
On occasion, it can be valuable to show search engines one version of content and show humans a different version. This is technically called cloaking, and the search engines’ guidelines have near-universal policies restricting this. In practice, many websites, large and small, appear to use content delivery effectively and without being penalized by the search engines. However, use great care if you implement these techniques, and know the risks that you are taking.
Before we discuss the risks and potential benefits of cloaking-based practices, take a look at Figure 6-30, which shows an illustration of how cloaking works.
Google’s Matt Cutts, head of Google’s webspam team, has made strong public statements indicating that all forms of cloaking (other than First Click Free) are subject to penalty. This was also largely backed by statements by Google’s John Mueller in a May 2009 interview, which you can read at http://www.stonetemple.com/articles/interview-john-mueller.shtml.
Google makes its policy pretty clear in its Guidelines on Cloaking (http://www.google.com/support/webmasters/bin/answer.py?hl=en&answer=66355):
Serving up different results based on user agent may cause your site to be perceived as deceptive and removed from the Google index.
There are two critical pieces in the preceding quote: may and user agent. It is true that if you cloak in the wrong ways, with the wrong intent, Google and the other search engines may remove you from their index, and if you do it egregiously, they certainly will. But in some cases, it may be the right thing to do, both from a user experience perspective and from an engine’s perspective.
The key is intent: if the engines feel you are attempting to manipulate their rankings or results through cloaking, they may take adverse action against your site. If, however, the intent of your content delivery doesn’t interfere with their goals, you’re less likely to be subject to a penalty, as long as you don’t violate important technical tenets (which we’ll discuss shortly).
What follows are some examples of websites that perform some level of cloaking:
Search for google toolbar or google translate or adwords or any number of Google properties and note how the URL you see in the search results and the one you land on almost never match. What’s more, on many of these pages, whether you’re logged in or not, you might see some content that is different from what’s in the cache.
- NYTimes.com
The interstitial ads, the request to log in/create an account after five clicks, and the archive inclusion are all showing different content to engines versus humans.
- Wine.com
In addition to some redirection based on your path, there’s the state overlay forcing you to select a shipping location prior to seeing any prices (or any pages). That’s a form the engines don’t have to fill out.
- Yelp.com
Geotargeting through cookies based on location is a very popular form of local targeting that hundreds, if not thousands, of sites use.
- Amazon.com
At SMX Advanced 2008 there was quite a lot of discussion about how Amazon does some cloaking (http://www.naturalsearchblog.com/archives/2008/06/03/amazons-secret-to-dominating-serp-results/). In addition, Amazon does lots of fun things with its Buybox.amazon.com subdomain and with the navigation paths and suggested products if your browser accepts cookies.
- Trulia.com
Trulia was found to be doing some interesting redirects on partner pages and its own site (http://www.bramblog.com/trulia-caught-cloaking-red-handed/).
The message should be clear. Cloaking isn’t always evil, it won’t always get you banned, and you can do some pretty smart things with it. The key to all of this is your intent. If you are doing it for reasons that are not deceptive and that provide a positive experience for users and search engines, you might not run into problems. However, there is no guarantee of this, so use these types of techniques with great care, and know that you may still get penalized for it.
There are a few common causes for displaying content differently to different visitors, including search engines. Here are some of the most common ones:
- Multivariate and A/B split testing
Testing landing pages for conversions requires that you show different content to different visitors to test performance. In these cases, it is best to display the content using JavaScript/cookies/sessions and give the search engines a single, canonical version of the page that doesn’t change with every new spidering (though this won’t necessarily hurt you). Google offers software called Google Website Optimizer to perform this function.
- Content requiring registration and First Click Free
If you force registration (paid or free) on users to view specific content pieces, it is best to keep the URL the same for both logged-in and non-logged-in users and to show a snippet (one to two paragraphs is usually enough) to non-logged-in users and search engines. If you want to display the full content to search engines, you have the option to provide some rules for content delivery, such as showing the first one to two pages of content to a new visitor without requiring registration, and then requesting registration after that grace period. This keeps your intent more honest, and you can use cookies or sessions to restrict human visitors while showing the full pieces to the engines.
In this scenario, you might also opt to participate in a specific program from Google called First Click Free, wherein websites can expose “premium” or login-restricted content to Google’s spiders, as long as users who click from the engine’s results are given the ability to view that first article for free. Many prominent web publishers employ this tactic, including the popular site, Experts-Exchange.com.
To be specific, to implement First Click Free, the publisher must grant Googlebot (and presumably the other search engine spiders) access to all the content they want indexed, even if users normally have to log in to see the content. The user who visits the site will still need to log in, but the search engine spider will not have to do so. This will lead to the content showing up in the search engine results when applicable. However, if a user clicks on that search result, you must permit him to view the entire article (all pages of a given article if it is a multiple-page article). Once the user clicks to look at another article on your site, you can still require him to log in.
For more details, visit Google’s First Click Free program page at http://googlewebmastercentral.blogspot.com/2008/10/first-click-free-for-web-search.html.
- Navigation unspiderable to search engines
If your navigation is in Flash, JavaScript, a Java application, or another unspiderable format, you should consider showing search engines a version that has spiderable, crawlable content in HTML. Many sites do this simply with CSS layers, displaying a human-visible, search-invisible layer and a layer for the engines (and less capable browsers, such as mobile browsers). You can also employ the
noscripttag for this purpose, although it is generally riskier, as many spammers have appliednoscriptas a way to hide content. Adobe recently launched a portal on SEO and Flash and provides best practices that have been cleared by the engines to help make Flash content discoverable. Take care to make sure the content shown in the search-visible layer is substantially the same as it is in the human-visible layer.- Duplicate content
If a significant portion of a page’s content is duplicated, you might consider restricting spider access to it by placing it in an iframe that’s restricted by robots.txt. This ensures that you can show the engines the unique portion of your pages, while protecting against duplicate content problems. We will discuss this in more detail in the next section.
- Different content for different users
At times you might target content uniquely to users from different geographies (such as different product offerings that are more popular in their area), with different screen resolutions (to make the content fit their screen size better), or who entered your site from different navigation points. In these instances, it is best to have a “default” version of content that’s shown to users who don’t exhibit these traits to show to search engines as well.
A variety of strategies exist to segment content delivery. The
most basic is to serve content that is not meant for the engines in
unspiderable formats (e.g., placing text in images, Flash files,
plug-ins, etc.). You should not use these formats for the purpose of
cloaking. You should use them only if they bring a substantial end-user
benefit (such as an improved user experience). In such cases, you may
want to show the search engines the same content in a
search-spider-readable format. When you’re trying to show the engines
something you don’t want visitors to see, you can use CSS formatting
styles (preferably not display:none,
as the engines may have filters to watch specifically for this),
JavaScript, user-agent, cookie, or session-based delivery, or perhaps
most effectively, IP delivery (showing content based on the visitor’s IP
address).
Be very wary when employing cloaking such as that we just described. The search engines expressly prohibit these practices in their guidelines, and though there is leeway based on intent and user experience (e.g., your site is using cloaking to improve the quality of the user’s experience, not to game the search engines), the engines do take these tactics seriously and may penalize or ban sites that implement them inappropriately or with the intention of manipulation.
This file is located on the root level of your domain (e.g., http://www.yourdomain.com/robots.txt), and it is a highly versatile tool for controlling what the spiders are permitted to access on your site. You can use robots.txt to:
Prevent crawlers from accessing nonpublic parts of your website
Block search engines from accessing index scripts, utilities, or other types of code
Avoid the indexation of duplicate content on a website, such as “print” versions of HTML pages, or various sort orders for product catalogs
Auto-discover XML Sitemaps
The robots.txt file must reside in the root directory, and the filename must be entirely in lowercase (robots.txt, not Robots.txt, or other variations including uppercase letters). Any other name or location will not be seen as valid by the search engines. The file must also be entirely in text format (not in HTML format).
When you tell a search engine robot not to access a page, it prevents the crawler from accessing the page. Figure 6-31 illustrates what happens when the search engine robot sees a direction in robots.txt not to crawl a web page.
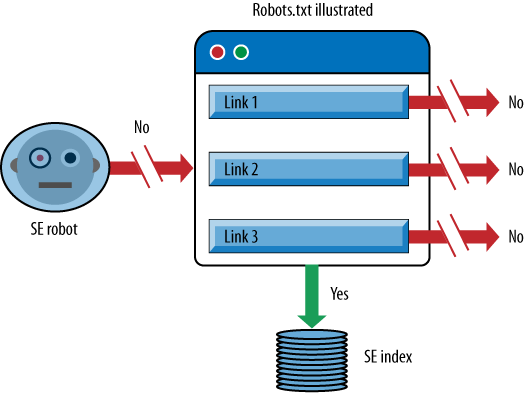
In essence, the page will not be crawled, so links on the page cannot pass link juice to other pages since the search engine does not see the links. However, the page can be in the search engine index. This can happen if other pages on the Web link to the page. Of course, the search engine will not have very much information on the page since it cannot read it, and will rely mainly on the anchor text and other signals from the pages linking to it to determine what the page may be about. Any resulting search listings end up being pretty sparse when you see them in the Google index, as shown in Figure 6-32.

Figure 6-32 shows the results for the Google query site:news.yahoo.com/topics/ inurl:page. This is not a normal query that a user would enter, but you can see what the results look like. Only the URL is listed, and there is no description. This is because the spiders aren’t permitted to read the page to get that data. In today’s algorithms, these types of pages don’t rank very high because their relevance scores tend to be quite low for any normal queries.
Google, Yahoo!, Bing, Ask, and nearly all of the legitimate crawlers on the Web will follow the instructions you set out in the robots.txt file. Commands in robots.txt are primarily used to prevent spiders from accessing pages and subfolders on a site, though they have other options as well. Note that subdomains require their own robots.txt files, as do files that reside on an https: server.
The basic syntax of robots.txt is fairly simple. You specify a robot name, such as “googlebot”, and then you specify an action. The robot is identified by user agent, and then the actions are specified on the lines that follow. Here are the major actions you can specify:
Disallow:the pages you want to block the bots from accessing (as many disallow lines as needed)Noindex:the pages you want a search engine to block and not index (or de-index if previously indexed); this is unofficially supported by Google and unsupported by Yahoo! and Bing
Some other restrictions apply:
Each User-Agent/Disallow group should be separated by a blank line; however, no blank lines should exist within a group (between the User-Agent line and the last Disallow).
The hash symbol (#) may be used for comments within a robots.txt file, where everything after # on that line will be ignored. This may be used either for whole lines or for the end of lines.
Directories and filenames are case-sensitive: “private”, “Private”, and “PRIVATE” are all uniquely different to search engines.
Here is an example of a robots.txt file:
User-agent: Googlebot Disallow: User-agent: msnbot Disallow: / # Block all robots from tmp and logs directories User-agent: * Disallow: /tmp/ Disallow: /logs # for directories and files called logs
The preceding example will do the following:
Allow “Googlebot” to go anywhere.
Prevent “msnbot” from crawling any part of the site.
Block all robots (other than Googlebot) from visiting the /tmp/ directory or directories or files called /logs (e.g., /logs or logs.php).
Notice that the behavior of Googlebot is not affected by
instructions such as Disallow: /.
Since Googlebot has its own instructions from robots.txt, it will ignore directives
labeled as being for all robots (i.e., uses an asterisk).
One common problem that novice webmasters run into occurs when they have SSL installed so that their pages may be served via HTTP and HTTPS. A robots.txt file at http://www.yourdomain.com/robots.txt will not be interpreted by search engines as guiding their crawl behavior on https://www.yourdomain.com. To do this, you need to create an additional robots.txt file at https://www.yourdomain.com/robots.txt. So, if you want to allow crawling of all pages served from your HTTP server and prevent crawling of all pages from your HTTPS server, you would need to implement the following:
For HTTP:
User-agent: * Disallow:
For HTTPS:
User-agent: * Disallow: /
These are the most basic aspects of robots.txt files, but there are more advanced techniques as well. Some of these methods are supported by only some of the engines, as detailed in the list that follows:
- Crawl delay
Crawl delay is supported by Yahoo!, Bing, and Ask. It instructs a crawler to wait the specified number of seconds between crawling pages. The goal with the directive is to reduce the load on the publisher’s server:
User-agent: msnbot Crawl-delay: 5
- Pattern matching
Pattern matching appears to be usable by Google, Yahoo!, and Bing. The value of pattern matching is considerable. You can do some basic pattern matching using the asterisk wildcard character. Here is how you can use pattern matching to block access to all subdirectories that begin with private (e.g., /private1/, /private2/, /private3/, etc.):
User-agent: Googlebot Disallow: /private*/
You can match the end of the string using the dollar sign ($). For example, to block URLs that end with .asp:
User-agent: Googlebot Disallow: /*.asp$
You may wish to prevent the robots from accessing any URLs that contain parameters in them. To block access to all URLs that include a question mark (?), simply use the question mark:
User-agent: * Disallow: /*?*
The pattern-matching capabilities of robots.txt are more limited than those of programming languages such as Perl, so the question mark does not have any special meaning and can be treated like any other character.
AllowdirectiveThe
Allowdirective appears to be supported only by Google, Yahoo!, and Ask. It works the opposite of theDisallowdirective and provides the ability to specifically call out directories or pages that may be crawled. When this is implemented it can partially override a previousDisallowdirective. This may be beneficial after large sections of the site have been disallowed, or if the entire site itself has been disallowed.Here is an example that allows Googlebot into only the google directory:
User-agent: Googlebot Disallow: / Allow: /google/
NoindexdirectiveThis directive works in the same way as the
metarobotsnoindexcommand (which we will discuss shortly) and tells the search engines to explicitly exclude a page from the index. Since aDisallowdirective prevents crawling but not indexing, this can be a very useful feature to ensure that the pages don’t show in search results. However, as of October 2009, only Google supports this directive in robots.txt.- Sitemaps
We discussed XML Sitemaps at the beginning of this chapter. You can use robots.txt to provide an autodiscovery mechanism for the spider to find the XML Sitemap file. The search engines can be told to find the file with one simple line in the robots.txt file:
Sitemap: sitemap_location
The
sitemap_locationshould be the complete URL to the Sitemap, such as http://www.yourdomain.com/sitemap.xml. You can place this anywhere in your file.
For full instructions on how to apply robots.txt, see Robots.txt.org. You may also find it valuable to use Dave Naylor’s robots.txt generation tool to save time and heartache (http://www.davidnaylor.co.uk/the-robotstxt-builder-a-new-tool.html).
You should use great care when making changes to robots.txt. A simple typing error can, for example, suddenly tell the search engines to no longer crawl any part of your site. After updating your robots.txt file it is always a good idea to check it with the Google Webmaster Tools Test Robots.txt tool.
In 2005, the three major search engines (Yahoo!, Google, and
Microsoft) all agreed to support an initiative intended to reduce the
effectiveness of automated spam. Unlike the meta robots version of NoFollow, the new directive could be
employed as an attribute within an <a> or link tag to indicate that the
linking site “does not editorially vouch for the quality of the
linked-to page.” This enables a content creator to link to a web page
without passing on any of the normal search engine benefits that
typically accompany a link (things such as trust, anchor text,
PageRank, etc.).
Originally, the intent was to enable blogs, forums, and other
sites where user-generated links were offered to shut down the value
of spammers who built crawlers that automatically created links.
However, this has expanded as Google, in particular, recommends use of
NoFollow on links that are paid
for—as the search engine’s preference is that only those links that
are truly editorial and freely provided by publishers (without being
compensated) should count toward bolstering a site’s/page’s
rankings.
You can implement NoFollow
using the following format:
<a href="http://www.google.com" rel="NoFollow">
Note that although you can use NoFollow to restrict the passing of link
value between web pages, the search engines may still crawl through
those links (despite the lack of semantic logic) and crawl the pages
they link to. The search engines have provided contradictory input on
this point. To summarize, NoFollow
does not expressly forbid indexing or spidering, so if you link to
your own pages with it, intending to keep those pages from being
indexed or ranked, others may find them and link to them, and your
original goal will be thwarted.
Figure 6-33 shows how a
search engine robot interprets a NoFollow attribute when it finds one
associated with a link (Link 1 in this example).
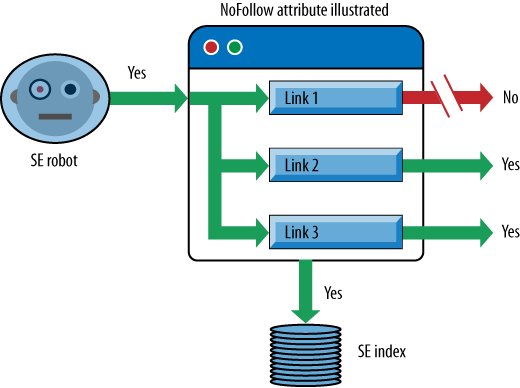
The specific link with the NoFollow attribute is disabled from passing
link juice. No other aspects of how the search engines deal with the
page have been altered.
After the introduction of the NoFollow attribute, the notion of PageRank
sculpting using NoFollow was a
popular idea. The belief was that when you NoFollow a particular link, the link juice
that would have been passed to that link was preserved and the search
engines would reallocate it to the other links found on the page. As a
result, many publishers implemented NoFollow links to lower value pages on their
site (such as the About Us and Contact Us pages, or alternative sort
order pages for product catalogs). In fact, data from SEOmoz’s Linkscape tool,
published in March 2009, showed that at that time about 3% of all
links on the Web were NoFollowed,
and that 60% of those NoFollows
were applied to internal links.
In June 2009, however, Google’s Matt Cutts wrote a post that
made it clear that the link juice associated with that NoFollowed link is discarded rather than
reallocated (http://www.mattcutts.com/blog/pagerank-sculpting/). In
theory, you can still use NoFollow
however you want, but using it on internal links does not (at the time
of this writing, according to Google) bring the type of benefit people
have been looking for in the past. In fact, in certain scenarios it
can be harmful.
The following example will illustrate the issue. If a publisher
has a 500-page site, every page links to its About Us page, and all
those links are NoFollowed, it will
have cut off the link juice that would otherwise be sent to the About
Us page. However, since that link juice is discarded, no benefit is
brought to the rest of the site. Further, if the NoFollows are removed, the About Us page
would pass at least some of that link juice back to the rest of the
site through the links on the About Us page.
This is a great illustration of the ever-changing nature of SEO. Something that was a popular, effective tactic is now being viewed as ineffective. Some more aggressive publishers will continue to pursue link juice sculpting by using even more aggressive approaches, such as implementing links in encoded JavaScript or within iframes that have been disallowed in robots.txt, so that the search engines don’t see them as links. Such aggressive tactics are probably not worth the trouble for most publishers.
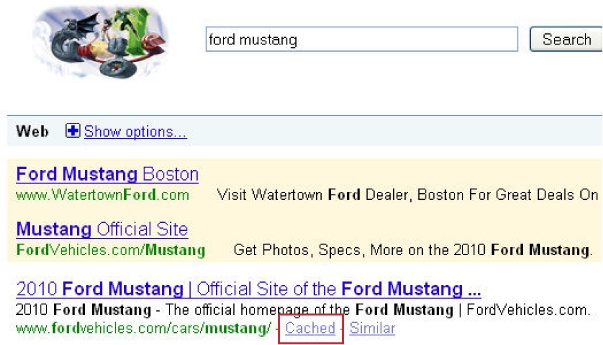
The meta robots tag has three
components: cache, index, and
follow. The cache component instructs the engine about
whether it can keep the page in the engine’s public index, available
via the “cached snapshot” link in the search results (see Figure 6-34).
The second, index, tells the
engine whether the page is allowed to be crawled and stored in any
capacity. A page marked NoIndex will thus be
excluded entirely by the search engines. By default, this value is
index, telling the search engines,
“Yes, please do crawl this page and include it in your index.” Thus,
it is unnecessary to place this directive on each page. Figure 6-35 shows what a search engine robot does
once it sees a NoIndex tag on a web
page.
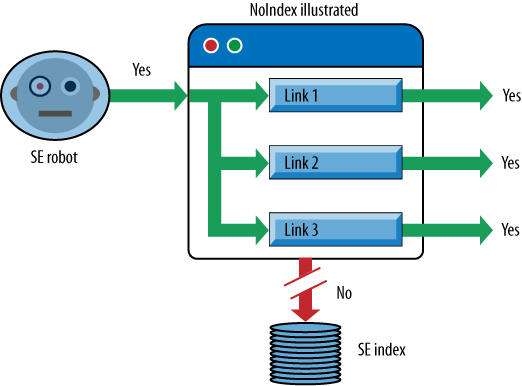
The page will still be crawled, and the page can still accumulate and pass link juice to other pages, but it will not appear in search indexes.
The final instruction available through the meta robots tag is follow. This command, like index, defaults to “yes, crawl the links on
this page and pass link juice through them.” Applying NoFollow tells the engine that the links on
that page should not pass link value or be crawled. By and large, it
is unwise to use this directive as a way to prevent links from being
crawled. Since human beings will still reach those pages and have the
ability to link to them from other sites, NoFollow (in the meta robots tag) does little to restrict crawling
or spider access. Its only application is to prevent link juice from
spreading out, which has very limited application since the 2005
launch of the rel="nofollow"
attribute (discussed earlier), which allows this directive to be
placed on individual links.
Figure 6-36 outlines the
behavior of a search engine robot when it finds a NoFollow meta tag on a web page.
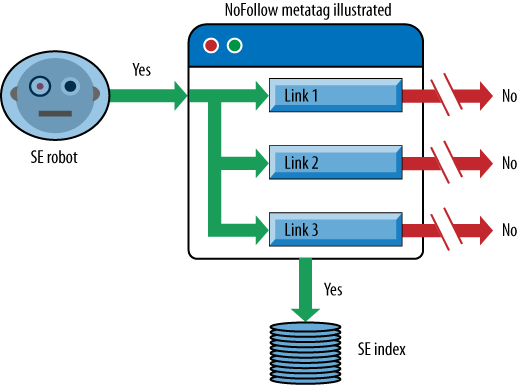
When you use the NoFollow
meta tag on a page, the search engine will still crawl the page and
place the page in its index. However, all links (both internal and
external) on the page will be disabled from passing link juice to
other pages.
One good application for NoIndex is to place this tag on HTML sitemap
pages. These are pages designed as navigational aids for users and
search engine spiders to enable them to efficiently find the content
on your site. However, on some sites these pages are unlikely to rank
for anything of importance in the search engines, yet you still want
them to pass link juice to the pages they link to. Putting NoIndex on these pages keeps these HTML
sitemaps out of the index and removes that problem. Make sure you
do not apply the NoFollow meta tag on the pages or the
NoFollow attribute on the links on
the pages, as these will prevent the pages from passing link
juice.
In February 2009, Google, Yahoo!, and Microsoft announced a new
tag known as the canonical tag.
This tag was a new construct designed explicitly for purposes of
identifying and dealing with duplicate content. Implementation is very
simple and looks like this:
<link rel="canonical" href="http://www.seomoz.org/blog" />
This tag is meant to tell Yahoo!, Bing, and Google that the page in question should be treated as though it were a copy of the URL http://www.seomoz.org/blog and that all of the link and content metrics the engines apply should technically flow back to that URL (see Figure 6-37).

The canonical URL tag
attribute is similar in many ways to a 301 redirect from an SEO
perspective. In essence, you’re telling the engines that multiple
pages should be considered as one (which a 301 does), without actually
redirecting visitors to the new URL (often saving your development
staff trouble). There are some differences, though:
Whereas a 301 redirect points all traffic (bots and human visitors), the
canonicalURL tag is just for engines, meaning you can still separately track visitors to the unique URL versions.A 301 is a much stronger signal that multiple pages have a single, canonical source. Although the engines are certainly planning to support this new tag and trust the intent of site owners, there will be limitations. Content analysis and other algorithmic metrics will be applied to ensure that a site owner hasn’t mistakenly or manipulatively applied the tag, and you can certainly expect to see mistaken use of the
canonicaltag, resulting in the engines maintaining those separate URLs in their indexes (meaning site owners would experience the same problems noted in Duplicate Content Issues).301s carry cross-domain functionality, meaning you can redirect a page at Domain1.com to Domain2.com and carry over those search engine metrics. This is not the case with the
canonicalURL tag, which operates exclusively on a single root domain (it will carry over across subfolders and subdomains).
We will discuss some applications for this tag later in this
chapter. In general practice, the best solution is to resolve the
duplicate content problems at their core, and eliminate them if you
can. This is because the canonical
tag is not guaranteed to work. However, it is not always possible to
resolve the issues by other means, and the canonical tag provides a very effective
backup plan.
You can customize entire IP addresses or ranges to block particular bots through server-side restrictions on IPs. Most of the major engines crawl from a limited number of IP ranges, making it possible to identify them and restrict access. This technique is, ironically, popular with webmasters who mistakenly assume that search engine spiders are spammers attempting to steal their content, and thus block the IP ranges to restrict access and save bandwidth. Use caution when blocking bots, and make sure you’re not restricting access to a spider that could bring benefits, either from search traffic or from link attribution.
At the server level, it is possible to detect user agents and restrict their access to pages or websites based on their declaration of identity. As an example, if a website detected a rogue bot, you might double-check its identity before allowing access. The search engines all use a similar protocol to verify their user agents via the Web: a reverse DNS lookup followed by a corresponding forward DNS→IP lookup. An example for Google would look like this:
> host 66.249.66.1 1.66.249.66.in-addr.arpa domain name pointer crawl-66-249-66-1.googlebot.com. > host crawl-66-249-66-1.googlebot.com crawl-66-249-66-1.googlebot.com has address 66.249.66.1
A reverse DNS lookup by itself may be insufficient, because a spoofer could set up reverse DNS to point to xyz.googlebot.com or any other address.
Sometimes there’s a certain piece of content on a web page (or a persistent piece of content throughout a site) that you’d prefer search engines didn’t see. As we discussed earlier in this chapter, clever use of iframes can come in handy, as Figure 6-38 illustrates.
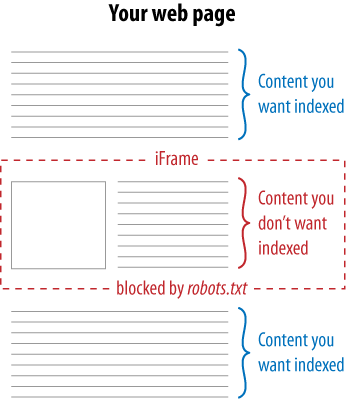
The concept is simple: by using iframes, you can embed content from another URL onto any page of your choosing. By then blocking spider access to the iframe with robots.txt, you ensure that the search engines won’t “see” this content on your page. Websites may do this for many reasons, including avoiding duplicate content problems, reducing the page size for search engines, or lowering the number of crawlable links on a page (to help control the flow of link juice).
As we discussed previously, the major search engines still have very little capacity to read text in images (and the processing power required makes for a severe barrier). Hiding content inside images isn’t generally advisable, as it can be impractical for alternative devices (mobile, in particular) and inaccessible to others (such as screen readers).
As with text in images, the content inside Java applets is not easily parsed by the search engines, though using them as a tool to hide text would certainly be a strange choice.
Search engines will not submit HTML forms in an attempt to access the information retrieved from a search or submission. Thus, if you keep content behind a forced-form submission and never link to it externally, your content will remain out of the engines (as Figure 6-39 demonstrates).
The problem comes when content behind forms earns links outside your control, as when bloggers, journalists, or researchers decide to link to the pages in your archives without your knowledge. Thus, although form submission may keep the engines at bay, make sure that anything truly sensitive has additional protection (e.g., through robots.txt or meta robots).
Password protection of any kind will effectively prevent any search engines from accessing content, as will any form of human-verification requirements, such as CAPTCHAs (the boxes that request the copying of letter/number combinations to gain access). The major engines won’t try to guess passwords or bypass these systems.
A secondary, post-indexing tactic, URL removal is possible at most of the major search engines through verification of your site and the use of the engines’ tools. For example, Yahoo! allows you to remove URLs through its Site Explorer system (http://help.yahoo.com/l/us/yahoo/search/siteexplorer/delete/siteexplorer-46.html), and Google offers a similar service (https://www.google.com/webmasters/tools/removals) through Webmaster Central. Microsoft’s Bing search engine may soon carry support for this as well.