly relates to an order entity. Or, in 2NF language, all the data is directly dependent on the primary key.
The OrderID field in tblBookOrderDetails is a foreign key that is used to relate the two tables together. Figure 4.7 shows that the first three records in tblBookOrderDetails show an OrderID of 1 that maps to the first record of tblBookOrders5.
All the fields in tblBookOrderDetails are directly dependent on the primary key BookOrderDetailID. The quantity from the first record, 10, relates directly to that line item on the order. It only relates to the order as a whole indirectly, just as the quantities from the next two records, 5 and 7, do. That indirect relationship is created by including the OrderID foreign key in the record.
The original table, tblBookOrders1, contained data about several different entities in each record. Through a series of steps, we split the data into four tables—tblBookOrders5, tblBookOrderDetails, tblCustomers, and tblBooks—each of which contains data about one entity. Our data is finally in the second normal form.
Breaking a table into individual tables, each of which describes some aspect of the data, is called decomposition. Decomposition is a very important part of the normalization process. Even though the tables appear smaller than the original table (refer to Figure 4.2), the data contained within the tables is the same as before.
A developer working with the bookstore tables is able to use queries to recombine the data in the four tables in new and interesting ways. It'd be quite easy to determine how many books of each type have been ordered by the different customers, or how many times a particular book has been ordered. When coupled with a table containing information such as book unit cost, book selling price, and so on, the important financial status of the book wholesaler becomes clear.
Notice also that the number of records in tblBookOrders5 has been reduced. This is one of several advantages to using a relational database. Each table contains only as much data as is necessary to represent the entity (in this case, a book order) described by the table. This is far more efficient than adding duplicate field values (refer to Figure 4.2) for each new record added to a table.
Breaking the rules
From time to time, you might find it necessary to break the rules. For example, let's assume that the bookstores are entitled to discounts based on the volume of purchases over the last year. Strictly following the rules of normalization, the discount percentage should be included in the tblBookStores table. After all, the discount is dependent on the customer, not on the order.
But maybe the discount applied to each order is somewhat arbitrary. Maybe the book wholesaler permits the salespeople to cut special deals for valued customers. In this case, you might want to include a Discount column in the table containing book orders information, even if it means duplicating information in many records. You could store the traditional discount as part of the customer's record in tblBookStores, and use it as the default value for the Discount column but permit the salesperson to override the discount value when a special arrangement has been made with the customer.
In fact, it only appears that this breaks the second normal form. The default discount is directly dependent on the customer. The actual discount given is directly dependent on the order. A similar situation might exist with shipping addresses. A customer may have most of their orders shipped to them, but occasionally they may want to have an order shipped directly to their customer. The customer's shipping address directly relates to the customer, and the address where the order was actually shipped relates directly to the order. Values in object tables that serve as default values in transaction tables are common in large databases.
Third normal form
The last step of normalization, called third normal form (3NF), requires removing all fields that can be derived from data contained in other fields in the table or other tables in the database. For example, let's say the sales manager insists that you add a field to contain the total number of books in an order in the Orders table. This information, of course, would be calculated from the Quantity field in tblBookOrderDetails.
It's not really necessary to add the new OrderTotal field to the Orders table. Access easily calculates this value from data that is available in the database. The only advantage of storing order totals as part of the database is to save the few milliseconds required for Access to retrieve and calculate the information when the calculated data is needed by a form or report.
Removing calculated data maintains the integrity of the data in your database. Figure 4.7 shows three records in tblBookOrderDetails that relate to the order with OrderID of 1. Summing the Quantity field, you can see that 22 books were ordered. If there were an OrderTotal field and the total were incorrectly entered as 33 instead of 22, the data would be inconsistent. A report showing total books ordered using the OrderTotal field would show a different number than a report based on the Details table.
Depending on the applications you build, you might find good reasons to store calculated data in tables, particularly if performing the calculations is a lengthy process, or if the stored value is necessary as an audit check on the calculated value printed on reports. It might be more efficient to perform the calculations during data entry (when data is being handled one record at a time) instead of when printing reports (when many thousands of records are manipulated to produce a single report).
As you'll read in the “Denormalization” section later in this chapter, there are some good reasons why you might choose to include calculated fields in a database table. As you'll read in this section, most often the decision to denormalize is based on a need to make sure the same calculated value is stored in the database as is printed on a report.
Denormalization
After hammering you with all the reasons why normalizing your databases is a good idea, let's consider when you might deliberately choose to denormalize tables or use unnormalized tables.
Generally speaking, you normalize data in an attempt to improve the performance of your database. For example, in spite of all your efforts, some lookups will be time consuming. Even when using carefully indexed and normalized tables, some lookups require quite a bit of time, especially when the data being looked up is complicated or there's a large amount of it.
Similarly, some calculated values may take a long time to evaluate. You may find it more expedient to simply store a calculated value than to evaluate the expression on the fly. This is particularly true when the user base is working on older, memory-constrained, or slow computers.
Another common reason for denormalizing data is to provide the ability to exactly reproduce a document as it was originally produced. For example, if you need to reprint an invoice from a year ago but the customer's name has changed in the last year, reprinting the invoice will show the new name in a perfectly normalized database. If there are business reasons that dictate the invoice be reproducible precisely, the customer's name may need to be stored in the invoice record at the time the invoice is created.
Be aware that most steps to denormalize a database schema result in additional programming time required to protect the data and user from the problems caused by an unnormalized design. For example, in the case of the calculated OrderTotal field, you must insert code that calculates and updates this field whenever the data in the fields underlying this value changes. This extra programming, of course, takes time to implement and time to process at run time.
Finally, always document whatever you've done to denormalize the design. It's entirely possible that you or someone else will be called in to provide maintenance or to add new features to the application. If you've left design elements that seem to violate the rules of normalization, your carefully considered work may be undone by another developer in an effort to “optimize” the design. The developer doing the maintenance, of course, has the best of intentions, but he may inadvertently re-establish a performance problem that was resolved through subtle denormalization.
One thing to keep in mind is that denormalization is almost always done for reporting purposes, rather than simply to maintain data in tables. Consider a situation in which a customer has been given a special discount that doesn't correspond to his traditional discount. It may be very useful to store the actual amount invoiced to the customer, instead of relying on the database to calculate the discount each time the report is printed. Storing the actual amount ensures that the report always reflects the amount invoiced to the customer, instead of reporting a value that depends on other fields in the database that may change over time.
Table Relationships
Many people start out using a spreadsheet application like Excel to build a database. Unfortunately, a spreadsheet stores data as a two-dimensional worksheet (rows and columns) with no easy way to connect individual worksheets together. You must manually connect each cell of the worksheet to the corresponding cells in other worksheets—a tedious process at best.
Two-dimensional storage objects like worksheets are called flat-file databases because they lack the three-dimensional quality of relational databases. Figure 4.8 shows an Excel worksheet used as a flat-file database.
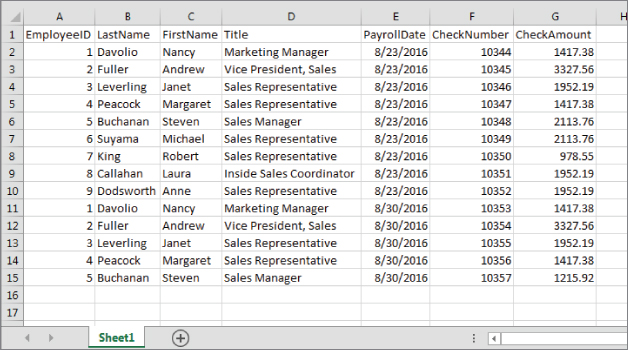
Figure 4.8 An Excel worksheet used as a flat-file database.
The problems with flat-file databases should be immediately apparent from viewing Figure 4.8. Notice that the employee information is duplicated in multiple rows of the worksheet. Each time a payroll check is issued to an employee, a new row is added to the worksheet. Obviously, this worksheet would rapidly become unmanageably large and unwieldy.
Consider the amount of work required to make relatively simple changes to the data in Figure 4.8. For example, changing an employee's title requires searching through numerous records and editing the data contained within individual cells, creating many opportunities for errors.
Through clever programming in the Excel VBA language, it would be possible to link the data in the worksheet shown in Figure 4.8 with another worksheet containing paycheck detail information. It would also be possible to programmatically change data in individual rows. But such Herculean efforts are needless when you harness the power of a relational database such as Access.
Connecting the data
A table's primary key uniquely identifies the records in a table. In a table of employee data, the employee's Social Security number, a combination of first and last names, or an employee ID might be used as the primary key. Let's assume the employee ID is selected as the primary key for the Employees table. When the relationship to the Payroll table is formed, the EmployeeID field is used to connect the tables together. Figure 4.9 shows this sort of arrangement (see the “One-to-many” section later in this chapter).

Figure 4.9 The relationship between the Employees and Payroll tables is an example of a typical one-to-many relationship.
Some of the issues related to using natural keys (such as Social Security number) are discussed in the “Natural versus surrogate primary keys” section later in this chapter.
Although you can't see the relationship in Figure 4.9, Access knows it's there because a formal relationship has been established between tblEmployees and tblPayroll. (This process is described in the “Creating relationships and enforcing referential integrity” section later in this chapter.) Because of the relationship between these tables, Access is able to instantly retrieve all the records from tblPayroll for any employee in tblEmployees.
The relationship example shown in Figure 4.9, in which each record of tblEmployees is related to several records in tblPayroll, is the most common type found in relational database systems, but it's by no means the only way that data in tables is related. This book, and most books on relational databases such as Access, discuss the three basic types of relationships between tables:
- One-to-one
- One-to-many
- Many-to-many
Figure 4.10 shows most of the relationships in the Collectible Mini Cars database.

Figure 4.10 Most of the Collectible Mini Cars table relationships.
Notice that there are several one-to-many relationships between the tables (for example, tblSales-to-tblSalesLineItems, tblProducts-to-tblSalesLineItems, and tblCustomers-to-tblSales). The relationship that you specify between tables is important. It tells Access how to find and display information from fields in two or more tables. The program needs to know whether to look for only one record in a table or look for several records on the basis of the relationship. tblSales, for example, is related to tblCustomers as a many-to-one relationship. This is because the focus of the Collectible Mini Cars system is on sales. This means that there will always be only one customer related to every sales record. That is, many sales can be associated with a single customer. In this case, the Collectible Mini Cars system is actually using tblCustomers as a lookup table.
One-to-one
A one-to-one relationship between tables means that for every record in the first table, one and only one record exists in the second table. Figure 4.11 illustrates this concept.

Figure 4.11 A one-to-one relationship.
Pure one-to-one relationships are not common in relational databases. In most cases, the data contained in the second table is included in the first table. As a matter of fact, one-to-one relationships are generally avoided because they violate the rules of normalization. Following the rules of normalization, data should not be split into multiple tables if the data describes a single entity. Because a person has one and only one birth date, the birth date should be included in the table containing a person's other data.
There are times, however, when storing certain data along with other data in the table isn't a good idea. For example, consider the situation illustrated in Figure 4.11. The data contained in tblSecurityIDs is confidential. Normally, you wouldn't want anyone with access to the public customer information (name, address, and so on) to have access to the confidential security code that the customer uses for purchasing or billing purposes. If necessary, tblSecurityIDs could be located on a different disk somewhere on the network, or even maintained on removable media to protect it from unauthorized access.
Another instance of a one-to-one relationship is a situation known as subtyping. For example, your database may contain a Customers table and a Vendors table. If both your customers and vendors are businesses, a lot of the information for both entities may be similar. In that case, you may prefer to have a Companies table that contains all the data that is similar, such as CompanyName, Address, and TaxIdentificationNumber. Then your Customers and Vendors table would contain a reference to the Companies table and include additional fields that are particular to customers and vendors, respectively. The customer and vendor entities are subtypes of the companies and related one-to-one.
A common situation for one-to-one relationships is when data is being transferred or shared among databases. Perhaps the shipping clerk in an organization doesn't need to see all of a customer's data. Instead of including irrelevant information—such as job titles, birth dates, alternate phone numbers, and e-mail addresses—the shipping clerk's database contains only the customer's name, address, and other shipping information. A record in the Customers table in the shipping clerk's database has a one-to-one relationship with the corresponding record in the master Customers table located on the central computer somewhere within the organization. Although the data is contained within separate ACCDB files, the links between the tables can be live (meaning that changes to the master record are immediately reflected in the shipping clerk's ACCDB file).
One-to-many
A far more common relationship between tables in a relational database is the one-to-many. In one-to-many relationships, each record in the first table (the parent) is related to one or more records in the second table (the child). Each record in the second table is related to one and only one record in the first table.
Without a doubt, one-to-many relationships are the most common type encountered in relational database systems. Examples of one-to-many situations abound:
- Customers and orders: Each customer (the “one” side) has placed several orders (the “many” side), but each order is sent to a single customer.
- Teacher and student: Each teacher has many students, but each student has a single teacher (within a particular class, of course).
- Employees and paychecks: Each employee has received several paychecks, but each paycheck is given to one and only one employee.
- Patients and appointments: Each patient has zero or more doctor appointments, but each appointment is for one patient.
As we discuss in the “Creating relationships and enforcing referential integrity” section later in this chapter, Access makes it very easy to establish one-to-many relationships between tables. A one-to-many relationship is illustrated in Figure 4.12. This figure, using tables from the Northwind Traders database, clearly demonstrates how each record in the Customers table is related to several different records in the Orders table. An order can be sent to only a single customer, so all requirements of one-to-many relationships are fulfilled by this arrangement.

Figure 4.12 The Northwind Traders database contains many examples of one-to-many relationships.
Although the records on the “many” side of the relationship illustrated in Figure 4.12 are sorted by the Customer field in alphabetical order, there is no requirement that the records in the “many” table be arranged in any particular order.
Notice how difficult it would be to record all the orders for a customer if a separate table were not used to store the order's information. The flat-file alternative discussed earlier in this section requires much more updating than the one-to-many arrangement shown in Figure 4.12. Each time a customer places an order with Northwind Traders, a new record is added to the Orders table. In a one-to-many arrangement, only the CustomerID (for example, AROUT) is added to the Orders table. The CustomerID is a foreign key that relates the order back to the Customers table. Keeping the customer information is relatively trivial because each customer record appears only once in the Customers table.
Many-to-many
You'll come across many-to-many situations from time to time. In a many-to-many arrangement, each record in both tables can be related to zero, one, or many records in the other table. An example is shown in Figure 4.13. Each student in tblStudents can belong to more than one club, while each club in tblClubs has more than one member.

Figure 4.13 A database of students and the clubs they belong to is an example of a many-to-many relationship.
As indicated in Figure 4.13, many-to-many relationships are somewhat more difficult to understand because they can't be directly modeled in relational database systems like Access. Instead, the many-to-many relationship is broken into two separate one-to-many relationships, joined through a linking table (called a join table). The join table has one-to-many relationships with both of the tables involved in the many-to-many relationship. This principle can be a bit confusing at first, but close examination of Figure 4.13 soon reveals the beauty of this arrangement.
In Figure 4.13, you can see that Jeffrey Walker (StudentID 12) belongs to both the Horticulture and Photography clubs (ClubID = 2 and ClubID = 3), an example of one student belonging to many clubs. You can also see that the French club (ClubID = 4) has Barry Williams and David Berry (StudentIDs 7 and 9), an example of one club having many students. Each student belongs to multiple clubs, and each club contains multiple members.
Because of the additional complication of the join table, many-to-many relationships are often considered more difficult to establish and maintain. Fortunately, Access makes such relationships quite easy to establish, if a few rules are followed. These rules are explained in various places in this book. For example, in order to update either side of a many-to-many relationship (for example, to change club membership for a student), the join table must contain the primary keys of both tables joined by the relationship.
Many-to-many relationships are quite common in business environments:
- Lawyers to clients (or doctors to patients): Each lawyer may be involved in several cases, while each client may be represented by more than one lawyer on each case.
- Patients and insurance coverage: Many people are covered by more than one insurance policy. For example, if you and your spouse are both provided medical insurance by your employers, you have multiple coverage.
- Video rentals and customers: Over a year's time, each video is rented by several people, while each customer rents more than one video during the year.
- Magazine subscriptions: Most magazines have circulations measured in the thousands or millions. Most people subscribe to more than one magazine at a time.
The Collectible Mini Cars database has a many-to-many relationship between tblCustomers and tblSalesPayments, linked through tblSales. Each customer might have purchased more than one item, and each item might be paid for through multiple payments. In addition to joining contacts and sales payments, tblSales contains other information, such as the sale date and invoice number. The join table in a many-to-many relationship often contains information regarding the joined data.
As shown in Figure 4.13 join tables can contain information other than the primary keys of the tables they join. The tblStudentToClubJoin table includes a field to record the date that the related student joined the related club.
Integrity Rules
Access permits you to apply referential integrity rules that protect data from loss or corruption. Referential integrity means that the relationships between tables are preserved during updates, deletions, and other record operations. The relational model defines several rules meant to enforce the referential integrity requirements of relational databases. In addition, Access contains its own set of referential integrity rules that are enforced by the ACE database engine.
Imagine a payroll application that contained no rules regulating how data in the database is used. It would be possible to issue payroll checks that aren't linked to an employee, for instance. From a business perspective, issuing paychecks to “phantom” employees is a very serious situation. Eventually, the issue will be noticed when the auditors step in and notify management of the discrepancy.
Referential integrity operates strictly on the basis of the tables' key fields. Referential integrity means that the database engine checks each time a key field (whether primary or foreign) is added, changed, or deleted. If a change to a value in a key field invalidates a relationship, it is said to violate referential integrity. Tables can be set up so that referential integrity is automatically enforced.
Figure 4.14 illustrates a relationship between a Customers table and a Sales table. tblCustomers is related to tblSales through the CustomerID field. The CustomerID field in tblCustomers is the primary key, while the CustomerID field in tblSales is a foreign key. The relationship connects each customer with a sales invoice. In this relationship, tblCustomers is the parent table, while tblSales is the child table.

Figure 4.14 A typical database relationship.
Orphaned records are very bad in database applications. Because sales information is almost always reported as which products were sold to which customers, a sales invoice that is not linked to a valid customer will not be discovered under most circumstances. It's easy to know which products were sold to Fun Zone, but given an arbitrary sales record, it may not be easy to know that there is no valid customer making the purchase. In Figure 4.14, the invoice records related to Fun Zone are indicated by boxes drawn around the data in tblSales.
Because the referential integrity rules are enforced by the Access database engine, data integrity is ensured wherever the data appear in the database: in tables, queries, or forms. Once you've established the integrity requirements of your applications, you don't have to be afraid that data in related tables will become lost or disorganized.
We can't overemphasize the need for referential integrity in database applications. Many developers feel that they can use VBA code or user interface design to prevent orphaned records. The truth is that, in most databases, the data stored in a particular table may be used in many different places within the application, or even in other applications that use the data. Also, given the fact that many database projects extend over many years, and among any number of developers, it's not always possible to recall how data should be protected. By far, the best approach to ensuring the integrity of data stored in any database system is to use the power of the database engine to enforce referential integrity.
The general relational model referential integrity rules ensure that records contained in relational tables are not lost or confused. For obvious reasons, it's important that the primary keys connecting tables be protected and preserved. Also, changes in a table that affect other tables (for example, deleting a record on the “one” side of a one-to-many relationship) should be rippled to the other tables connected to the first table. Otherwise, the data in the two tables will quickly become unsynchronized.
No primary key can contain a null value
The first referential integrity rule states that no primary key can contain a null value. A null value is one that simply does not exist. The value of a field that has never been assigned a value (even a default value) is null. No row in a database table can have null in its primary key because the main purpose of the primary key is to guarantee uniqueness of the row. Obviously, null values cannot be unique and the relational model would not work if primary keys could be null. Access will not allow you to set a field that already contains null values as the primary key.
Furthermore, Access can't evaluate a null value. Because a null value doesn't exist, it can't be compared with any other value. It isn't larger or smaller than any other value; it simply doesn't exist. Therefore, a null value can't be used to look up a record in a table or to form a relationship between two tables.
Access automatically enforces the first referential integrity rule. As you add data to tables, you can't leave the primary key field empty without generating a warning (one reason the AutoNumber field works so well as a primary key). Once you've designated a field in an Access table as the primary key, Access won't let you delete the data in the field, nor will it allow you to change the value in the field so that it duplicates a value in another record.
When using a composite primary key made up of several fields, all the fields in the composite key must contain values. None of the fields is allowed to be empty. The combination of values in the composite primary key must be unique.
All foreign key values must be matched by corresponding primary keys
The second referential integrity rule says that all foreign key values must be matched by corresponding primary keys. This means that every record in a table on the “many” (or child) side of a one-to-many relationship must have a corresponding record in the table on the “one” (or parent) side of the relationship. A record on the “many” side of a relationship without a corresponding record on the “one” side is said to be orphaned and is effectively removed from the database schema. Identifying orphaned records in a database can be very difficult, so you're better off avoiding the situation in the first place.
The second rule means the following:
- Rows cannot be added to a “many” side table (the child) if a corresponding record does not exist on the “one” side (the parent). If a child record contains a ParentID field, the ParentID value must match an existing record in the parent table.
- The primary key value in a “one” side table cannot be changed if the change would create orphaned child records.
- Deleting a row on the “one” side must not orphan corresponding records on the “many” side.
For example, in the sales example, the foreign key in each record in tblSales (the “many” side) must match a primary key in tblCustomers. You can't delete a record in tblCustomers (the “one” side) without deleting the corresponding records in tblSales.
One of the curious results of the rules of referential integrity is that it's entirely possible to have a parent record that isn't matched by any child records. Intuitively, this makes sense. A company may certainly have employees who haven't yet been issued paychecks. Or the Collectible Mini Cars company may hire a new employee who hasn't made any sales yet. Eventually, of course, most parent records are matched by one or more child records, but this condition is not a requirement of relational databases.
As you'll see in the next section, Access makes it easy to specify the integrity rules you want to employ in your applications. You should be aware, however, that not using the referential integrity rules means that you might end up with orphaned records and other data integrity problems.
Keys
When you create database tables, like those created in Chapter 3, you should assign each table a primary key. This key is a way to make sure that the table records contain only one unique value; for example, you may have several contacts named Michael Heinrich, and you may even have more than one Michael Heinrich (for example, father and son) living at the same address. So, in a case like this, you have to decide how you can create a record in the Customers database that will let you identify each Michael Heinrich separately.
Uniquely identifying each record in a table is precisely what a primary key field does. For example, using Collectible Mini Cars as an example, the CustomerID field (a unique number that you assign to each customer placing an order) is the primary key in tblCustomers—each record in the table has a different CustomerID number. (No two records have the same number.) This is important for several reasons:
- You don't want to have two records in tblCustomers for the same customer, because this can make updating the customer's record virtually impossible.
- You want assurance that each record in the table is accurate so that the information extracted from the table is accurate.
- You don't want to make the table (and its records) any larger than necessary. Adding redundant or duplicate fields and records just complicates the database without adding value.
The ability to assign a single, unique value to each record makes the table clean and reliable. This is known as entity integrity. By having a different primary key value in each record (such as the CustomerID in tblCustomers), you can tell two records (in this case, customers) apart, even if all other fields in the records are the same. This is important because you can easily have two individual customers with a common name, such as Fred Smith, in your table.
Theoretically, you could use the customer's name and address, but two people named Fred D. Smith could live in the same town and state, or a father and son (Fred David Smith and Fred Daniel Smith) could live at the same address. The goal of setting primary keys is to create individual records in a table that guarantees uniqueness.
If you don't specify a primary key when creating Access tables, Access asks whether you want one. If you say yes, Access uses the AutoNumber data type to create a primary key for the table. An AutoNumber field is automatically inserted each time a record is added to the table, and it can't be changed once its value has been established. Furthermore, once an AutoNumber value has appeared in a table, the value will never be reused, even if the record containing the value is deleted and the value no longer appears in the table. In fact, because an AutoNumber field is added to a new record before any of the other data, if the new row is not saved for some reason, the new AutoNumber is never used in the table at all.
Deciding on a primary key
As you learned earlier, a table normally has a field (or combination of fields)—the primary key for that table—which makes each record unique. The primary key is an identifier that is often a text, numeric, or AutoNumber data type. To determine the contents of this ID field, you specify a method for creating a unique value for the field. Your method can be as simple as letting Access automatically assign an AutoNumber value or using the first letter of the real value you're tracking along with a sequence number (such as A001, A002, A003, B001, B002, and so on). The method may rely on a random set of letters and numbers for the field content (as long as each field has a unique value) or a complicated calculation based on information from several fields in the table.
However, there is no reason why the primary key value has to be meaningful to the application. A primary key exists in a table solely to ensure uniqueness for each row and to provide an anchor for table relationships. Many Access developers routinely use AutoNumber fields as primary keys simply because they meet all the requirements of a primary key without contributing to an application's complexity.
In fact, meaningful primary keys can cause confusion as the data in the table changes. For example, if the primary key for a table of employee information is the first letter of the employee's last name plus a sequential number, then Jane Doe might have an EmployeeID of D001. If Jane were to get married and change her last name, her EmployeeID would no longer be consistent with the data in her record. Her EmployeeID may still be unique, but it may also cause confusion if someone were to rely on that data.
Table 4.1 lists the Collectible Mini Cars tables and describes one possible plan for deriving the primary key values in each table. As this table shows, it doesn't take a great deal of work (or even much imagination) to derive a plan for key values. Any rudimentary scheme with a good sequence number always works. Access automatically tells you when you try to enter a duplicate key value. To avoid duplication, you can simply add the value of 1 to the sequence number.
Table 4.1 Deriving the Primary Key
| Table | Possible Derivation of Primary Key Value |
| tblCustomers | Companies: AutoNumber field assigned by Access |
| tblSales | Invoice Number: AutoNumber field |
| tblSalesLineItems | Invoice Number (from Sales) and an AutoNumber field |
| tblProducts | Product Number, entered by the person putting in a new product |
| tblSalesPayments | Invoice Number (from Sales) and an AutoNumber field |
| tblSalesperson | Sales Person ID: AutoNumber field |
| tblCategories | Category of Items: Entered by the person putting in a new record |
Even though it isn't difficult to use logic (implemented, perhaps, though VBA code) to generate unique values for a primary key field, by far the simplest and easiest approach is to use AutoNumber fields for the primary keys in your tables. The special characteristics of the AutoNumber field (automatic generation, uniqueness, the fact that it can't be changed, and so on) make it the ideal candidate for primary keys. Furthermore, an AutoNumber value is nothing more than a 4-byte integer value, making it very fast and easy for the database engine to manage. For all these reasons, the Collectible Mini Cars exclusively uses AutoNumber fields as primary keys in its tables.
You may be thinking that all these sequence numbers make it hard to look up information in your tables. Just remember that, in most case, you never look up information by an ID field. Generally, you look up information according to the purpose of the table. In tblCustomers, for example, you would look up information by customer name—last name, first name, or both. Even when the same name appears in multiple records, you can look at other fields in the table (zip code, phone number) to find the correct customer. Unless you just happen to know the customer ID number, you'll probably never use it in a search for information.
Looking at the benefits of a primary key
Have you ever placed an order with a company for the first time and then decided the next day to increase your order? When you call the people at the order desk, they may ask you for your customer number. You tell them that you don't know your customer number. Next, they ask you for some other information—generally, your zip code and last name. Then, as they narrow down the list of customers, they ask your address. Once they've located you in their database, they can tell you your customer number. Some businesses use phone numbers or e-mail addresses as starting points when searching for customer records.
Database systems usually have more than one table, and the tables are related in some manner. For example, in the Collectible Mini Cars database, tblCustomers and tblSales are related to each other through the CustomerID field. Because each customer is one person or organization, you only need one record in tblCustomers.
Each customer can make many purchases, however, which means you need to set up a second table to hold information about each sale—tblSales. Again, each invoice is one sale (on a specific day at a specific time). CustomerID is used to relate the customer to the sales.
A foreign key in the child table (the CustomersID field in the tblSales table) is related to the primary key in the parent table (CustomerID in tblCustomers).
Besides being a common link field between tables, the primary key field in an Access database table has the following advantages:
- Primary key fields are always indexed, greatly speeding up queries, searches, and sorts that involve the primary key field.
- Access forces you to enter a value (or automatically provides a value, in the case of AutoNumber fields) every time you add a record to the table. You're guaranteed that your database tables conform to the rules of referential integrity.
- As you add new records to a table, Access checks for duplicate primary key values and prevents duplicates entries, thus maintaining data integrity.
- By default, Access displays your data in primary key order.
Designating a primary key
From the preceding sections, you're aware that choosing a table's primary key is an important step toward bulletproofing a database's design. When properly implemented, primary keys help stabilize and protect the data stored in your Access databases. As you read the following sections, keep in mind that the cardinal rule governing primary keys is that the values assigned to the primary key field within a table must be unique. Furthermore, the ideal primary key is stable.
Single-field versus composite primary keys
Sometimes, when an ideal primary key doesn't exist within a table as a single value, you may be able to combine fields to create a composite primary key. For example, it's unlikely that a first name or last name alone is enough to serve as a primary key, but by combining first and last names with birth dates, you may be able to come up with a unique combination of values to serve as the primary key. As you'll see in the “Creating relationships and enforcing referential integrity” section later in this chapter, Access makes it very easy to combine fields as composite primary keys.
There are several practical considerations when using composite keys:
- None of the fields in a composite key can be null.
- Sometimes composing a composite key from data naturally occurring within the table can be difficult. Sometimes records within a table differ by one or two fields, even when many other fields may be duplicated within the table.
- Each of the fields can be duplicated within the table, but the combination of composite key fields cannot be duplicated.
However, as with so many other issues in database design, composite keys have a number of issues:
- Composite keys tend to complicate a database's design. If you use three fields in a parent table to define the table's primary key, the same three fields must appear in every child table.
- Ensuring that a value exists for all the fields within a composite key (so that none of the fields is null) can be quite challenging.
Natural versus surrogate primary keys
Many developers maintain that you should use only natural primary keys. A natural primary key is derived from data already in the table, such as a Social Security number or employee number. If no single field is enough to uniquely identify records in the table, these developers suggest combining fields to form a composite primary key.
However, there are many situations where no “perfect” natural key exists in database tables. Although a field like SocialSecurityNumber may seem to be the ideal primary key, there are a number of problems with this type of data:
- The value is not universal. Not everyone has a Social Security number.
- The value may not be known at the time the record is added to the database. Because primary keys can never be null, provisions must be made to supply some kind of “temporary” primary key when the Social Security number is unknown, and then other provisions must be made to fix up the data in the parent and child tables once the value becomes known.
- Values such as Social Security number tend to be rather large. A Social Security number is at least nine characters, even omitting the dashes between groups of numbers. Large primary keys unnecessarily complicate things and run more slowly than smaller primary keys.
- Legal and privacy issues inhibit its use. A Social Security number is considered “personally identifiable information” and (in the United States) its use is limited under the Social Security Protection Act of 2005.
Although an AutoNumber value does not naturally occur in the table's data, because of the considerable advantages of using a simple numeric value that is automatically generated and cannot be deleted or changed, in most cases an AutoNumber is the ideal primary key candidate for most tables.
Creating primary keys
A primary key is created by opening a table in Design view, selecting the field(s) that you want to use as a primary key, and clicking the Primary Key button on the Table Tools Design tab of the Ribbon. If you're specifying more than one field to create a composite key, hold down the Ctrl key while using the mouse to select the fields before clicking on the Primary Key button.
Creating relationships and enforcing referential integrity
The Relationships window lets you establish the relationships and referential integrity rules that you want to apply to the tables involved in a relationship. Creating a permanent, managed relationship that ensures referential integrity between Access tables is easy:
- Select Database Tools
 Relationships. The Relationships window appears.
Relationships. The Relationships window appears. - Click the Show Table button on the Ribbon, or right-click the Relationships window and select Show Table from the shortcut menu. The Show Table dialog box (shown in Figure 4.15) appears.

Figure 4.15 Double-click a table name to add it to the Relationships window.
- Add tblBookOrders5 and tblBookOrderDetails to the Relationships window (double-click each table in the Show Table dialog box, or select each table and click the Add button).
- Create a relationship by dragging the primary key field in the “one” table and dropping it on the foreign key in the “many” table. Alternatively, drag the foreign key field and drop it on the primary key field.
For this example, drag OrderID from tblBookOrders5 and drop it on OrderID in tblBookOrderDetails. Access immediately opens the Edit Relationships dialog box (shown in Figure 4.16) to enable you to specify the details about the relationship you intend to form between the tables. Notice that Access recognizes the relationship between tblBookOrders5 and tblBookOrderDetails as a one-to-many.

Figure 4.16 You enforce referential integrity in the Edit Relationships dialog box.
- Specify the referential details you want Access to enforce in the database. In Figure 4.16, notice the Cascade Delete Related Records check box. If this check box is left unchecked, Access won't permit you to delete records in tblBookOrders5 (the “one” table) until all the corresponding records in tblBookOrderDetails (the “many” table) are first deleted. With this box checked, deletions across the relationship “cascade” automatically. Cascading deletes can be a dangerous operation because the deletions in the “many” table occur without confirmation.
- Click the Create button. Access draws a line between the tables displayed in the Relationships window, indicating the type of relationship. In Figure 4.17, the 1 symbol indicates that tblBookOrders5 is the “one” side of the relationship while the infinity symbol (∞) designates tblBookOrderDetails as the “many” side.

Figure 4.17 A one-to-many relationship between tblBookOrders5 and tblBookOrderDetails.
Specifying the join type between tables
The right side of the Edit Relations window has four buttons:
- Create: The Create button returns you to the Relationships window with the changes specified.
- Cancel: The Cancel button cancels the current changes and returns you to the Relationships window.
- Join Type: The Join Type button opens the Join Properties dialog box.
- Create New: The Create New button lets you specify an entirely new relationship between the two tables and fields.
By default, when you process a query on related tables, Access returns only records that appear in both tables. Considering the payroll example from the “Integrity Rules” section earlier in this chapter, this means that you would see only employees who have valid paycheck records in the paycheck table. You wouldn't see any employees who haven't yet received a paycheck. Such a relationship is sometimes called an inner join because the only records that appear are those that exist on both sides of the relationship.
However, the inner join is not the only type of join supported by Access. Click the Join Type button to open the Join Properties dialog box. The alternative settings in the Join Properties dialog box allow you to specify that you prefer to see all the records from either the parent table or child table, regardless of whether they're matched on the other side. (It's possible to have an unmatched child record as long as the foreign key in the child table is null.) Such a join (called an outer join) can be very useful because it accurately reflects the state of the data in the application.
In the case of the Collectible Mini Cars example, seeing all the customers, regardless of whether they have records in the Sales table, is what you're shooting for. To specify an outer join connecting customers to sales, perform these steps:
- From the Relationships window, add tblCustomers and tblSales.
- Drag the CustomerID from one table and drop it on the other. The Edit Relationships dialog box appears.
- Click the Join Type button. The Join Properties dialog box (shown in Figure 4.18) appears.

Figure 4.18 The Join Properties dialog box, used to set up the join properties between tblCustomers and tblSales. Notice that it specifies all records from the Contacts table.
- Select the Include ALL Records from ‘tblCustomers’ and Only Those Records from ‘tblSales’ Where the Joined Fields Are Equal option button.
- Click OK. You're returned to the Edit Relationships dialog box.
- Click Create. You're returned to the Relationships window. The Relationships window should now show an arrow going from the Contacts table to the Sales table. At this point, you're ready to set referential integrity between the two tables on an outer join relationship.
Given the join properties shown in Figure 4.18, any time the Customers and Sales tables are involved in a query, all the customer records are returned by default, even if a customer hasn't yet placed any orders. This setting should give a more complete impression of the company's customer base instead of restricting the returned records to customers who've placed orders.
Establishing a join type for every relationship in your database isn't absolutely necessary. In the following chapters, you'll see that you can specify outer joins for each query in your application. Many developers choose to use the default inner join for all the relationships in their databases and to adjust the join properties on each query to yield the desired results.
Enforcing referential integrity
After using the Edit Relationships dialog box to specify the relationship, to verify the table and related fields, and to specify the type of join between the tables, you should set referential integrity between the tables. Select the Enforce Referential Integrity check box in the lower portion of the Edit Relationships dialog box to indicate that you want Access to enforce the referential integrity rules on the relationship between the tables.
Enforcing referential integrity also enables two other options that you may find useful—cascading updates and cascading deletes. These options are near the bottom of the Edit Relationships dialog box (refer to Figure 4.16).
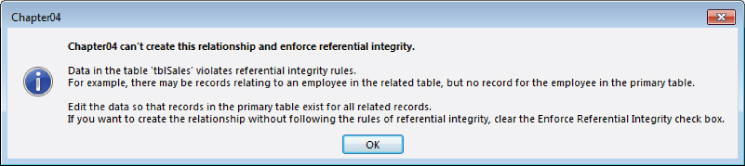
Figure 4.19 A dialog box warning that referential integrity can't be enforced because of integrity violations.
You could remove the offending records, return to the Relationships window, and set referential integrity between the two tables. Whether it's appropriate to clean up data by deleting records depends entirely on the business rules governing the application. Deleting orders just because referential integrity can't be enforced would be considered a bad idea in most environments.
Choosing the Cascade Update Related Fields option
If you specify Enforce Referential Integrity in the Edit Relationships dialog box, Access enables the Cascade Update Related Fields check box. This option tells Access that, as a user changes the contents of a related field (the primary key field in the primary table—CustomerID, for example), the new CustomerID is rippled through all related tables.
Generally speaking, however, there are very few reasons why the value of a primary key may change. The example I give in the “Connecting the data” section earlier in this chapter, of a missing Social Security number, is one case where you may need to replace a temporary Social Security number with the permanent Social Security number after employee data has been added to the database. However, when using an AutoNumber or another surrogate key value, there is seldom any reason to have to change the primary key value once a record has been added to the database. In fact, an Autonumber primary key cannot be changed.
Choosing the Cascade Delete Related Records option
The Cascade Delete Related Records option instructs Access to delete all related child records when a parent record is deleted. Although there are instances in which this option can be quite useful, as with so many other options, cascading deletes comes with a number of warnings.
For example, if you've chosen Cascade Delete Related Records and try to delete a particular customer (who moved away from the area), Access first deletes all the related records from the child tables—Sales and SalesLineItems—and then deletes the customer record. In other words, Access deletes all the records in the sales line items for each sale for each customer—the detail items of the sales, the associated sales records, and the customer record—with one step.
Perhaps you can already see the primary issue associated with cascading deletes. If all of a customer's sales records are deleted when the customer record is deleted, you have no way of properly reporting sales for the period. You couldn't, for instance, reliably report on the previous year's sales figures because all the sales records for “retired” customers have been deleted from the database. Also, in this particular example, you would lose the opportunity to report on sales trends, product category sales, and a wide variety of other uses of the application's data.
It would make much more sense to use an Active field (Yes/No data type) in the Customers table to indicate which customers are still active. It would be quite easy to include the Active field in queries where only current customers are needed (Active = Yes), and ignore the Active field in queries where all sales (regardless of the customer's active status) are required.
In general, it's probably not a good idea to enable cascading deletes in a database. It's far too easy to accidentally delete important data. Consider a situation where a user accidentally deletes a customer, wiping out the customer's entire sales history, including payments, shipping, backorders, promotions, and other activities. There are very few situations where users should be permitted to delete many different types of data as a single action.
Viewing all relationships
With the Relationships window open, click All Relationships on the Relationship Tools Design tab of the Ribbon to see all the relationships in the database. If you want to simplify the view you see in the Relationships window, you can “hide” a relationship by deleting the tables you see in the Relationships window. Click a table, press the Delete key, and Access removes the table from the Relationships window. Removing a table from the Relationships window doesn't delete any relationships between the table and other tables in the database.
When building database tables, make sure that the Required property of the foreign key field in the related table (in the case of tblBookOrders5 and tblBookOrderDetails, the foreign key is OrderID in tblBookOrderDetails) is set to Yes. This action forces the user to enter a value in the foreign key field, providing the relationship path between the tables.
The relationships formed in the Relationships window are permanent and are managed by Access. When you form permanent relationships, they appear in the Query Design window by default as you add the tables. (Queries are discussed in detail in Part III.) Even without permanent relationships between tables, you form temporary relationships any time you include multiple tables in the Query Design window.
Deleting relationships
During the design phase, even in meticulously planned designs, table structures change, which may necessitate deleting and re-establishing some of the relationsips. The Relationships window is simply a picture of the relationships between tables. If you open the Relationships window, click each of the tables in the relationship, and press the Delete key, you delete the picture of the tables in the relationship, but not the relationship itself. You must first click the line connecting the tables and press Delete to delete the relationship, and then delete each of the table pictures to completely remove the relationship.
Following application-specific integrity rules
In addition to the referential integrity rules enforced by the ACE Database Engine, you can establish a number of business rules that are enforced by the applications you build in Access. In many cases, your clients or users will tell you the business rules that must be enforced by the application. It's up to you as the developer to compose the Visual Basic code, table design, field properties, and so on that implement the business rules expected by your users.
Typical business rules include items such as the following:
- The order-entry clerk must enter his ID number on the entry form.
- Quantities can never be less than zero.
- The unit selling price can never be less than the unit cost.
- The order ship date must come after the order date.
Most often, these rules are added to a table at design time. Enforcing such rules goes a long way toward preserving the value of the data managed by the database. For example, in Figure 4.20, the ValidationRule property of the Quantity field (>=0) ensures that the quantity can't be a negative number. If the inventory clerk tries to put a negative number into the Quantity field, an error message box pops up containing the validation text: Must not be a negative number.

Figure 4.20 A simple validation rule goes a long way toward preserving the database's integrity.
You can also establish a table-wide validation rule using the Validation Rule property on the table's Property Sheet that provides some protection for the data in the table. Unfortunately, only one rule can be created for the entire table, making it difficult to provide specific validation text for all possible violations.
The Validation Rule property has some limitations. For instance, you can't use user-defined functions in a rule. Also, you can't reference other fields, data in other records, or other tables in your rules. Validation rules prevent user entry rather than provide warnings that the user can bypass. If you need to provide a warning but still allow the user to continue, you shouldn't use a validation rule.
You can read examples of using VBA to enforce business rules throughout this book.