
Intelligent Banking XML Encryption Using Effective Fuzzy Logic
Faisal T. Ammari1, J. Lu1 and Maher Aburrous2, 1University of Huddersfield, Huddersfield, UK, 2Al Hoson University, Abu Dhabi, UAE
In this chapter we present a novel approach for securing financial XML transactions using an effective and intelligent fuzzy classification technique. Our approach defines the process of classifying XML content using a set of fuzzy variables. Upon fuzzy classification phase, a unique value is assigned to a defined attribute named "ImportanceLevel." Assigned value indicates the data sensitivity for each XML tag. The model also defines the process of securing classified financial XML message content by performing element-wise XML encryption on selected parts defined in fuzzy classification phase. Element-wise encryption is performed using symmetric encryption using AES algorithm with different key sizes. A key size of 128-bit is being used on tags classified with "Medium" importance level; a key size of 256-bit is being used on tags classified with "High" importance level. An implementation has been performed on a real-life environment using an online banking system to demonstrate system efficiency. Our experimental results verified tangible enhancements in encryption efficiency, processing-time reduction, and resulting XML message sizes.
Keywords
XML encryption; fuzzy XML; fuzzy classification; XML security; banking security
Information in this chapter
Introduction
The eXtensible Markup Language (XML) [1] has been widely adopted in many financial institutions in their daily transactions; this adoption was due to the flexible nature of XML providing a common syntax for systems messaging in general and in financial messaging in particular [2]. Excessive use of XML in financial transactions messaging created an aligned interest in security protocols integrated into XML solutions in order to protect exchanged XML messages in an efficient yet powerful mechanism. There are several approaches proposed by researchers to secure XML messages.
Many models have been proposed to protect exchanged messages both on the network level [3,4] and on the XML level. Among the proposed models, W3C played a major role, providing standardized forms to represent XML data in a secure and trusted method. W3C introduced XML Encryption [5], XML Signature [6], and XML Key Management [7].
The XML Encryption standard defines how to encrypt the XML message. This can involve fully encrypting the entire message, partially encrypting it by selecting parts of each message, or even encrypting external elements attached to the message itself. Although this model is able to secure XML messages, some issues arose concerning performance and inefficient memory usage [8,9], leaving room for more improvements and enhancements.
However, financial institutions (i.e., banks) perform large volume of transactions on a daily basis that require XML encryption on a large scale. Encrypting a large volume of messages in full will result in performance and resource issues. Therefore, an approach is needed to encrypt specified portions of an XML document, syntax for representing encrypted parts, and processing rules for decrypting them. W3C XML encryption has a feature to encrypt parts of an XML document called element-wise encryption, which is the process of encrypting parts of the XML document. To avoid any performance or resources issues, a mechanism should be considered to choose which parts of the XML document are to be encrypted on the fly, whereby those parts are selected upon intelligent criteria detecting sensitive information within the XML document.
The Fuzzy Logic (FL) [10] approach can be used here to distinguish sensitive parts within each XML document. FL provides a simple way to arrive at a definite conclusion based upon vague, ambiguous, imprecise, noisy, or missing input information. FL’s approach to control problems mimics how a person would make a faster decision. FL incorporates a simple, rule-based “If X and Y then Z” approach to solving a control problem, rather than attempting to model a system mathematically. The FL model is empirically-based, relying on an operator’s experience rather than on technical understanding of the system.
The fuzzy logic approach is quantified based on a combination of historical data and expert input. Fuzzy logic has been used for decades in the computer sciences to embed expert input into computer models for a broad range of applications. The advantage of the fuzzy approach is that it enables processing of vaguely defined variables and variables whose relationships cannot be defined by mathematical relationships. Fuzzy logic can incorporate expert human judgment to define those variables and their relationships. The model can be closer to reality and be more site specific than some of the other methods [11].
Literature review
Flexibility, expressiveness, and usability of XML have formed a motive for researchers to shed more light on XML security. Researchers have focused their interests on securing XML data due to the increased usage of XML in many business and educational cases. Efficient models have been proposed [3–7,12] to add a secure layer over exchanged XML data. The models’ main purpose is to ensure data confidentiality and authenticity. Many XML threats [8] have been considered, such as Oversized Payload, Schema Change, XML Routing, and Recursive Payload. Such threats have forced researchers to pay more attention to securing exchanged XML messages.
W3C XML Encryption Working Group [5] is developing a method for XML encryption and decryption. The group used XML syntax to represent the secured elements in XML. Their approach is able to encrypt the whole message, full nodes, and sub-trees; however, it is not able to encrypt an element while keeping the descendants of the same node unchanged, and also it cannot handle attribute encryption. Therefore, a solution has been proposed [9] to handle this limitation. Ed Simon proposed changing the attribute so that it is encrypted with the EncryptedDataManifest attribute and includes any other details inside the element. Another solution proposed was to use XSLT for attribute transformation into elements to perform the encryption process. However, this suggested solution was not successful, as the decrypted parts need to be transformed back to the original attributes for message validation against the corresponding XML schema.
A system has been proposed by [13] for pool encryption, which has the capability of removing sensitive information from the output file. Their basic idea is to parse the XML message that needs encryption into a DOM tree, where each node in the tree is labeled and all information related to its position is attached to the corresponding node. Then each node is encrypted individually with a node-specific encryption key. These nodes are removed from their original position in the XML message into a pool that contains all other encrypted nodes. The pool can be saved into the original message or in a different message. The sender determines the decryption capabilities of different users by distributing the collection of node keys to the receiver. This collection of node keys is encrypted with the recipients’ key before final submission. Although this model solves the issue of removing confidential material from the main message and hides the size of the encrypted content, it has the following disadvantages: (1) The original position for each individual node needs to be attached, due to the addition of "the position information," (2) a decent increase in message size is noticed, due to the pool of node keys, (3) a decent increase in message size is noticed, (4) there is high resource usage and bandwidth allocation, (5) more storage and more processing power is needed, and (6) a unique node key has to be generated for each node.
The authors of [14] introduced an XML access control (XAC) that is a server-side access control, and a trusted access control processor, allowing security policies and procedures to be established. Based on the policies, XAC presents a way to control access of users to specific portions of the full XML document that is stored on a server. XAC encrypts an XML element with the ability to exclude its descendants. This specific feature gives the advantage of XAC over XEnc because XEnc requires the encryption of a full sub-tree.
The authors of [15] presented an approach to incorporate fuzziness in XML. Their approach tried to identify the potential entities in XML that can have fuzzy values. They analyze the structure of an XML document to identify the portions that can be handled using fuzziness; then they specify the appropriate mechanism to incorporate fuzziness. Their approach focused on XML being structured (logical and physical) and well-formed language.
The authors of [16] introduced a fuzzy XML data model to manage fuzzy data in XML, based on possibility distribution theory, by first identifying multiple granularity of data fuzziness in UML and XML. The fuzzy UML data model and fuzzy XML data model that address all types of fuzziness are developed. Further, they developed the formal conversions from the fuzzy UML model to the fuzzy XML model, and the formal mapping from the fuzzy XML model to the fuzzy relational databases.
The authors of [17] presented an XML methodology to represent fuzzy systems for facilitating collaborations in fuzzy applications and design. DTD and XML Schema are proposed to define fuzzy systems in general. One fuzzy system can be represented in different formats understood by different applications using the concept of XSLT stylesheets. With an example, they represent that given fuzzy system in XML and transform it to comprehensible formats for Matlab and FuzzyJess applications.
The authors of [18] proposed an approach along with an automated tool called FXML2FOnto for constructing fuzzy ontologies from fuzzy XML models. They also investigated how the constructive fuzzy ontologies may be useful for improving some of the fuzzy XML applications (i.e., reasoning on fuzzy XML models).
System model and design
Our model consists of two major parts. Each part has a discrete scope that acts as an independent unit and forms an essential part of the whole system. Content is classified using a set of fuzzy classification techniques [19] and encrypted using an element-wise encryption on selected parts within each XML message. The fuzzification phase is performed before the XML messages are submitted to the next phase, which is responsible for securing message content. The process of fuzzy classification is mainly responsible for defining an attribute value and assigning it to an existing XML tag named "ImportanceLevel." The assigned value is used to define the security level needed in the next phase. The next phase involves applying element-wise encryption to different parts within each XML message. Encryption could be for the whole message or elements of an XML message. The “Importance Level” value assigned in the fuzzification phase is also used to decide which type of encryption and key size is to be deployed. Element-wise encryption is based on W3C’s recommendation [5]. Figure 37.1 illustrates the system model and basic components used to form our model.
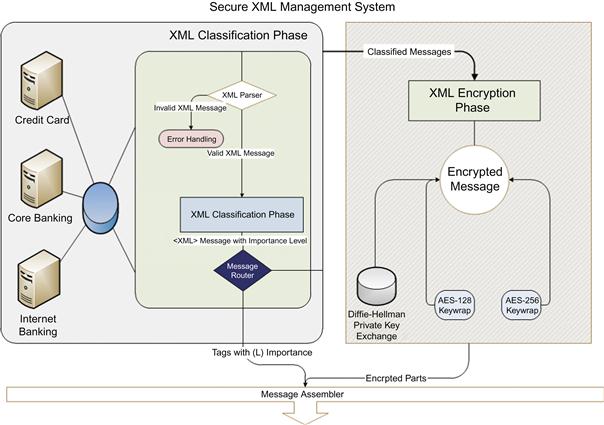
As seen in the figure, the main two components are displayed as two separate units; each act as an independent unit performing a set of operations that is used as input to the other phase.
The system core has been built based on two major phases. Phase one involves performing a set of fuzzy classification techniques on XML messages. The fuzzy classification process is designed mainly for determining the similarity of different standards within the same message. Basically, the main target is to describe how semantic concepts are evaluated and explained by the provided XML content. Upon fuzzy classification, a new value is generated and assigned to an existing XML tag.
We assigned the name “ImportanceLevel” to the mentioned tag so we can use it as an identifier for the next phase. Phase two involves applying element-wise encryption to different parts within each XML message. Encryption could be for the whole message, some elements, or some attributes of an element of an XML message. The ImportanceLevel value assigned in phase one is used to decide which type of encryption is performed; it also decides which parts of the XML message are to be encrypted. We base our encryption on W3C’s recommendation [5]. The following stages form the system life cycle in detail.
Fuzzy classification phase
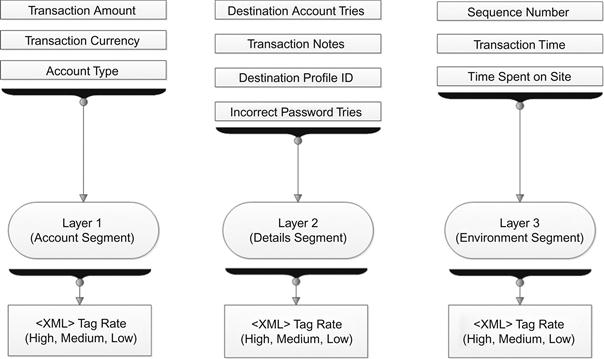
In our fuzzy classification phase, we categorized 10 transaction characteristics into three different layers according to their type. The characteristics were chosen after exploring different experts’ opinions and backgrounds, reviewing financial analysis tools, reviewing technical reports, researching different online and offline financial systems conducted within the financial institution, and performing a set of internal surveys among banking group heads. We categorized these 10 transaction characteristics extracted from the XML message into three layers (Account Segment, Details Segment, and Environment Segment). Grouping will facilitate and simplify the process of fuzzy classification.
This phase is responsible for assigning a new value, which is the importance level for each XML tag. The main idea is to distinguish which parts of the message are to be encrypted using an AES-128-bit key encryption, and which are to be encrypted using an AES-256-bit key. Usage of the key depends on the importance level value (high, medium or low), whereby we deploy the 128-bit key on tags with “Medium” importance level and the 256-bit key on tags with a "High" importance level value. Tags with a “Low” importance level value are forwarded directly to the message assembler, where no encryption is performed. The phase uses fuzzification techniques of a set of input variables based on 10 characteristics extracted from the XML message, all depending on the previous knowledge, experience, and expertise backgrounds. The 10 characteristics are defined in detail as follows:
1. Transaction amount: Financial institutions set pre-defined transaction limits. The limits allow users to perform transactions with specified limits on a daily basis. The range of transaction limits is defined based on the local policy within each institution. Banks normally treat the transaction amount as an alert to any critical transaction; the amount is used in most banks to measure the weight of total transaction performed. Source, destination, and amount all combine to act as an alert that is already pre-defined based on the bank’s policy. Large transaction amounts will affect the importance of the transaction itself, which can be used in our model as a measurement item in our importance level evaluation.
2. Transaction currency: We use a well-defined list of allowed currencies that can be used online or offline. Each currency has its own set of risk variables, depending on usage and importance. Foreign currency uses exchange rates, operational interference, and market value for the transaction the moment it occurred. Banks treat each FX transaction with high importance, because it involves buying and selling with the bank’s rate. We have used this factor in our importance evaluation
3. Account type: Accounts are segmented within each institution. Segmentation is performed to enable the application of a set of internal rules on selected segments. Each segment has its own value and weight; for example, corporate account segments are listed with high importance and priority because most of the transactions are large volume, which can benefit the bank for each transaction. We used this factor due to its role in deciding the importance level for the whole transaction.
4. Transaction notes: Exceptions are placed on unusual activity on a specific account, and such exceptions will raise a flag in any transaction being processed to handle the exception before the process is completed. Having a flagged transaction will raise the importance level and trigger an alert to monitor that specific transaction due to its importance; we have used this factor to measure the importance level in term of transaction critical weight.
5. Profile ID: This is a unique identifier for the destination account owner; the value is set during the system integration and profile creation process. Companies or individuals with custom profile IDs have a high potential to be monitored for transactions. Monitoring is based on the transaction amount after classifying each profile ID, whereby a range of IDs are listed in the high importance zone, all after deploying a bank’s methods and procedures.
6. Account tries: This refers to how many times the account is used in the system; more usage means more trust, whereby the history of the account is known and trusted. A historical log is kept and evaluated on a regular basis to confirm trusted accounts and suspicious ones. Evaluation will result in a set of important ranges of trusted accounts to be used in a transaction evaluation and setting an importance level.
7. Incorrect password tries: This is the number of times a user enters the password incorrectly to try to complete the financial transaction. This factor adds a slight importance level for each transaction; a high rate of incorrect tries gives an indication of high importance.
8. Time spent on the service: This refers to the time spent navigating the service before performing a transaction. The time range is set based on the bank’s policy, taking into consideration peak hours. This factor is considered a technical factor to measure the importance level of the transaction based on non-financial elements.
9. Daily transactions: this refers to how many transactions are performed before the financial transaction is carried out. The number of daily transactions puts a weight on the overall importance level for the transaction itself, whereby the number of transactions to be performed is set based on the bank’s policy within the allowed ranges.
10. Transaction time: The financial day is categorized into three periods: peak period, normal hours, and dead zone. Periods are defined by the financial institution based on local policy and historical transaction periods. Each period has its own value, which adds an importance level, and how the occurrence of any transaction is affected by the time of occurrence. Ranges are set to weigh an importance level when the transaction is performed.
Fuzzy methodology
Our fuzzy classification phase is based on Mamdani [19] fuzzy inference and performs the four basic steps shown in Figure 37.2.
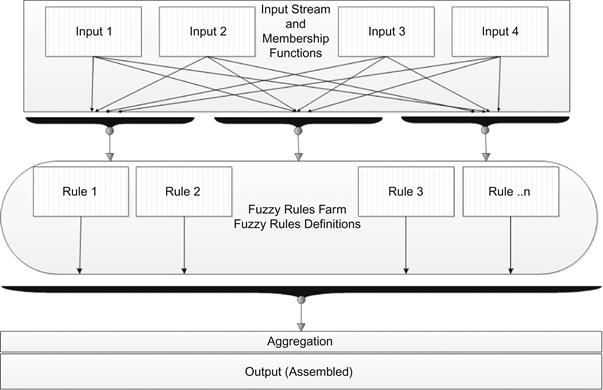
Step 1 (Fuzzification): Take the crisp input X and input Y and determine the degree to which these inputs belong to, and where they fit into, the fuzzy set. Figure 37.3 illustrates an example of a linguistic variable used to represent one factor, which is the transaction currency. The x-axis represents the range of the transaction amount. The y-axis represents the degree of each value in the linguistic descriptor.
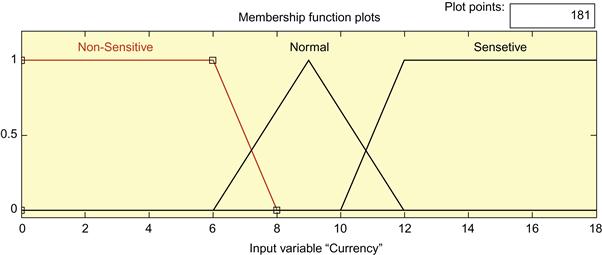
Transaction Currency (Non-Sensitive, Normal, Sensitive)
Variable used: Transaction amount
Step 2 (Rule evaluation): Take the fuzzy inputs and apply them to the qualified fuzzy rules. The fuzzy operators (AND/OR) are used in case of any uncertainty to get a single value. The outcome value is called the “Truth Value,” which will be applied to the membership function for rule evaluation.
Step 3 (Aggregation of the rule outputs): Process of unification of the outputs of all the rules. Combining scaled rules into a single fuzzy set for each variable.
Step 4 (Transforming the fuzzy output into a crisp output): Figure 37.4 illustrates an example of an expected crisp output [Low, Medium, and High].
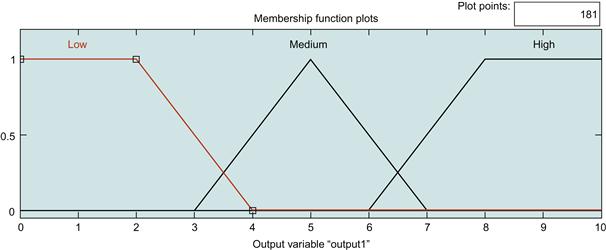
The output should have a clear, crisp value where it will be assigned to each tag classified.
Low: This tag means the importance level is low and less attention should be paid to the value. The root element and child tags should be forwarded directly to the message assembler, skipping the encryption phase.
Medium: This tag is important to some extent, and the tag attribute is assigned the value of medium, so an element-wise encryption will be applied using the AES algorithm with a 128-bit key on selected parts.
High: This tag is to be handled with high importance and encrypted in the next phase using the AES algorithm with a 256-bit key.
Detection module
To perform the fuzzy inference system, we have categorized the XML tags within each message into 10 characteristics distributed into three layers, each with its own weight and criteria. The layers are account layer, details layer, and environment layer. Figure 37.5 represents the layers distribution.
After giving a weight to each layer, the calculation of overall weight is based on the following criteria:
![]()
Rule Base: Each layer has a set of rules defined, based on input variables within each layer. The rule is based on the “if-then” rule. The rule base should contain a number of entries depending on how many layer members exist. For example, layer 1 has three members and we have three outputs expected, so the entries should be calculated as (33)=27 entries presenting the rules for that layer. The final evaluation is dependent on finding the center of gravity, as shown in Equation 1.
![]() (1)
(1)
µi(x): Aggregated membership function.
x: Output variable.
After deploying the fuzzy classification methodology on the three layers, we then have a list of classified tags with an importance level attribute defined and assigned.
Encryption module
The encryption phase has two possibilities: the first one is to perform an element-wise encryption using the AES algorithm with a 256-bit key size, while the second is to perform an element-wise encryption using the AES algorithm with a 128-bit key size. Key size is determined by the importance level value assigned in the fuzzy classification phase. Figure 37.6 illustrates the process of encryption. Tags with “Low” importance level will be forwarded directly to the message composition stage without any type of encryption being performed.
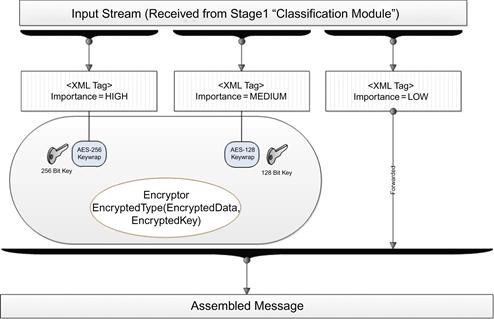
Tags related to the parent tag are also encrypted using the same level of encryption. Child tags behavior is taken from the parent "ImportanceLevel" value. Figure 37.7 illustrates the XML message after the fuzzy classification phase, where the “ImportanceLevel” attribute is assigned a value.

Figure 37.8 illustrates the same XML message after encryption, depending on the fuzzy classification performed earlier.
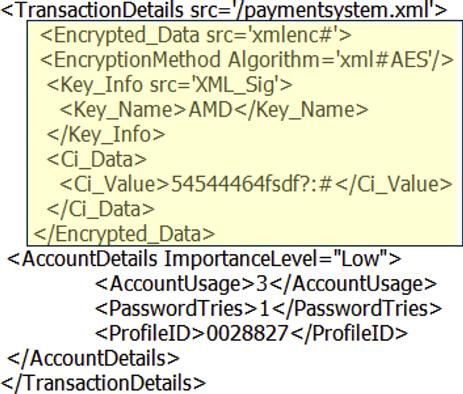
Tags related to the parent tag are also encrypted using the same level of encryption. Child tags behavior is taken from the parent "ImportanceLevel" value. In Figure 37.7, Account Holder, Account Number, Amount, Currency, and Type tags are encrypted using AES encryption with a 256-bit key size, as per their parent "Account" layer. Basically, we inherit the encryption behavior from parent to child as per our categorization process, and the categorization process in our model is built based on relevance and parent tag evaluation.
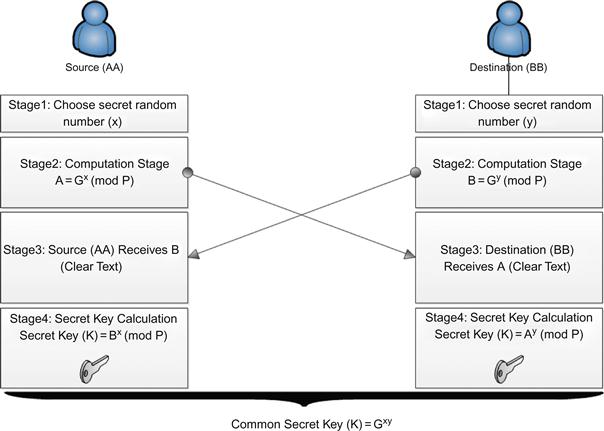
Keys used during the encryption process should be transferred to the decryptor in the destination using a secure and private method. We use Diffie-Hellman [20] key exchange for the handover of keys between source and destination. Figure 37.9 illustrates how to exchange keys between source and destination.
Experiments and results
We have performed our evaluation using two sets of XML messages; each set represents a period in which the messages were extracted. Each set has a number of XML messages to test. Collected XML messages present online banking service transactions fetched from Jordan Ahli Bank, one of the leading banks in Jordan. We have selected to deploy full and partial encryption on selected sets of XML messages, whereby we will deploy full encryption on the first set of XML messages and partial encryption on the second set of XML messages.
The two sets have been selected randomly, taken over a period of seven months (between January, 2012 and August, 2012), and specifically representing financial transactions. In the first set, we collected 1,000 random XML messages taken over a period of three months (between January, 2012 and March, 2012). In the second set we used 1,500 XML messages taken over a period of four months (between April, 2012 and August, 2012). Sample sets were collected after receiving the necessary approvals and authorizations from the bank’s concerned departments. Table 37.1 illustrates the two sets of XML messages in detail.

Figure 37.10 illustrates an actual XML message fetched from one of the XML messages in set 1.
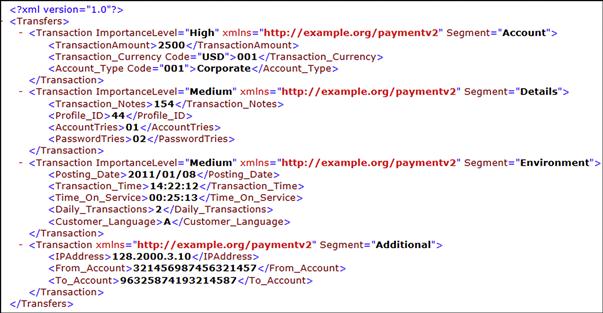
Table 37.2, Table 37.3, and Table 37.4 illustrate a sample of the data provided in set 1, segregated into three layers.



To ensure that we are evaluating our model in a fair and comprehensive manner, we divided our evaluation into two stages. Evaluation stages are compared against W3C XML encryption recommendations. In each stage, there are two experiments performed; each experiment presents an encryption using different key sizes. In the first stage, we have deployed full message encryption using W3C encryption standard with different key sizes. In the second stage, we have deployed partial encryption using W3C encryption standard with different key sizes.
Results from both stages are compared against our model, which uses element-wise encryption and a mixture of key sizes. Table 37.5 illustrates the evaluation details for Stage 1.

Stage 1: The evaluation for this stage has been conducted by performing two experiments; the first experiment was deployed by performing full encryption using the W3C XML encryption standard with a 128-bit key size deployed on the first set of 1,000 XML messages. SXMS uses the same sample of XML messages to deploy element-wise encryption. The SXMS model uses symmetric AES encryption with mixed key values (128-bit, 256-bit). Key size used in the encryption process depends on the importance level attribute value assigned by the fuzzification stage for a selected set of tags within each XML message. Our model’s main goal is to optimize and increase encryption-processing time; therefore, we have listed the number of occurrences for “High” and “Medium” importance levels, which require an encryption process to secure existing content. Table 37.6 represents the number of occurrences for transactions marked “High” and “Medium” across the three layers.

As seen in Table 37.6, the highest occurrences for “High” and “Medium” importance levels combined is 32.9 percent in layer 1, which means only 32.9 percent of the 1,000 XML messages require an encryption processing using either a 128-bit key or a 256-bit key, leaving 67.1 percent of the sample data to be forwarded directly to the message assembler without the need of the encryption process. In brief, instead of performing full encryption for the whole XML message, or even performing partial encryption on pre-selected parts, we were able to produce secured, optimized, and utilized messages, performing encryption only on needed parts selected using our fuzzy classification techniques. Figure 37.11 shows an actual XML message after the fuzzy classification phase, where we notice the importance level value assigned per root node in each XML message.
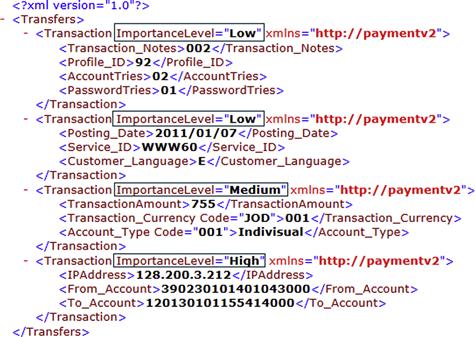
Table 37.7 illustrates the time needed and the resulting file size to encrypt the XML message set using our model compared against the W3C XML encryption model using a 128-bit key size and encrypting each message in full.

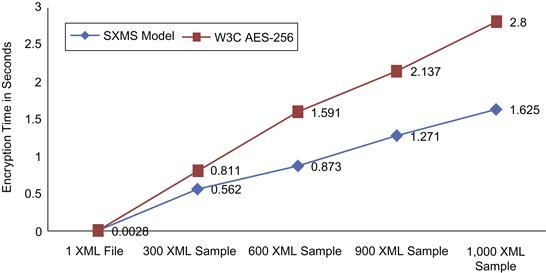
We have encrypted the XML messages in chunks of 1, 300, 600, 900, and 1,000 messages. Our SXMS model processed the XML chunks with a measurable improvement in processing time compared to the W3C XML encryption model, which uses a 128-bit key size to encrypt the whole XML message. SXMS uses a 128-bit key in the cases where the importance level attribute value equals “Medium” and a 256-bit key is used when the importance level attribute value equals “High.” As seen in Table 37.7, the encryption process for all 1,000 XML messages using the W3C encryption standard with a 128-bit key size took 2.456 seconds to complete, compared to 1.625 seconds using the SXMS model. The result reflects a 33.8 percent improvement in processing time for the 1,000 messages. Figure 37.12 illustrates the comparison between the two models and performance improvement using SXMS.
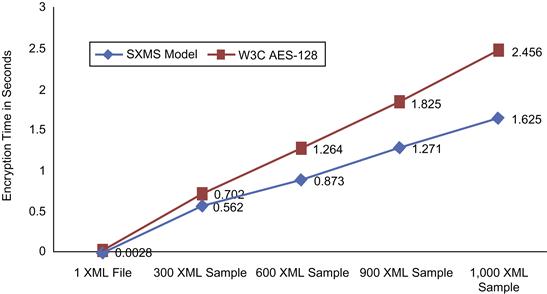
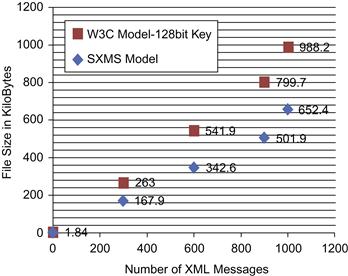
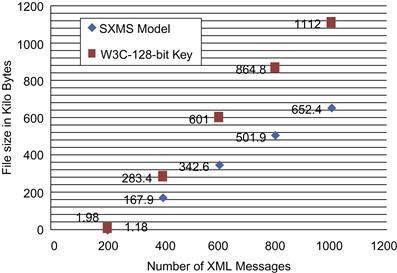
Table 37.7 also illustrates file size reduction by encrypting XML messages using the SXMS model. The table shows a measurable reduction in file size, whereby the total size of the 1,000 encrypted XML messages was 988 KB using the W3C model with a 128-bit key size and encrypting each XML message in full. SXMS achieved smaller sizes for the same set of 1,000 encrypted XML messages, which is 652.4 KB, showing a size reduction of 34 percent from the encrypted file size using the W3C model. Such improvement can save a measurable amount of space and bandwidth on a large scale. Figure 37.12 illustrates the processing time needed to encrypt the sample messages in the first experiment compared to our model.
As seen in Figure 37.12, the x-axis represents the number of XML messages being processed, while the y-axis represents the processing time in seconds to encrypt the XML messages. Figure 37.13 shows the file size comparison for the encrypted XML messages using SXMS and W3C XML encryption syntax and processing model using a 128-bit key size and performing full message encryption.
The second experiment has been conducted performing full encryption using the W3C XML encryption standard with a 256-bit key deployed on the same 1,000 sample XML messages. SXMS uses the same sample of XML messages to deploy element-wise encryption. Later we compare results for both experiments against results from our model. Table 37.8 illustrates the time needed and the resulting file size to encrypt the XML message set using our model compared against the W3C XML encryption model using a 256-bit key size and encrypting each message in full.

We have encrypted the XML messages in chunks of 1, 300, 600, 900, and 1,000 messages. Our SXMS model processed the XML chunks with a measurable improvement in processing time compared to the W3C XML encryption model, which uses a 256-bit key size to encrypt the whole XML message. SXMS uses a 128-bit key in the cases where the importance level attribute value equals “Medium” and a 256-bit key is used when the importance level attribute value equals “High.”
In the second experiment of Stage 1, we deployed the W3C encryption standard to fully encrypt the same sample of 1,000 XML messages, but this time using a 256-bit key size. SXMS used the same sample of XML messages to deploy element-wise encryption. The SXMS model uses symmetric AES encryption with mixed key values (128-bit, 256-bit). Key size used in the encryption process depends on the importance level attribute value assigned by the fuzzification stage for a selected set of tags within each XML message. Table 37.8 represents the time needed for each model performing the encryption process on the selected sample of messages.
As seen in Table 37.8, the encryption process for the whole message using the W3C encryption standard with a 256-bit key size took 2.8 seconds to complete, compared to 1.625 seconds using the SXMS model. The result reflects a 41.9 percent improvement in processing time for the 1,000 messages.
Table 37.8 also illustrates the file size reduction encrypting XML messages using the SXMS model The table shows a measurable reduction in file size, whereby the total size of the encrypted 1,000 XML messages was 1112 KB using the W3C model with a 256-bit and encrypting each XML message in full. SXMS achieved smaller sizes for the same set of 1,000 encrypted XML messages, which is 652.4 KB, showing a size reduction of 41.3 percent from the encrypted file size using the W3C model. Such an improvement can save a measurable amount of space and bandwidth on a large scale. Figure 37.14 illustrates the performance comparison between the SXMS model and the W3C encryption standard using a 256-bit key size. Figure 37.15 shows a file size comparison for the encrypted XML messages using SXMS and the W3C XML encryption syntax and processing model, using a 256-bit key size.
Finally, Figures 37.16 and 37.17 illustrate the final performance and file size reduction comparison between SXMS and the W3C model for both experiments, which uses a 128-bit key and a 256-bit key, performing full encrypting for each XML message in the first message set. Figure 37.16 presents a measurable amount of performance improvement using the SXMS model.
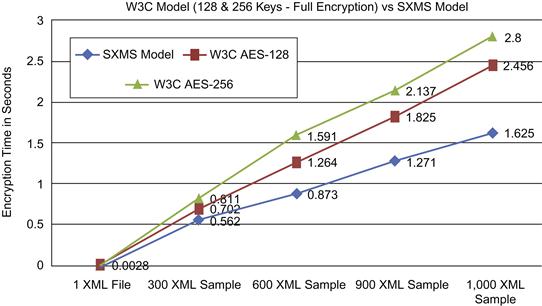
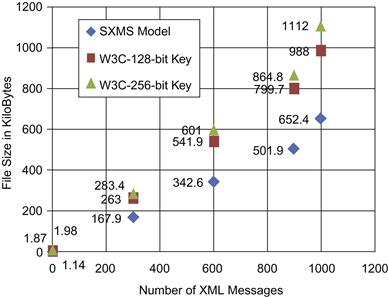
Figure 37.18 shows a file size comparison for the encrypted XML messages using SXMS and the W3C XML encryption syntax and processing model using a 128-bit key size performing partial message encryption.
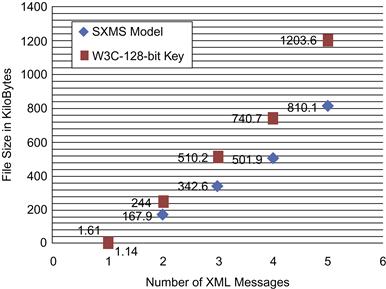
In the second experiment of Stage 2, we deployed the W3C encryption standard to partially encrypt the XML messages to a sample of 1,500 XML messages, but this time using a 256-bit key size. SXMS used the same sample of XML messages to deploy element-wise encryption. The SXMS model uses symmetric AES encryption with mixed key values (128-bit, 256-bit). Key size used in the encryption process depends on the importance level attribute value assigned by the fuzzification stage for a selected set of tags within each XML message. Table 37.9 represents the time needed for each model performing the encryption process on the selected sample of messages.
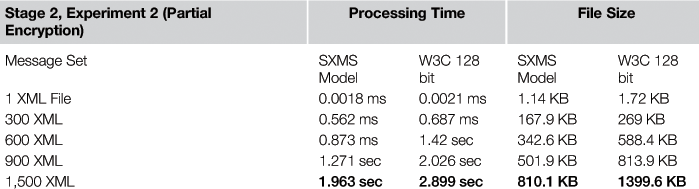
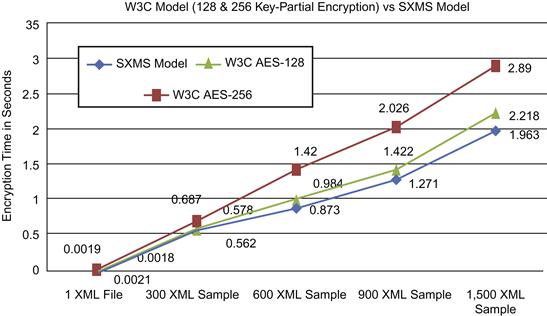
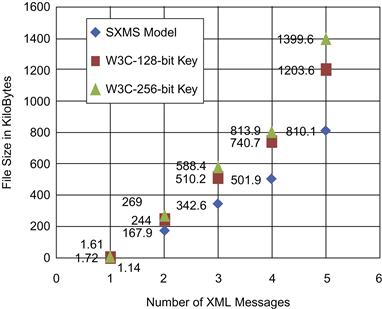
As seen in Table 37.9, the encryption process for part of the message using the W3C encryption standard with a 256-bit key size took 2.899 seconds to complete, compared to 1.963 seconds using the SXMS model. The result reflects a 32.2 percent improvement in processing time for the 1,500 messages. Table 37.9 also illustrates file size reduction encrypting XML messages using the SXMS model. The table shows a measurable reduction in file size, whereby the total size of the 1,500 encrypted XML messages was 1399.6 KB using the W3C model with a 256-bit key size and encrypting parts of the XML message. SXMS achieved smaller sizes for the same set of 1,500 encrypted XML messages—810.1 KB—showing a size reduction of 42.1 percent from the encrypted file size using the W3C model. Such improvement can save a measurable amount of space and bandwidth on a large scale.
Figure 37.19 illustrates the comparison between the SXMS model and the W3C encryption standard using a 256-bit key size and encrypting parts of the XML message for the second sample set.
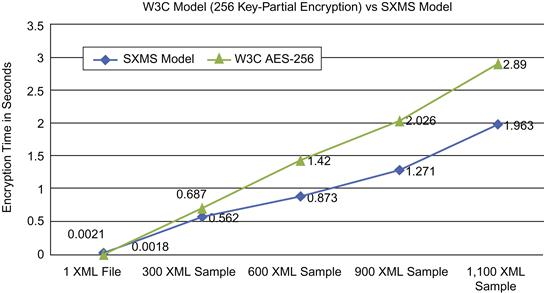
Figure 37.20 shows a file size comparison for the encrypted XML messages using SXMS and the W3C XML encryption syntax and processing model using a 256-bit key size and performing partial message encryption.
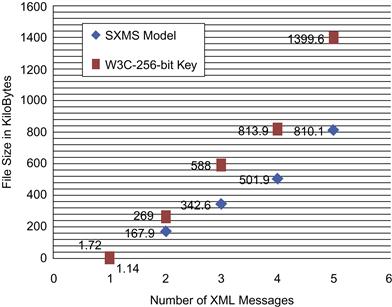
Finally, Figure 37.21 and Figure 37.22 illustrate performance improvements and a file size reduction comparison between the SXMS model and the W3C model for both experiments in Stage 2, showing a measurable performance improvement and size reduction on a large scale using the SXMS model.
Summary
In this chapter, a novel approach for securing financial XML messages using intelligent mining fuzzy classification techniques has been proposed.
Mining fuzzy classification techniques have been used to evaluate and measure the data sensitivity level within each XML message to find a degree of sensitivity for each tag in the message. The mining fuzzy classification process allowed us to assign a value to a new attribute added to the parent XML nodes. A value is determined by applying a set of classification processes based on Mamdani inference. A new value has been used to determine which type of encryption algorithm is being performed on selected tags, allowing us to secure only the needed parts within each message, rather than encrypting the whole message. XML encryption is based on the W3C XML recommendation. Nodes that are assigned an importance level value of “High” are encrypted using the AES encryption algorithm with a 256-bit key size to ensure that maximum security is performed. Nodes that are assigned an importance level value of “Medium” are encrypted using the AES encryption algorithm with a 128-bit key size. An implementation was performed on a real-life environment, using online banking systems to demonstrate the model’s flexibility, feasibility, and functionality. Our experimental results with the new model verified tangible enhancements in encryption efficiency, processing time reduction, and financial XML message utilization.
Each unit in our SXMS model acts independently as a separate system. Taking into consideration such a flexible nature allows for and motivates future work and enhancements. The following points describe the future work on each unit within our SXMS model:
• Fuzzy classification phase: We can utilize supervised machine learning techniques to automate the fuzzy rule generation process in order to reduce the human expert knowledge intervention and increase performance of the phishing detection system. This can be achieved by generating classification rules using well-known classifiers. For example, we can use: PRISM [21], C4.5 Decision Tree [22], Ripper [23], k-nearest neighbor classification (kNN) [24], naïve Bayes classification [25], linear least squares fit mapping [26], and the vector space method [27]. These mining association classification rules can be combined with a fuzzy logic inference engine to provide efficient and competent techniques for importance level extraction.
• Encryption phase: We can utilize a different encryption scheme; asymmetric algorithms can be deployed. We have deployed symmetric encryption due to the efficiency and processing time outperforming asymmetric encryption algorithms. We can even change the symmetric encryption algorithm to something else, like DES, triple DES, or Blowfish. Researchers will be able to test and measure performance for any replaced encryption algorithm. Also, usage of the encryption keys can be change to reflect a different key size for each importance level assigned. For example, we can assign an encryption key of 192 bits instead of 256 bits for the importance level “High” value.
• We can create multiple instances of SXMS whereby it handles XML messages based on a load balancer designed to distribute XML messages on multiple SXMS instances. By performing this distribution, processing speed will be boosted by two times or even more, depending on the new instances created and used. However, such initiative might be a high cost on the resources used.
References
1. Bray T, Paoli J, Sperberg-McQueen CM. Extensible markup language (XML). 1.0. W3C; 1998.
2. Fan M, Stallaert J, Whinston AB. The Internet and the future of financial markets. Commun ACM. 2000;43(11):83–88.
3. Organization for the Advancement of Structured Information Standards (OASIS). Extensible access control markup language (XACML) V2.0; 2005.
4. ContentGuard. XrML: The digital rights language for trusted content and services. [Internet]. Available at: <http://www.xrml.org/>; 2001.
5. XML encryption syntax and processing (W3C Recommendation); 2003.
6. XML-signature syntax and processing (W3C/IETF Recommendation); 2002.
7. XML key management specification (XKMS 2.0). [Internet]. Available at: <http://www.w3.org/TR/2005/PR-xkms2-20050502/>; 2005.
8. Juric M, Sarang P, Loganathan R, Jennings F. SOA approach to integration. Packt Publising; 2007.
9. Simon E. XML encryption: Issues regarding attribute values and referenced. External Data. W3C XML-Encryption Minutes; Session 3. Boston, MA; 2000.
10. Zadeh LA. Fuzzy sets, information and control; 1965.
11. Mahant N. Risk assessment is fuzzy business – Fuzzy logic provides the way to assess off-site risk from industrial installations Australia: Bechtel; 2004.
12. Oasis security services (saml) tc. [Internet]. Available at:< http://www.oasis-open.org/committees/security/>.
13. Geuer-Pollmann C. XML pool encryption. ACMWorkshop on XML Security. University of Siegen; Institute for Data Communications Systems; 2002.
14. Rosario R. Secure XML an overview of XML encryption; 2001.
15. Gaurav A, Alhajj R. Incorporating fuzziness in XML and mapping fuzzy relational data into fuzzy XML. Proceedings of the 2006 ACM Symposium on Applied computing. Dijon, France; 2006.
16. Ma Z, Fuzzy XML. data modeling with the UML and relational data models. Data & Knowledge Engineering. 2007;63:972–996.
17. Tseng C. Universal fuzzy system representation with XML. Computer Standards and Interfaces. 2005;28:218–230.
18. Fu Zhang ZM, Ma LY. Construction of fuzzy ontologies from fuzzy XML models. Knowledge-Based Systems: 2013;42:20-39. ISSN 0950-7051. Avaiable from http://dx.doi.org/10.1016/j.knosys.2012.12.015.
19. Liu M, Chen D, Wu C. The continuity of Mamdani method. International Conference on Machine Learning and Cybernetics. 2002;3:1680–1682.
20. Diffie W, Hellman ME. New directions in cryptography. IEEE Trans on Information Theory IT-22. 1976;6:644–654.
21. Cendrowska J. PRISM: an algorithm for inducing modular rules. Int J Man Mach Stud. 1987;27(4):349–370.
22. Quinlan J. Improved use of continuous attributes in c4.5. Journal of Artificial Intelligence Research. 1996;4(1):77–90.
23. Cohen W. Fast effective rule induction. Proceedings of the twelveth International Conference on Machine Learning. CA, USA; 1995. p. 115–23.
24. Guo G, Wang H, Bell D, Bi Y, Greer Y. Using kNN model for automatic text categorization. Journal of Soft Computing Verlag Heidelberg: Springer; 2004.
25. McCallum A, Nigam KA. Comparison of event models for naive bayes text classification. AAAI-98 Workshop on Learning for Text Categorization; Madison, WI 1998;41–48.
26. Yang Y, Chute CG. An application of least squares fit mapping to text information retrieval. In: Proceedings of the ACM SIGIR. Pittsburgh, PA; 1993. p. 281–90. 163.
27. Gauch S, Madrid JM, Induri S, Ravindran D, Chadlavada S. KeyConcept: A conceptual search engine. Information and Telecommunication Technology Center; Technical Report: ITTC-FY2004-TR-8646-37. University of Kansas.
Further Reading
1. Shirasuna S, Slominski A, Fang L, Gannon D. Performance comparison of security mechanisms for grid services. Fifth IEEE/ACM International Workshop on Grid Computing IEEE Computer Society 2004; p. 360–4.
2. Park N, Kim H, Chung K, Sohn S, Won D. XML-Signcryption based LBS security protocol acceleration methods in mobile distributed computing. Computational Science and Its Applications; ICCSA 2006 Berlin/Heidelberg: Springer; 2006; 3984:251–9.
3. Imamura, T, Clark, A, Maruyama, H. A stream-based implementation of XML encryption. In: XMLSEC 2002: Proceedings of the 2002 ACM Workshop on XML security. ACM Press; 2002. p. 11–17.
4. Hwang G-H, Chang T-K. An operational model and language support for securing XML documents. Computers & Security. 2004;23(6):498–529.