
Chapter 3. Implementing DSLs
At this point you should have a good sense of what a DSL is and why you might be interested in using one. It’s time now to delve into the techniques that you’ll need to start building a DSL. Although many of these techniques vary between internal and external DSLs, there is also much that they have in common. In this chapter, I’ll concentrate on the common issues for internal and external DSLs, moving onto specific issues in the next chapter. I’ll also ignore language workbenches for the moment; I’ll get back to them much later on.
3.1 Architecture of DSL Processing
Figure 3.1 The overall architecture of DSL processing that I usually prefer
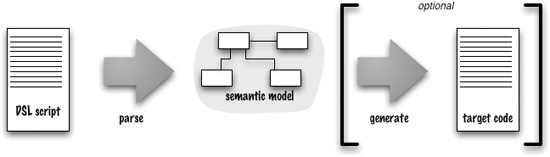
Perhaps one of the most important things to talk about is the broad structure of how DSL implementations work—what I might call the architecture of a DSL system.
By now you should be getting tired of me saying that a DSL is a thin layer over a model. When I refer to a model in this context I call it the Semantic Model pattern. The basic idea behind this pattern is that all the important semantic behavior is captured in a model, and the DSL’s role is to populate that model via a parsing step. This means that the Semantic Model plays a central role in how I think about DSLs—indeed almost all of this book assumes you are using one. (I’ll talk about alternatives to a Semantic Model at the end of this section, when I have enough context to discuss them.)
Since I’m an OO bigot, I naturally assume that a Semantic Model is an object model. I like rich object models that combine data and processing. But a Semantic Model doesn’t need to be like that; it can also be just a data structure. While I’d always rather have proper objects if I can, using a data model form of Semantic Model is better than not using a Semantic Model at all. So, although I’ll be assuming proper behavioral objects in the discussion in this book, remember that data structures are an option you may also see.
Many systems use a Domain Model [Fowler PoEAA] to capture the core behavior of a software system. Often a DSL populates a significant portion of a Domain Model. I do like to keep the notions of Domain Model and Semantic Model different. The Semantic Model of a DSL is usually a subset of the application’s Domain Model, as not all parts of the Domain Model are best handled by the DSL. In addition, DSLs may be used for tasks other than populating a Domain Model, even when one is present.
The Semantic Model is a completely normal object model, which can be manipulated in the same way as any object model you might have. In the state example, we can populate the state machine by using the command-query API of the state model, and then run it to get our state behavior. In a sense, it’s thus independent of the DSL, although in practice the two are close siblings.
(If you come from a compiler background you may be wondering whether the Semantic Model is the same as an abstract syntax tree. The short answer is that it’s a different notion; I’ll explore that in “The Workings of a Parser,” p. 47.)
Keeping a Semantic Model separate from the DSL has several advantages. The primary benefit is that you can think about the semantics of this domain without getting tangled up in the DSL syntax or parser. If you’re using a DSL at all, it’s usually because you’re representing something pretty complex, for otherwise you wouldn’t be using it. Since you’re representing something quite complex, that’s enough for it to deserve its own model.
In particular, this allows you to test the Semantic Model by creating objects in the model and manipulating them directly. I can create a bunch of states and transitions and test to see if the events and commands run, without having to deal with parsing at all. If there are problems in how the state machine executes, I can isolate the problem in the model without having to understand how the parsing works.
An explicit Semantic Model allows you to support multiple DSLs to populate it. You might start with a simple internal DSL, and later add an external DSL as a alternative version that’s easier to read. Since you have existing scripts and existing users, you might want to keep the existing internal DSL and support both. Since both DSLs can parse into the same Semantic Model, this isn’t difficult. It also helps to avoid any duplication between the languages.
More to the point, having a separate Semantic Model allows you to evolve the model and language separately. If I want to change the model, I can explore that without changing the DSL, adding the necessary constructs to the DSL once I get the model working. Or I can experiment with new syntaxes for the DSL and just verify that they create the same objects in the model. I can compare two syntaxes by comparing how they populate the Semantic Model.
In many ways, this separation of the Semantic Model and DSL syntax mirrors the separation of domain model and presentation that we see in designing enterprise software. Indeed on a hot day I think of a DSL as another form of user interface.
The comparison between DSLs and presentations also suggests limitations. The DSL and the Semantic Model are still connected. If I add new constructs to the DSL, I need to ensure they are supported in the Semantic Model, which often means modifying the two at the same time. However, the separation does mean I can think about semantic issues separately from parsing issues, which simplifies the task.
The difference between internal and external DSLs lies in the parsing step—both in what is parsed and in how the parsing is done. Both styles of DSL will produce the same kind of Semantic Model, and as I implied earlier there’s no reason to not have a single Semantic Model populated by both internal and external DSLs. Indeed, this is exactly what I did when programming the state machine example where I have several DSLs all populating a single Semantic Model.
With an external DSL, there is a very clear separation between the DSL scripts, the parser, and the Semantic Model. The DSL scripts are written in a clearly separate language; the parser reads these scripts and populates the Semantic Model. With an internal DSL, it’s much easier for things to get mixed up. I advocate having an explicit layer of objects (Expression Builders) whose job is to provide the necessary fluent interfaces to act as the language. DSL scripts then run by invoking methods on an Expression Builder which then populates the Semantic Model. Thus in an internal DSL, parsing the DSL scripts is done by a combination of the host language parser and the Expression Builders.
This raises an interesting point—it may strike you as a little odd to use the word “parsing” in the context of an internal DSL. I’ll confess it’s not something I’m entirely comfortable with either. I have found, however, that thinking of the parallels between internal and external DSL processing is a useful point of view. With traditional parsing, you take a stream of text, arrange that text into a parse tree, and then process that parse tree to produce a useful output. With parsing an internal DSL, your input is a series of function calls. You still arrange them into a hierarchy (usually implicitly on the stack) in order to produce useful output.
Another factor in the use of the word “parsing” here is that several cases don’t involve handling the text directly. In an internal DSL, the host language parser handles the text, and the DSL processor handles further language constructs. But the same occurs with XML DSLs: The XML parser translates the text into XML elements, and the DSL processor works on these.
At this point it’s worth revisiting the distinction between internal and external DSLs. The one I used earlier—whether or not it’s written in the base language of your application—is usually right, but not 100% so. An example edge case is if your main application is written in Java but you write your DSL in JRuby. In this case I’d still classify the DSL as internal, in that you’d use the techniques from the internal DSL section of this book.
The true distinction between the two is that internal DSLs are written in an executable language and parsed by executing the DSL within that language. In both JRuby and XML, a DSL is embedded into a carrier syntax, but we execute the JRuby code and just read the XML data structures. Most of the time, an internal DSL is done in the main language of the application, so that definition is generally more useful.
Once we have a Semantic Model, we then need to make the model do what we want. In the state machine example, this task is to control the security system. There are two broad ways we can do this. The simplest, and usually the best, is just to execute the Semantic Model itself. The Semantic Model is code and as such can run and do all it needs to.
Another option is to use code generation. Code generation means that we generate code which is separately compiled and run. In some circles, code generation is seen as an essential part of DSLs. I’ve seen talks about code generation assuming that to do any DSL work, you have to generate code. In the rare event that I see someone talking or writing about Parser Generators, they inevitably talk about generating code. Yet DSLs have no inherent need for code generation. A lot of the time the best thing to do is just to execute the Semantic Model.
The strongest case for code generation is when there is a difference between where you want to run the model and where you want to parse the DSL. A good example of this is executing code in an environment that has limited language choices, such as on limited hardware or inside a relational database. You don’t want to run a parser in your toaster or in SQL, so you implement the parser and Semantic Model in a more suitable language and generate C or SQL. A related case is where you have library dependencies in your parser that you don’t want in the production environment. This situation is particularly common if you are using a complex tool for your DSL, which is why language workbenches tend to do code generation.
In these situations, it’s still useful to have a Semantic Model in your parsing environment that can run without generating code. Running the Semantic Model allows you to experiment with the execution of the DSL without having to simultaneously understand how the code generation works. You can test parsing and semantics without generating code, which will often help you run tests more quickly and on isolating problems. You can do validations on the Semantic Model that can catch errors before generating code.
Another argument for code generation, even in an environment where you could happily interpret the Semantic Model directly, is that many developers find the kind of logic in a rich Semantic Model difficult to understand. Generating code from the Semantic Model makes everything much more explicit and less like magic. This could be a crucial point in a team with less capable developers.
But the most important thing to remember about code generation is that it’s an optional part of the DSL landscape. It’s one of those things that are absolutely essential if you need them, yet most of the time you don’t. I think of code generators as snowshoes: If I’m hiking in winter over deep snow I really have to have them, but I’d never carry them on a summer day.
With code generation, we see another benefit to using a Semantic Model: It decouples the code generators from the parser. I can write a code generator without having to understand anything about the parsing process, and test it independently too. That alone is enough to make the Semantic Model worthwhile. In addition, it makes it easier to support multiple code-generation targets should I need them.
3.2 The Workings of a Parser
So the differences between internal and external DSLs lie entirely in parsing, and indeed there are many differences in detail between the two. But there are a lot of similarities, too.
One of the most important similarities is that parsing is a strongly hierarchical operation. When we parse text, we arrange the chunks into a tree structure. Consider the simple structure of a list of events from the state machine. In the external syntax, it looked something like this:
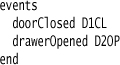
We can look at this composite structure as an event list containing a list of events, with each event having a name and a code.
We can take a similar view in the Ruby internal DSL.
event :doorClosed "D1CL"
event :drawerOpened "D2OP"
Here there’s no explicit notion of an overall list, but each event is still a hierarchy: an event containing a name symbol and a code string.
Whenever you look at a script like this, you can imagine that script as a hierarchy; such a hierarchy is called a syntax tree (or parse tree). Any script can be turned into many potential syntax trees—it just depends on how you decide to break it down. A syntax tree is a much more useful representation of the script than the words, for we can manipulate it in many ways by walking the tree.
If we are using a Semantic Model, we take the syntax tree and translate it into the Semantic Model. If you read material in the language community, you’ll often see more emphasis placed on the syntax tree—people execute the syntax tree directly or generate code off the syntax tree. Effectively, people can use the syntax tree as a semantic model. Most of the time I would not do that, because the syntax tree is very tied to the syntax of the DSL script and thus couples the processing of the DSL to its syntax.
Figure 3.2 A syntax tree and a semantic model are usually different representations of a DSL script.
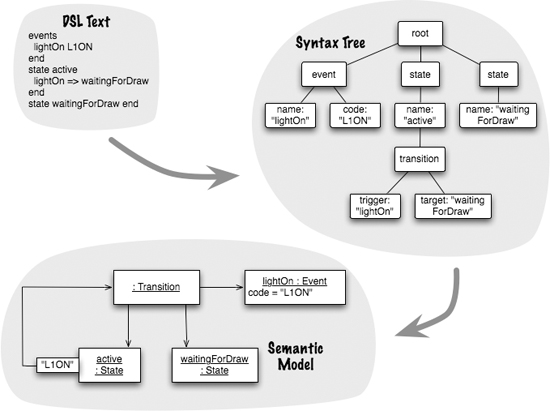
I’ve been talking about the syntax tree as if it’s a tangible data structure in your system, like the XML DOM. Sometimes it is, but often it isn’t. A lot of the time the syntax tree is formed on the call stack and processed as we walk it. As a result, you never see the whole tree, just the branch that you are currently processing (which is similar to the way XML SAX works). Despite this, it’s usually helpful to think about a ghostly syntax tree hiding in the shadows of the call stack. For an internal DSL, this tree is formed by arguments in a function call (Nested Function) and by nested objects (Method Chaining). Sometimes, you don’t see a strong hierarchy and you have to simulate it (Function Sequence with the hierarchy simulated with Context Variables). The syntax tree may be ghostly, but it’s still a useful mental tool. Using an external DSL leads to a more explicit syntax tree; indeed, sometimes you actually do create a full-blown syntax tree data structure (Tree Construction). But even external DSLs are commonly processed with the syntax tree forming and pruning continuously on the call stack. (I’ve referenced a few patterns above that I haven’t described yet. You can safely ignore them on your first read, but the references will be helpful on a later pass.)
3.3 Grammars, Syntax, and Semantics
When you work with a language’s syntax, an important tool is a grammar. A grammar is a set of rules which describe how a stream of text is turned into a syntax tree. Most programmers have come across grammars at some point in their lives, as they are often used to describe the programming languages we all work with. A grammar consists of a list of production rules, where each rule has a term and a statement of how it gets broken down. So, a grammar for an addition statement might look like additionStatement := number '+' number. This would tell us that if we see the language sentence 5 + 3, the parser can recognize it as an addition statement. Rules mention each other, so we would also have a rule for a number telling us how to recognize a legal number. We can compose a grammar for a language with these rules.
It’s important to realize that a language can have multiple grammars that define it. There is no such thing as the grammar for a language. A grammar defines the structure of the syntax tree that’s generated for the language, and we can recognize many different tree structures for a particular piece of language text. A grammar just defines one form of a syntax tree; the actual grammar and syntax tree you’ll choose will depend on many factors, including the features of the grammar language you’re working with and how you want to process the syntax tree.
The grammar also only defines the syntax of a language—how it gets represented in the syntax tree. It doesn’t tell us anything about its semantics, that is, what an expression means. Depending on the context, 5 + 3 could mean 8 or 53; the syntax is the same but the semantics may differ. With a Semantic Model, the definition of the semantics boils down to how we populate the Semantic Model from the syntax tree and what we do with the Semantic Model. In particular, we can say that if two expressions produce the same structure in the Semantic Model, they have the same semantics, even if their syntax is different.
If you’re using an external DSL, particularly if you use Syntax-Directed Translation, you’re likely to make explicit use of a grammar in building a parser. With internal DSLs, there won’t be an explicit grammar, but it’s still useful to think in terms of a grammar for your DSL. This grammar helps you choose which of the various internal DSL patterns you might use.
One of the things that makes talking about a grammar tricky for internal DSLs is that there are two parsing passes and thus two grammars involved. The first is the parsing of the host language itself, which obviously depends on the host grammar. This parsing creates the executable instructions for the host language. As the DSL part of that host language executes, it will create the ghostly syntax tree of the DSL on the call stack. It’s only in this second parse that the notional DSL grammar comes into play.
3.4 Parsing Data
As the parser executes, it needs to store various bits of data about the parse. This data could be a complete syntax tree, but a lot of the time that isn’t the case—and even when it is, there’s other data that usually needs to be stored to make the parse work well.
The parse is inherently a tree walk, and whenever you are processing a part of a DSL script, you’ll have some information about the context within the branch of the syntax tree that you’re processing. However, often you need information that’s outside that branch. Again, let’s take a fragment of a state machine example:
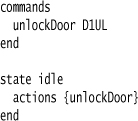
Here we see a common situation: A command is defined in one part of the language and referred to somewhere else. When the command is referred to as part of the state’s actions, we’re on a different branch of the syntax tree from where the command was defined. If the only representation of the syntax tree is on the call stack, then the command definition has disappeared by now. As a result, we need to store the command object for later use so we can resolve the reference in the action clause.
In order to do this, we use a Symbol Table, which is essentially a dictionary whose key is the identifier unlockDoor and whose value is an object that represents the command in our parse. When we process the text unlockDoor D1UL, we create an object to hold that data and stash it in the Symbol Table under the key unlockDoor. The object we stash may be the semantic model object for a command, or it could be an intermediate object that’s local to the syntax tree. Later, when we process actions {unlockDoor}, we look up that object using the Symbol Table to capture the relationship between the state and its actions. A Symbol Table is thus a crucial tool for making the cross-references. If you actually do create a full syntax tree during the parse, you can theoretically dispense with a Symbol Table, although usually it’s still a useful construct that makes it easier to stitch things together.
Figure 3.3 Parsing creates both a parse tree and a symbol table.
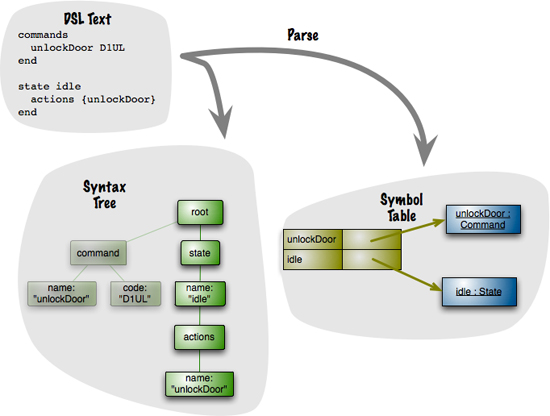
At this point I’m going to finish this section by lurching into a couple of more detailed patterns. I’m mentioning them here because they are used in both internal and external DSLs, so this is a good spot even though most of this chapter is at a higher level.
As the parse continues, you’ll need to keep its results. Sometimes all the results can be weaved into a Symbol Table, sometimes a lot of information can be kept on the call stack, sometimes you’ll need additional data structures in the parser. In all of these cases the most obvious thing to do is to create Semantic Model objects as your results; often, however, you’ll need to create intermediate objects because you can’t create Semantic Model objects till later in the parse. A common example of such an intermediate object is a Construction Builder which is an object that captures all the data for a Semantic Model object. This is useful when your Semantic Model object has read-only data after construction, but you gradually gather the data for it during parsing. A Construction Builder has the same fields as the Semantic Model object, but makes them read-write, which gives you somewhere to stash the data. Once you have all the data, you can create the Semantic Model object. Using a Construction Builder complicates the parser but I’d rather do that than alter the Semantic Model to forgo the benefits of read-only properties.
Indeed sometimes you might defer all creation of Semantic Model objects till you’ve processed all the DSL script. In this case the parse has distinct phases: first, reading through the DSL script and creating intermediate parsing data, and second, running through that intermediate data and populating the Semantic Model. The choice of how much to do during the text processing and what to do afterwards usually depends on how the Semantic Model needs to be populated.
The way you parse an expression often depends on the context that you are working in. Consider this text:
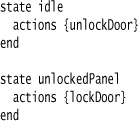
When we process actions {lockDoor}, it’s important to know that this is in the context of the unlockedPanel state and not the idle state. Often, this context is supplied by the way the parser builds and walks the parse tree, but there are many cases where it’s difficult to do that. If we can’t find the context by examining the parse tree, then a good way to deal with it is by holding the context, in this case the current state, in a variable. I call this kind of variable a Context Variable. This Context Variable, like a Symbol Table, can hold a Semantic Model object or some intermediate object.
Although a Context Variable is often a straightforward tool to use, in general I prefer to avoid them as much as possible. The parsing code is easier to follow if you can read it without having to mentally juggle Context Variables, just as lots of mutable variables make procedural code more complicated to follow. Certainly there are times when you can’t avoid using a Context Variable, but I tend to see them as a smell to be avoided.
3.5 Macros
Macros are a tool that can be used with both internal and external DSLs. They used to be used pretty widely, but are less common now. In most contexts I’d suggest avoiding them, but they are occasionally useful, so I need to talk a little about how they work and when you might use them.
Macros come in two flavors: textual and syntactic. Textual macros are the simplest to understand; they allow you to substitute some text for some other text. A good example of where they can be handy is specifying colors in a CSS file. For all but a few fixed cases, CSS forces you to specify colors with color codes, such as #FFB595. Such a code is not very meaningful; what’s worse, if you use the same color in multiple places, you have to repeat the code. This, like any form of code duplication, is a Bad Thing. It would be better to give it a name that’s meaningful in your context, like MEDIUM_SHADE, and define in one place that MEDIUM_SHADE is #FFB595.
Although CSS (at least currently) doesn’t let you do that, you can use a macro processor to handle such situations. Just create a file which is your CSS file but with MEDIUM_SHADE where you need your color. The macro processor then does a simple text substitution to replace MEDIUM_SHADE with #FFB595.
That’s a very simple form of macro processing; more involved ones can use parameters. A classic example of this is the C preprocessor that can define a macro to replace sqr(x) with x * x.
Macros provide a lot of opportunities to create DSLs, either within a host language (as the C preprocessor does) or as a stand-alone file transformed into a host language. The downside is that macros have a number of awkward problems that make them difficult to use in practice. As a result, textual macros have pretty much fallen out of favor, and most mavens like me advise against them.
Syntactic macros also do substitution, but they work on syntactically valid elements of the host language, transforming from one kind of expression to another. The language that’s most famous for its heavy use of syntactic macros is Lisp, although C++ templates may be a better-known example. Using syntactic macros for DSLs is a core technique for writing internal DSLs in Lisp, but you can only use syntactic macros in a language that supports them; I therefore don’t talk about them much in this book, since relatively few languages do.
3.6 Testing DSLs
Over the last couple of decades I’ve become quite a bore on the subject of testing. I’m a big fan of test-driven development [Beck TDD] and similar techniques that put testing into the forefront of programming. As a result, I can’t think about DSLs without thinking about testing them.
With DSLs, I can break testing down into three separate areas: testing the Semantic Model, testing the parser, and testing the scripts.
3.6.1 Testing the Semantic Model
The first area I think about is testing the Semantic Model. These tests are about ensuring that the Semantic Model behaves the way I expect it to—that, as I execute it, the right outputs happen depending on what I place in the model. This is standard testing practice, the same as you would use with any framework of objects. For this testing, I don’t really need the DSL at all—I can populate the model using the basic interface of the model itself. This is good, as it allows me to test the model independently of the DSL and the parser.
Let me illustrate this with the secret panel controller. Here, my Semantic Model is the state machine. I can test the Semantic Model by populating it with the command-query API code I used at the beginning of the Introduction (p. 9), which doesn’t require any DSL.

The above code demonstrates that I can simply test the Semantic Model in isolation. However, I should point out that the real test code for this case will be more involved and should be better factored.
Here are a couple of ways to better factor this kind of code. First off, we can make a bunch of small state machines which provide minimal fixtures for testing various features of the Semantic Model. To test that an event triggers a transition, all we need is a simple state machine with an idle state and two outbound transitions to separate states.

When we want to test commands, however, we might just want a smaller machine with just a single state off our idle state.

These different test fixtures can be run, and tests probed, in similar ways. I can make this easier by giving them a common superclass. The first thing this class provides is the ability to set up a common fixture—in this initializing, a controller and a command channel with the supplied state machine.

I can now write tests by firing events at the controller and checking the state.

The superclass provides Test Utility Methods [Meszaros] and Custom Assertions [Meszaros] to make the tests easier to read.
An alternative approach for testing the Semantic Model is to populate a larger model that demonstrates many features of the model, and run multiple tests on that. In this case, I can use Miss Grant’s controller as a test fixture.


In this case, I again populated the Semantic Model using its own command-query interface. As the test fixtures get more complex, however, I can simplify the test code by using the DSL to create fixtures. I can do this if I have tests for the parser.
3.6.2 Testing the Parser
When we’re using a Semantic Model, the job of the parser is to populate the Semantic Model. So our testing of the parser is about writing small fragments of DSL and ensuring that they create the right structures in the Semantic Model.

Poking around in the Semantic Model like this is rather awkward, and may result in breaking encapsulation on the objects in the Semantic Model. Therefore another way to test the output of the parser is to define methods to compare Semantic Models and use those.

Checking complex structures for equivalence is more involved than the regular notions of equality would suggest. We also need more information than just a Boolean answer, since we want to know what’s different between the objects. As a result, I have a comparison that uses a Notification.


The approach of this probe is to walk through the objects in the Semantic Model and record any differences in a Notification. This way I find all differences instead of stopping at the first one. My assertion then just checks to see if the Notification has any errors.

You may think I’m being paranoid by doing the equivalence assertion in both directions, but usually the code is out to get me.
Invalid Input Tests
The tests I’ve just discussed are positive tests, in that they ensure that a valid DSL input creates the correct structures in the Semantic Model. Another category of tests are negative tests, which probe what happens if I submit invalid DSL input. This goes into the whole area of error handling and diagnostics, which is out of scope for this book, but I won’t let that stop me briefly mentioning invalid input tests here.
The idea with invalid input tests is to throw various kinds of invalid input at the parser. The first time you run such a test, it’s interesting to see what happens. Often you’ll get an obscure but violent error. Depending on the amount of diagnostic support you want to provide with the DSL, that may be enough. It’s worse if you supply an invalid DSL, parse it, and get no error at all. This would violate the principle of “fail fast”—that is, that errors should show up as early and loudly as possible. If you populate a model in an invalid state and have no checks for that, you won’t find out there’s a problem till later. At that point, there is a distance between the original fault (loading an invalid input) and the later failure, and that distance makes it harder to find the fault.
My state machine example has very minimal error handling—a common feature of book examples. I probed one of my parser examples with this test, just to see what would happen.

The test passed just fine, which is a bad thing. Then, when I tried to do anything with the model, even just print it, I got a null pointer exception. I’m fine with this example being somewhat crude—after all, its only purpose is pedagogical—but a typo in an input DSL could lead to much lost time debugging. Since this is my time, and I like to pretend to myself that it’s valuable, I’d rather it failed fast.
Since the problem is that I’m creating an invalid structure in the Semantic Model, the responsibility to check for this problem is that of the Semantic Model—in this case, the method that adds a transition to a state. I added an assertion to detect the problem.

Now I can alter the test to catch the exception. This will tell me if I ever change the behavior of this output, as well as document what kind of error this invalid input causes.

You’ll notice that I only put in an assertion for the target state and not for the trigger event, which also could be null. My reason for this is that a null event will cause an immediate null pointer exception due to the event.getCode() call. This fulfills the fast-fail need. I can check this with another test.
@Test public void triggerNotDeclared () {
String code =
"events trigger TGGR end " +
"state idle " +
"wrongTrigger => target " +
"end " +
"state target end ";
try {
StateMachine actual = StateMachineLoader.loadString(code);
fail();
} catch (NullPointerException expected) {}
A null pointer exception does fail fast, but isn’t as clear as the assertion. In general, I don’t do not-null assertions on my method arguments, as I feel the benefit isn’t worth the extra code to read. The exception is when this leads to a null that doesn’t cause an immediate failure, such the null target state.
3.6.3 Testing the Scripts
Testing the Semantic Model and the parser does unit testing for the generic code. However, the DSL scripts are also code, and we should consider testing them. I do hear arguments along the lines of “DSL scripts are too simple and obvious to be worth testing,” but I’m naturally suspicious of that. I see testing as a double-check mechanism. When we write code and tests, we are specifying the same behavior using too different mechanisms, one involving abstractions (the code) and the other using examples (the tests). For anything of lasting value, we should always double-check.
The details of script tests very much depend on what it is you’re testing. The general approach is to provide a test environment that allows you to create text fixtures, run DSL scripts, and compare results. It’s usually some effort to prepare such an environment, but just because a DSL is easy to read doesn’t mean people won’t make mistakes. If you don’t provide a test environment and thus don’t have a double-check mechanism, you greatly increase the risk of errors in the DSL scripts.
Script tests also act as integration tests, since any errors in the parser or Semantic Model should cause them to fail. As a result, it’s worth sampling the DSL scripts to use a few for this purpose.
Often, alternative visualizations of the script are a useful aid in testing and debugging DSL scripts. Once you have a script captured in the Semantic Model, it’s relatively easy to produce different textual and graphical visualizations of the script’s logic. Presenting information in multiple ways often helps people find errors—indeed, this notion of a double check is the heart of why writing self-testing code is such a valuable approach.
For the state machine example, I begin by thinking about the examples that would make sense for this kind of machine. To my mind, the logical approach would be to run scenarios, each scenario being a sequence of events sent to the machine. I then check the end state of the machine and the commands it has sent out. Building up something like this in a readable way naturally leads me to another DSL. That’s not uncommon; testing scripts is a common use of DSLs as they fit well with the need for a limited, declarative language.

3.7 Handling Errors
Whenever I write a book, I reach a point where I recognize that, as with writing software, I have to cut the scope in order to get the book published. While this means that an important topic isn’t covered properly, I reason that it’s better to have a useful but incomplete book than a complete book that never gets finished. There are many topics I’d like to have explored further in this book, but the top of that list is error handling.
During a compiler class at university, I remember being told that parsing and output generation are the easy part of compiler writing—the hard part was giving good error messages. Appropriately, error diagnostics was as beyond the scope for that class as it has become for this book.
The out-of-scopeness of decent error messages goes further than that. Good diagnostics are a rarity even in successful DSLs. More than one highly useful DSL package does little in the way of helpful information. Graphviz, one of my favorite DSL tools, will simply tell me syntax error near line 4, and I feel somewhat lucky even to get a line number. I’ve certainly come across tools that just fall over, leaving me to do a binary search with commenting out lines in order to find just where the problem is.
One can rightly criticize such systems for their poor error diagnostics, but diagnostics are yet another thing to be traded off. Any time spent on improving error handling is time not spent adding other features. The evidence from many DSLs in the wild is that people do tolerate poor error diagnostics. After all, DSL scripts are small, so crude error finding techniques are more reasonable with them than with general-purpose languages.
I’m not saying this to persuade you to not work on error diagnostics. In a heavily used library, good diagnostics can save a lot of time. Every tradeoff is unique, and you have to decide based on your own circumstances. It does, however, make me feel a little bit better about not devoting a section of this book to the subject.
Despite the fact that I can’t give the topic the in-depth coverage I’d like to, I can say something that will hopefully get you started in thinking more about error diagnostics, should you decide to provide greater support.
(One thing that I should mention is the crudest error-finding technique of all—commenting out. If you use an external DSL, make sure that you support comments. Not just for the obvious reasons, but also to help people find problems. Such comments are easiest to work with when they are terminated by line endings. Depending on the audience, I’d use either “#” (script style) or “//” (C style). These can be done with a simple lexer rule.)
If you follow my general recommendation to use a Semantic Model, then there are two places where error handling can live: the model or the parser. For syntactic errors, the obvious place to put the handling is in the parser. Some syntactic errors will be handled for you: host language syntax errors in an internal DSL or grammar errors when using a Parser Generator in an external DSL.
The situation where you have a choice between parser and model is handling semantic errors. For semantics, both places have their strengths. The model is really the right place to check the rules of semantically well-formed structures. You have all the information structured the way you need to think about it, so you can write the clearest error checking code here. Additionally, you’ll need the checking here if you want to populate the model from more than one place, such as multiple DSLs or using a command-query interface.
Putting error handling purely in the Semantic Model does have one serious disadvantage: There’s no link back to the source of the problem in the DSL script, not even an approximate line number. This makes it harder for people to figure out what went wrong, but this may not be an intractable problem. There is some experience that suggests that a purely model-based error message is enough to find the problem in many situations.
If you do want the DSL script context, then there are a few ways to get it. The most obvious one is to put the error detection rules in the parser. However, the problem with this strategy is that it makes it much harder to write the rules, as you are working on the level of the syntax tree rather than the semantic model. You also have a much greater risk of duplicating the rules, with all the problems that code duplication entails.
An alternative is to push syntactic information into the Semantic Model. You might add a line number field to a semantic transition object, so that when the Semantic Model detects an error in that transition, it can print the line number from the script. The problem is that this can make the Semantic Model much more complicated as it has to track the information. Additionally, the script may not map that cleanly to the model, which could result in error messages that are more confusing than helpful.
The third strategy, and the one that sounds best to me, is to use the Semantic Model for error detection, but trigger error detection in the parser. This way, the parser will parse a hunk of DSL script, populate the Semantic Model, and then tell the model to look for errors (if populating the model doesn’t do that directly). Should the model find any, the parser can then take those errors and supply the DSL script context it knows. This separates the concerns of syntactic knowledge (in the parser) and semantic knowledge (in the model).
A useful approach is to divide error handling into initiation, detection, and reporting. This last strategy puts initiation in the parser, detection in the model, and reporting in both, with the model supplying the semantics of the error and the parser adding syntactic context.
3.8 Migrating DSLs
One danger that DSL advocates need to guard against is the notion that first you design a DSL, then people use it. Like any other piece of software, a successful DSL will evolve. This means that scripts written in an earlier version of a DSL may fail when run with a later version.
Like many properties of DSL, good and bad, this is very much the same as what happens with a library. If you take a library from someone, write some code against it, and they upgrade the library, you may end up stuck. DSLs don’t really do anything to change that; the DSL definition is essentially a published interface, and you have to deal with the consequences just the same.
I started using the term published interface in my Refactoring book [Fowler Refactoring]. The difference between published and the more common “public” interface is that a published interface is used by code written by a separate team. Therefore, if the team that defines the interface wants to change it, they can’t easily rewrite the calling code. Changing a published DSL is an issue with both internal and external DSLs. With nonpublished DSLs, it may be easier to change an internal DSL if the language concerned has automated refactoring tools.
One way to tackle the problem of changes to DSLs is to provide tools that automatically migrate a DSL from one version to another. These can be run either during an upgrade, or automatically should you try to run an old-version script.
There are two broad ways to handle migration. The first is an incremental migration strategy. This is essentially the same notion that’s used by people doing evolutionary database design [Fowler and Sadalage]. For every change you do to your DSL definition, create a migration program that automatically migrates DSL scripts from the old version to the new version. That way, when you release a new version of the DSL, you also provide scripts to migrate any code bases that use the DSL.
An important part of incremental migration is that you keep the changes as small as you can. Imagine you are upgrading from version 1 to 2, and have ten changes that you want to make to your DSL definition. In this case, don’t create just one migration script to migrate from version 1 to 2; instead, create at least ten scripts. Change the DSL definition one feature at a time, and write a migration script for each change. You may find it useful to break it down even more and add some features with more than one step (and thus more than one migration). This may sound like more work than a single script, but the point is that migrations are much easier to write if they are small, and it’s easy to chain multiple migrations together. As a result, you’ll be able to write ten scripts much faster than one.
The other approach is model-based migration. This is a tactic you can use with a Semantic Model. With model-based migration you support multiple parsers for your language, one for each released version. (So you only do this for versions 1 and 2, not for the intermediate steps.) Each parser populates the semantic model. When you use a semantic model, the parser’s behavior is pretty simple, so it’s not too much trouble to have several of them around. You then run the appropriate parser for the version of script you are working with. This handles multiple versions, but doesn’t migrate the scripts. To do the migration, you write a generator from the semantic model that generates a DSL script representation. This way, you can run the parser for a version 1 script, populate the semantic model, and then emit a version 2 script from the generator.
One problem with the model-based approach is that it’s easy to lose stuff that doesn’t matter for the semantics but is something that the script writers want to keep. Comments are the obvious example. This is exacerbated if there’s too much smarts in the parser, although then the need to migrate this way may encourage the parsers to stay dumb—which is a Good Thing.
If the change to the DSL is big enough, you may not be able to transform a version 1 script into a version 2 semantic model. In this case, you may need to keep a version 1 model (or an intermediate model) around and give it the ability to emit a version 2 script.
I don’t have a strong preference among these two alternatives.
Migration scripts can be run by script programmers themselves when needed, or automatically by the DSL system. If it’s to be run automatically, it’s very useful to have the script record which version of the DSL it is so the parser can detect it easily and trigger the resulting migrations. Indeed, some DSL authors argue that all DSLs should have a mandatory version statement in a script so it’s easy to detect out-of-date scripts and support the migration of scripts. While a version statement may add a bit of noise to the script, it’s something that’s very hard to retrofit.
Of course another migration option is not to migrate—that is, to keep the version 1 parser and just let it populate the version 2 model. You should help people migrate, and they will need to if they want to use more features. But supporting the old scripts directly, if you can, is useful since it allows them to migrate at their own pace.
Although techniques like this are quite appealing, there is the question of whether they are worth it in practice. As I said earlier, the problem is exactly the same as with widely used libraries, and automated migration schemes have not been used much there.