
In the last few recipes, we've seen how to generate term frequencies and scale them by the size of the document so that the frequencies from two different documents can be compared.
Term frequencies also have another problem. They don't tell you how important a term is, relative to all of the documents in the corpus.
To address this, we will use term frequency-inverse document frequency (TF-IDF). This metric scales the term's frequency in a document by the term's frequency in the entire corpus.
In this recipe, we'll assemble the parts needed to implement TF-IDF.
We'll continue building on the previous recipes in this chapter. Because of that, we'll use the same project.clj file:
(defproject com.ericrochester/text-data "0.1.0-SNAPSHOT"
:dependencies [[org.clojure/clojure "1.6.0"]
[clojure-opennlp "0.3.2"]])We'll also use two functions that we've created earlier in this chapter. From the Tokenizing text recipe, we'll use tokenize. From the Focusing on content words with stoplists recipe, we'll use normalize.
Aside from the imports required for these two functions, we'll also want to have this available in our source code or REPL:
(require '[clojure.set :as set])
For this recipe, we'll also need more data than we've been using. For this, we'll use a corpus of State of the Union (SOTU) addresses from United States presidents over time. These are yearly addresses that presidents make where they talk about the events of the past year and outline their priorities over the next twelve months. You can download these from http://www.ericrochester.com/clj-data-analysis/data/sotu.tar.gz. I've unpacked the data from this file into the sotu directory.
The following image shows the group of functions that we'll be coding in this recipe:
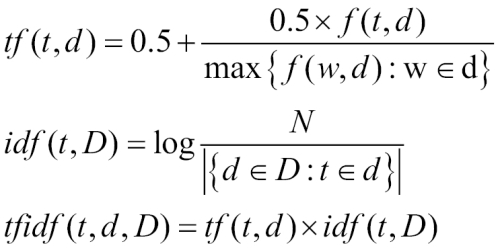
So, in English, the function for tf represents the frequency of the term t in the document d, scaled by the maximum term frequency in d. In other words, unless you're using a stoplist, this will almost always be the frequency of the term the.
The function for idf is the log of the number of documents (N) divided by the number of documents that contain the term t.
These equations break the problem down well. We can write a function for each one of these. We'll also create a number of other functions to help us along. Let's get started:
- For the first function, we'll implement the
tfcomponent of the equation. This is a transparent translation of the tf function from earlier. It takes a term's frequency and the maximum term frequency from the same document, as follows:(defn tf [term-freq max-freq] (+ 0.5 (/ (* 0.5 term-freq) max-freq)))
- Now, we'll do the most basic implementation of
idf. Like thetffunction used earlier, it's a close match to the idf equation:(defn idf [corpus term] (Math/log (/ (count corpus) (inc (count (filter #(contains? % term) corpus)))))) - Now, we'll take a short detour in order to optimize prematurely. In this case, the IDF values will be the same for each term across the corpus, but if we're not careful, we'll code this so that we're computing these terms for each document. For example, the IDF value for the will be the same, no matter how many times the actually occurs in the current document. We can precompute these and cache them. However, before we can do that, we'll need to obtain the set of all the terms in the corpus. The
get-corpus-termsfunction does this, as shown here:(defn get-corpus-terms [corpus] (->> corpus (map #(set (keys %))) (reduce set/union #{}))) - The
get-idf-cachefunction takes a corpus, extracts its term set, and returns a hashmap associating the terms with their IDF values, as follows:(defn get-idf-cache [corpus] (reduce #(assoc %1 %2 (idf corpus %2)) {} (get-corpus-terms corpus))) - Now, the
tf-idffunction is our lowest-level function that combinestfandidf. It just takes the raw parameters, including the cached IDF value, and performs the necessary calculations:(defn tf-idf [idf-value freq max-freq] (* (tf freq max-freq) idf-value))
- The
tf-idf-pairfunction sits immediately on top oftf-idf. It gets the IDF value from the cache, and for one of its parameters, it takes a term-raw frequency pair. It returns the pair with the frequency being the TF-IDF for that term:(defn tf-idf-pair [idf-cache max-freq pair] (let [[term freq] pair] [term (tf-idf (idf-cache term) freq max-freq)])) - Finally, the
tf-idf-freqsfunction controls the entire process. It takes an IDF cache and a frequency hashmap, and it scales the frequencies in the hashmap into their TF-IDF equivalents, as follows:(defn tf-idf-freqs [idf-cache freqs] (let [max-freq (reduce max 0 (vals freqs))] (->> freqs (map #(tf-idf-pair idf-cache max-freq %)) (into {}))))
Now, we have all of the pieces in place to use this.
- For this example, we'll read all of the State of the Union addresses into a sequence of raw frequency hashmaps. This will be bound to the name
corpus:(def corpus (->> "sotu" (java.io.File.) (.list) (map #(str "sotu/" %)) (map slurp) (map tokenize) (map normalize) (map frequencies))) - We'll use these frequencies to create the IDF cache and bind it to the name
cache:(def cache (get-idf-cache corpus))
- Now, actually calling
tf-idf-freqson these frequencies is straightforward, as shown here:(def freqs (map #(tf-idf-freqs cache %) corpus))
TF-IDF scales the raw token frequencies by the number of documents they occur in within the corpus. This identifies the distinguishing words for each document. After all, if the word occurs in almost every document, it won't be a distinguishing word for any document. However, if a word is only found in one document, it helps to distinguish that document.
For example, here are the 10 most distinguishing words from the first SOTU address:
user=> (doseq [[term idf-freq] (->> freqs
first
(sort-by second)
reverse
(take 10))]
(println [term idf-freq ((first corpus) term)]))
[intimating 2.39029215473352 1]
[licentiousness 2.39029215473352 1]
[discern 2.185469574348983 1]
[inviolable 2.0401456408424132 1]
[specify 1.927423640693998 1]
[comprehending 1.8353230604578765 1]
[novelty 1.8353230604578765 1]
[well-digested 1.8353230604578765 1]
[cherishing 1.8353230604578765 1]
[cool 1.7574531294111173 1]You can see that these words all occur once in this document, and in fact, intimating and licentiousness are only found in the first SOTU, and all 10 of these words are found in six or fewer addresses.