
Using Event Reasoning for Trajectory Tracking
Jianbing Ma, Bournemouth University, Bournemouth, UK
CCTV systems are broadly deployed in the present world. Despite this, the impact on anti-social and criminal behavior has been minimal. To ensure in-time reaction for intelligent surveillance, it is a fundamental task for real-world applications to determine the trajectory of any interested subject. However, precise video information for subjects (e.g., face information) is not always available, especially in zones without cameras. In these cases, we have to use event reasoning techniques to combine all kinds of dynamic information (e.g., video analytics, card reading results, etc.) as well as background information (e.g., topological information). This chapter hence proposes an event reasoning based framework for trajectory tracking. The main idea is to use inference rules to infer the passage of a subject when there is not enough dynamic information. We demonstrate the significance and usefulness of our framework with a simulation experiment, which shows better performance than using dynamic information only.
Keywords
rule inference; rule-based systems; event reasoning; trajectory tracking; intelligent surveillance
Information in this chapter
Introduction
During the past decade, there has been massive investment in CCTV technology in the UK. Currently, there are approximately four million CCTV cameras operationally deployed. Despite this, the impact on anti-social and criminal behavior has been minimal. Although most incidents, also called events, are captured on video, there is no response because very little of the data is actively analyzed in real time. Consequently, CCTV operates in a passive mode, simply collecting enormous volumes of video data. For this technology to be effective, CCTV has to become active by alerting security analysts in real time so that they can stop or prevent the undesirable behavior. Such a quantum leap in capability will greatly increase the likelihood of offenders being caught, a major factor in crime prevention.
To ensure in-time reaction for intelligent surveillance [1,2], one fundamental task to utilize CCTV videos is to track the trajectory of any subject of interest (e.g., [3,4], etc.). This trajectory knowledge is very powerful as an input to future reasoning, but even on its own it would allow us to augment traditional CCTV monitoring displays. For example, rather than just present a human operator with a live CCTV image of a subject, we could also augment the live feed with a series of key timestamped frames taken at other points in the facility.
Example
Consider a subject with the intent of leaving a suitcase with an explosive device in a crowded airport space and leaving before detonation. The CCTV operator is shown a live video feed of the subject exiting the airport through a recognized exit at time T. However, using our trajectory tracking, the live feed can also be supplemented with earlier footage of the subject entering the airport at time T - 4 minutes. Conceivably, the operator might also be shown a representation or map of the route taken by the subject through the space. Crucially, by comparing the images, the operator observes that the subject entered with a suitcase (from the archived frames) but left with no baggage (from the live frames). This could warrant an alert.
This example shows that the short-term historical details are extremely valuable to the human operator by putting a live feed into a wider context.
Key to the success of subject tracking is subject reacquisition [5]. That is, when we have detected a subject, we should be able to know who it is by retrieving from our subject database on past records. Currently, common approaches for subject acquisition are face recognition and clothing color signature classification, etc.
We should notice that in some testing scenarios, these methods can behave well, but they are facing major challenges in real application.
Face recognition can give a pretty precise result for cooperative subjects (that is, a subject looks at the camera for a few seconds with the face clearly exposed) within a small subject database. When the size of the subject database increases, there will be a considerable decline in the precision of face recognition, since the possibility that subjects with similar face features increases. This problem can be alleviated by improving face recognition algorithms. Clothing color signature method only applies when we assume that the subject does not change clothes while in the environment. Most importantly, pure video analytic approaches can be hard to apply or the results can be not enough to obtain a clear trajectory when there are not enough cameras or when some cameras have been tampered with.
While video analytics alone are not sufficient to obtain a clear trajectory, we are aware that there is usually more information that can be used in tracking, for example, (identity) card reading results, topological information about the environment, etc. These kinds of dynamic information (e.g., video analytics, card reading results, etc.) and background information (e.g., it takes a person 30 seconds to walk from location A to location B) can be combined by event reasoning [6,7] techniques.
The aim of this chapter is to successfully determine a subject’s passage through a series of monitored spaces, given the following scenario. Some spaces (called zones) have sensors capable of making observations about the physical location of a subject at a given time and observing key appearance signatures of a subject at a given time (facial features, clothing color, etc.). Some zones have no sensors. We have domain knowledge regarding the topology of connecting zones and we have expected time-of-flight information for subjects moving between zones. Access to some zones is protected by access control hardware. It should be noticed that this chapter focuses more on augmenting trajectory information by using background information than on computing accurate paths by some trajectory tracking efforts, such as in [8,9], etc.
To this end, in this chapter, event reasoning techniques are introduced to integrate information from various sources, for example, video analytics, card reading results, domain knowledge, etc. The main idea is to use inference rules to infer the passage of a subject when there is not enough dynamic information. Another focus of this chapter is how to obtain a precise identity of a subject.1 That is, when a subject is detected by a camera, how to classify it as one of a subject already in our database, since a camera can only detect a subject, not recognize a subject. Here the detector is a combination of the camera and the video analytics, while the recognition results follow the reasoning process.
In the literature, event reasoning systems have been proposed for dealing with event composition in many areas, such as those discussed in [10–13], etc. This chapter extends frameworks proposed in [10,11] to allow event functions. We also have simplification settings with respect to the frameworks in [10,11], especially for rule definitions. Subsequently, in the “Event Model” section, we introduce our event model. In the section titled “Scenario Adapts,” we adapt event settings with respect to the application practice. “Event Functions and Inference Rules” shows event functions and rules used in the application. Experimental results are provided in the “Experiments” section. In the summary, we conclude the chapter.
Event model
In this section, we introduce an event reasoning model that is a variant of the event reasoning framework proposed in [10,11] to adapt our scenario.
Event definition
In this chapter, we distinguish two kinds of events: observable events and domain events. An observable event is an occurrence that is instantaneous (event duration is 0, i.e., takes place at a specific point in time) and atomic (it happens or not). The atomic requirement does not exclude uncertainty. For instance, when there is a person entering a building who can be Bob or Chris based on face profiling, then whether it is Bob or Chris who enters the building is an example of uncertainty. But Bob (resp. Chris) is entering the building is an atomic event that either occurs completely or does not occur at all. To represent uncertainty encountered during event detection, in the following, we distinguish an observation (with uncertainty) from possible events associated with the observation (because of the uncertainty). This can be illustrated by the above example: an observation is that a person is entering the building and the possible observable events are Bob is entering the building and Chris is entering the building. An observation says that something happened, but the subject being observed is not completely certain yet, so we have multiple observable events listing who that subject might be.
This event definition is particularly suitable for surveillance, where the objects being monitored are not complete clear to the observer.
Event representation
A concrete event definition in this special application is defined as follows:
| occT: | the point in time that an event occurred |
| location: | the 3-D location that an event occurred |
| pID: | the classified person ID of that event |
| iID: | the information source ID that reports that event |
This format is specially designed for our subject tracking scanario. Here a subject is the human entity detected in the event. We don’t know who it is, so we should determine the subject’s identity by subject reacquisition (SR). However, SR techniques usually cannot provide us precise classification results; instead, it yields several possible candidates. As in this application, our dynamic information comes from either face recognition, clothing color recognition, pure localization, or card reading; iID hence can be one of the following values: {face, color, loc, card}. In addition, we will introduce a kind of inferred event, which also follows this definition, but its iID is infer.
Formally, we define an event e as: e=(occT, location, pID, iID).
Event cluster
Any two events with the same occT location, and iID are from the set of possible events related to a single observation. For example, e1=(20:01:00, 13.5/12.5/0, Bob, face) and e2=(20:01:00, 13:5/12.5/0, Chris, face) are two possible events from a single observation. To represent these, event cluster, denoted as EC, is introduced, which is a set of events that have the same occT, location, and iID, but with different pID values. Events e1 and e2 above form an event cluster for the observed fact that a subject is entering the building at 20:01:00 at location 13.5/12.5/0.
An event is always attached to a probability, and we use p(e) to denote the probability of e.
For an event e in event cluster EC, we use notations like e.occT to denote the time of occurrence of e, etc. By abuse of notations, we also write EC.occT to denote the time of occurrence of any event in EC, etc., since all the events in EC share the same values on these attributes.
Probabilities for events in an event cluster EC should satisfy the normalization condition: ![]() . That is, EC does contain an event that really occurred. For example, for the two events, e1 and e2, introduced above, a possible probability function p can be p(e1)=0.85 and p(e2)=0.15.
. That is, EC does contain an event that really occurred. For example, for the two events, e1 and e2, introduced above, a possible probability function p can be p(e1)=0.85 and p(e2)=0.15.
An event cluster hence gives a full description of an observed fact with uncertainty from the perspective of one source.
Event functions
Event functions are functions applied on events to get required results. For instance, a simple but useful function EC(e, e′) is a boolean function that determines whether two events e and e′ are in the same event cluster.
![]()
Some event functions are generic to any application (e.g., EC(e, e′)) while some event functions may only be proposed for special applications. To our knowledge, the notion of event functions has not been proposed by any event reasoning frameworks in the literature.
Event inference
Event inference is expressed as a set of rules that are used to represent the relationships between events. An inference rule R is formatted as:
Conditions can be evaluated by known information of current events and other assertions about the environment/situation. If all conditions are evaluated as true, then action1 can be taken, which usually sets values for some events or raises alerts, etc.. An example of the rule is as follows:
The conditions of this rule are that, at the same time but in different locations, there are two inferred events indicating that two subjects are the same person. Obviously this is impossible, so if all these conditions hold, an alert should be raised to the monitor.
Scenario adapts
In this section, we introduce the details of dynamic events generated in this scenario, including face or clothing color recognition events, localization events, and card reading events.
Video sensor observations generate observation events, and in the application these observations have the following primary attributes:
Face recognition, color histogram matching, and localization algorithms generate the following secondary attributes:
Here, an n-best list of matches means that a subject is being classified as several candidate persons, with associated probabilities derived by video analytic algorithms (namely face recognition algorithm, color matching algorithm, etc.). For instance, a subject can be classified as: Bob with probability 0.65, Chris with probability 0.2, and David with probability 0.15. Note that either an n-best list of face matches or an n-best list of color matches generates an event cluster.
Overall, we find that these resulted events by algorithms can be described by our event definition given previously. That is, we have occT , location (real world), pID (each taken from the n-best lists), and iID (face or color), which perfectly matches our event definition. In addition, these events are attached with probabilities.
In practice, for the sake of computational efficiency, we cannot afford always recording facial or clothing color information and applying corresponding algorithms. Hence, most of the time, we only apply localization sensing that records only the location of a subject. The ratio of facial/color recognition events and pure localization events are about 1:5 to 1:10, etc. A localization event has the following primary attributes:
A localization event can generate the following secondary attributes:
Since the ratio of facial/color recognition events and pure localization events are about 1:5 to 1:10, etc., we can always find a nearest facial/color recognition event cluster with the same subject ID. As there can be two closest event clusters (i.e., one for face recognition and the other for clothing color), we select the event cluster that contains a greatest probability. After obtaining the closest n-best matches, the localization events form an event cluster. For example, if the two nearest event clusters are: e1=(20:01:00, 13.5/12.5/0, Bob, face) with probability 0.85, e2=(20:01:00, 13.5/12.5/0, Chris, face) with probability 0.15, and e′1=(20:01:00, 13.5/12.5/0, Bob, color) with probability 0.55, e′2=(20:01:00, 13.5/12.5/0, David, color) with probability 0.45, then the localization event cluster will take the face matching results as its n-best list of matches for the events in the event cluster.
Access control events, or card reading events, have the following attributes:
Secondary attributes of this event are:
• A user identity (name of the card owner)
• Other employee details; however, we should ignore these in this case for clarity.
For a card reading event, we will set its subject ID sID to a special value, ANY, which matches any subject ID. Therefore, we also have the required occT, location, sID, pID, and iID values. The probability is 1.
Environment topological information, or more generally, background information (also called domain knowledge), is seen mostly about the expected time-of-flight information for subjects moving between zones; that is, the time a person took to go from one zone to another. For instance, a person cannot appear within zone A and then appear in zone B within 10 seconds. But if the 10 s is changed to 10–20 seconds, then it could be possible; if the time-of-flight is 20–40 seconds, it is highly possible; if the time is greater than 40 seconds, it is possible, etc. Empirical probabilities for such information can be found by tests. However, we will use simple settings that in some special range of time-of-flight, the certainty is 1 instead of probabilities.
Assumptions
Our ultimate objective aims at complicated environments. However, initially, we will begin with simple scenarios with simplification assumptions. Complexity can be incrementally increased. This process clarifies our objective. Some initial assumptions are listed below:
• Only one subject shall be considered (no occlusions, etc.).
• The subject will be cooperative at key points (i.e., look into the camera for a few frames).
• The subject will not change clothing for the duration of the scenarios.
• The subject swiping the access card can be assumed to be the registered owner of the card (i.e., not stolen or cloned).
Event functions and inference rules
In this section, we introduce the event functions and inference rules used in this application.
First, we define some useful event functions. The next event with the same classified person is defined as:
![]()
Here recall that “infer” is the iID of an inferred event.
Given the Next(e) function, similarly, a Prev(e) function that obtains the very previous event of e with the same subject can be defined as:
![]()
Note that Prev(e) only defines for dynamic events. It is not defined for inferred events.
We also define a local function Neighbor(e, e′) to judge whether e and e′ are neighbors with respect to space and time.
![]()
Here, dis is a measure of distance between two locations.
The following function judges whether e is the very last event that appears on ground floor. That is, any event exactly next to it is not on ground floor.
![]()
Here GROUNDFloor is a predefined application constant. Note that this function is a special one for this application.
Another important event function is to create an event.
![]()
Note that only inferred events can be created. Based on the dynamic (video, card information, etc.) information and background information, we can set up rules to infer which person it is.
First, we list rules for inferring a KnownSubjectAcquired event, which is a special kind of event used for indicating the most possible candidate of a subject. The iID value of a KnownSubjectAcquired event e=(occT, location, pID, iID) is set to infer. Also note KnownSubjectAcquired events are not attached to an event cluster.
Rules for inferring KnownSubjectAcquired events are listed as follows:
• If e1.iID ≠ infer and p(e1)>0.5 and / ∃e2 (EC(e1; e2) ∧p(e1)−p(e2)<0.3) , then Create(e1.occT, e1.location, e1.pID, infer, p(e1)).
• If e1.iID=card, then Create(e1.occT, e1.location, e1.pID, infer, 1).
• If e1.iID=infer and e2.iID ≠ infer and Neighbor(e1,e2) and e1.pID=e2.pID and e2.pID>0.5, then Create(e2.occT, e2.location, e2.pID, infer, p(e2)).
• If e1.iID=infer and e2.iID=infer and Neighbor(e1,e2) and e1.pID ≠ e2.pID and p(e1)>p(e2) and ∃e3((e3=Prev(e1)∨e3=Next(e1))∧e3.occT=e2.occT∧e3.location=e2.location), then e2.pID=e1.pID, p(e2)=p(e1).
Note that rule 1 implies that if a dynamic event has an associated probability of at least 0.65, then it must satisfy conditions of rule 1. Rule 2 takes advantage of no-stolen and no-clone assumption of cards. Rule 3 indicates that if some subject has been reacquired, then the subject in the neighbor event is also him/her. This rule makes use of the one-subject-at-a-time assumption and is shown satisfied, in most cases. Also, it is proved very useful and powerful in reasoning. Rule 4 is used to resolve inconsistency. That is, if two neighbor events provide different classifications, then the more reliable one should be respected.
There are also rules for inferring KnownSubjectAcquired events that use background knowledge. For instance, we use event reasoning rules to judge whether a person takes a lift or goes from the stairway when he is found at the first floor.
• If e1.iID ≠ infer and dis(e1.location, LIFTLocation)<1 m and e1.pID=e2.pID and e1.location.z=GROUNDFloor and e2.location.z=FIRSTFloor and 0<e2.occT−e1.occT<5 sec, then Create((e1.occT+e2.occT)/2, INLIFT, e2.pID, infer, 1).
If e1.iID ≠ infer and GroundLast(e1) and e1.pID=e2.pID and e1.location.z=(GROUNDFloor and e2.location.z=FIRSTFloor and e2.occT−e1.occT>10 sec, then Create ((e1.occT+e2.occT)/2, INSTAIR, e2.pID, infer, 1).
• If e1.iID≠infer and GroundLast(e1) and e1.pID=e2.pID and e1.location.z=GROUNDFloor and e2.location.z=FIRSTFloor and 8<e2.occT−e1.occT <=10 sec and dis(e1.location, STAIRLocation)<1 m, then Create ((e1.occT+e2.occT)/2, INSTAIR, e2.pID, infer, 1).
• If e1.iID ≠ infer and e1.iID ≠ infer and e1.pID=e2.pID and dis(e1.location, WCLocation)<1 m and dis(e2.location,WCLocation)<1 m and e2.occT−e1.occT>60 sec and e2=next(e1), then Create((e1.occT+e2.occT)/2, INWC, e2.pID, infer, 1).
Here LIFTLocation, FIRSTFloor, INLIFT, WCLocation and INWC are predefined application constants. The first rule says if a subject first appears on the ground floor and then is detected at the first floor within five seconds, then the subject must have taken a lift. The second and third rule indicate how to judge whether the subject uses the stairway to go to the first floor. The last rule tells that if a subject goes to and leaves the WC (the lavatory) for one minute and does not appear anywhere during that period, then the subject must be in the WC. In addition, similar rules can be set up for subjects who go down from the first floor, etc.
There can be many such rules using topological and time-of-flight information of the environment.
There are also rules for inferring inconsistencies between events. Usually, an inconsistency indicates a potential system failing and warranting investigation. An example rule is:
If e1.iID=infer and e2.iID=infer and e1.pID=e2.pID and dis(e1.location; e2.location)>10 * abs(e1.occT−e2.occT), then RaiseAlert.
Here RaiseAlert is a system function to alert the monitor, or it just acts as a report of system failure.
A trajectory can be set up by tracing KnownSubjectAcquired events, which provides more information than video analytic results.
The system architecture is shown in Figure 16.1.
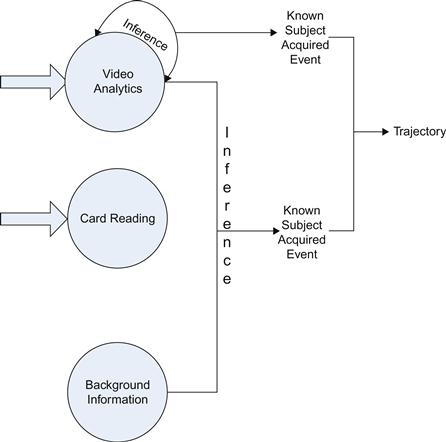
Experiments
We demonstrate our system by the following scenario, showing that we can infer trajectories of subjects even if we do not have clear images in some zones. This experiment scenario shows that our method can be used to enhance security.
Consider: five subjects sequentially enter a building, with their faces (as our cooperative subject assumption) detected, analyzed, and recognized (with a high certainty). They move in, with only their clothing color signature being detected (with a medium or low certainty). After some time, they are detected on the first floor. They swipe their cards and go to their offices, which are captured by cameras in the corridors. They go to the WC occasionally. Finally, they leave the building.
Video analytics only provide clear information when the subjects are cooperatively looking at the cameras, and card reading can only prove the identity of the card owner at the moment of card swiping. However, even for cooperative subjects, sometimes video analytic algorithms make wrong classifications. Figures 16.2, 16.3, and 16.4 show some video dynamic information on face recognition and clothing color signature.



In this experiment, we compare the clear information provided by dynamic information only, and by our event reasoning systems.
For this experiment, the performance is characterized by the true positive rate: TPR=N/NPR, where NPR is the number of pieces of clear information in which the subject has been correctly classified and N is the total number of pieces of clear information in which the subject is classified.
We applied the methods on the scenario previously proposed. The comparison results are presented in Table 16.1.

The generated dynamic events include 5 card reading events, 10 face recognition events at the ground floor, 5 face recognition events at the first floor, and 20 clothing color recognition events, of which there are 8 mis-classifications. The generated 348 pieces of clear information include 40 dynamic events, 280 localization events (ratio 1:7), 10 subject going up events, 10 subject going down events, and 8 WC events, in which the mis-classification events are due to the original video mis-classification. But some mis-classifications are fixed by rule 4 proposed in the above section.
From Table 16.1, we can see that an event reasoning system provides much more clear information about the trajectory of the subject. It is not surprising because, with event reasoning, we can provide clear information for localization events and other tracking events when there are no cameras (e.g., the subject is in WC, etc.). We can also see that the event reasoning system gives an increase of approximately 11 percent in TPR compared to that provided by dynamic information only. This is because the mis-classification of cooperative subjects can be corrected by neighbor classifications.
Summary
In this chapter, we propos an event reasoning system which can help to track the trajectory of subjects. We set up rules to infer which subject is seen based on uncertain video analytic results. We also infer the position of subjects when there is no camera data by using topological information of environments. This framework has been evaluated by a simulated experiment, which shows a better performance than using video analytic results only.
We find that the advantage of using event reasoning in these scenarios are two-fold:
• Event reasoning helps to determine which subject is tracked when we have uncertain video analytic results.
• Event reasoning helps to determine the route the subject passes when we have no video analytic results.
For future work, we want to extend this event reasoning model to include the expression of incomplete information using probability theory (induced from combining knowledge bases [14,15]) or Dempster-Shafer theory [16–19]. Also, we need to consider cases where a combination of some uncertain results can provide more certain results. In addition, we will gradually loosen our assumptions to allow multiple subjects to appear at the same time, allow non-cooperative subjects, allow unreliable card information, etc. Furthermore, situation calculus [20,21] can be used to keep a record of the events. Belief revision [22–27] and merging [28–31] techniques for uncertain input can also be considered in our framework.
Acknowledgments
This research work is sponsored by the EU Project: 251617 (the INFER project) and EPSRC projects EP/D070864/1 and EP/G034303/1 (the CSIT project).
References
1. Liu W, Miller P, Ma J, Yan W. Challenges of distributed intelligent surveillance system with heterogenous information. Procs of QRASA CA: Pasadena; 2009; p. 69–74.
2. Miller P, Liu W, Fowler F, Zhou H, Shen J, Ma J, et al. Intelligent sensor information system for public transport: To safely go … In: Procs of AVSS; 2010.
3. Jiang X, Motai Y, Zhu X. Predictive fuzzy logic controller for trajectory tracking of a mobile robot. In: Procs of IEEE Mid-Summer Workshop on Soft Computing in Industrial Applications; 2005.
4. Klancar G, Skrjanc I. Predictive trajectory tracking control for mobile robots. In: Proc of Power Electronics and Motion Control Conference; 2006. p. 373–78.
5. Ma J, Liu W, Miller P. An improvement of subject reacquisition by reasoning and revision. In: Procs of SUM; 2013.
6. Ma J, Liu W, Miller P. Evidential fusion for gender profiling. In: Procs of SUM; 2012. p. 514–24.
7. Ma J, Liu W, Miller P. An evidential improvement for gender profiling. In: Procs of Belief Functions; 2012. p. 29–36.
8. Corban E, Johnson E, Calise A. A six degree-of-freedom adaptive flight control architecture for trajectory following. In: AIAA Guidance, Navigation, and Control Conference and Exhibit; 2002. AIAA-2002-4776.
9. Ahmed M, Subbarao K. Nonlinear 3-d trajectory guidance for unmanned aerial vehicles. In: Procs of Control Automation Robotics Vision (ICARCV); 2010. p. 1923–7.
10. Wasserkrug S, Gal A, Etzion O. Inference of security hazards from event composition based on incomplete or uncertain information. IEEE Transactions on Knowledge and Data Engineering. 2008;20(8):1111–1114.
11. Ma J, Liu W, Miller P, Yan W. Event composition with imperfect information for bus surveillance. Procs of AVSS IEEE Press 2009; p. 382–7.
12. Ma J, Liu W, Miller P. Event modelling and reasoning with uncertain information for distributed sensor networks. Procs of SUM Springer 2010; p. 236–49.
13. Han S, Koo B, Hutter A, Shet VD, Stechele W. Subjective logic based hybrid approach to conditional evidence fusion for forensic visual surveillance. In: Proc AVSS’10; 2010. p. 337–44.
14. Ma J, Liu W, Hunter A. Inducing probability distributions from knowledge bases with (in)dependence relations. In: Procs of AAAI; 2010. p. 339–44.
15. Ma J. Qualitative approach to Bayesian networks with multiple causes. IEEE Transactions on Systems, Man, and Cybernetics. 2012;42(2 Pt A):382–391.
16. Ma J, Liu W, Dubois D, Prade H. Revision rules in the theory of evidence. In: Procs of ICTAI; 2010. p. 295–302.
17. Ma J, Liu W, Dubois D, Prade H. Bridging Jeffrey’s rule, AGM revision and Dempster conditioning in the theory of evidence. Int J Artif Intell Tools. 2011;20(4):691–720.
18. Ma J, Liu W, Miller P. A characteristic function approach to inconsistency measures for knowledge bases. In: Procs of SUM; 2012. p. 473–85.
19. Ma J. Measuring divergences among mass functions. In: Procs of ICAI; 2013.
20. Ma J, Liu W, Miller P. Belief change with noisy sensing in the situation calculus. In: Procs of UAI; 2011.
21. Ma J, Liu W, Miller P. Handling sequential observations in intelligent surveillance. In: Proceedings of SUM; 2011. p. 547–60.
22. Ma J, Liu W. A general model for epistemic state revision using plausibility measures. In: Procs of ECAI; 2008. p. 356–360.
23. Ma J, Liu W. Modeling belief change on epistemic states. In: Procs of FLAIRS; 2009.
24. Ma J, Liu W. A framework for managing uncertain inputs: An axiomization of rewarding. Int J Approx Reasoning. 2011;52(7):917–934.
25. Ma J, Liu W, Benferhat S. A belief revision framework for revising epistemic states with partial epistemic states. In: Procs of AAAI; 2010. p. 333–8.
26. Ma J, Benferhat S, Liu W. Revising partial pre-orders with partial pre-orders. A unit-based revision framework 2012.
27. Ma J, Benferhat S, Liu W. Revision over partial pre-orders: A postulational study. In: Procs of SUM; 2012. p. 219–32.
28. Ma J, Liu W, Hunter A. The non-Archimedean polynomials and merging of stratified knowledge bases. In: Procs of ECSQARU; 2009. p. 408–20.
29. Ma J, Liu W, Hunter A. Modeling and reasoning with qualitative comparative clinical knowledge. Int J Intell Syst. 2011;26(1):25–46.
30. Ma J, Liu W, Hunter A, Zhang W. An XML based framework for merging incomplete and inconsistent statistical information from clinical trials. In: Soft Computing in XML Data Management; LNAI; 2010. p. 259–90.
31. Ma J, Liu W, Hunter A, Zhang W. Performing meta-analysis with incomplete statistical information in clinical trials. BMC Med Res Methodol. 2008;8(1):56.
1It is called “subject reacquisition” in the video analysis community. In this chapter, subject determined by inference is somehow beyond this meaning. But for simplicity, we will still call it subject reacquisition.