
On the Use of Unsupervised Techniques for Fraud Detection in VoIP Networks
Yacine Rebahi1, Tran Quang Thanh1, Roman Busse1 and Pascal Lorenz2, 1Fraunhofer Institute for Open Communication Systems (FOKUS), Berlin, Germany, 2University of Haute Alsace, Colmar, France
In traditional telecommunication networks, fraud is already a threat depriving telecom operators of huge amounts of money every year. With the migration from circuit-switched networks to packet-switched networks, it is expected that this situation will worsen. In this chapter, we present an unsupervised learning technique for classifying VoIP subscribers according to their potential involvement in fraud activities. This technique builds a signature for each subscriber to describe his or her typical behavior. Then the signature is used as a basis for comparison as it evolves over time. An implementation prototype of this technique was developed and assessed against real-life data delivered by a VoIP provider. The results were proven reasonable by comparing this technique to another unsupervised method, namely the Neural Network Self Organizing Map (NN-SOM).
Keywords
VoIP; fraud; signatures; NN-SOM; unsupervised learning
Information in this chapter
Introduction
Various definitions of fraud are reflected in the literature. However, fraud can simply be seen as any activity that leads to obtaining financial advantage or causing loss by implicit or explicit deception. In traditional telecommunication networks, fraud is already a threat depriving telecom operators of huge amounts of money every year. With the migration from circuit-switched networks to packet-switched networks, this situation can be expected to worsen. This is mainly due to the lack of strong built-in security mechanisms and the use of open standards in IP-based networks. Based on a 2011 survey, the Communication Fraud Control Association (CFCA) reports that telecom fraud costs businesses more than $40 billion every year [1].
Unfortunately, the problem of detecting fraud in telecom in general and in Voice over IP (VoIP) in particular is very difficult. Supervised classification techniques can be useful if a training sample of data with fraud labels is obtained. A training sample is required in standard supervised techniques to help the system learn the fraud cases. In reality, it is costly and sometimes impossible to obtain a training sample with unambiguous fraud labels [2].
In telecommunication, Call Data Records (CDRs) are the type of data usually used for fraud investigation. Unfortunately, CDRs are not enough, and the fraud management expert needs to look into the customer’s data (service subscription, number of persons using the service, etc.) as well. On the other hand, the use of CDRs is not straightforward. The expert has to prepare the CDRs data, which means: separating business accounts from residences accounts; identifying which accounts can be reached from outside and which ones cannot (similar to private IP addresses); and identifying non-real accounts which are just accounts used to test whether the VoIP components are alive or not. The testing accounts usually generate huge traffic, which can lead to confusion. From these comments, it is clear that building an effective training sample requires deep knowledge in VoIP and a lot of time. In addition, even if such a sample is produced, it can be subject to classification errors that will affect the developed model. Moreover, to avoid to be detected, fraudsters frequently change their behavior, which can certainly reduce the effectiveness of the supervised developed model.
For these reasons, we believe that building a Fraud Management System (FMS) based only on expert knowledge and supervised techniques is not effective enough. We also believe that unsupervised techniques that do not require knowledge of fraud labels for a subset of data can be applied to VoIP fraud detection, and that the corresponding results can complement the results obtained with supervised models. This approach is being explored in the SUNSHINE [3] project.
This chapter is organized as follows: The next section provides the background needed for understanding the subsequent sections. It includes an overview of VoIP, a taxonomy of VoIP fraud, and an overview of the state of the art. The subsequent section explains our design of the signature-based technique, including aspects such as dealing with data fluctuation, comparison between short-term and long-term signatures, and signature initialization and update. In the final section, we discuss the performance and effectiveness of the proposed technique.
Background
Voice over IP (VoIP) technologies
VoIP is a set of technologies enabling voice calls to be carried over the Internet. Distinguishing it from the traditional telephone system—the Public Switched Telephone Network (PSTN) —what drives the use of the VoIP technology is the very low cost and free voice calls, as well as VoIP’s ability to converge with other technologies, in particular, presence and instant messaging, which in turn can result in new services and applications.
A number of protocols can be employed to provide VoIP communication services; however, the Session Initiation Protocol (SIP) [4] has rapidly gained widespread acceptance as the signaling protocol of choice for fixed and mobile Internet multimedia and telephone services. SIP is an application-layer control protocol that allows users to create, modify, and terminate sessions with one or more participants. It can be used to create two-party, multiparty, and multicast sessions that include Internet telephone calls, multimedia distribution, and multimedia conferences.
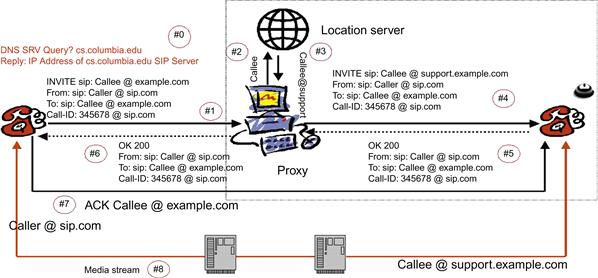
In SIP (see Figure 22.1), a user is identified through an SIP-URI in the form of user@domain. This address can be resolved to a SIP proxy that is responsible for the user’s domain. To identify the actual location of the user in terms of an IP address, the user needs to register his or her IP address at the SIP registrar responsible for his or her domain. Thereby, when inviting a user, the caller sends his or her invitation to the SIP proxy responsible for the user’s domain, which checks in the registrar’s database the location of the user and forwards the invitation to the callee. The callee can either accept or reject the invitation. The session initiation is finalized by the caller’s acknowledging the reception of the callee’s answer. During this message exchange, the caller and callee exchange the addresses where they would like to receive the media and indicate what kind of media they can accept. After the session has been established, the end systems can exchange data directly without involving the SIP proxy.
Call data records
Every time a call is placed on a telecommunication network, descriptive information about the call is saved as a Call Data Record (CDR). Millions of CDRs are generated and stored every day. In addition, at minimum, each Call Data Record has to include the originating and terminating phone numbers, the date and time of the call, and the duration of the call. The CDRs might also include other kinds of data that are not necessary but are useful for billing, for instance, the identifier of the telephone exchange writing the record, a sequence number identifying the record, the result of the call (whether it was answered, busy, etc.), the route by which the call entered the exchange, any fault condition encountered, and any features used during the call, such as call waiting. An example of CDRs made available by a VoIP provider and used for testing (see the final section for more details) include the fields: Time (the start time of call); SIP Response Code: 2xx, 3xx, 4xx, 5xx or 6xx; SIP Method: INVITE (mainly); User-name (From URI); To URI; To-Tag; From-Tag; User-Agent; Source IP; RPID (Remote Party ID); and Duration.
VoIP Fraud detection taxonomy
Fraud can be classified in different ways according to the point of view from which the related activities are observed. However, the categorization generally cited in the literature is the following:
• Subscription fraud: Someone sets up an account or service, often using false identity details, without the intention of paying. The account is usually used for selling calls or intensive personal use.
• Superimposed fraud: Someone illegally obtains resources from legitimate users by gaining access to their phone accounts. This kind of fraud can be detected by the appearance of unknown calls on the bill of the compromised account. Scenarios involving this kind of fraud include mobile phone cloning, breaking into a PBX system, etc.
Based on what we have discussed in this section, we would like to add to the subscription fraud category activities in which the service usage does not match the subscription type, a type of fraud that can cause a substantial damage to VoIP providers. For instance, some customers subscribe to a residential service, which is usually cheaper than a business service, and use it for business purposes.
Another example is where the customer chooses to uses the customer’s own PBX and then uses this PBX as a dialer for call center purposes. A dialing system in a call center dials more calls than the number of employed agents, usually at a ratio of one call and half or two calls per agent. This means that for 100 agents logged on, the system will place 150 (or 200) outbound calls. Then the dialing system will monitor each call and determine its outcome. From the 150 (or 200) calls made, the system will discard busy calls, calls with no answers, calls ending at answering machines, and calls with invalid numbers. If a call is apparently being answered by a person, it will be passed through to an agent. On the infrastructure side, this service abuse appears as a Denial of Service (DoS) attack, affecting the VoIP provider’s network and reducing its capacity. The seriousness of this situation depends on the capacity of the SIP trunk and how often the operation is repeated.
Another kind of abuse, which does not fit the subscription type, is when the customer uses the provider infrastructure to build a subscriber database that can be sold to marketing companies. For instance, some customers look for operational mobile accounts by trying to connect to them without establishing the calls. They determine whether the targeted mobile accounts are operational or not based on the provisioning response messages.
The fraud cases just described are based not on theoretical brainstorming but on real observations reported by several VoIP providers. Unfortunately, the VoIP provider cannot know the device that is installed on the customer’s premises or the purpose for which it is being used. Moreover, the VoIP provider who has hundreds of thousands of customers cannot easily check the installations related to all these accounts.
Related work
The diversity of fraud activities in telecommunication in general and in VoIP in particular has made the detection of such misbehaviors a difficult task. Most of the telecom operators and VoIP providers currently rely on simple rule-based systems for reviewing customers’ activities. The rule-based system defines fraud patterns as rules [5]. The rules might consist of one or more conditions. If all the conditions are met, an alarm is produced. These rules are usually developed as a result of investigations of past fraudulent activities. In addition, they tend to be very basic, consisting of simple threshold conditions on some features of the service subscription.
To the best of our knowledge, the use of more sophisticated technologies in telecom fraud detection is still in a research phase [5–8]. This is mainly because the new technologies are based on data mining and pattern recognition, which often require skills that the operators and VoIP providers do not have. As the convergence between telecom networks and the Internet continues (under the name of VoIP or Next Generation Networks [NGN]) and a lot of telecom services are being replaced by similar IP-based services, applying data mining techniques to the IPDRs data when investigating fraud may become more attractive. An IP Detail Record (IPDR) [9] provides information about Internet Protocol(IP)-based service usage and other activities. It targets emerging services such as VoIP, CableLabs DOCSIS, WLAN access services, and streaming media services. The use of IPDRs in fraud detection was investigated by [10] (and also [11] in the context of rule-based systems), suggesting a high-level model for NGN fraud detection. Unfortunately, the use of IPDRs is very limited, and most VoIP providers still rely on traditional CDRs. This has led us to stick to the use of CDRs for our fraud activity investigations.
Data mining falls into two categories: supervised and unsupervised learning. The former makes use of extensive training using labeled data classes of both fraudulent and non-fraudulent cases. This training data is used to develop a model for discovering new cases that can be classified as legitimate or fraudulent. The use of supervised techniques was not an option for us due to the difficulty of obtaining training data and other reasons discussed earlier in the introduction.
Contrary to the supervised methods, unsupervised techniques can be used even when we are not certain which transactions in the database are fraudulent and which are legal. These techniques are based on "profile/signature" [6] or "normal behavior" ([7,8]), in which the past behavior of the user is collected in order to build a profile used to predict the user’s future behavior. Since this profile describes the user’s habitual service usage pattern of the user ("normal behavior"), any significant deviation from this profile is reported because it might hide fraudulent activity. A signature is a statistical description or a set of features that captures the user’s typical behavior, namely, the average number of calls, times of the calls, areas where the calls are made, number of calls during work hours), and number of calls at night [8].
This chapter discusses the development of a signature-based technique for VoIP fraud detection. Although signatures or profiles (in other words. anomaly detection) have been extensively discussed in the literature in the context of intrusion detection [12–14], the use of this technique in telecommunication is still limited [6–8]. In addition, the current use of this method in telecom fraud detection does not take into account several aspects. including the business plans of the VoIP providers. What it has been discussed in the literature ([6,8]) is the generation of one profile with different types of features. Unfortunately, evaluating such approaches is not easy task in the absence of sufficient detail (in the literature, enough detail is provided about how the proposed techniques were developed). We also believe that such anapproach leads to performance problems, especially as the signature gets bigger. We also believe that using global metrics for comparison (such as the Hellinger distance [15]) leads to loss of information about individual features. This means it is difficult to know which feature led to the misbehavior.
Our work uses the z-score model [16] for each feature of the signature, as it shows the impact of this feature on the entire signature. In addition, and contrary to the solutions already proposed in the literature, we use various profiles instead of a single complex one, as it is easier to manipulate them separately. (The profile discussed in this chapter is related to user calls. We have also developed another one related to used IP addresses and their geolocation).
When computing the signature, we account for data fluctuation in the use of service, which varies from one day to another including periods of inactivity in which the subscriber did not use the service. Our solution also investigates how the signatures can be initialized and updated, based on the related specification.
Signature-based fraud detection
In this section, we describe how we implement a subscriber’s signature. In short, it is defined as a set of the following features:
• Total number of calls per period of time, dividing the day to four intervals
• Number of calls to premium numbers
• Number of calls to international destinations
The number of calls to premium, international, and mobile destinations are also divided into four intervals similar to the ones mentioned for "Total number of calls." These features were chosen because they usually reflect calls that are relatively expensive, which makes them possible targets for fraudsters.
Activities per day
The signature features implemented are the ones described above. If we take, for instance, the number of calls for the period of time 06am–12am, this value is computed on a daily basis. Table 22.1 shows a simple example where the long-term signature is calculated over 10 days, and the values reflect the number of calls within the mentioned period of time.
This example reflects normal usage for a given user. The value 70 (on day 7) is an example of how usage data might fluctuate.
Dealing with data fluctuation
In our work, the statistical metrics used to describe the service usage of a given user are the mean and the standard deviation. One problem with using the mean is that it often does not show the typical behavior. Data fluctuation can severely affect the signature computation. To mitigate its impact on the signature, we divided the week into groups of days, the time into several time slots, and the call duration into several smaller time windows. However, this might not be sufficient. To clarify this issue, let us consider Table 22.1: if one value (like the 70 on Day 7) in the user activity is very far from the rest of the data, then the mean will be strongly affected by that value. Such values are called outliers.
An alternative measure, resistant to outliers, is the trimmed mean, which is the mean after getting rid of the smallest and biggest values of the list describing the activity. In our case, we removed 5 percent of the values from both ends of the list. To compute the trimmed mean, we needed to sort the list into an increasing order. From Table 22.1 we got the following sequence:
![]()
Another issue is the existence of periods of inactivity (reflected by the 0 values), which can also affect the computation of the mean. Fraud is usually perpetrated for profit purposes, reflected in excessive use of the service through a fraudulent subscription or fraudulent activities using a legitimate account. As inactivity means no losses, considering the periods of inactivity in computing the mean does not yield any valuable information for fraud detection. As a consequence, we only need to compute the mean for the values of the list that are different from 0.
![]()
Five percent of the length of this sequence is 0:35. By rounding this value to 1, we remove the first and the last values of this list. In this case, the mean and the standard deviation are as follows:
![]()
![]()
Comparison of long-term and short-term signatures
In order to compare the user’s historical and current behaviors, we need a distance metric. In our case, the current behavior (the short-term signature) is computed every day. The values obtained for the short-term signature features, described above, can be compared to the means of the values of the same features of the user’s historical behavior (the long-term signature). If these values do not belong to the confidence intervals related to the computed means, the user’s activity appears suspicious and an alarm is sent. This comparison technique is also called the z-score test in the literature [16].
The confidence interval is reflected by the value "α*stdi" where α is a real number greater than 1 that can be tuned based on the testing activities, while (stdi) denotes the standard deviation related to the ith feature of the long-term signature. This solution can be extended to instances where the short-term signature counts more than one day. In this case, we do not compare the related values to the means of the same features belonging to the long-term signature; rather, we compare the means related to the same features in the long-term and short-term signatures.
Signature initialization
New users might also be fraudsters. This means they have to be monitored right after they start using the service. To build a reliable profile for a user, we need to observe the person’s behavior for some time (a week, a month, etc.). However, this does not apply to users who have just signed up for the service. Typical subscription fraud behavior is the excessive usage of an account or a subscription in a very short time interval, which enables the fraudster to escape the detection.
It turns out that signature initialization is an important step in detecting and preventing subscription fraud. However, signature initialization is a challenging task due to the very limited data about new subscribers.
Dealing with a new subscriber relies on the signature technique that we have already discussed, in which the user’s service usage is mainly described by the mean and the related standard deviation. In addition, the signature is updated on a per-day basis. As a consequence, a new subscriber can be observed over two days; if no fraudulent activity is found, requiring interruption of the service, the new user is assigned a signature in the manner discussed earlier. In general, the mean and the standard deviation for each feature can be computed over two days but not over one day. However, it is also possible to monitor the new user over one day (instead of two days); however, this requires some changes in the implemented signature itself.
Observing the new subscriber for the first two days involves looking particularly for whether this subscriber
• has made at least one international call (or a premium call) with a duration greater than a predefined threshold, or
• has made a call to a destination on the black list. (We assume that the VoIP provider maintains a list of phone numbers or account IDs of subscribers who have committed fraud.)
A subscriber who engages in either of these activities is labeled as suspicious and is monitored closely during the mentioned two days.
Signature update
As the user’s activities are tracked on a daily basis, updating the user’s signature is straightforward. The values related to the first day in the long-term signature are discarded, and the values generated by the short-term signature are considered in the calculation of the long-term signature being updated. This is achieved as described in the beginning of this section. For instance, the earlier example, yielded the following:
![]()
![]()
The same user’s activities during days 11 and 12 are shown by the values in Table 22.2.
If we assume that the confidence interval has a length of 2*std=9.9, we can note that (24–23)=1<9.9; this means that the value for Day11 is not an outlier. Updating the signature in this case works as before: we sort the values from Day2 to Day11, remove the inactivity periods, and compute the trimmed mean. This yields:
![]()
![]()
If we assume that the confidence interval has a length of 2.std=9.32, we can note that 35–23.8=11.2>9.32; this means the value for Day12 is an outlier.
Experiments
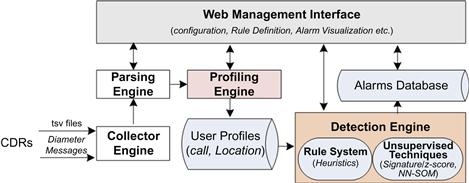
To handle the testing activities, a testbed was set up (see Figure 22.2). This testbed is a part of the Fraud Management System being developed as a part of the SUNSHINE project [3]. Some of the components of the testbed are discussed in this section.
Data used for testing
To test our algorithms, we used real-life data provided by a VoIP provider. The data consisted of three months of CDRs dating from the January 1, 2011 to the end of March 2011. The data belonged to 4,825 subscribers, who generated almost 31 million CDRs during these three months. The CDRs were provided in a tsv file, which required the development of a parser module, using parallel processes, to parse the information in the file and store it in a relational database within a reasonable period of time.
Known fraudulent cases
The VoIP provider offered a list of 17 accounts that seemed to be compromised and from which fraudulent activities were committed during this three-month period. Most of the fraudulent activities were detected by the VoIP provider because the users in question exceeded a virtual threshold set by the VoIP provider, or because calls were made to unusual destinations. Other scam activities were detected (by chance) while checking the logs of some network monitoring components.
Call center behavior
As mentioned in the section titled “Background,” call center activities can be considered a kind of fraud when these activities do not respect the subscription agreement. Unfortunately, VoIP providers do not have a means to deal with such an issue. This fact pushed us to investigate how the unsupervised techniques could be utilized to detect such activities. The first step in this direction was to define some heuristics to classify the data into potential call centers and non-call centers. The heuristics we used related to the total number of calls, the success rate, and the IP addresses’ geolocation, as discussed later in the chapter. Other filtering criteria could be considered, such as the number of calls made during nights and on weekends. These numbers should be very small, as call centers are businesses, so they are often not active during these times—although this is not always true, since the VoIP provider might have business with other countries on other continents which requires taking into account the time offset between these countries. We used the following heuristics for classification:
• The total number of calls made from a given account is greater than 100 per day, and this happened at least three times during the three months.
• The call success rate is less than 60 percent.
• For a given account the geolocation does not change (in other words, the IP addresses used by this account remain in the same network). To achieve this, the IP geolocation database from MaxMind [17] was integrated into our system.
These criteria allowed us to generate a list of 69 potential call centers, representing 1.43 percent of the accounts used in the tests. This sounds reasonable because the scam-related data is usually a small portion of all the data. The heuristics were defined with the help of the VoIP provider. The list of potential call centers was also reviewed by the VoIP provider. who confirmed that the subscription accounts figuring on this list were call centers.
Signature-based technique testing
Before assessing the signature-based technique, it is worth mentioning that we cannot be certain, based only on statistical analysis, that fraud has been committed. Unsupervised techniques, in particular, profiling and clustering, should be regarded as a means for producing warnings of cases that need deeper investigation.
The signature-based technique was evaluated against two categories: known fraud cases and the call center behavior. To test its performance, we built for each user a short-term signature representing his or her daily activities as discussed in the preceding section. The short-term signatures were collected on a 30-day basis to generate long-term signatures (see the preceding section). In other words, the first long-term signature started on January 1 and ended on January 30. Then, a comparison was made with the short-term signature reflecting the activities on January 31. After that, the long-term signature was updated, and a comparison with February 1 was made. This occurred until we reached March 31. In all, we ended up with 60 long-term signatures and 60 comparisons.
Technically, it is possible to have shorter or longer long-term signatures. However, short long-term signatures (duration of one or two weeks) lose information that could be valuable for describing the subscriber’s behavior. Longer long-term signatures (duration of more than one month) are better at describing subscriber behavior, as our tests confirmed. However according to German law, keeping personal information about subscribers for more than one month is forbidden.
When developing a signature for 30 days without distinguishing between weekdays and weekends, the assumption is that the user’s behavior is the same for all the days within this period of time. However, this might not always be realistic, especially since user behavior could change in terms of call volume and duration. To take into consideration this possibility, the signature was divided into two sub-signatures, one for weekdays and the other one for weekends. The comparison in this case was achieved by looking at whether the short-term signature reflected activities for a weekday or a weekend day, and then comparing it with the appropriate sub-signature. Unfortunately, the obtained results did not show any improvement, which can be simply explained by the fact that in this case we computed signatures for fewer days (22 days for the weekday signature and 8 days for the weekend signature).
It is worth mentioning that the z-score test usually applies to normal distributions. Therefore, the comparison between the long-term signatures and the short-term signatures was not performed on the original data, which does not follow a normal distribution, but on transformed data. To handle the transformation, we explored two commonly used transformations (logarithm function-![]() , square root function is
, square root function is ![]() ), and found that the logarithm transformation was better, especially in producing fewer alarms.
), and found that the logarithm transformation was better, especially in producing fewer alarms.
The comparison was performed on a feature basis. This means that one comparison between a long-term and a short-term signature leads to a number of alarms between 0 and the number of features considered in the signature (20 features in this case). Here are two different ways of counting and integrating the alarms:
• Option one: Whenever a feature presents a misbehavior, it is counted as an alarm. This means a signature can generate a number of alarms less than or equal to the number of feature misbehaviors detected in the comparison. This also depends on the features chosen for comparison. The VoIP provider might select features that ,when abused, have greater impact on its business, for example, premium and international calls, as they are usually expensive. The provider can also select features related to calls made during the night, if fraud is expected to be committed during that time.
• Option two: In contrast to the previous option, all the alarms generated during a comparison for one account are considered one alarm. This is sufficient to trigger a deeper investigation of that account. This scenario has the advantage of reducing the number of alarms; however, it leaves the fraud details related to the features to the fraud management expert, who needs to investigate the case more deeply.
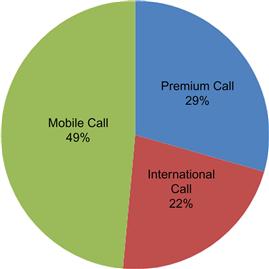
Both options were tested in our framework; however, for simplicity, we focus on the second option in this chapter. The distribution of alarms with respect to the type of call is depicted in Figure 22.3. The figure shows that almost half of the numbers that generated alarms are related to the mobile call type, suggesting that the VoIP provider should monitor more closely that type of call.
Now, let us check how effective is the signature based technique in detecting the known fraud cases and the call center behavior discussed previously. Detection here means that such cases have generated at least one alarm during the 3 months period.
To handle the testing, the three-months of data were divided into two data sets, A and B, using a 50-50 random sample split, which also led to some proportions (for both sets) of the known fraud cases and call center behavior that were not known beforehand. Then, the signature-based technique was applied to both sets (A and B), and the results were matched against the fraudulent account proportions in both sets. A similar approach was introduced in [2] to evaluate the stability of the algorithm, which is stable if the obtained results do not depend on the data. The splitting technique can be handled in two ways: either apply the algorithm to both sets separately and then compare the obtained results, or apply the algorithm to set B using the results obtained when applying the algorithm to set A. Both ways were investigated in our work. To test the signature-based technique, we applied it separately to sets A and B; however, to assess the NN-SOM technique (discussed later in the chapter), we used the results obtained from the set A as training data for testing the NN-SOM on set B. The testing results are depicted in Table 22.3 and show the stability of the technique as well as a very good performance. The detection rate in all cases is above 90 percent, and the success rates related of sets A and B are very close to each other.
Performance and effectiveness
A general question frequently asked about unsupervised classifications techniques is how to assess the reasonableness of the obtained results and by which standards [2]. One method is to create a list of potential suspicious accounts and ask the VoIP provider to assess each of these accounts in terms of its functionality and the criteria used for filtering. For instance, some accounts are used by the VoIP provider to test the status of the network components, so one should expect a huge amount of calls generated by these accounts with a weak rate of call success, as the provider is often interested in whether these components react or not, so there is no need to establish the calls.
This behavior (huge number of calls with weak success rate) is typical call center behavior, and the accounts for testing cannot be separated from the potential call centers without the provider’s help. Unfortunately, this method requires time and resources, especially if the list is long. In our work, we used this method as a first assessment, and the results are presented in the preceding sections.
Another method is to compare the signature-based technique with other unsupervised or supervised methods [2]. In our research, we also compared our work to the Neural Network Self Organizing Map (NN-SOM) technique [18]. A neural network can be seen as an adaptive machine that is able to store experimental knowledge and make it available for use [19]. There are two types of architecture for Neural Networks:
• Supervised training algorithms: Here, in the learning phase, the network learns the desired output for a given input or pattern. The besy-known architecture for supervised neural networks is the Multi-Level Perceptron (MLP) [20]. The MLP is employed for pattern recognition problems.
• Unsupervised training algorithms: In this case, in the learning phase, the network learns without specifying desired output. Self-Organizing Maps (SOM) are popular unsupervised training algorithms; an SOM tries to find a topological mapping from the input space to clusters. SOMs are employed for classification problems.
The testing activities related to NN-SOM were based on modified software provided by T.E.I. of Mesolonghi ([21]). This software is, in its turn, based on the Encog Neural Network Framework ([18]). In this chapter, we present just the results obtained from NN-SOM. The NN-SOM technique was first applied to set A, and then the results obtained were used as input for the testing phase of the NN-SOM. The results depicted in Table 22.4 show a very good performance of the NN-SOM algorithm, although the signature-based technique exceeds it slightly. In fact, looking further at the results of both techniques, we found that at least 88 percent of the fraud activities discussed in this paper were detected by both techniques. This rate is more than reasonable for unsupervised techniques [2].
Conclusion
In this chapter, we investigate the use of signature-based techniques in VoIP fraud detection. We explain that the supervised techniques and the system experts, in spite of their importance, need not be the only means for fraud detection. Unsupervised methods are another means for data classification, and they do not require training cases to produce results. Signature-based techniques belong to the unsupervised category and have been addressed within this work. We discuss in detail the generation of the signatures, and their initialization, update, and comparison. In addition, we describe how the prototype was implemented and tested. The reasonableness of the obtained results is also assessed.
References
1. Humbug Labs. Communications fraud control association (CFCA) report; 2011.
2. Ai J, Golden L, Brockett L. Assessing consumer fraud risk in insurance claims: An unsupervised learning technique using discrete and continuous predictor variables. North American Actuarial Journal. Hawaii, USA; 13(4).
3. The Sunshine project. [Internet]. 20XX Mon(th) [accessed on 20XX Mon(th)]. Available from: <http://www.sunshineproject.net/index.html>.
4. Rosenberg J, Schulzrinne H, Camarillo G, Johnston A, Peterson J, Sparks R, et al. RFC 3261-SIP: Session Initiation Protocol; 2002.
5. Verrelst H, Lerouge E, Moreau Y, Vandewalle J, Störmann C, Burge P. A rule based and neural network system for fraud detection in mobile communications. [Internet]. Available from: <http://ftp.cordis.europa.eu/pub/ist/docs/ka4/10396.pdf;2003>.
6. Ferreira P, Alves R, Belo O, Cortesão L. Establishing fraud detection patterns based on signatures. Proceedings of the 6th Industrial Conference on Data Mining Berlin, Heidelberg: Springer-Verlag; 2006.
7. Hilas CS, Sahalos JN. User profiling for fraud detection in telecommunications networks. Proceedings of 5th International Conference Technology and Automation ICTA05; 2005; Greece. p. 382–387.
8. Cortes C, Pregibon D. Signature based methods for data streams. Data Mining and Knowledge Discovery Journal. 5 Springer 2001; 167–182.
9. Internet protocol detail record (ipdr). [Internet]. Available from: <http://www.tmforum.org/InternetProtocolDetail/4501/home.html>.
10. Bihina Bella MA, Olivier MS, Elo JHP. A fraud detection model for next-generation networks. [Internet]. Available from: <http://mo.co.za/open/ngnfms.pdf>.
11. Mcgibney J, Hearne S. An approach to rules based fraud management in emerging converged neworks. [Internet]. Available from: <http://eprints.wit.ie/619/1/2003> itsrs mcgibney hearne final.pdf.
12. Ashman H, Pannell G. Anomaly detection over user profiles for intrusion detection. Proceedings of the 8th Information Security Mangement Conference, Australia; 2010.
13. Dickerson JE, Dickerson JA. Fuzzy network profiling for intrusion detection. In NAFIPS: Proceedings of the 19th International Conference of the North American, Fuzzy Information Processing Society; 2000.
14. Buennemeyer TK, Nelson TM, Clagett LM, Dunning JP, Marchany RC, Tront JG. Mobile device profiling and intrusion detection using smart batteries. In: Proceedings of the 41st Annual Hawaii International Conference on System Sciences. 2008 Jan7-10;296.
15. The Hellinger distance. [Internet]. Available from: <http://www.encyclopediaofmath.org/index.php/Hellinger_distance>.
16. The z-score. [Internet]. Available from: <http://wise.cgu.edu/sdtmod/reviewz.asp>.
17. MaxMind Geolocation. [Internet]. Available from: <http://www.maxmind.com>.
18. Neural network framework. [Internet]. Available from: <http://www.heatonresearch.com/encog>.
19. Boukerche A, Notare MSMA. Neural fraud detection in mobile phone operations. Workshops on parallel and distributed processing. Proceedings of the 15th IPDPS. 2000;1800:636-644.
20. Multilayer Perceptrons (MLP). [Internet]. Available from: <http://deeplearning.net/tutorial/mlp.html>.
21. Technological Education Institute of Mesolonghi (T.E.I.). [Internet]. Available from: <http://www.teimes.gr/wwwen/>.