
Not all of the data on the Web is in tables, as in our last recipe. In general, the process to access this nontabular data might be more complicated, depending on how the page is structured.
First, we'll use the same dependencies and the require statements as we did in the last recipe, Scraping data from tables in web pages.
Next, we'll identify the file to scrape the data from. I've put up a file at http://www.ericrochester.com/clj-data-analysis/data/small-sample-list.html.
This is a much more modern example of a web page. Instead of using tables, it marks up the text with the section and article tags and other features from HTML5, which help convey what the text means, not just how it should look.
As the screenshot shows, this page contains a list of sections, and each section contains a list of characters:
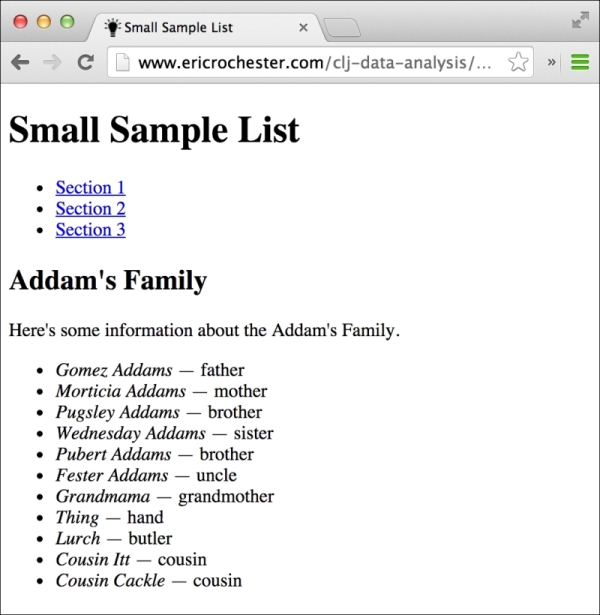
- Since this is more complicated, we'll break the task down into a set of smaller functions:
(defn get-family "This takes an article element and returns the family name." [article] (string/join (map html/text (html/select article [:header :h2])))) (defn get-person "This takes a list item and returns a map of the person's name and relationship." [li] (let [[{pnames :content} rel] (:content li)] {:name (apply str pnames) :relationship (string/trim rel)})) (defn get-rows "This takes an article and returns the person mappings, with the family name added." [article] (let [family (get-family article)] (map #(assoc % :family family) (map get-person (html/select article [:ul :li]))))) (defn load-data "This downloads the HTML page and pulls the data out of it." [html-url] (let [html (html/html-resource (URL. html-url)) articles (html/select html [:article])] (i/to-dataset (mapcat get-rows articles)))) - Now that these functions are defined, we just call
load-datawith the URL that we want to scrape:user=> (load-data (str "http://www.ericrochester.com/" "clj-data-analysis/data/" "small-sample-list.html")) | :family | :name | :relationship | |----------------+-----------------+---------------| | Addam's Family | Gomez Addams | — father | | Addam's Family | Morticia Addams | — mother | | Addam's Family | Pugsley Addams | — brother | …
After examining the web page, each family is wrapped in an article tag that contains a header with an h2 tag. get-family pulls that tag out and returns its text.
get-person processes each person. The people in each family are in an unordered list (ul), and each person is in an li tag. The person's name itself is in an em tag. let gets the contents of the li tag and decomposes it in order to pull out the name and relationship strings. get-person puts both pieces of information into a map and returns it.
get-rows processes each article tag. It calls get-family to get that information from the header, gets the list item for each person, calls get-person on the list item, and adds the family to each person's mapping.
Here's how the HTML structures correspond to the functions that process them. Each function name is mentioned beside the elements it parses:

Finally, load-data ties the process together by downloading and parsing the HTML file and pulling the article tags from it. It then calls get-rows to create the data mappings and converts the output to a dataset.