
One of the most important features of a storage system is its flexibility. A good storage solution should be flexible enough to support its expansion and reduction without causing any downtime to the services. Traditional storage systems had limited flexibility; the expansion and reduction of such systems is a tough job. Sometimes, you feel locked with storage capacity and cannot perform changes as per your needs.
Ceph is an absolutely flexible storage system that supports on-the-fly changes to storage capacity, whether expansion or reduction. In the last recipe, we learned how easy it is to scale out a Ceph cluster. In this recipe, we will scale down a Ceph cluster, without any impact on its accessibility, by removing ceph-node4 from the Ceph cluster.
Before proceeding with the cluster size reduction, scaling it down, or removing the OSD node, make sure that the cluster has enough free space to accommodate all the data present on the node you are planning to move out. The cluster should not be at its full ratio, which is the percentage of used disk space in an OSD. So, as a best practice, do not remove the OSD or OSD node without considering the impact on the full ratio.
- As we need to scale down the cluster, we will remove
ceph-node4and all of its associated OSDs out of the cluster. Ceph OSDs should be set out so that Ceph can perform data recovery. From any of the Ceph nodes, take the OSDs out of the cluster:# ceph osd out osd.9 # ceph osd out osd.10 # ceph osd out osd.11

- As soon as you mark an OSD out of the cluster, Ceph will start rebalancing the cluster by migrating the PGs out of the OSDs that were made out to other OSDs inside the cluster. Your cluster state would become unhealthy for some time, but it would be good for the server data to clients. Based on the number of OSDs removed, there might be some drop in cluster performance until the recovery time is complete. Once the cluster is healthy again, it should perform as usual:
# ceph -s
Here, you can see that the cluster is in recovery mode but at the same time is serving data to clients. You can observe the recovery process using the following:
# ceph -w
- As we have marked
osd.9,osd.10, andosd.11as out of the cluster, they will not participate in storing data, but their services are still running. Let's stop these OSDs:# ssh ceph-node4 service ceph stop osd
Once the OSDs are down, check the OSD tree; you will observe that the OSDs are down and out:
# Ceph osd tree
- Now that the OSDs are no longer part of the Ceph cluster, let's remove them from the CRUSH map:
# ceph osd crush remove osd.9 # ceph osd crush remove osd.10 # ceph osd crush remove osd.11

- As soon as the OSDs are removed from the CRUSH map, the Ceph cluster becomes healthy. You should also observe the OSD map; since we have not removed the OSDs, it will still show 12 OSDs, 9
UPand 9IN. - Remove the OSD authentication keys:
# ceph auth del osd.9 # ceph auth del osd.10 # ceph auth del osd.11

- Finally, remove the OSD and check your cluster status; you should observe 9 OSDs, 9
UP, and 9IN, and the cluster health should beOK:# ceph osd rm osd.9 # ceph osd rm osd.10 # ceph osd rm osd.11

- To keep your cluster clean, perform some housekeeping; as we have removed all the OSDs from the CRUSH map,
ceph-node4does not hold any item. Removeceph-node4from the CRUSH map; this will remove all the traces of this node from the Ceph cluster:# ceph osd crush remove ceph-node4 # ceph -s

Removing a Ceph monitor is generally not a very frequently required task. When you remove monitors from a cluster, consider that Ceph monitors use the PAXOS algorithm to establish consensus about the master cluster map. You must have a sufficient number of monitors to establish a quorum for consensus on the cluster map. In this recipe, we will learn how to remove the ceph-node4 monitor from the Ceph cluster.
- Check the monitor status:
# ceph mon stat
- To remove the Ceph monitor
ceph-node4, execute the following command fromceph-node1:# ceph-deploy mon destroy ceph-node4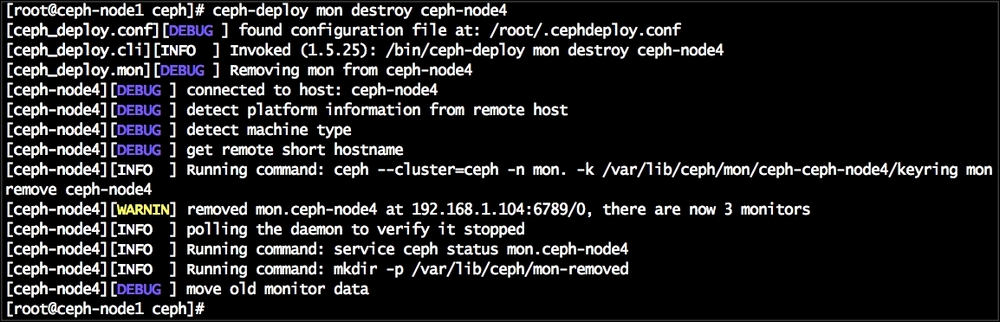
- Check to see that your monitors have left the quorum:
# ceph quorum_status --format json-pretty
- Finally, check the monitor status; the cluster should have three monitors:
# ceph mon stat