
Security through Emulation-Based Processor Diversification
Héctor Marco, Ismael Ripoll, David de Andrés and Juan Carlos Ruiz, Universitat Politècnica de València, Valencia, Spain
Memory errors, such as stack and integer vulnerabilities, still rank among the top most dangerous software security issues. Existing protection techniques, like Address Space Layout Randomization and Stack-Smashing Protection, prevent potential intrusions by crashing applications when anomalous behaviors are detected. Unfortunately, typical networking server architectures, such those used on Web servers ones, limit the effectiveness of such countermeasures. Since memory error exploits usually rely on highly specific processor characteristics, the same exploit rarely works on different hardware architectures. This paper proposes a novel strategy to thwart memory error exploitation by dynamically changing, upon crash detection, the variant executing the networking server. Required software diversification among variants is obtained using off-the-shelf cross-compilation suites, whereas hardware diversification relies on processor emulation. The proposed case study shows the feasibility and effectiveness of the approach to reduce the likelihood, and in some cases even prevent the possibility, of exploiting memory errors.
Keywords
Memory errors; software vulnerabilities; hardware virtualization; diversification
Information in this chapter
Introduction
Computer systems are under constant threat by hackers who attempt to seize unauthorized control for malicious ends. Memory errors have been around for over 30 years and, despite research and development efforts carried out by academia and industry, they are still included in the CWE SANS top 25 list of the most dangerous software errors [1]. Classically, they were exploited pursuing the remote injection of binary code into the target application’s memory and then diverting the control flow to the injected code. Today, memory error exploitation has evolved toward code-reuse attacks, where no malicious code is injected and legitimate code is reused for malicious purposes [2]. Interested readers can find in [3] a detailed analysis of the past, present, and future of memory errors. As authors conclude, memory errors “still represent a threat undermining the security of our systems.”
Various approaches have been proposed and developed so far to eradicate or mitigate memory errors and their exploitation. The use of safe languages [4] may be the most effective approach, since it removes memory error vulnerabilities entirely. The idea consists in imposing stronger memory models on programming languages in order to increase their safety. Other effective strategies for fighting against memory errors rely on bounds checkers [5], which audit programs execution for out-of-bounds accesses; deploy countermeasures to prevent overwriting memory locations [6]; detect code injections at early stages [7]; and prevent attackers from finding, using, or executing injected code [8]. Commonly, these techniques rely on keeping secret key information required by attackers to break the system protection. Notably, all of them cause protected systems or applications to crash in the case of memory errors. Although not perfect, those solutions have shown their usefulness in greatly reducing the success of attackers. This is why they are nowadays incorporated in most computer systems [9].
The decision to abort an application to hinder an attack can, however, be questionable, especially in the context of critical networking business services. The cost of one hour of downtime for an airline reservation center is about $89,000, for eBay is about $225,000 and in the case of a credit card authorization that cost grows to $6,450,000 [10]. To deal with this unavailability problem, modern server-oriented architectures commonly make use of process-based abstractions as error containment regions [11]. As a result, and despite the crash of a concrete process serving a particular request, the server may continue processing ongoing and new requests.
Another pending issue in existing crash-based protection techniques relates to their inability to keep the confidentiality of the secret key information in the presence of brute force attacks. Depending on the protection technique and the internal architecture of the targeted application, the number of tries or guesses to find the secret varies. For instance, it takes around 216 seconds to bypass the Address Space Layout Randomization mechanism included in an Apache server running on Linux [12]. Unfortunately, this is a too short time to enable system administrators to deploy any effective countermeasure.
To address the problem of brute force attacks, one PaX developers group recommendation relies on combining existing protection techniques with a “crash detection and reaction mechanism” [13]. This approach could be applied to any protection technique that causes the attacked process to crash (wrong guess of the secret key information), thus becoming detectable. As already mentioned, nowadays, very limited actions are usually taken when brute force attacks are detected: either the service is shut down, with subsequent economic cost, or it keeps running and an alert is issued to administrators, who may not be able to intervene fast enough to prevent a successful intrusion.
Diversification is an approach with high potential to build effective defenses against attacks in general and brute force attacks against Web servers in particular. Applied to systems development, diversification can be seen as a system (or application) with at least two variants plus a decider that monitors results from the variants’ execution in order to make decisions affecting their execution [14]. These variants are different versions of the same application (coming from different designs and/or implementations) that, although different, behave as expected from their specifications, that they provide the same service as perceived by users. However, differences existing among variants lead them to exhibit dissimilar sets of vulnerabilities, and thus different degrees of sensitivity against accidental and malicious faults.
The proposal presented in this chapter builds on the principle that the exploitation of memory errors relies on highly specific processor characteristics, so the same procedure rarely works on different hardware architectures. Obviously, diversifying the hardware also means diversifying the considered software. Software diversification, that is, the production of server variants, can be achieved using off-the-shelf cross-compilation suites, whereas hardware diversification relies on the emulation of different processor architectures. In this way, some vulnerabilities that manifest on a given architecture could be removed just by changing the execution platform to another architecture where existing software faults no longer constitute a vulnerability. Basically, a variant replacement policy is deployed upon detecting a process crash issued from memory errors. This approach can be seamlessly combined with existing protection techniques to complement a highly secure mechanism against memory error exploitation.
The key contributions of this chapter are:
1. Proposing a multi-architecture variant system running on a single platform and taking advantage of improvements in emulation support,
2. Employing off-the-shelf cross-compilation toolchains as a diversification technique,
3. Offering a novel recovery strategy, after an attack attempt, that maintains service continuity while invalidating brute force attacks and prevents the manifestation of accidental faults, and
4. Demonstrating through two case studies the effectiveness and portability of the technique, as well as the low implementation cost because it involves reuse of already existing tools.
The rest of this chapter describes in detail this proposal. The section titled “Background and Challenges” provides the background required to understand the problem tackled by this solution. The section “Proposed Security Approach” details the approach, whereas the section titled “A Case Study: Web Server” reports all practical aspects related to its deployment onto a real Web server running on two different platforms. Results issued from the evaluation of the developed prototypes are presented in the section “Experimentation and Results” and discussed in “Discussion.” The chapter closes with the section “Conclusions and Future Work.”
Background and challenges
This section describes the vulnerabilities that commonly lead to memory errors, the already existing mechanisms developed to cope with this problem, and the attacks that could bypass those mechanisms and successfully exploit existing vulnerabilities in the context of networking servers. Finally, identifying the common characteristics of presented vulnerabilities and attacks paves the way to defining a new architecture for memory error prevention. Figure 21.1 maps the concepts introduced in this section against the well-known AVI (Attack+Vulnerability→Intrusion) model [15].
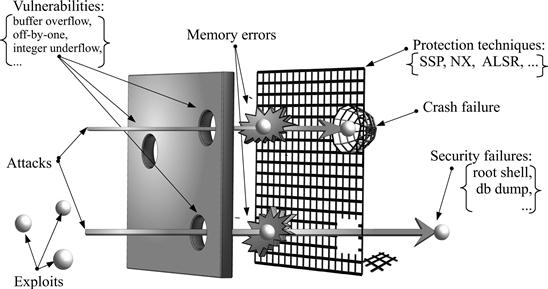
Memory errors
Memory errors usually derive from the exploitation of vulnerabilities (depicted as holes in a wall in Figure 21.1) existing in a given application due to software faults introduced during the software’s implementation. The most common software faults leading to memory errors are off-by-one, integer, and buffer overflow.
Off-by-one vulnerabilities [16] write one byte outside the bounds of allocated memory. They are often related to iterative loops iterating one time too many or common string functions incorrectly terminating strings. For instance, the bug reported by Frank Bussed [17] in the libpng library allowed remote attackers to cause an application crash via a crafted PNG image that triggered an out-of-bounds read during the copy of an error-message data.
Integer vulnerabilities [18] are usually caused by an integer exceeding its maximum or minimum boundary value. They can be used to bypass size checks or cause buffers to be allocated a size too small to contain the data copied into them. A recent bug discovered on the libpng library did not properly handle certain malformed PNG images [19]. It allowed remote attackers to overwrite memory with an arbitrary amount of data and possibly have other unspecified impact, via a crafted PNG image. Vendors affected included Apple, Debian GNU/Linux, Fedora, Gentoo, Google, Novell, Ubuntu, and SUSE.
Buffer overflows [20] are caused by overrunning the buffer’s boundary while writing data into a buffer. This allows attackers to overwrite data that controls the program execution path and hijack the program to execute the attacker’s code instead of the process code. A recent stack-based buffer overflow example involved the cbtls_verify function in FreeRADIUS, causing server crashes and possibly executing arbitrary code via a long “not after” timestamp in a client certificate [21].
Over the past decade, different techniques have been developed to prevent attacks from successfully exploiting these vulnerabilities, thus reducing their chance of causing memory errors.
Protection mechanisms
The most effective protection techniques commonly used nowadays to fight against memory errors, represented as a grid in Figure 21.1, are Address-Space Layout Randomization, Stack-Smashing Protection, Non-Executable Bit, and Instruction Set Randomization.
Address-Space Layout Randomization (ASLR)[13]. Whenever a new process is loaded in the main memory, the operating system loads different areas of the process (code, data, heap, stack, etc.) at random positions in the process’s virtual memory space. Attacks that rely on precisely knowing the absolute address of a library function, like ret2libc or the already injected shellcode, are very likely to crash the process, thus preventing a successful intrusion.
Stack-Smashing Protection (SSP) [22]. A random value, commonly known as canary, is placed on the stack just below the saved registers from the function prologue. That value is checked at the end of the function, before returning, and the program aborts if the stored canary does not match its initial value. Any attempt to overwrite the saved return address on the stack will also overwrite the canary and lead to a process crash to stop the intrusion.
Non-Executable Bit (NX) or “W⊕X”[6]. The memory areas (pages) of the process not containing code are marked as non-executable, so they cannot be written. On the other hand, those areas containing data are marked as just writeable, so they cannot be executed. Processors must provide hardware support to check for this policy when fetching instructions from the main memory. Even if an attacker successfully injects code into a writeable (not executable) memory region, any attempt to execute this code would lead to a process crash.
Instruction Set Randomization (ISR)[23]. ISR randomly modifies the instructions (code) of the process so they must be properly decoded before being effectively executed by the processor. Successful binary code injection attacks will crash the process, as decoding the injected code will not render the correct instructions. ISR is less commonly used than the preceding three techniques.
Despite the high protection provided by these techniques, their effectiveness is greatly reduced in the case of networking servers. Typically, the implementation of these servers is crash resilient (see crash failure in Figure 21.1), which increases the availability of the provided service. However, this also makes servers very sensitive to brute force attacks (note the grid hole leading to security failures in Figure 21.1). The next section focuses on this problem.
Networking server weaknesses
Traditionally, networking server architectures [24] are available in two main flavors: thread-based and process-based.
Multi-threaded architectures associate incoming connections with separate lightweight threads. Those threads share the same space address and thus also the same global variables and state. These architectures require small amounts of memory and provide fast inter-thread communication and response time, making them suitable for high performance servers. However, memory errors on one thread may corrupt the memory of any other thread, resulting in compromised threads accessing sensitive data from the rest of threads.
Multi-process architectures are well-suited for the compartmentalization philosophy promoted in security manuals. Incoming connections are handled by separate child processes, which are forked (created) by making an exact copy of the memory segments of the parent process in a separate address space (see Figure 21.2). Although performance suffers the effects of larger memory footprints and heavyweight structures, these architectures are more suitable for, and typically used in, highly secure servers [24].
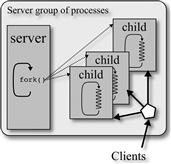
Nevertheless, the common operation of multi-process servers makes them vulnerable to different attacks. Since all the children have the same secrets (ASLR offset, canary value, etc.) as the father, a brute force attack can be created.
ASLR provides little benefit for 32-bits systems, as there are only 8 random bits for mmapped areas, and the secret can be guessed by brute force in a matter of minutes [12].
Applications protected with SSP are vulnerable to buffer overflows in the heap, functions overwrites, and brute force attacks [25]. The most dangerous vulnerabilities are those allowing a “byte for byte” brute force attack, which will compromise the system with 1024 attempts (32-bit machine), like the latest pre-auth ProFTPd bug [26].
The NX technique is easily bypassed by overwriting the return address on the call stack, so instead of returning into code located within the stack, it returns into a memory area occupied by a dynamic library [27]. Typically, the libc shared library is used, as it is always linked to the program and provides useful calls to an attacker (like system(“/bin/sh”) to get a shell).
ISR, like SPP, is vulnerable to brute force attacks, and also to attacks that only modify the contents of variables in the stack or the heap that cause control flow change or logical operation of the program [23].
Although several techniques have been proposed so far to prevent the successful exploitation of memory errors, the truth is that all these mechanisms can be bypassed one way or another. The following section discusses how to complement these mechanisms with an approach to improve their resilience against brute force attacks.
Proposed security approach
The core idea of the proposed security appraoch consists of having the same application compiled for different processors and replacing the executable process when an error is detected. Each variant is executed in sequential order on the same host by a fast processor emulator. In the case of a malicious attack, since code execution is highly processor dependent, changing the processor that runs the application greatly hinders the attack’s success. The proposed architecture has the following elements:
1. A set of cross-compiler suites for creating the set of variants
2. A set of emulators for running the variants
3. An error detection mechanism, which triggers the variant replacement
4. A recovery strategy that selects the variant that will be used once an error has been detected
Creation of variants
Many diversification techniques are based on compiler or linker customizations for the automatic generation of variants [28]. Although it eliminates the need to manually rewrite the source code for diversification, deploying the required customizations on different compilers/linkers or introducing new modifications is costly and prone to introducing new errors.
The proposed approach (see Figure 21.3) uses already existing cross-compilers to generate variants, one for each target architecture, in an easy and effective way. Cross-compiler toolchains provide the set of utilities (compiler, linker, support libraries, and debugger) required to build binary code for a platform other than the one running the toolchain. For instance, the GNU cross-compiling platform toolchain is a highly portable widespread suite that is able to generate code for almost all of the 32-bit and 64-bit existing processors.
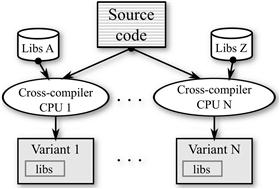
Just by compiling the application source code for different target processors, the particular architecture of each processor provide variants with different (i) endianness and instruction sets, so raw data and machine code injected by attackers are differently interpreted; (ii) register sets, thus changing the stack layout (on non-orthogonal architectures); (iii) data and code alignments, so unaligned instructions and word data type raise an exception; (iv) address layouts, which result in different positions for functions and main data structures according to the resulting code size and data layout; and (v) compiler optimizations, some generic and some processor specific, resulting in register allocation, instruction reordering, or function reordering.
Furthermore, most applications use the services provided by one or more libraries, which are linked during the compilation process. For instance, the standard C library provides the interface to the operating system (system calls), basic algorithms (string manipulation, math function, sorting, etc.), types definition, and so on. Since several implementations of the C library exist for achieving different goals, such as license issues, small memory footprint, better portability, or multi-thread support, by linking variants with different libraries it is possible to (i) get a higher degree of diversification among them, and (ii) get rid of specific software faults that are not present in some libraries.
This form of binary diversification preserves the semantic behavior of each variant. It is easy to implement because it uses widely available and tested software, and it offers a strong differentiation between resulting binaries.
Execution of variants
In order to run, variants require a proper execution environment, including the operating system API, system calls convention, processor instruction set, and the executable file format. The native variant—the one compiled for the physical processor and operating system hosting the server—runs on the native execution environment. However, as the rest of variants have been built for different processors, it is necessary to create a virtual execution environment to run them all.
Nowadays, there are two different virtualization solutions (see Figures 21.4a and 21.4b) to build a complete execution environment: (i) platform emulation, where the emulator provides a virtual hardware to execute the guest operating system managing the guest application, and (ii) user-mode emulation, where the emulator provides both processor virtualization and operating system services, translating guest system calls into host system calls that are forwarded to the host operating system.
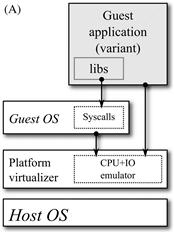
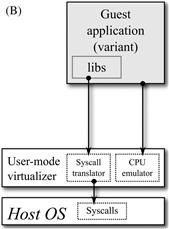
User-mode emulation is the less common form of emulation but offers better performance, since the operating system code is directly executed by the host processor. The emulator loads the guest executable code in its process memory space. The guest executable code is then dynamically translated into host native code, and the system calls are emulated (converted from guest format to host and back). Conceptually, user-mode emulation is very close to the Java Run-time Environment (JRE), which is a software emulator for running the Java Virtual Machine Specification. The main difference between user-mode emulation and JRE is that the former emulates real processors and real operating systems, while the latter emulates the Java Virtual Machine Specification.
Because of these advantages, the proposed security approach promotes the use of user-mode emulation to create the execution environment required for each variant. Variants should be compiled for the same operating system as the host machine is running (or a compatible one).
Memory error detection
The proposed approach relies on existing protection mechanisms (SSP, ASLR, etc.) to crash the compromised process. A monitor is in charge of detecting these crash-related events and triggering the established variants replacement strategy according to the defined security policy.
Notably, although those techniques were initially developed to deal with malicious faults, they also provide good coverage for accidental faults, like wild pointers. Accordingly, accidental activation of software faults leading to memory errors will also crash the process, giving the system a chance to deal with them.
Precisely diagnosing whether the problem is related to an accidental or a malicious fault and its precise origin (kind of attack), in order to define a more specific reaction, is still an issue for further research.
Variants replacement strategy
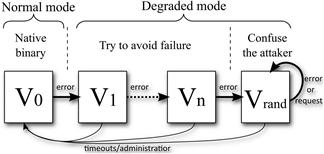
The widely used multi-process architecture of networking servers provides an ideal scenario for deploying different security policies for variant replacement upon detection of memory errors. The proposed policy consists of three successive stages (see Figure 21.5):
Stage 1: High performance service
Initially, the service is provided by the native variant, directly running on the host computer, and is thus free of any overhead due to virtualisation. Upon detecting a process crash, the system enters into a fault avoidance mode.
Stage 2: Fault avoidance
In the second stage, the system assumes that an attack, or an accidental software fault, exists that could cause another crash on another child. To try to hinder or even prevent the successful exploitation of the memory error, the next variant to be executed is selected among those with more architectural differences with respect to the previously selected one. For instance, a buffer overflow by one byte is likely to cause an error on the i386 architecture but not on the SPARC one, due to the different ways the processor registers are managed; the Apache chunked-encoding was exploitable on 32-bit processors but not on 64-bit Unix platforms [29]; and a busybox integer overflow [30] only affected big endian systems.
After changing the variant, the service runs in a performance degraded mode due to the processor emulation overhead. This performance penalty also runs against attackers by slowing down the attacks, which administrators valuable time to fix the problem. If no new crashes occur during a given period, the system can automatically revert to the native mode to increase its performance, or it could require an explicit command from the system administrator to do so. If there are new process crashes, the system keeps changing from one variant to another until all of them have been tried. When no new variants are available, the system assumes it is under a brute force attack and the fault manifests on all variants, which requires a more aggressive replacement policy.
Stage 3: Confuse the attacker
The third stage is focused on confusing a possible attacker to reduce as much as possible the information that could be retrieved from unsuccessful exploitation attempts. If variant replacement is sequential, although difficult and time-consuming, expert attackers might finally guess the processor architecture of some variants and could develop exploits to compromise the system. Accordingly, the proposed policy relies on randomly selecting the next variant to be executed, which makes construction of a brute force attack more difficult. The policy to revert to native mode is the same as in the second stage.
Obviously, different policies should be defined according to the particular needs and resources available for each server, such as existing variants, and diagnosis and detection capabilities, so they vary from one case to another. Since each request is redirected to a different variant independently, whether they crash or not, brute force attacks are no longer possible.
A case study: Web server
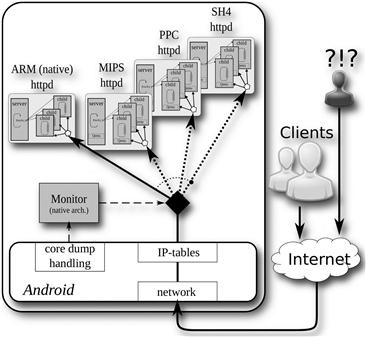
As a proof of concept to show the feasibility and portability of the proposed approach, two hardware platforms have been chosen for case studies: an HTTP server running on a PC and a smartphone. The first hardware platform, selected as representative of a common platform for Web servers, consists of a PC running an Ubuntu 12.04.1 LTS operating system. The PC is equipped with an x86_64 Intel Core i3-370 M CPU, clocked at 2.4 GHz and 3072 MB RAM. The second target platform, selected to show the portability of the proposed approach even on devices with limited resources, is a Samsung Galaxy S smartphone running the Android 2.3.6 operating system. The smartphone is equipped with a 1 GHz ARM Cortex A8 processor with 512 MB RAM and a PowerVR SGX 540 GPU.
The busybox-httpd application [31] has been selected to provide the required networking service. It is a complex, full-featured application widely used on many platforms, including smartphones, routers, and media players, running a variety of POSIX environments like Linux, Android, and FreeBSD. The busybox application consists of a single executable file that can be customized to provide a subset of over 200 utilities specified in the Single Unix Specification (SIS) plus many others that a user would expect to see on a Linux system, including the HTTPD Web server considered for this case study.
The following sections describe in detail the particular instantiation of all the elements required to deploy the proposed approach, including variants created using cross-compilation, the processor emulation support, the detection mechanism, the recovery strategy deployed for variant replacement procedure, and the security policy. The following implementation has been seamlessly applied to both hardware platforms with minor changes. An overview of the prototype developed for the smartphone is depicted in Figure 21.6.
Building cross-compilers
To build the binary images (HTTPD variants) for each target architecture, a cross-compiling toolchain suite is required for each of them. One possibility is to download pre-compiled versions from different projects or providers, but these would not be flexible enough to achieve the desired level of diversification. Another possibility is to build the required toolchain suites from the source code of each element (compiler, linker, library, and debugger) to get greater controllability when creating variants.
Although building a toolchain is quite tricky due to the strong dependence among elements, thanks to the buildroot project (http://buildroot.net) it is possible to build (and customize) the GNU toolchain very easily. Buildroot uses the same source code configuration tools as the Linux kernel, commonly known as menuconfig, which presents a simple menu interface (see Figure 21.7) that guides the user to configure code features while avoiding conflicting or incompatible options.
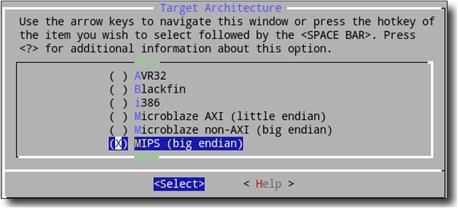
Buildroot V2012.05 was selected for this case study, and, according to the target architectures, generation parameters were customized to build the required cross-compilers as follows: (i) according to the host operating system the selected kernel headers were “Linux 3.2.x kernel headers”; (ii) the considered target architecture included the native ones, “x86_64” and “ARM,” as well as others with very different architectures, like “SPARC,” “i386,” “SH4,” “MIPS,” and “PowerPC”; (iii) the uClibc C library version was “uClibc 0.9.32.x”; and (iv) the selected version of the processor emulator does not support “Native POSIX Threading (NPTL)” for all architectures, the “linuxthreads (stable/old)” Thread library implementation was used. The remaining options were configured to be as similar as possible to each other in order to perform an accurate comparative analysis.
Qemu emulator
Qemu [32] is a generic, open source, and fast machine emulator and virtualizer that uses a portable dynamic translator for various target CPU architectures. As an example of its high quality and popularity, it is the base of the Android emulator currently distributed in the Android SDK. Besides the standard CPU emulation mode, Qemu implements the user-mode emulation, capable of running a single program (process) in a complete virtualized environment, that constitutes the core of the proposed approach as described in the subsection “Execution of Variants.” User-mode emulation is not limited to statically compiled binaries, but can also load dynamic libraries, thereby enabling the direct execution (emulation) of most existing applications.
Combining the user-mode emulation with the Linux capability to run arbitrary executables (called binfmt_misc), it is possible to run a guest binary executable (variant) as if it were a native one. Note that it is the operating system kernel, and not a module of the command interpreter or another user application, that interprets the executable format. In fact, all variants (regardless of the target processor) use the same operating system and can access the same directory hierarchy and network interfaces. With this form of emulation, it is not necessary to set up a complete virtual platform, and variants are transparently and efficiently executed as if they were native processes.
Detecting crashes
The core dump facility of Linux (also available on many operating systems) was selected as a suitable tool for detecting the abnormal termination of variants. Core dumps are triggered by different signals (see Table 21.1). Since Linux 2.6. the operating system infrastructure for dumping process core images (/proc/sys/kernel/core_pattern file) provides facilities to send the core image to a crash reporter program along with command-line information about the crashed process.
Table 21.1
| Signal | Description |
| SIGQUIT | Quit from keyboard |
| SIGILL | Illegal Instruction |
| SIGABRT | Abort signal from abort(3) |
| SIGFPE | Floating point exception |
| SIGSEGV | Invalid memory reference |
| SIGBUS | Bus error (bad memory access) |
| SIGTRAP | Trace/breakpoint trap |
| SIGXCPU | CPU time limit exceeded |
| SIGXFSZ | File size limit exceeded |
| SIGIOT | IOT trap. A synonym for SIGABRT |
Although core dumps provide lots of useful information for diagnosing and debugging programming errors, the proposed approach only requires notification that the process has crashed, regardless of its cause (as previously mentioned, this could be an enhancement requiring further research). The core_pattern file has been configured (see Code 1) to call a tiny shell script log_crashes.sh (see Code 2), whenever any process of the system crashes. This script will receive the PID of the crashed process (%p), the triggering signal (%s), the executable filename name (%e), and the time of dump (%t). It will append a single line containing the received information into a file named /var/log/m/crashes.log.
echo "|/var/log/m/log_crashes.sh %p %s %e %t" >/proc/sys/kernel/core_pattern
Code 1 Command for configuring core_pattern
#!/bin/bash
pid=$1
signal=$2
ex_name=$3
time=$4
fcrash="/var/log/m/crashes.log"
echo "[$pid] [$signal] [$ex_name] [$time]" >> $fcrash
Code 2 Saving core dump information into crashes.log
The Linux inotify mechanism, which provides an efficient file system events monitoring service, has been used to monitor when new entries are written in the crashes.log file. This makes it possible to read new entries from the file and consider only those caused by variants processes without overhead. Note that the monitor is compiled for the native architecture and will be blocked (inactive) until a new entry is written.
As the monitor is a critical component of this approach, it has been designed to be simple and small, with the aim of minimizing the probability of introducing design or software faults. Another requisite was to isolate the monitor from the application so attackers cannot know of the monitor’s presence and use a communication channel to interfere with it.
Contrary to other protection solutions, the monitor does not act as a barrier between clients/attackers and servers, and it does not add new code or features that attackers could exploit. The kernel facilities used to handle core files enable the immediate detection of crashed variants, without modifications of either the variants’ code or their configuration. The fact that it is a one-way communication channel with a very limited and simple interface makes it extremely difficult to successfully attack the monitor through this channel.
Alternating among variants
Once the crash has been detected, the current variant is replaced by another one according to the established replacement policy. The straightforward solution would be to stop (kill) all the processes (in the case of a multi-process server) of the current variant and start up the next one. However, this solution presents two important drawbacks: (i) the failure of a single server process serving a particular client is propagated to the rest of processes, so all ongoing connections are affected by the failure; and (ii) the service is unavailable until the next variant is up and running.
A less drastic solution can be implemented using kernel firewall facilities, known as iptables, which allow a system administrator to customize the tables provided by the Linux kernel firewall and the chains and rules it stores. Using iptables, the active connections are preserved for the server processes that are working properly, while new connections (clients) are redirected to the newly selected variant, thus solving any μ-denial-of-service (μ-DOS) or temporary service unavailability problem.
Following this approach, all variants are created and started as if they were the actual server. Each variant is configured to listen for connections on different ports (other than the external server port), which are blocked using iptables to prevent external connections from directly accessing variants. The internal firewall is then configured to redirect incoming connections from the service port to the active port of the current variant. When a process of the current variant crashes, the policy of the recovery strategy is applied to decide which will be the next variant, and the service port is redirected to the next variant port. A sample iptables rule implementing this approach is shown in Code 3.
Following the isolation design principle of the monitor, the variant selection procedure implemented using the iptables facility is an indirect mechanism that takes advantage of the kernel IP routing tables. Variants are not aware of the presence of the monitor, and they are not modified in any way. In this case, there is no communication channel that attackers could exploit to reach the monitor through variants.
iptables -A PREROUTING -t nat -p tcp --dport [service-port] -j REDIRECT --to-ports [variant-port]
Code 3 Firewall configuration to change the active variant
In this prototype, all variants are simultaneously launched when the service is started. More advanced replacement and recovery policies enabled by the kernel firewall facility are discussed in the “Discussion” section VI.
Experimentation and results
In order to assess the effectiveness of the proposed approach, the prototypes considered in the case study were exposed to a number of exploitable vulnerabilities leading to memory errors. The results show the importance of properly selecting hardware architectures to prevent the further exploitation of existing vulnerabilities, either because software faults no longer lead to memory errors or because brute force attacks get confused. Finally, the temporal and spatial overhead induced by the solution is analyzed.
Fault Manifestation
The exploitation of software faults leading to memory errors may manifest differently according to the variant being executed due to its particular processor architecture. To illustrate this, a buffer overflow fault was injected into the busybox HTTPD web server (see Code 4”) whereas, for the sake of clarity, off-by-one and integer underflow faults were manually injected into a standalone program (see Code 5).
static int get_line(void) {
int count=0;
char c;
char buffer[256]; // Injected code
…
…
strcpy(buffer, iobuf); // Injected code
return count;
}
Code 4 Buffer overflow fault injected in busybox-httpd
The code injected into the httpd.c file, in the function get_line(void) (see Code 4”), constitutes a typical buffer overflow, similar to the one found in Oracle 9 [33]. The URL of the HTTP request is copied into the added buffer, but since there is no length check, long URLs overflow the buffer and cause a memory error. HTTP requests of increasing URL lengths were tested for each variant. Table 21.2 lists the minimum length required to crash the process. The results show that the SPARC architecture is, by far, the most robust against that particular fault, so it could be a good choice for preventing problems derived from buffer overflows.

void offByOne(char*arg) {
char buffer[128];
if(strlen(arg)>128) {
printf("Overflow ");
exit(0);
}
strcpy(buffer, arg);
}
void intUnderflow(unsigned int len, char*src){
unsigned int size;
size=len-2;
char*comment=(char*) malloc (size + 1);
memcpy (comment, src, size);
}
Code 5 Standalone code for off-by-one and integer underflow faults
The offByOne() function from Code 5 line 1, inspired by one affecting an FTP server in [34], includes an offset-by-one software fault, since arguments with a length of 128 will cause the strcpy() function to overflow the buffer by just one byte (the appended ’�’ char). Table 21.2 lists how this fault manifests for two different variants created for each considered architecture: one with the commonly used -O2 optimization flag, and the other with no optimizations (-O0). SPARC is again the most robust architecture, as the fault does not crash the process regardless of the selected optimization flags, whereas the SH4 architecture always crashes. The negative influence of compiler optimizations that, in general, produce less robust variants is worth noting.
The integer underflow software fault was tested using a real-world vulnerability [35] in a JPEG processing code. The code of the faulty intUnderflow() function is shown in Code 5 line 10. When 1 is passed as the first parameter, the size variable has the value -1, which is interpreted as a large positive value (0xFFffFFff) in the third parameter of the memcpy() function (line 14), on a 32-bit architecture. This incorrect value is then used to perform a memory copy into the buffer reserved by the previous malloc(). The behavior of a malloc() request for zero bytes is implementation dependent (some implementations return NULL, while others return a pointer to the heap area). As shown in Table 21.2, only the ARM and MIPSEL variants prevent the process from crashing.
Protection against attacks
The basic idea behind brute force attacks is to make continuous requests, trying all the possible values of the unknown secret (a memory address or a random value, for instance), until the right value is found. On a system equipped with ASLR, NX, and stack protector techniques, the typical steps taken to build an attack are:
1. Find out the offset to the canary on the stack. It can be estimated accurately from the application image (which we assume the attacker has), but often the offset is verified by testing sequentially the position of the canary.
2. Find out the value of the canary (using brute force against the target).
3. Build the Return Oriented Programming (ROP) sequence (based on the ELF). For simplicity’s sake, we assume the ROP gadgets are from the libc.
4. Find the entry point for the ROP (using brute force against the target).
Depending on the kind of error, all of these steps may not be required. For example, a memory error in the data segment can be exploited without knowing the canary.
The final exploit string must have the correct values of all these elements: canary value and offset, and ROP sequence and entry point. The parts of the exploit not known by the attacker can be obtained using brute force, building a partial exploit using the values already known and testing only the values that are missing. Any incorrect value in the exploit (or a partial exploit string) is detected by the protection mechanisms, and the application is crashed. Since the protection mechanisms are applied sequentially, the attacker builds a partial exploit that affects only one of these protections. One the protection is bypassed, the next one can be addressed.
Our solution prevents exploits from being built this way because the following assumptions no longer hold:
• The active server target is not always the same, so a fault cannot be unequivocally interpreted as an incorrect value guess. For instance, variants may crash not only due to a wrong guess but also due to different memory layouts (invalid offsets) or endianness (invalid instruction/data format).
• Some software faults may not manifest in certain variants (as previously discussed), which exploits interpret as a successful guess.
• Once an emulated variant is active, the performance of the server is degraded due to the emulation overhead, which plays against the attacker by increasing the time required to guess the secret, similar to the GRKERNSEC_BRUTE [36] option.
In [12], the authors show how ASLR can be bypassed using a brute force attack to find out the correct address for a return-to-libc. The proposed exploit succeeded in just 216 seconds on average. However, using our technique, the current variant is replaced when the monitor detects a crash. In a variant with a different stack layout (the offset of the return address) the attacker will be overwriting the wrong one, so the return address is not overwritten with the guessed value and the exploit can never succeed.
The most dangerous way to bypass the SSP mechanism is the “byte for byte” approach, whereas the most generic procedure is a generic brute force attack [37]. In the first case, if attackers may overwrite individual bytes of the canary (secret), at the most ![]() tries (1024 attempts for a 32-bits machine) are required to guess the right value, which takes just a few seconds. For generic brute force attacks, exploits need to try all the possible values of the secret (
tries (1024 attempts for a 32-bits machine) are required to guess the right value, which takes just a few seconds. For generic brute force attacks, exploits need to try all the possible values of the secret (![]() attempts at most for a 32-bits secret), returning the first one that does not cause a crash. This kind of attack cannot succeed on the proposed architecture. After a variant is replaced, the address being overwritten by the attacker is not that belonging to the canary. If the process does not crash, the exploit will wrongly assume that the secret has been accurate guessed ; if it crashes (which is not related to wrong guesses), the exploit will keep erroneously discarding possible values. From this point on, the next steps of the exploit are completely useless.
attempts at most for a 32-bits secret), returning the first one that does not cause a crash. This kind of attack cannot succeed on the proposed architecture. After a variant is replaced, the address being overwritten by the attacker is not that belonging to the canary. If the process does not crash, the exploit will wrongly assume that the secret has been accurate guessed ; if it crashes (which is not related to wrong guesses), the exploit will keep erroneously discarding possible values. From this point on, the next steps of the exploit are completely useless.
Spatial and temporal cost
In spite of the great security benefits provided by the proposed approach, there is also a price to be paid in terms of spatial and temporal overhead due to the execution of multiple virtual environments.
Spatial overhead refers to the amount of main memory consumed at run time for each variant when it is interpreted by the processor emulator (Qemu). This total amount of memory has three different components: (i) the size of the executable image of the variant, which depends on the libraries selected for building the toolchain, the compiler optimization flags, and the code density of the related architecture; (ii) the size of Qemu’s memory translation cache, where application code is dynamically translated from guest to host architecture; and (iii) the memory required by Qemu itself. Note that the native variants have no memory overhead, since they are executed as if the proposed approach were not used.
The memory consumed by each variant has been estimated according to the set of pages unique to a process (Unique Set Size, or USS), which has been measured with the smem(8) tool. As both Qemu and variants are statically compiled, there is no shared memory other than the pages shared between father and children processes (all pages copied to children are marked as copy-on-write). Table 21.3 summarizes the average USS memory for each variant. The total memory used in the proposed implementation is the memory used by all running variants. By default all variants are launched, but more conservative solutions are possible in which only the active and next variant are ready (i.e., launched).
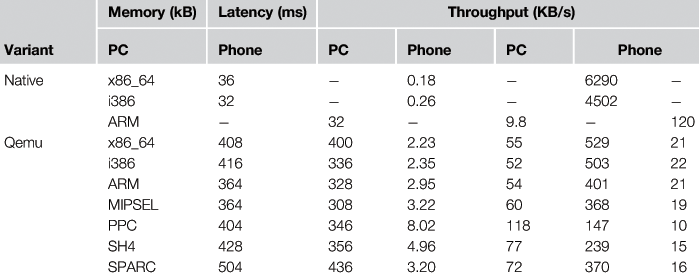
The temporal overhead is introduced by the emulation support provided by Qemu when executing non-native variants. In the absence of crashes, the native variant is executed without any temporal overhead. This overhead has been estimated by means of the Apache HTTP server benchmarking tool, which was configured to perform 100 simultaneous requests for a total of 5,000 requests. Table 21.3 summarixes the average latency and throughput (from the user viewpoint) obtained by the considered HTTPD Web server when running the benchmark for each variant. Notably, requests on the PC were made locally, which could be considered the best possible scenario, whereas requests on the smartphone were made remotely, thus incurring all the delays related to wireless networks, which could be considered the worst possible scenario. The time required for the monitor to detect a process crash and configure the firewall was on the order of a few microseconds and considered negligible, so it is not included in the table, where latency is expressed in milliseconds.
Discussion
Successfully exploiting a memory error is not an easy task for anyone to achieve. However, due to the proliferation of popular websites that act as repositories for existing exploits, even inexpert hackers have a chance to succeed. According to their knowledge and available resources, three basic types of attackers can be considered: script kiddies, black hat hackers, and Advanced Persistent Threat (APT) groups.
Most attacks come from script kiddies or skiddies, who are non-expert users who simply download and use existing exploits. These exploits are usually highly customized to target a specific vulnerability on a given architecture. Thus, unless the exploit succeeds on the very first try (quite unlikely, but there is always a chance), replacing the variant under attack will prevent this kind of user from successfully exploiting the memory error.
The knowledge and experience required to exploit a software fault is mastered by only a few. Due to the complexity and the time required, black hat hackers usually specialize in a given platform (operating system and architecture). It is rare to find hackers able to target multi-architecture platforms like the one proposed in this chapter. Bypassing the proposed solution would require developing a meta-exploit, targeting multiple architectures, that could extract some valuable information from the running variant. As long as the next variant is randomly selected, it is unlikely that brute force attacks could succeed.
Finally, APT groups are sets of people with the capability, knowledge, and resources as well as the intent to persistently and effectively break the security of a specific target. With the proposed plan, even these groups will be highly delayed in achieving a successful attack, not only by the complexity involved in developing a suitable exploit but also due to the temporal overhead caused by the emulation process, which greatly delays the attack. This delay gives administrators enough time to react and deploy the required countermeasures.
Following this line of thought, this technique should not be used as a stand-alone mechanism but shall be integrated into the server’s security policy. Whenever the server switches to a degraded mode (a non-native variant is active), administrators should be notified to deploy the most suitable countermeasures.
Typically, successful brute force attacks are launched by compromising a set of Internet-connected computers (zombies) that collaborate in the exploitation attempt (botnet). Distributed attacks are one of the most difficult kinds of attacks to handle with common firewalls because the request come from a variety of sources. Since the proposed solution does not take into account the source address of the attackers, it is equally effective whether it is facing a single node or multiple botnet attacks.
Although the primary source of diversification is the use of cross-development tools, it is also possible to create variants for native architectures using different compilation flags. It might even be interesting to create some variants from former versions of the code. Considering that newer code is more likely to have bugs than older and more tested versions, using old versions of the code is a good solution when the focus prioritizes security over functionality.
Another possible improvement consists in adapting the policy for variant replacement according to a diagnosis of the particular kind of attack and the exploited vulnerability. In this way the most suitable architecture to deal with each exploitation attempt could be selected from the variant pool.
Likewise, a simple improvement to decrease the spatial overhead could be to keep only two variants launched: the current and next.
Conclusions and future work
Nowadays, memory errors continue to rank among the top dangerous software errors despite many research efforts by both academia and industry. Although existing protection mechanisms constitute a formidable barrier to the successful exploitation of memory errors by common hackers, these mechanisms do not constitute an impassable obstacle to more capable and resourceful opponents, like black hat hackers and APT groups.
Due to the nature of the protection mechanisms, most attacks are thwarted at the cost of causing a server crash. The administrator can configure the service to either stop it at once, with related economical losses, or keep it running, with an increasing likelihood of successful attacks. The work presented in this chapter, which relies on diversification, complements existing protection mechanisms with a detection and reaction approach that offer administrators a third possibility, less drastic and dangerous, for hindering and even preventing the successful exploitation of memory errors while preserving continuity of service.
Based on the fact that software faults leading to memory errors are highly dependent on the hardware architecture (processor), our technique uses processor diversification as an effective protection against most kind of attacks and accidental faults. Attacks designed to target a specific processor will not succeed. The only alternative for attackers is to build meta-exploits for all available target architectures, greatly hindering the possibility of a real attack. Even if such a meta-exploit were available, applying a replacement policy in which the next variant is randomly selected would prevent attackers from obtaining useful information to bypass existing mechanisms. The processor diversification required for this policy can be done efficiently due to current advances in processor emulation techniques.
Contrary to most automatic diversification techniques, which customize the compiler or even the resulting executable binary, the use of cross-toolchains provides a simple and powerful means of software diversification, with the added benefit of using widely used and tested tools without having to modify them. Combining this with the underlying hardware diversification, existing software faults will manifest differently among variants and may not manifest at all in some of them.
The feasibility and portability of this secure approach has been proven by deploying a HTTP Web server in two very different scenarios: a personal computer and a smartphone. The results show that common attacks against existing protection mechanisms are effectively handled at the cost of degrading the service performance due to the processor emulator overhead. The service degradation, usually considered an undesired side-effect, in fact plays against attackers, since it delays brute force attacks, thus giving administrators time to react while still providing service.
The powerful capabilities of the proposed approach open up a wide range of possibilities for further research. Some of these are: (i) a deep study of different hardware architectures with regard to how memory errors manifest in order to characterize their robustness against exploitation attempts; (ii) a careful diagnosis of an attack in process, which could be invaluable in selecting the most suitable hardware architecture to hinder that attack or even prevent it; and (iii) research into tailoring the variant replacement policy to fit the needs of particular services or scenarios.
Acknowledgments
This work has been supported by Spanish MICINN grant TIN2009-14205-C04-02 and MEC TIN2012-38308-C02-01.
References
1. CWE/SANS. (2011) Top 25 most dangerous software errors. [Online]. Available: http://cwe.mitre.org/top25.
2. Tran M, Etheridge M, Bletsch T, Jiang X, Freeh V, Ning P. On the expressiveness of return-into-libc attacks. In RAID’11: Proceedings of the 14th International Conference on Recent Advances in Intrusion Detection;Berlin, Heidelberg: Springer-Verlag. p. 121–141. [Internet]. Available from: <http://dx.doi.org/10.1007/978-3-642-23644-0_7>; 2011.
3. van der Veen V, dutt Sharma N, Cavallaro L, Bos H. Memory errors: The past, the present, and the future. In RAID: Proceedings of the 15th International Symposium on Research in Attacks Intrusions and Defenses; 2012.
4. Wichmann BA. Requirements for programming languages in safety and security software standards. Comput Stand Interfaces. 1992;14(5-6):433–441 Available from: <http://dx.doi.org/10.1016/0920-5489(92)90009-3>.
5. Brünink M, Süßkraut M, Fetzer C. Boundless memory allocations for memory safety and high availability In DSN. Proceedings of The 41st Annual IEEE/IFIP International Conference on Dependable Systems and Networks Los Alamitos, CA, USA: IEEE Computer Society; 2011 2011; Proceedings of The 41st Annual IEEE/IFIP International Conference on Dependable Systems and Networks Los Alamitos, CA, USA: IEEE Computer Society; 2011 2011; p. 13–24.
6. Paulson LD. New chips stop buffer overflow attacks. Computer. 2004;37(10):28–30.
7. Snow KZ, Krishnan S, Monrose F, Provos N. Shellos: Enabling fast detection and forensic analysis of code injection attacks. In USENIX Security Symposium. USENIX Association. [Internet]. Available from: <http://dblp.uni-trier.de/db/conf/uss/uss2011.html#SnowKMP11>; 2011.
8. Salamat B, Jackson T, Wagner G, Wimmer C, Franz M. Runtime defense against code injection attacks using replicated execution. IEEE Transactions on Dependable and Secure Computing. 2011;8:588–601.
9. Riley R, Jiang X, Xu D. An architectural approach to preventing code injection attacks. IEEE Trans Dependable Secur Comput. 2010;7(4):351–365 Available from: http://dx.doi.org/10.1109/TDSC.2010.1.
10. Patterson DA. A simple way to estimate the cost of downtime. In LISA: Proceedings of the 16th USENIX Conference on System Administration; Berkeley, CA, USA. USENIX Association; 2002. p. 185–188. [Internet]. Available from: <http://dl.acm.org/citation.cfm?id=1050517.1050538>; 2002.
11. Chapin J, Rosenblum M, Devine S, Lahiri T, Teodosiu D, Gupta A Hive: fault containment for shared-memory multiprocessors. SIGOPS Oper Syst Rev. 1995 Dec;29(5):12-25. [Internet]. Available from: http://doi.acm.org/10.1145/224057.224059.
12. Shacham H, Page M, Pfaff B, Goh E-J, Modadugu N, Boneh D. On the effectiveness of address-space randomization. In CCS ’04: Proceedings of the 11th ACM Conference on Computer and communications security; New York, NY, USA; ACM. p. 298–307. [Internet]. Available from: <http://doi.acm.org/10.1145/1030083.1030124>; 2004.
13. Pax Team. PaX address space layout randomization (ASLR). [Internet]. Available from: <http://pax.grsecurity.net/docs/aslr.txt>; 2003.
14. Laprie J-C, Béounes C, Kanoun K. Definition and analysis of hardware- and software-fault-tolerant architectures. Computer. 1990;23(7):39–51 [Internet]. Available from: <http://dx.doi.org/10.1109/2.56851>.
15. Verissimo PE, Neves NF, Cachin C, et al. Intrusion tolerant middleware: The road to automatic security. IEEE Security and Privacy. 2006;4(4):5–62.
16. Koziol J., Litchfield D., Aitel D., et al. The shellcoder’s handbook: Discovering and exploiting security holes. Wiley Publishing Inc; 2006.
17. NIST. Vulnerability summary for CVE-2011-2501. [Internet]. Available from: <http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2011-2501>; 2011.
18. Brumley D, Chiueh T-C, Johnson R, Lin H, Song D. Rich: Automatically protecting against integer-based vulnerabilities. In: Symp on Network and Distributed Systems Security; 2007.
19. NIST. Vulnerabilitysummary for CVE-2011-3026. [Internet]. Available from: <http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2011-3026>; 2012.
20. One A. Smashing the stack for fun and profit. Phrack. 1996;7:49.
21. NIST. Vulnerability summary for CVE-2012-3547. [Internet]. 2012 Nov. Available from:< http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2012-3547>; 2012.
22. Cowan C, Pu C, Maier D, et al. Stackguard: Automatic adaptive detection and prevention of buffer-overflow attacks. Proc of the 7th USENIX Security Symposium 1998 Jan:63–78.
23. Kc GS, Keromytis AD, Prevelakis V. Countering code injection attacks with instruction-set randomization. In CCS ’03: Proceedings of the 10th ACM Conference on Computer and Communications Security; 2003; New York, NY, USA; ACM. p. 272-280. [Internet]. Available from: <http://doi.acm.org/10.1145/948109.948146>.
24. Erb B Concurrent programming for scalable web architectures. [diploma thesis]; Institute of Distributed Systems: Ulm University; . [Internet]. Available: <http://www.benjamin-erb.de/thesis>; 2012.
25. Bulba, Kil3r. Bypassing stackguard and stackshield. Phrack. 56; 2002.
26. NIST. Vulnerability summary for CVE-2010-3867. [Internet]. 2011 Sep. Available from: <http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2010-3867>; 2011.
27. Nergal. The advanced return-into-lib(c) exploits: PaX case study. Phrack; 58; 2001.
28. Salamat B, Jackson T, Wagner G, Wimmer C, Franz M. Run-time defense against code injection attacks using replicated execution. IEEE Trans Dependable Sec Comput. 2011;8(4):588–601.
29. CERT. Advisory CA-2002-17 Apache Web server chunk handling vulnerability. [Internet]. Available from: <http://www.cert.org/advisories/CA-2002-17.html>; 2002.
30. Glaser T Busybox: integer overflow in expression on big endian. [Internet]. Available from: <http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=635370.>; 2011.
31. Perens B Busybox. [Internet]. Available from: <http://www.busybox.net>; 1996.
32. Bellard F. Qemu, a fast and portable dynamic translator. In: USENIX Annual Technical Conference, FREENIX Track. USENIX; 2005. p. 41–46.
33. CERT. Advisory CA-2002-08 Multiple vulnerabilities in Oracle servers. [Internet]. Available from: <http://www.cert.org/advisories/CA-2002-08.html>; 2002.
34. NIST. WFTPD Pro server denial of service. [Internet]. Available from: <http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2004-0342>; 2004.
35. MS Bulletin. Buffer overrun in JPEG processing (GDI+) could allow code execution. [Internet]. Available from: <http://technet.microsoft.com/en-us/security/bulletin/ms04-028>; 2004.
36. Grsecurity kernel patches. [Internet]. Available from: <http://grsecurity.net/>; 2013.
37. Zabrocki A. Scraps of notes on remote stack overflow exploitation. Phrack. 2010;13:63.