
Chapter 47. Adaptive Model
Arrange blocks of code in a data structure to implement an alternative computational model.
Programming languages are designed with a particular computational model in mind. For mainstream languages, this model is an imperative model with code organized in an object-oriented way. This approach is currently favored because it’s worked out to be a suitable compromise between power and understandability. However, this model isn’t always the best one for a particular problem. Indeed, often the desire to use a DSL comes with a desire to use a different computational model.
Adaptive Model allows you to implement alternative computational models within an imperative language. You do this by defining a model where the links between elements represent the behavioral relationships of the computational model. This model usually needs references to sections of imperative code. You then run the model either by executing code over it (procedural style) or by executing code within the model itself (object-oriented style).
47.1 How It Works
As we write software, we regularly build models of the bits of the world the software is working with. A catalog system captures information about products and prices; a media web site has news stories, advertising, and tags that describe how they should go together. These models may be pure data structures (data models) or compose data with the code that manipulates them (object models). But even in an object model, the flow of processing is dictated by the code. The data it operates on is different, and its differences cause changes in detail of the processing, but the broad flow remains the same.
The state model of secret panels that I opened this book with is a different kind of beast. Depending on which state model I load a particular system with, I get a big change in the overall behavior of the system. Essentially, the instantiation of the state model is the program. Certainly, there is the general Semantic Model of a state machine; this is a constant factor and a constraint on what any particular state machine can do. But in a very real sense, the program that executes is the configuration of a particular state machine.
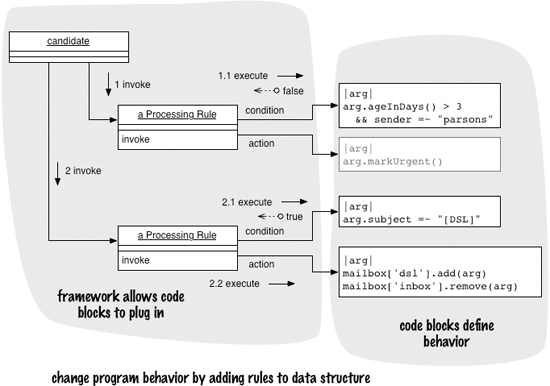
When a model takes the primary behavioral role in a system, I call this an Adaptive Model. As with most boundaries in software, the one around Adaptive Models is fuzzy, but I find the classification useful. To me, the essence of using an Adaptive Model is the sense that you are changing the program by altering the instances and their relationships. This sense dissolves the boundary between code and data, and we enter a world with new possibilities and new problems. Some software communities relish this world—the Lisp community is particularly strong on the duality of code and data—but for many developers it’s a world that’s both entrancing and scary.
Adaptive Models exist independently from DSLs in that you can have an Adaptive Model in a system without a DSL in sight and get most of the benefits of using one. The DSL’s role here is to make it easier to program the Adaptive Model by providing a language in which you can describe your intentions more clearly. The examples I used for the difference between the command-query API and the various DSLs illustrate this point. One of the hardest parts in using an Adaptive Model is to figure out what it’s supposed to do—a DSL can be a big help in overcoming that.
My examples in this book use in-memory object models as Adaptive Models, but Adaptive Models can take many forms. An Adaptive Model can be a data structure interpreted by procedural code. A common use of Adaptive Model is to store the model in a database and have it interpreted by other applications. Workflow systems often use this style.
When I see an Adaptive Model stored in a relational database, I often find that it goes with a (usually crude) projectional editor (p. 136), usually using forms and fields to edit the Adaptive Model. While this is serviceable, there are many advantages to using a DSL instead. DSLs are often better at giving the whole picture of a behavior, although visualization techniques can also do that. Perhaps the best argument for a textual DSL is that it allows you to easily put the Adaptive Model under version control. I find it deeply troubling when core system behavior isn’t kept under a proper source code control system.
Adaptive Models are often represented by data structures that take well-known graph structures. As a result, you may find textbooks on algorithms and data structures very helpful in working with them.
47.1.1 Incorporating Imperative Code into an Adaptive Model
When I created the initial state machine example, I deliberately made it so that all the behavioral elements could be described through simple data. The actions in the state machine are simply represented by transmitting a command code. It’s common, however, for Adaptive Models to interplay much more closely with imperative code. In another state machine, I might want actions to do a wider range of things, or put conditions on my transitions as guards. To do this within the Adaptive Model would mean complicating it with a range of imperative expressions that I already have in my host programming language. Often, a better alternative is to embed regular programming language code into the Adaptive Model data structure.
A good example of this is a rule in a Production Rule System. Such a rule has two parts: a Boolean condition and an action. It’s often useful to represent these in the host language.
The most natural way to do this is with a closure.
rule.Condition = j => j.Start == "BOS";
rule.Action = j => j.Passenger.PostBonusMiles(2000);
Closures work well because they allow you to easily embed arbitrary blocks of code into data structures. A closure is the most direct statement of my intention here. The big drawback of using closures is that many languages don’t have them. If that is the case with yours, you need to resort to some workarounds.
Probably the easiest workaround is to use a Command [GoF]. To do this, I create little objects that wrap a single method. My rule class then uses one for the condition and one for the action.

I can then set up a particular rule by making a subclass.

Most of the time I can reduce the amount of subclasses I need by parametrizing the commands.

In a language without closure support, something like this is usually where I would prefer to go.
Another option is to use the name of a method and invoke it using reflection. I don’t like this approach, as it circumvents the mechanisms of the underlying environment just a bit too much.
I’ve described using commands as a workaround, and when you’re looking at it from the Adaptive Model viewpoint, that’s true. However, if you’re populating the Adaptive Model with a DSL, then commands become more attractive. In many situations, the DSL will wrap common cases in parameters anyway, which leads naturally to parametrized commands. To use the full expressiveness of closures in the DSL means using closures either in an internal DSL or Foreign Code in an external DSL. The latter, in particular, is something you should use only rarely.
47.1.2 Tools
A DSL is a valuable tool for an Adaptive Model since it allows people to configure the instance of a model using a programming language that makes its behavior more explicit. However, a DSL is not really enough to work with an Adaptive Model when it gets more complicated. Other tools come in handy.
It’s often difficult to follow what an Adaptive Model is doing since it uses a computational model that people are less familiar with. As a result, it’s particularly important to use some kind of tracing when executing the model. The trace should capture how the model processed its inputs, leaving a clear log of why it did what it did. This greatly helps answering the question, “Why did the program do that?”
A model can also produce alternative visualizations of itself, where you tell the model to produce a descriptive output of a model instance. A graphical description is often very useful. I’ve seen some very handy visualizations produced using Graphviz, a tool for automatically laying out node-and-arc graph structures. The state diagram picture of the secret panel control system is a good example of this. Various kinds of reports that show what the model looks like from different perspectives can also be useful.
Such visualizations are a simple equivalent of the multiple projections of a language workbench. Unlike those projections, they aren’t editable—or rather, the cost to make them editable is usually prohibitive. But such visualizations can still be extremely useful. You can build them automatically as part of your build process and use them to check your understanding of how the model is configured.
47.2 When to Use It
An Adaptive Model is the key to using an alternative computational model. Using an Adaptive Model allows you to build a processing engine for an alternative computational model that you can then program for specific behavior. So, once you have an Adaptive Model for a Production Rule System, you can execute any set of rules by loading them into the model. I would usually advise that any of the alternative computational models mentioned in this book should be implemented with an Adaptive Model.
Of course this is somewhat of a glib answer—it begs the question of when would you want to use an alternative computational model? That is a qualitative decision on what best seems to fit your problem. I don’t have any rigorous approach to making this decision. My best suggestion is to try expressing the behavior according to a different computational model and see if that seems to make it easier to think about. Doing this often means prototyping a DSL to drive the model, since the Adaptive Model alone may not provide enough clarity.
A lot of the time, this involves considering a common computational model. The other patterns in this part of the book give you a starting point; if one of these seems to fit, then it’s worth a try. It’s less common to find that you want an entirely new computational model, but it isn’t unknown. Often such a realization can grow from the way a framework changes over time. A framework can begin by just storing data, but as more behavior worms its way in, you can see a Adaptive Model beginning to form.
Adaptive Models come with a particularly large disadvantage: they can be very hard to understand. I commonly come across cases where programmers complain bitterly about being unable to understand how an Adaptive Model works. It’s as if a bit of magic is embedded in the program, and a lot of people find this kind of magic rather scary.
The scariness comes from the fact that an Adaptive Model results in implicit behavior. No longer can you reason about what the program does by reading the code. Instead, you have to look at a particular model configuration to see how the system behaves. Many developers find this enormously frustrating. It’s often difficult to write a clear program that expresses your intent, but now you have to decode it from a data model that’s hard to navigate. Debugging can be a nightmare. You can make it easier by producing tools to help with this, but then you’ll spend time building the tools rather than working on the true purpose of the software.
Usually, there are a couple of people around who understand the Adaptive Model. They are big fans of it, and can be incredibly productive by using it. Everyone else, however, steers well clear.
This phenomenon genuinely puts me in two minds. I’m the kind of person who finds Adaptive Models very powerful. I’m comfortable with finding them and using them—and I feel that a well-chosen Adaptive Model can greatly improve productivity. But I also have to recognize that they can be an alien artifact to most developers—and sometimes, you have to forgo the gains of an Adaptive Model because it’s not good to have a magic section in a system that people are fearful of touching. If the few people who understand the Adaptive Model would move on, nobody will be able to maintain that part of the system.
One hope I have is that using DSLs can alleviate this problem. Without a DSL, it’s very hard to program an Adaptive Model and understand what it does. A DSL can make much of that implicit behavior explicit by capturing the configuration of the Adaptive Model in a language nature. My sense is that as DSLs become more common, more people will become comfortable with Adaptive Models and thus able to realize the productivity benefits they provide.