
When working with sampled data, we need to produce descriptive statistics. We want to know how accurate our estimates are, which is known as standard error of the estimate.
Bootstrapping is a way to estimate the standard errors of the estimate when we can't directly observe the data. Bootstrapping works by repeatedly taking samples of the chosen sample, allowing items to be included in the secondary sample multiple times. Doing this over and over allows us to estimate the standard error.
We can use bootstrapping when the sample we're working with is small, or when we don't know the distribution of the sample's population.
For this recipe, we'll use these dependencies in out project.clj file:
(defproject statim "0.1.0"
:dependencies [[org.clojure/clojure "1.6.0"]
[incanter "1.5.5"]])We'll also use these namespaces in our script or REPL:
(require '[incanter.core :as i] '[incanter.stats :as s] 'incanter.io '[incanter.charts :as c])
For data, we'll use the same census data that we did in the Working with changes in values recipe:
(def data-file "data/all_160_in_51.P3.csv")
This is a simple recipe. Here, we'll use Incanter's bootstrapping functions to estimate the median of the census population:
- We'll read in the data:
(def data (incanter.io/read-dataset data-file :header true))
- Then we'll pull out the population column and resample it for the median using the
incanter.stats/bootstrapfunction:(def pop100 (i/sel data :cols :POP100)) (def samples (s/bootstrap pop100 s/median :size 2000))
- Now let's look at a histogram of the samples to see what the distribution of the median looks like:
(i/view (c/histogram samples))
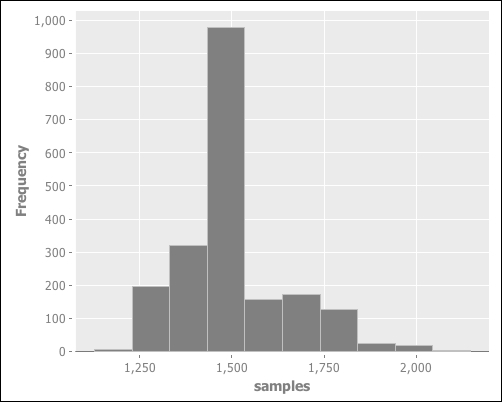
We can see that the median clusters pretty closely around the sample's median (1480).
Bootstrapping validates whether the output of a function over a data sample represents that value in the population by repeatedly resampling from the original sample of inputs to the function. But there's a twist. When the original sample was created, it was done without replacement, that is, without duplicates. The same observation cannot be included in the sample twice.
However, the resampling is done with replacements, which means duplicates are permitted. Actually, since the resample is the same size as the original sample that it's drawn from, there must be observations that are in the resample more than once.
Each resampling is then fed to the function being validated, and its outputs are used to estimate the distribution of the population.
For more about boostrapping, Bootstrap: A Statistical Method by Kesar Singh and Minge Xie is a good, general introduction ( http://www.stat.rutgers.edu/home/mxie/rcpapers/bootstrap.pdf)