
We carry out a Spike when we're about to embark on a new piece of work and are finding it hard to make decisions about direction in business terms, technical terms, or both.
Similar in concept to a hackathon, a Spike is an investigatory piece of work which should:
- Answer a single question
- Either be technical or customer-focused
- Reduce uncertainty and create a way forward
The key thing to note is that a Spike doesn't directly contribute to an increment in the working software. As a result, we don't estimate spikes, instead we timebox them. When the timebox is up, we determine if we've answered the question we set out to answer:
- If we have, the next step is to determine how this information will help move us forward. The usual outcome is to either create new User Stories or change existing ones.
- If we haven't, then we determine if we need more time. If we do, then we set a new timebox. If we don't, then maybe we've reached a dead end and we need a new line of inquiry. If so, it's time for us to regroup and decide what to do.
A Spike should seek to push through all of the layers of our technology stack, as each of these will inform any technical or user decisions that we make:
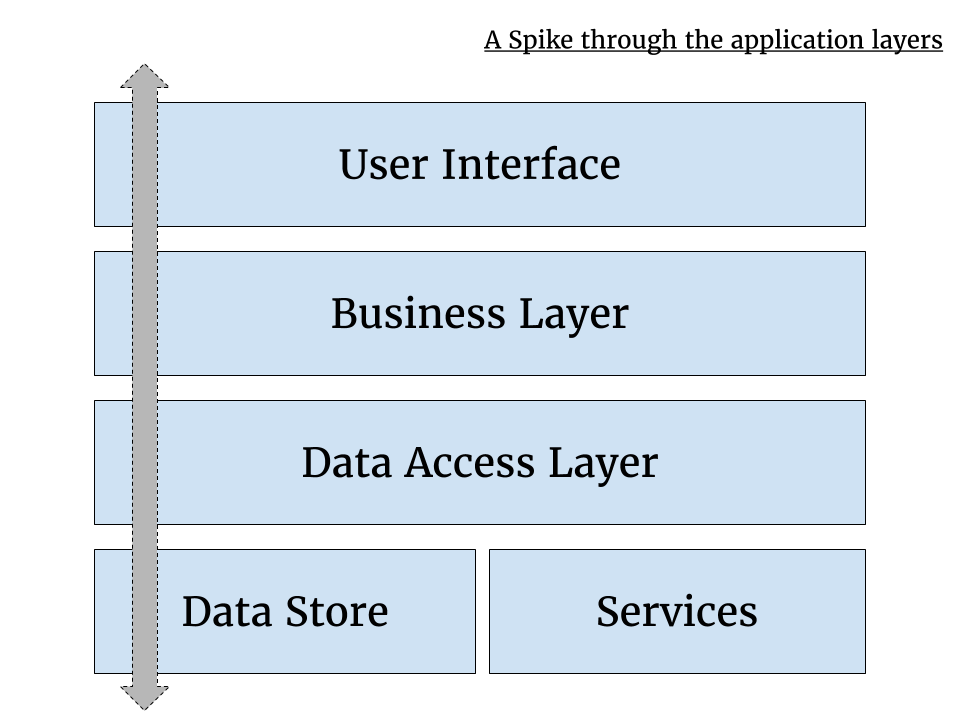
Be aware it's also a bad smell if our team use Spikes too often as there is a degree of the unknown in any User Story. A balance needs to be struck between moving forward and genuine uncertainty.
Also, any code produced during a Spike should be treated like any other prototype—rewritten to proper standards, likely from scratch.