
A Fresh Look at Semantic Natural Language Information Assurance and Security
NL IAS from Watermarking and Downgrading to Discovering Unintended Inferences and Situational Conceptual Defaults
Victor Raskin and Julia M. Taylor, Purdue University, West Lafayette, IN, USA
This chapter introduces natural language information assurance and security (NL IAS), a new front in information security effort enabled by applying the Ontological Semantics approach to natural language processing to the existing and new applications. It reviews the earlier (1999–2004) application implementations, their increasing and expanding computational semantic foundations, and new advances (2010–2013). The thrust of the chapter is that access to comprehensive natural language meaning—incrementally approximating human understanding and based on the dedicated semantic resources, the language independent property rich ontology, and language-specific lexicons—is necessary for the design and implementation of high precision applications in authenticating and protecting natural language files.
Keywords
information assurance; ontological semantics; meaning; the unsaid; situational default
Information in this chapter
Introduction
The goal of this chapter is to revisit, update, and advance significantly the issue of a possible and necessary contribution from natural language processing to information assurance and security. First, it will review the early motivation for natural language information assurance and security (NL IAS), its program, and its implementations. For some reason, until now this has never been published in a dedicated and concentrated publication. The closest we have ever come to that was a COLING 2004 tutorial [1], never presented as a cohesive text but rather only as a huge collection of PowerPoint slides, even though it was distributed widely throughout the security community. This paper will selectively borrow some pertinent factual material from that tutorial, mostly the descriptions of the implemented software because, of course, those facts—the reality on the ground, as it were—have remained the same, although their interpretation and theoretical basis have been rethought significantly since, often as clarifications rather than rebuttals to subsequent citations.
Different from the still-dominant statistical machine learning strand in Natural Language Processing (NLP) since the early 1990s, the NLP approach we have applied to IAS has been rule- and meaning-based. Its theoretical basis remains the Ontological Semantics theory developed in the 1990 s and applied to the level of academic proof-of-concept implementations. Since roughly 2005, it has been significantly revised on a continuous basis, gaining considerable momentum in the 2004–2011 proprietary implementations of product-level systems. Leaving that IP behind and persistently expanding the coverage domain as well as improving the quality of the methodology, since 2011 OST has made qualitative jumps, mostly within academia again, toward developing a new set of resources, potentially for open source use as an alternative to the currently common opportunistic resources such as WordNet [2].
Early work in NL IAS took advantage of the access to meaning of NL texts. Its fullest semantic application was semantic forensics, where the system could automatically flag contradictions as potential deception [3], but it was not until 2010 that even more sophisticated semantic techniques led to a qualitatively higher level of penetration into semantic clues revealing what is not being said. While still short of full-fledged NL inferencing and deliberately staying away from reasoning proper, this initiative has a far-reaching potential, in particular in security work.
Accordingly, the rest of the chapter consists of three major sections corresponding to early NL IAS (“Early Breakthrough in NL IAS”), the semantic foundation of this work (“A Sketch of Ontological Semantic Technology”), and new advances in NL IAS (“Mature Semantic NL IAS”). The conclusion and future work are briefly outlined in the last section.
Early breakthrough in NL IAS
The conceptual foundation of NL IAS
Information Assurance and Security is the CERIAS designation, shared by many in the 2000 s, of the general enterprise to protect computer systems and information in them from attacks. Within IAS, Information Security (IS) was often understood as protection from intrusion and unauthorized use, the area that has been recently referred to as Cyber Security, folding neatly into the domains of computer science, computer engineering, and computer technology. Information assurance (IA) has focused on ensuring the authenticity of stored and transmitted information, and it is inherently multidisciplinary: the Purdue Center for Education and Research in Information Assurance and Security (CERIAS), a leading IAS organization in the world and the first ever multidisciplinary center, includes some 80 faculty from at least 12 different departments in six colleges. Now much of the information in IA is in the form of NL texts, and that brings the necessity to handle this enormous massive of text computationally. So, as early as 1999, CERIAS started funding and encouraging a joint effort by an NLP expert (Raskin) and a computer scientist (Atallah) on what has become a new front in the IAS effort, namely, NL IAS.
By that time, NLP had progressed since the early 1950 s from machine translation (MT) to information retrieval (IR) in its various forms, such as information extraction (IE), data and text mining, question answering (QA), Internet searching, and abstracting and summarization. The rationale for NLP to move into IAS was based on the following arguments [4]:
• Information assurance and security needs make it an important and growing area of application for NLP.
• The new area of application is a healthy mix of recycling the existing modules and systems and of new adjustments and adaptations.
• One exciting innovation is the clearly identified need of “lite” versions of tools and resources, which are incremental but non-adhoc meaning-based enhancements for bag-of-words applications.
The symmetrical rationale for IAS to be receptive to NLP listed these arguments:
• Inclusion of natural NL data sources as an integral part of the overall data sources in InfoSec applications.
• Analysis of NL at the level of meaning, that is, with the knowledge-based methods, such as Ontological Semantics.
• Re-use of already implemented and tested systems of MT, IR, IE, QA, planning and summarization, data mining, information security, intelligence analysis, etc.
Within NL IAS, NL IA has been understood as the global task of protecting NL information on computer systems by guaranteeing its authenticity and preventing its misuse and abuse; as such, it has largely been a part of the digital rights protection effort. NL IA applications centrally include:
Somewhat symmetrically again, NL IS has been seen as using NL and/or ontological clues for the traditional tasks of information security, such as network protection, intrusion detection, trusted computing, etc. Its applications largely include:
NL IA applications
In this subsection, we briefly describe a selection of central NL IA applications.
NL watermarking
This is the most cited, emulated, criticized, and attempted-to-improve-on application, most probably because it spent a year on a provisional patent and was then abandoned, both actions initiated by the authors’ institution. We discuss here the more advanced and hard-to-emulate semantic version of it rather than the simpler syntactic version [6]. The main principle was that we created a 128-bit hash of the entire document, selected at random 64 sentences in the text to carry two bits each, and applied a published traversal procedure [7] to a semantic representation of the meaning of the carrying sentence produced by Ontological Semantics as its text-meaning representation (TMR).
At the time, there had been a few attempts to watermark an NL text. The approach that had gained the most currency was based on watermarking text on the same principle as an image. It was obviously harder to do with the letters, so they tweaked the proportional spacing. A smart idea it was; however, it was easily defeated by OCR software. Embedding the watermark in an automatically generated text that followed the rules of the English sentence, another smart low-hanging fruit of an idea, made it impossible to detect by computers equipped only with syntactic rules, but it also made these texts stand out for any smarter computer as well as for any human speaker or reader of English. Such attempts violated at least some of the principles of efficient watermarking that had been developed in a highly successful enterprise of watermarking images: those provided a lot of pixels to play with in the margins of an image without the human eye noticing any difference when a lot of them from, say, the human face on a portrait, were deliberately switched from blue, for example, to red.
The watermark technology we developed lived up to the standard requirements of image watermarking, which include:
We watermarked the digital NL text itself—in fact, its meaning, not the form—and most certainly not its printed, video, audio, or any other image, nor any particular format, such as MS Word, Adobe PDF, XML, etc. It survived anything but the most radical meaning changes, namely:
Very simplistically, the overview of the watermarking algorithm can be represented as follows:
• Choose subset t1,…,tm of sentences from the text being watermarked to carry a watermark in a k-based procedure.
• Represent text as a sequence of TMR (semantic) tree representations T1,…,Tn for each of its sentences s1,…,sn.
• “Arborize” each TMR; that is, turn it into a tree in case it is not one already.
• Use secret key k (large prime number).
• Map each tree into a bit string B1,…,Bn using keyed hash Hk(T(s)).
Transform the subset such that β≤8 bits of each Bt1,…Btα correspond to the watermark W: if the transform already carries the necessary two bits (about 25 percent of all cases, on the average, obviously), leave it as is; if not, apply any one of the three prescribed techniques to transform the sentence, and hence its tree, until the targeted pair of bits is achieved.
The three prescribed procedures, grafting (adding), pruning (dropping), and substitution, each operating algorithmically with the prescribed lists and tables, create minor changes in the carrying sentences, such as adding something like “generally speaking,” dropping similar expressions, or substituting, say, “Kabul” with “the capital of Afghanistan”—or vice versa. To mask the carrying sentences further, it is optionally recommended to perform similar transformations in a number of non-carrying sentences as well to fake a stylistic feature and thus further hide the watermark-carrying sentences. (Because the procedure is designed mainly for government- or corporation-generated papers, verbose and stylistically garbled on their own, our minor changes did not affect the readers’ perception of the styles.)
NL tamperproofing
The NL watermarking technique can be interestingly reversed from the search for the most robust, indestructible watermark to that for the most brittle one, so that any tampering with a document, other than mere formatting, would invariably lead to the removal of the watermark. It shares the Ontological Semantics basis with NL watermarking, but it adds the chaining algorithm, so that the slightest change in the original breaks the watermark and thus signals tamper-proofing.
The chaining of sentences according to secret ordering includes:
• Semantic “mini-watermark” of b bits inserted in each sentence
• Dependence of the watermark on all predecessors of that sentence in the chain (“fragilization”)
This makes the probability of a successful attack on a sentence equal 2−β, where β is the distance from the end of the chain. After applying this preliminary scheme, we repeat it but now chain sentences according to the reverse of secret ordering, including:
• Syntactic “mini-watermark” of β bits per sentence
• Dependence of the watermark on all successors of that sentence in the secret ordering
This makes the probability of a successful attack on a sentence 2−β that is 1+the total length of the chain. Then, at the first pass of a semantic marking scheme, we need to state precisely which β bits are to be the inserted as a “mini-watermark” in each sentence. Let H denote a keyed hash function. We do the following
• Compute x1=Hk(1…1)=the keyed hash of all 1’s (e.g., 100 ones)
• Insert (as a watermark) in s1 the leftmost β bits of x1
• Then for i=2, … , n we do the following:
• Compute xi=Hk(xi–1, Ti–1), where xi–1, Ti–1 denotes the concatenation of xi–1 and Ti–1, and Ti–1 is the TMR tree obtained from the already marked version of sentence si–1
• Insert (as a watermark) in si the leftmost β bits of the just-computed xi
The verification phase that corresponds to the first pass is a similar pass, except that instead of inserting β watermark bits in an si, we read them and compare them to the leftmost β bits of xi. Because of the “forward chaining” from 1 to n, the probability that a modification of si goes undetected by this “first pass verification” is ![]() .
.
The second pass is a syntactic marking scheme (so it does not change any of the TMRs resulting from the first pass). We need to state precisely which β bits are to be the inserted as a “mini-watermark” in each sentence. As before, Hk denotes a keyed hash function. We then do the following:
• Compute xn=Hk(1…1)=the keyed hash of all 1’s (e.g., 100 ones)
• Insert (as a watermark) in sn the leftmost β bits of xn
• Then for i=n–1, … , 1 we do the following:
• Compute xi=Hk(xi+1, Ti+1), where xi+1, Ti+1 denotes the concatenation of xi+1 and Ti+1, and Ti+1 is the syntax tree obtained from the already marked version of sentence si+1
• Insert (as a watermark) in si the leftmost β bits of the just-computed xi
The verification phase that corresponds to the second pass is a similar pass, except that instead of inserting β watermark bits in an si, we read them and compare them to the leftmost β bits of xi. Because of the “backward chaining” from n to 1, the probability that a modification of si goes undetected by this “second pass verification” is 2–i.
The probability that a modification to si escapes detection by both the first-pass verification and the second-pass verification is, therefore, ![]() .
.
NL sanitizing/downgrading
The need to suppress certain information from documents that have to be published or shared with less than fully trustworthy or authorized parties is ubiquitous. Governments have to monitor the distribution of classified information; businesses must protect their trade secrets and other proprietary forms of their intellectual property.
In the late 1990 s, the US Department of Energy, guarding primarily nuclear secrets, had over 700 rules of declassification, mostly listing words and phrases that could not be listed, and it took their human analysts a very long time to redact texts manually and then getting the authorization—up to two person-months for a 20-page document. So the idea of computing the process was natural.
Non-semantic NLP can only operate on character strings, and without understanding the meaning of a text, it is very hard to add, delete, or substitute the sensitive material. Attempts were made to create lists of synonyms for classified terms, but this rarely worked smoothly. Statistical methods, with their admitted 15–20 percent error rate, are not typically employed for this task.
To complicate matters, downgrading rules rarely ban the use of a term and stop there. In a mock-up but realistic example, a term like nuclear submarine will be allowed, but any information about the location of any particular vessel and its fuel capacity, which is essential for calculating the speed of its getting to the next location from the previous one, cannot be mentioned.
The OST Lexicon entry for nuclear submarine, in significantly simplified form, is as follows. The declassification rule will not allow the system to fill the location and speed slots.
nuclear submarine
(isa warship)
(theme-of build, commission, decommission, deploy, destroy, attack)
(instrument-of attack, support, transport, threaten)
(propel-mode surface, sub-surface)
(engine-type nuclear-engine)
(range N < x < M)
(speed K < y < L)
(current-location body-of-water and/or geographic point and/or coordinates and/or relative, time-range)
(prior-location…)
(next-location …)
(current-mission …)
An advanced OST procedure is capable of filling a location slot by running into a report that a couple of US sailors were involved in a bar brawl in Manila on a certain date, if the system’s InfoStore has no other American vessel in port.
A proof-of-concept downgrading system based on Ontological Semantics was implemented at the master’s thesis level [8].
NL steganography and steganalysis
Steganography is the ancient art of concealing a secret message in an innocuous text. It has been widely used in the world of intelligence and terrorism: in fact, after 9/11, it was revealed [9] that several steganographic messages in Arabic had been intercepted by US agencies (but not deciphered until after the attack). Steganalysis, discovering the hidden message, is heuristic rather than algorithmic, and we have not implemented any OST approach to it [5].
Since watermarking is essentially a specific case of steganography, the OST-based algorithms for steganography follow the OST watermarking techniques for the existing texts. We have demonstrated, however [10], that OST can significantly advance the mimicking technique, that is, generating the cover text to hide the message. The original technique was based only on syntax, and using context-free grammar, it created cover texts that looked syntactically well-formed and thus could fool the computer-based detection programs that were not meaning-based. Obviously, reversing analysis into generation, OST can mimic texts that are semantically correct and thus fool non-expert humans.
A sketch of ontological semantic technology
The architecture of the Ontological Semantic Technology (OST—see [11–16]) is shown in Figure 3.1. The engineered language-independent ontology is acquired semi-automatically, with a minimum of “human computation,” to use a gimmicky new term (see [17] and references there) for a hybrid human-computer effort that we have been using for over two decades. The language-specific lexicons contain lexical entries for all senses of all words and phrasals of the language, and their meanings are anchored in the appropriate concepts of the ontology, with all of the concepts’ properties assigned a concept or literal filler. The POST (Processor for/in OST) uses all of these and other resources to convert each sentence of a text into a text meaning representation (TMR).
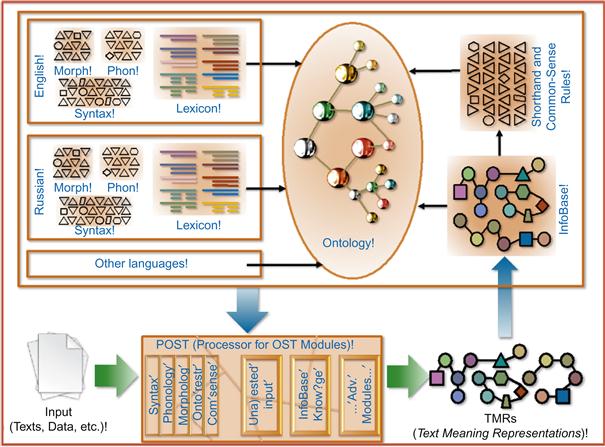
The oval centerpiece is the language-independent property-rich ontology, whose two main branches are event and object, connected by properties. In each language-specific lexicon, such as English, Russian, Korean, etc., every sense of every word is represented in ontological terms. Besides, the lexicon contains the morphosyntactic information about every word, such as where and in what syntactic context it occurs in sentences. When a sentence in a natural language is input, the system reads every word linearly, finds in the lexicon, and generates the ontological structure of the sentence, mostly and most ubiquitously by fitting the objects in the event as agent, theme, instrument, etc. (see [18]: Chs. 6, 7.1–2, and 8.1–2 on these basics). The result is the text-meaning representation (TMR) of the disambiguated meaning of the sentence.
Each successfully processed TMR is stored, along with the exact wording information, in the InfoBase. Along with the running, the testing and evaluation procedure of “blame assignment” identifies cases when a failure to disambiguate or even to generate a TMR is due to a missing common sense information, and a procedure of identifying this information, similar to that for understanding such unattested input as words that are not in the lexicon, is then activated (see, for instance, [16]).
Below is an example of an OST concept drive in the XML format, one of the many basically isomorphic formalisms, with all of which the OST resources are fully compatible:
<concept-def>
<name>drive</name>
<date>2013-02-14T20:06:38.704-05:00</date>
<anno><def>to operate a motor vehicle</def></anno>
<is-a>
<concept>
<name>move-vehicle</name>
</concept>
</is-a>
<property>
<name>agent</name>
<filler facet="sem">
<concept><name>human</name></concept>
</filler>
</property>
<property>
<name>instrument</name>
<filler facet="sem">
<concept><name>vehicle</name></concept>
</filler>
</property>
</concept-def>
Formally, the OST ontology is a lattice of conceptual nodes. In other words, the ontology can be looked at as a graph with labeled nodes, with the labels ignored by the machine and used only for identification, and edges named with the properties, one property per edge, corresponding to the concept-property filler connection between any two nodes.
In the example above, since DRIVE is a SubClassOf MOVE-VEHICLE, along with LAND, DOCK, TO-PARK, and TAKE-OFF-PLANE, a number of properties for DRIVE, such as time and instrument, are inherited from MOVE-VEHICLE. The IS-A relationship is based on the simple subsumption: “A property p subsumes q if and only if, for every possible state of affairs, all instances of q are also instances of p” [19]. If not for the multiple parenthood possibility, making the ontological graph into a lattice, the inheritance would be simply monotonic; as it happens, in cases of multiple parenthood, the child inherits from all parents.
Several versions of the ontology and lexicons, significantly upgraded between versions, have been used in academic, proof-of-concept ([18]: Ch. 1), and commercial applications. The largest version used under 10,000 concepts and under 400 properties to define over 100,000 English word senses.
While statistical approaches to NLP still dominate the field, seriously constraining the achievable level of precision in application implementations well below the users’ tolerance levels, some creeping semanticalization has been taking place. Lacking the credentials and resources to aim for comprehensive meaning representation, researchers try to patch up their systems with shallow ontologies—often automatically extracted and thus not very informative word lists—and, quite popularly, WordNet, a loose thesaurus that was originally created for psychological association experiments [2].
In this spirit of NLP semanticalization and, hence, better results in applications, we would like to take the semantic information used in NLP work to a finer grain size, beyond semantic types and synonymy/antonymy, to the level of explicitly represented concepts and properties that define the meaning of words in all of their senses. The existing semantic resources, such as WordNet, stop short of this level of representation. One could argue that WordNet synsets, when organized well, do—or at least should—correspond to a property that is the basis for the similarity. But, in our experience, a lexicon that uses these properties explicitly, while they come from a tight hierarchical structure of all properties and their fillers, does present a finer-grained representation of meaning. This is how the ontological semantic resources are organized.
An immediate advantage of the OST grain size of semantic representation is that it can support inferences, such as (1b), that have words not used in the premise (1a), are not synonyms or antonyms of those words, and do not even belong to the same semantic types.
The OST lexicon anchors the English verb drive in the concept DRIVE, from which it obtains VEHICLE as the INSTRUMENT. VEHICLE has CAR as a SUBCLASS, and CAR has a large numbers of fillers for the property BRAND-NAME, of which HONDA is one, and it will anchor the lexical entry Honda in the OST English lexicon. OST also has the DEFAULT facet for its properties, which turns out to be useful to mark situational defaults that are essential for understanding the unsaid.
Example (1) opens the way to a discussion of implicit meaning, unintended inferences, and conceptual defaults in the next section. But first, equipped with some basic information on OST, we briefly review the most semantic NL IAS application of the early 2000s, semantic forensics [3].
Mature semantic NL IAS
In this section, a brief review of the most semantically advanced application of the earlier period in NL IAS, semantic forensics, the algorithmic calculation and representation of unintended inferences, other implicit meanings, and finally, conceptual defaults are introduced and discussed in the aspect of their recent applications to NL IAS.
Semantic forensics
After minimal experience, people learn to produce lies, “white” and otherwise, as well as to expect and detect them. They do it by processing meaning, building expectations, and comparing the received content against those expectations. They detect contradictions (easy), omissions (harder), glossing over (harder still), and sophisticated lying (by inference, very hard). Can we emulate those abilities computationally? Semantic forensics was an early attempt to answer this question [3].
The application was triggered by a real-life event: a 10,000-word investigative profile of Howard Dean in a Sunday Times issue during a tumultuous Democratic primary in the US 2004 presidential election. The New York Times ran such a profile on each of the nine high-profile candidates on nine consecutive Sundays. Howard Dean, the former governor of Vermont, led the pack for a short while, and his family background was rather prominently Republican. The reporter did not seem to spare a single compromising detail: hereditary Republicanism, a (rich) Park Avenue childhood, the $7 million that Howard’s father left him and his somewhat troubled brother. Moreover, that father and his father (Dean’s grandfather) had both been presidents of a country club that, until recently, had not admitted Blacks or Jews. What I, a text-processing human, with enough motivation and alertness, could not help noticing was that the father’s profession was never mentioned. What could it have been that it was unmentionable in a sympathetic report? And could that omission have been detected computationally?
Actually, yes: ontological semantics could accommodate it pretty easily (using the alternative, early, easy-to-read LISP-like format):

This is, of course, the most elementary case of finding an omission, which is still harder than a direct contradiction, which is flagged by the system when a new TMR directly contradicts a previously processed TMR that is stored in the system’s InfoBase.
Unintended inferences and the meaning of the unsaid
The first mature NL IAS contribution was unintended inference [14,20], a sketch of an algorithmic process that catches unsolicited remarks, usually in relaxed private conversations, and derives information these remarks divulge, to a high degree of confidence, that the speakers neither intend to divulge nor become normally aware that they have. This is reiterated and exemplified later in this section in a more substantive fashion, albeit briefly, in the much broader context of the meaning of the unsaid, to which that venture finally led.
Understanding and processing information contained in natural language text has been the major challenge for natural language and information processing. The extent to which a computational system can comprehend and absorb the information similarly to what humans do determines how well it can implement any number of past, current, and future applications that use natural language as input. This is a tall enough order by and of itself, but it is complicated enormously by the fact that a human does not limit his or her understanding to what the text actually says.
A considerable part of the information that a human gets out of the text is not expressed there explicitly: it is considered too obvious and too well-known to the hearer or reader to be stated; it may be inferred from the text absolutely or with high enough probability; it may be hinted or insinuated; it may be presupposed, entailed, or inferred.
Humans uses their backgrounds, general and specific knowledge of how things are, domain experience, familiarity with a situation and/or its participants, etc. to understand a text, and the better informed the hearers or readers are, the more informed they are by what is unsaid, if we assume—rather counter-factually at a finer grain size—that they all interpret what is said differently. The huge divergence between the “minimum” and “maximum” comprehender is the latter’s ability to populate the unsaid with all the pertinent background information enabling its calculation.
The examples are ubiquitous, varying from such a primitive case as understanding (2) as John’s having used a key, without any need to mention the instrument of his action; to assessing (3) as a complaint, based on the never-mentioned notion that the (or even, a) line does not—or should not—normally take so long; to realizing that the observed and reported deployment of an enemy army division without any visible presence of the Corps of Engineers—with their bobcats, bulldozers, and other digging and construction equipment—is very likely to indicate the offensive, not defensive, intentions of the deployment because it is engineers that build trenches, bunkers, antitank barriers, etc.; to, finally, correctly interpreting the absence of military brass in a top-level US delegation to Israel as removing the controversial issue US F35 sales to Israel from the meeting agenda.
Let us consider the following English sentences:
(3) I spent over an hour in the check-out line.
(4a) John unlocked the door with the key.
(4b) John unlocked the door with a key.
(5a) John unlocked the door by inserting the key and turning it.
(5b) John unlocked the door by entering the code.
(5c) John unlocked the door by entering his personal code.
(5d) John unlocked the door by entering the appropriate code.
(6a) John unlocked the door, and Mary invited him in.
(6b) John unlocked the door for Mary, and she invited him in.
We claim that (4a and 4b) are more appropriate and likelier to be heard or read than (2). A key is what one normally opens a locked door with, and the definite article the indicates that the key should be the one for that very lock. If we replace it with a, we will assume that John did not know which key of several corresponded to that door and tried several, or he did not have the correct key and wanted to check if some other key might fit. The sentence (5a), in the same situation, is extremely obvious, to the point of absurdity and non-acceptability, while (5b) is perfectly appropriate. In (5c), his personal seems redundant, as indeed is the appropriate in (5d).
We equally claim that (7a) raises a question, while (7b) does not. Equally—or perhaps slightly less—obviously, it is normal for the host to unlock his or her own door and to let a companion in. So the second clause of (7a) raises the question why, which for Mary settles, doubling up as the introduction of a companion to the scene.
We introduce the term “default” for those bits of information that the speaker and hearers both take for granted and consider unworthy to be mentioned. We are interested in the hypothesis that people communicate felicitously when they omit defaults, while considering a deviation from them to be worthy of relaying. See more on defaults below.
Situational conceptual defaults
The term, its origins, and the canonical case
Examples 2 through 6 above present perhaps one of the simplest, most canonical, and archetypal cases of defaults. To reflect this fact, the OST concepts of LOCK and UNLOCK make KEY the filler of the INSTRUMENT property on the DEFAULT facet. In researching the meaning of the unsaid, we use the term “default” to mark all kinds of information that it is unnecessary and, in many cases, inappropriate to make explicit because it is obvious and therefore both uninformative and uninteresting to the hearers. This sense of default is also compatible with the terminology of the logic of default reasoning [21], also known as default logic, which allows the use of implicit propositions—such as that birds can fly—in the calculation of logical inferences. By the same token, default logic also introduced probabilistic reasoning [22] because, while most birds do indeed fly, chickens and ostriches do not. In our usage, defaults are situational because they occur in specific semantic situations, and they are conceptual because they are contained in, or follow from, the OST ontology.
Default reversal
Not only will failing to omit with the key in (4a) be perceived by the hearers as redundant, tautological, and boring, but it may also offend them because of the speaker’s possible implication that something that should be obvious is not part of their cognitive and/or intellectual baggage. Alternatively, guided by Grice’s [23] Co-Operative principle, the hearer(s), instead of dismissing the speaker as deficient or incompetent, may consider an alternative, somewhat more sophisticated but still easily accessible interpretation: that the reason the default is verbalized when it should not be is that it is not the default. What if John is a burglar (or a locksmith) who usually unlocks doors without having access to the correct keys and uses two paper clipsor a credit card instead? This default reversal was analyzed as an invaluable clue for detecting and representing the meaning of an unintended reference [24], often the last resort in detecting and exposing an inside traitor [22].
In a real-life example in the unintended inference research, a professional woman calls her cousin and angrily relates to her cousin that her boss wants her to fly to Frankfurt, Germany, from the United States by coach. Now, flying coach is a default for all but the very few, so when someone (of the “99 percent”) reports that he or she has just flown to Frankfurt, coach class is assumed unless explicitly indicated otherwise. In the cousins’ conversation, the traveler explicitly verbalizes that she traveled by coach, thus changing the default to first or business class. This happened to be factually true, in her case; she is an executive in a large company, but not an inside traitor at all. She naively gave away the fact that the company was cutting down on its travel expenses in a pretty drastic way, and that could be heard and interpreted as a signal to get rid of its stock.
Are defaults really common sense knowledge?
We found ourselves in disagreement with a somewhat careless statement in passing in an abstract by Raghavan [25], which said that “[h]uman readers naturally use common sense knowledge to infer … implicit information from the explicitly stated facts.” This is true only partially; going back to the numbered (and the two unnumbered) situations above, example (2), the key example, is the only one that can be referred to as common sense knowledge (a legitimate OST component presented by us at WI-IAT 2011 [16]). The two unnumbered situations deal with specialized domain knowledge—military and political, respectively—the latter of which is, in addition, highly time-sensitive. Example (3) is an element of situational knowledge shared by all, independent of their education and/or special knowledge, who have lived in the world of check-outs. We selected the adjective “situational” to use with our term—if and when an adjective is necessary to separate the term from the non-terminological uses and specific ones in different domains.
What is fair to say is that situational defaults may be based on any shared knowledge and work when used among those who share that knowledge. The real picture is much more complicated than the concentric circle figure representing individual, private knowledge inside, the group knowledge including it, and common sense knowledge as the larger circle ([26]: Ch. 2), but every individual is indeed encircled by those layers—except that one belongs to various groups and thus is encircled by various group knowledge circles.
Underdetermination of reality by language
The ubiquitous problem of underdetermination of reality by language remains surprisingly unexplored (see, however, [27–29]) with regard to natural language, because humans use natural language usually blissfully unaware of the problem—except when reporting on a piece of news to somebody and discovering that they cannot answer many questions about the piece. Thus, the sentence Two men walked into the room leaves out tons of information about them. HUMAN has tons of properties in the OST ontology; some of them are physical, such as age, height, mass, eye color, and hair color; and none of them are provided in the sentence. Humans have professions, they wear clothes, and they self-propel themselves, as those two men apparently did. They had not been born yesterday, so they had done things prior to walking into the room. They may have slept the night before at their homes or hotels. They may have eaten breakfast or lunch or even dinner, depending on the time of the day—which is also, by the way, not indicated.
The coverage of all these properties depends on the grain size of the statement, and if the listener or reader wants to refine the grain size in any respect they will ask the speaker or writer additional questions. But no matter how many questions they ask, they will never cover all of the properties, and they will be satisfied with a description of the situation that is partial and selective. In the context of the unsaid, implicit information, the acceptance of such undetermining statements is possible because of the defaults—some of them absolute, such as wearing clothes in public—and most probabilistic, such as having had breakfast. For humans, the defaults bridge the gap between whatever they may potentially want to know about the situation and what is actually, stated explicitly.
It is clear, of course, that requests for more details may be completely fatuous. Thus, it would be pretty weird to want to know if the men liked Quentin Tarantino’s movies unless there is some obvious connection between the director and the room (such as, for instance, the men have shot people in the room, covering the floor with pools of blood, and there is one person who inquires about the murderers’ cinematic preferences), but the ability to produce pertinent questions is cognitively important for humans, and the fact that they can answer these questions themselves, without asking them of their interlocutors, is invaluable.
Humans are enabled in this respect by defaults, and this is why it is essential for any form of Web intelligence—in fact, for any computational processing of information—that default knowledge be made available to the computer. Some of it may be present in the form of stated facts, but most will result from applying rules to the explicit statement, with some of these rules being based on the available knowledge and others—lacking the requisite knowledge—on learning algorithms.
Scripts
Finally, the last issue to consider in this subsection is that most of our knowledge, and hence, default knowledge, comes in scripts. Everybody knows about the script of going to a restaurant from the early and naïve attempt to treat it computationally in Schank and Abelson [30]. A typical script is a chronological and/or causal sequence of events that constitute a standard way of doing things or of how things happen. Raskin et al. [31] present an early attempt to accommodate the script of approaching bankruptcy in Ontological Semantics (not yet OST); incidentally, the inadvertent give-away in the coach/first class statement by that executive in a large and (still) prosperous company is a possible component of the script of approaching bankruptcy.
Anonymization
Referring to essentially a form of sanitizing or downgrading a text (see the section on early NL IAS above), the term “anonymization” has been widely used to designate the US law concerning privacy, especially an individual’s guaranteed protection from revealing private data to those unauthorized by law or the individual’s consent to access them. In a standard computer application, anonymization is achieved by removing all human names, addresses, social security or other identifying numbers, and often geographic locations. It is harder to generalize this to all named entities, because some statistical data, pooled from many private records, may be necessary to preserve.
Much of the research and application work has been invested in protecting health records, especially in connection with centralizing them, as per new legislation. In fact, this work has replaced many other IAS concerns of the recent past as the leading area in security. The state of the art shows, again and again, that statistical and other pre- and non-semantic approaches fall short of preventing reidentification after all the obvious identifying data are removed. Thus, if it follows from the record that the patient was a female African American senior army officer who lost a leg in action, this combination of features will probably uniquely identify one individual. A typical target in anonymization, marked by the variable k, is preset at k=3.
The way humans reidentify anonymized data is by using all the semantic clues left intact in the text. These clues are based on explicit text meaning, with its basis in conceptual structures and properties, as well as on implicit meaning, inadvertently divulged inferences, scripts, and everything else discussed in the previous subsection. We are now implementing a major anonymization draft, for which OST is accordingly implemented and extended (see Acknowledgments).
Summary
This chapter provides an updated view of Natural Language Information Assurance and Security, an effort in porting Ontological Semantics and, later, Ontological Semantic Technology, to previously existing assurance and security applications as well as to those that this approach has uniquely enabled. An argument is presented, in multiple facets, that computational access to meaning is necessary for any chance to implement successful IAS applications. Most of the chapter is devoted to the newest methods for enabling the computer to access natural language meaning, especially implicit meaning, using situational conceptual defaults, that is, the most obvious information that is typically omitted by speakers and writers. The significance of the approach to successful anonymization of health records is mentioned as a significant current application being implemented on its basis.
Many of the mentioned applications need to be implemented beyond the proof-of-concept level to a full-fledged off-the-shelf product level. Others have to be advanced from algorithms to fully implemented code. Even more importantly, we have to be on constant alert for new applications and new functionalities of the existing ones that the meaning-based approach uniquely enables.
Acknowledgments
This research has been partially supported by the National Science Foundation research grant “TC: Large: Collaborative Research: Anonymizing Textual Data and Its Impact on Utility.” The authors also wish to express their gratitude to their co-authors in the cited works and students participating in the classroom discussions of and research projects in NL IAS, especially in Taylor’s class, Spring 2013 CNIT 623: Natural Language in Information Assurance and Security.
References
1. Raskin V. Tutorial on natural language information assurance security. COLING 2004.
2. Fellbaum C. editor WordNet: An electronic lexical database Cambridge, MA: MIT Press; 1998.
3. Raskin V, Hempelmann CF, Triezenberg KE. Semantic forensics: An application of ontological semantics to information assurance. In: Hirst G, Nirenburg S, eds. Proceedings of the Second Workshop on Text Meaning and Interpretation. Barcelona, Spain: ACL; 2004 Jul:25–26.
4. Raskin V, Nirenburg S, Atallah MJ, Hempelmann CF, Triezenberg KE. Why NLP should move into IAS. In: Krauwer S, ed. Proceedings of the Workshop on a Roadmap for Computational Linguistics. Taipei, Taiwan: Academia Sinica; 2002;1–7.
5. Atallah MJ, Raskin V, Hempelmann CF, Karahan M, Sion R, Topkara U, et al. Natural language watermarking and tamperproofing. In: Petitcolas FAP, editor. Information Hiding. Berlin-New York: Springer Verlag; 2002. p. 196–212.
6. Atallah MJ, Raskin V, Crogan M, et al. Natural language watermarking: Design, analysis, and a proof-of-concept implementation. In: Moskowitz IS, ed. Information Hiding. Berlin-New York: Springer Verlag; 2001;193–208.
7. Atallah MJ, Wagstaff SS. Watermarking data using quadratic residues. Working Paper, Department of Computer Science Purdue University 1996.
8. Mohamed D. Ontological semantics methods for automatic downgrading [unpublished thesis]. W. Lafayette (IN): Linguistics and CERIAS, Purdue University; 2001.
9. Hersh SM. Missed messages: Why the government didn’t know what it knew. New Yorker. 2002 June 3.
10. Bennett K. Ontological semantic generation for mimicking texts in steganography. The Purdue Ontological Semantic Project, MCLC Bloomington: Indiana University; 2004.
11. Raskin V, Hempelmann CF, Taylor JM. Guessing vs. knowing: The two approaches to semantics in natural language processing. Annual International Conference Dialogue; 2010a. p. 642–50.
12. Raskin V, Taylor JM, Hempelmann CF. Meaning- and ontology-based technologies for high-precision language in information-processing computational systems. Advanced Engineering Informatics 2013.
13. Hempelmann CF, Taylor JM, Raskin V. Application-guided ontological engineering. International Conference on Artificial Intelligence; 2010.
14. Taylor JM, Hempelmann CF, and Raskin V. On an automatic acquisition toolbox for ontologies and lexicons in ontological semantics. International Conference on Artificial Intelligence; 2010a.
15. Taylor JM, Hempelmann CF, Raskin V. Post-logical verification of ontology and lexicons: The ontological semantic technology approach. International Conference on Artificial Intelligence; 2011a.
16. Taylor JM, Raskin V, Hempelmann CF. From disambiguation failures to common-sense knowledge acquisition: A day in the life of an ontological semantic system Web Intelligence Conference 2011.
17. Law E, von Ahn L. Human computation San Rafael: Morgan & Claypool 2011.
18. Nirenburg S, Raskin V. Ontological semantics Cambridge: MIT Press; 2004.
19. Guarino N, Welty CA. An overview of OntoClean. In: Staab S, Studer R, eds. Handbook on Ontologies. Berlin: Springer; 2004;151–159.
20. Raskin V, Hempelmann CF, Taylor JM. Ontological semantic technology for detecting insider threat and social engineering Concord, MA: New Security Paradigms Workshop; 2010.
21. Reiter. A logic for default reasoning. Artificial Intelligence. 1980;13:81–132.
22. Wheeler and Damasio. An implementation of statistical default logic. Proc. 9th European Conference on Logics in Artificial Intelligence (JELIA 2004). LNCS Series, Springer; 2004. p. 121–123.
23. Grice HP. Logic and conversation. In: Cole P, Morgan JL, eds. Syntax and Semantics, Speech Acts. New York: Academic Press; 1975;3.
24. Taylor JM, Raskin V, Hempelmann CF, Attardo S. An unintentional inference amd ontological property defaults. IEEE SMC 2010.
25. Raghavan S, Mooney RJ, Ku H. Learning to “read between the lines” using Bayesian logic programs. ACL 2012.
26. Raskin V. Semantic mechanisms of humor Dordrecht: Reidel; 1985.
27. Taylor JM, Raskin V. Fuzzy ontology for natural language Toronto, Ont, Canada: NAFIPS 2010; 2010.
28. Bonk T. Underdetermination: An essay on evidence and the limits of natural knowledge. Bost Stud Phil Sc Dordrecht: Springer; 1981; p. 261.
29. Quine WVO. Word and object Cambridge, MA: MIT Press; 1960.
30. Schank R, Abelson R. Scripts, plans, goals, and understanding.Hillsdale, NJ: Erlbaum.
31. Raskin V, Nirenburg S, Hempelmann CF, Nirenburg I, Triezenberg KE. The genesis of a script for bankruptcy in ontological semantics. Hirst G, Nirenburg S, editors. Proceedings of the Workshop on Text Meaning, NAACL-HLT; 2003. p. 27–31.