
Man-in-the-Browser Attacks in Modern Web Browsers
Sampsa Rauti and Ville Leppänen, University of Turku, Turku, Finland
Man-in-the-browser is a Trojan that infects a Web browser. A Trojan has the ability to modify Web pages and online transaction content, or insert itself in a covert manner, without the user noticing anything suspicious. This chapter presents a study of several man-in-the-browser attacks that tamper with the user’s transactions and examines different attack vectors on several software layers. We conclude that there are many possible points of attack on different software layers and components of a Web browser, as the user’s transaction data flows through these layers. We also propose some countermeasures to mitigate these attacks. Our conceptual solution is based on cryptographic identification and integrity monitoring of software components.
Keywords
Web security; online fraud; man-in-the-browser
Information in this chapter
• Flow of data through software layers when executing browser applications
• Building trust between software layers using cryptographic protocols
Introduction
As financial organizations and their customers move online, cybercriminals have started to operate low-risk and profitable online crime business. One sophisticated method they use is the man-in-the-browser attack.
Man-in-the-browser is a Trojan that infects a Web browser. It is able to change the contents of Web pages and tamper with network traffic. The malware acts between the server and the user. Neither the server nor the user can detect anything unusual, because the malware delivers fallacious information to both parties.
The Trojan waits for the user to log in to a specific Web page. When the user inputs sensitive data, for example data related to a money transfer, the Trojan alters this data before it is sent, without the user noticing. When the server sends back a confirmation of the data input by the user, the malware again alters this information so that the unsuspecting user sees what is expected. An important difference from online fraud attacks of previous generations is that a man-in-the-browser attack is practically impossible for the user to notice. Also, the user does absolutely nothing wrong, in the sense that there are not any security problems with the user’s own actions. No modern authentication scheme works against this attack, because man-in-the-browser acts in the GUI, in the program logic, or in the browser’s network traffic processing level, not on the authentication level. It just waits for the user to log in and uses the user’s legitimate session to do its business. Thus, it is not surprising that the amount of Trojans intercepting and manipulating user input has increased rapidly in recent years [1] and that this business has been profitable for the attackers [2].
A man-in-the-browser attack can be implemented in many ways. Probably the easiest and most popular way is to implement a browser extension that secretly intercepts the network traffic, but other attack methods on other software layers also exist. Many of these layers are shown in Figure 28.1. This chapter sheds light on various attack vectors that exist on software layers of the browser and operating system libraries.
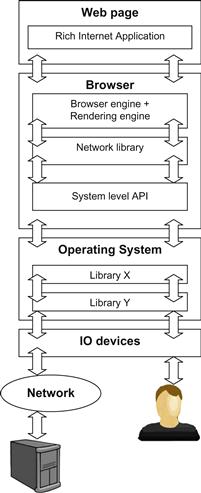
Chapter overview
In this chapter we examine typical browser architecture and explain the flow of data from the user to the server. We give a detailed description of attack vectors, that is, the points or components where attacks can take place. Based on these attack vectors, we study the different man-in-the-browser attacks grouped according to the software layers at which they take place. This helps to better understand the nature of the man-in-the-browser problem and to develop ideas for countermeasures against it. We then briefly explore possible countermeasures against the attacks described. A conclusion summarizes the chapter.
Related work
The man-in-the-browser attack has been discussed in detail by Dougan and Curran [3] and Gühring [4]. In [2], Ståhlberg describes various banking Trojans and some of the attack methods they use. The functionalities of malicious browser extensions have been studied by Sook and Enbody in [5] and by Ter Louw, Lim, and Venkatakrishnan in [6]. We analyze malicious browser extensions in [7] and present an obfuscation-based solution to the man-in-the-browser attack in Ajax applications [8]. Bandhakavi, King, Madhusudan, and Winslett [9] study vulnerabilities in benign browser extensions. Grosskurth describes different browser architectures in [10].
Browser architecture
To understand where vulnerabilities and attack vectors are located, we will briefly look at typical browser architecture, using Firefox’s architecture as an example. The main components of this architecture are shown in Figure 28.2. Arrows show interaction and data flow between components.
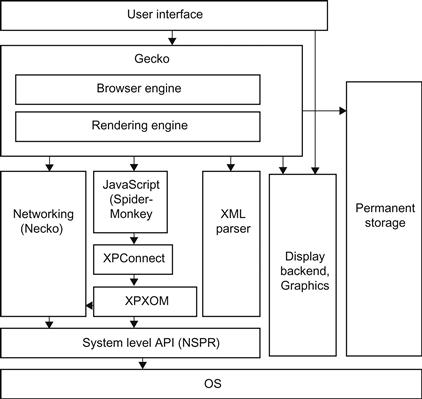
Figure 28.2 The architecture of the Firefox Web browser. Adapted from [10].
The user interacts with the user interface, which handles the user’s commands. The browser engine provides a high-level interface used to query and manipulate the rendering engine. The rendering engine handles parsing and lays out HTML documents, which are possibly styled with CSS. In Firefox, these two are bundled into the Gecko engine [10].
To parse HTML documents, and more generally XML, the rendering engine uses the XML parser. Mozilla’s JavaScript engine, SpiderMonkey, executes JavaScript on Web pages. The networking subsystem, Necko, handles all network traffic in the browser. The rendering engine and user interface use a display backend for drawing. The graphic libraries provide primitives for drawing and windowing, user interface, widgets, and fonts. Data persistence in Firefox is provided by Mozilla’s profile mechanism. This data store contains all data such as bookmarks, cookies, and page caches.
Cross Platform Component Object Model (XPCOM) is Mozilla’s cross-platform component model, which is similar to Microsoft’s COM. XPCOM makes practically all of Gecko’s functionality available as a series of components [10].
XPConnect enables JavaScript objects to use and manipulate XPCOM objects. JavaScript objects can also implement XPCOM-compliant interfaces to be called by XPCOM. Thus, objects communicating on different sides of XPConnect do not need to know about the implementation language of the other side.
Finally, the system level API, NSPR, is a platform-neutral interface for system-level functions. Using this interface, other components like XPCOM and Necko can use the operating system’s resources.
Firefox browser extensions are powerful enhancements that extend the browser’s core functionality. These extensions, written in JavaScript, use the services of Gecko, Necko, and NSPR through the interfaces provided by XPCOM. Firefox browser extensions have full privileges in the browser and can use practically all browser functionality, like intercepting HTTP requests and responses or modifying any Web page. Sandboxing that restricts the functionality of normal JavaScript on Web pages is not applied to browser extensions.
Man-in-the-browser attacks on different layers
In this section, we present man-in-the-browser attacks taking place at different layers and targeting various points in the data flow. In a sense, we analyze these attacks from the top down. First, we explore the attacks related to browser and rendering engines, then cover the network component and the system level API. Finally, we study the attacks associated with the operating system’s networking APIs. One can consider this as covering one possible path of data flow, when the user gives data as an input and this data is sent to the server.
Web page DOM and scripts
We can think of a Web page containing JavaScript code as the highest software layer. The man-in-the-browser attack can be implemented at this level either by modifying a Web page’s DOM (Document Object Model) tree, by changing the Web page’s JavaScript code, or by modifying the Ajax application’s data transmission mechanism. The two latter techniques work if the attacker’s target is an Ajax application. Because these three attacks change the structure of HTML and JavaScript code, they are actually attacks against the Gecko engine. In what follows, we take a look at these attacks and the methods used to achieve them.
Modifying the DOM tree
An easy method for modifying the input from the user is to use JavaScript to manipulate elements in a Web document’s DOM tree. Consider a situation where the adversary wants to secretly change the value of a text field that will be sent to the server. The following steps could be used:
• A malicious browser extension listens to the click events in the document body. If a text field is clicked, it is immediately made “invisible” using CSS-style definitions, and its value is changed according to the wishes of the attacker.
• A new, identical text field is put in place of the original, now-invisible text field. The focus is set on the new element.
• The user types input into the new text field without noticing anything suspicious.
• When the data is submitted, the value of the original text field is sent to the server and the new text field filled by the user is saved for later use.
When the modified text is sent back from the server, the attacker again replaces it with the user’s original input before it is displayed to the user. This can again be achieved by manipulating the DOM and replacing the changed value with the one the user expects. In an Ajax application, for example, the attacker can listen to a DOMNodeInserted event and immediately replace the new element’s innerHTML property when it is inserted.
Modifying a DOM tree to fool the user is a relatively easy attack to implement, and some existing Trojans use this approach. However, it requires knowledge about how the Web page or Web application works and what kind of elements it contains.
Modifying the JavaScript functionality on a web page
Using JavaScript, we can replace and add script elements on a Web page to modify its JavaScript functionality. This method can be considered a special case of modifying the DOM tree. However, in this scenario, the visible elements in the tree are not altered. The attacker simply uses JavaScript to add and modify the existing script elements on a Web page.
The goal of an adversary is to change the JavaScript functionality of a Web page to secretly edit the input given by the user before it is sent as an HTTP request. The malicious code can be added to existing JavaScript functions, or functions can be replaced altogether with a new malicious implementation that tampers with the data given by the user. DOM provides replaceChild, removeChild and appendChild methods that can be used to achieve the replacement.
For example, the adversary could find out what the XMLHttpRequest object’s “send” function (which Ajax applications usually use to send HTTP requests) is called and replace the data given as an argument to this function. The adversary would simply make a string replacement to the code in the original script element and replace this old element with a new script element containing the modified content. Alternatively, the adversary can overwrite entire functions by appending a new script element containing the function’s new implementation. When there are two function declarations with the same name in JavaScript, the first one gets overwritten.
Modifying the Ajax transmission mechanism
XMLHttpRequest is a JavaScript API available in JavaScript. In Ajax applications, it is used to send HTTP or HTTPS requests to a server and to receive responses from the server.
In JavaScript, objects are created based on prototypes. If the attacker overrides XMLHttpRequest’s prototype implementation, the attacker can modify the payload of any Ajax request. An attacker can modify XMLHttpRequest’s prototype by adding malicious code as a part of send function:
XMLHttpRequest.prototype.originalSend = XMLHttpRequest.prototype.send;
var evilSend = function(data) {
// Modify the data here
this.originalSend(data);
};
XMLHttpRequest.prototype.send = evilSend;
All XMLHttpRequest objects now use the new implementation of the “send” function. Each time a request is sent, this code silently modifies the data and then passes it to the original send function.
The XMLHttpRequest object’s callback function, onreadystatechange, is used to receive responses from the server. Again, an attacker can replace this function with the attacker’s own implementation that alters the incoming data:
XMLHttpRequest.prototype.onreadystatechange = evilHandler;
Here, the function handler is assumed to be the malicious implementation that handles the data sent by the Web server before it is shown to the user. That is, this function simulates the Web page or Web application’s normal behavior, fooling the user.
As in the previous two attacks, the adversary needs to have a good understanding of the website or application being attacked. However, especially in the case of Ajax applications, this is easily possible because the source code is kept on the client side and is totally visible to the attacker.
Accomplishing the example attacks
All three attacks we have discussed require JavaScript code to be inserted on a target Web page. How do attackers achieve this? There are two main methods to execute harmful JavaScript on a Web page: Cross-Site Scripting (XSS) attacks and browser extensions.
An XSS attack becomes possible if a Web application is vulnerable so that an attacker can inject the malicious code into a trusted website. The attacker uses normal functionality in a Web application to deliver the harmful code to another end user as a browser side script. Any Web application that uses unsanitized input from a user in the output the application shows on a Web page is susceptible to this attack. The attacker gives the malicious code as an input, which is then executed on another user’s machine when the user visits the appropriate page. The user’s Web browser, of course, thinks that the harmful script originates from a trusted source. After all, it is the benign website or Web application that delivers the malicious code to the browser.
Once the adversary can slip the malicious code into a Web application, it is easy to perform the man-in-the-browser attack. The attacker uses some of the three previously described methods: manipulating the DOM tree, modifying the Ajax application’s functionality, or subverting the Ajax transmission mechanism to attack an application or a website.
If the attacker is able to run browser extensions in the victim’s browser, it is even easier to launch the previously described attacks, because browser extensions can freely manipulate content on any Web page in any way they want. With a malicious extension at the attacker’s disposal, the attacker does not have to worry about finding vulnerabilities.
Even if the attacker does not have a malicious extension in the user’s browser, it may still be possible to run code with full privileges if the attacker knows about a vulnerable point in some benign extension. This can happen if a malicious script is injected into a benign Web page using an XSS attack, or if the user visits some evil Web page containing a malicious script. This kind of privilege escalation can happen, for example, if an extension uses JavaScript’s eval() function to execute a string taken from a Web page’s source code or a string that can otherwise be altered by the attacker. This will usually lead to arbitrary code execution that enables the attacker to do practically anything in the browser. Using eval() is a bad practice, but it is still used in extensions from time to time. Other functions, such as setTimeout(), may also make privilege escalation possible.
In addition to using browser extensions, the attacker could also use XPCOM components from outside the browser to achieve the very same functionality as the extensions. While building an extension is much easier, infecting the browser provides an even better hiding place for a malicious piece of code.
Networking library and system-level API
Malware can intercept Firefox’s HTTP requests and the server’s responses by abusing either the networking library (Necko) or the system level API (NSPR). Necko can easily be compromised by malicious browser extensions. On the other hand, malware not residing in the browser can use NSPR that is located on a lower software layer.
Necko
Firefox browser extensions can easily use Necko’s components through XPCOM interfaces. This allows the extensions to observe and modify all HTTP requests the browser makes and the responses it receives. In practice, this happens by implementing a listener interface called nsIObserver. A malicious extension implementing this interface then receives a notification each time a request or response takes place.
Assume an evil browser extension wants to tamper with outgoing traffic. Each notification has a topic that tells whether it deals with a request or a response. In the case of incoming traffic, malware listens to a notification with the http-on-modify-request topic. Associated with each arriving notification is an HTTP channel that implements the nsIHttpChannel interface.
The nsIHttpChannel interface includes an upload channel, nsIUploadChannel. The malware can use the upload stream of this channel to obtain the data it wants to modify. The modified data is put back in the HTTP channel and the request can resume normally.
Similarly, all incoming HTTP responses in the browser can be captured by listening to notifications with the http-on-examine-response topic. The payload included in a response can then be read and modified using the nsITraceableChannel interface, for example.
Naturally, Necko’s previously mentioned interfaces can also be hooked by an external program, but building a browser extension is probably much easier, at least in Firefox’s case. Internet Explorer uses wininet.dll for networking functionality. Zeus, which is a real-world example of a Trojan containing man-in-the-browser functionality, hooks WinInet in order to spy on and tamper with network traffic [11].
NSPR
NSPR can be attacked by hooking the PR_Write function. This is a function that writes a specified number of bytes to a file or socket. It is responsible for delivering outgoing HTTP requests. For example, Zeus Trojan hooks this function to intercept outgoing HTTP requests from Firefox [11]. Similarly, the PR_Read function in NSPR handles incoming responses from the server.
Network APIs
The malware on a user’s computer can intercept HTTP requests the browser issues by using Windows network APIs without residing in the browser. Figure 28.3 shows a simplified sketch of these network-related interfaces.
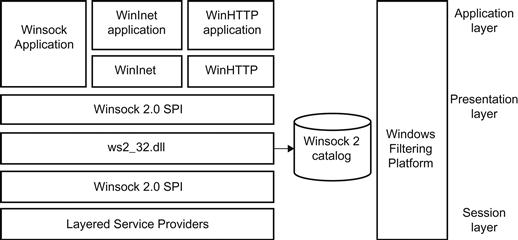
Figure 28.3 Windows network APIs. Adapted from [12].
Winsock is a technical specification defining how software should access network services in Windows. Winsock defines a standard interface between a client application, for example, a Web browser, and the underlying TCP/IP protocol stack.
WinInet and WinHTTP are basically wrappers built on top of Winsock and can be used to modify outgoing and incoming HTTP traffic. WinHTTP provides some HTTP-specific features, while WinInet is a more general API that also supports FTP, for example. Using these simplified interfaces makes an attacker’s job simpler and less error-prone. However, if a Web browser uses Winsock directly, these APIs cannot be used to modify packets.
Introduced with Windows Vista, a new architecture called Windows Filtering Platform (WFP) allows applications to intercept and modify network traffic [13]. This can happen at several layers of the TCP/IP stack, as shown in Figure 28.3. WFP makes applications tampering with network traffic easier to implement and even provides an engine for choosing packets using predefined filtering conditions.
One solution that allows malware to easily hook API functions is Microsoft Detours. Detours intercepts Win32 functions by rewriting the in-memory code for target functions. The Detours package also provides tools for attaching DLLs and data segments to any Win32 binary [14].
A Layered Service Provider (LSP) is a feature of the Winsock 2 interface. It is a DLL that uses Winsock APIs to insert itself into the TCP/IP protocol stack. These LSPs intercept Winsock 2 commands before they get processed by ws2_32.dll. This means they can modify or remove commands, or simply store the data for later use. In a way, an LSP acts as a proxy between the application and Winsock 2. Malware may insert itself as an LSP in the network stack in order to make modifications to the outgoing and incoming data. Layered Service Providers use the Winsock SPI interface. The order of these providers is stored in the Winsock catalog.
It is noteworthy that encryption with Transport Level Security (formerly Secure Sockets Layers, or SSL) does not affect the malware making use of the APIs discussed above. This is because Winsock operates above the transport layer [12], where the data is encrypted. Malware modifies outgoing data before it is encrypted and incoming data after it is decrypted. HTTPS and the lock symbols in the browser can therefore give users a false sense of security.
Modifying network traffic and hooking API functions can sometimes be troublesome for malware, though, as anti-virus programs often consider such activity malicious. On the other hand, browser extensions are often deemed totally safe by antivirus programs and are not even checked for malicious behavior [5].
Countermeasures
There are no guaranteed countermeasures against man-in-the-browser attacks, as all existing methods to prevent them have been more or less effectively circumvented. Therefore, only partial solutions exist and we can, at best, try to considerably mitigate the problem.
The modern browser is like an operating system in the sense that it has many separate software layers and the user’s applications are run on the top of this stack. The problem is that the adversary can freely and easily manipulate these layers or extend the browser by adding the attacker’s own malicious code.
The countermeasures we propose are as follows:
Building trust between software layers
We advocate the idea of building trust between different software layers and components by using cryptography. This is not yet a concrete solution, but a concept. In our approach, each component or layer would be run as a separate process. An ID could then be given to each component and the components would use cryptographic protocols to interact with each other. The idea is to make sure that the components really know who they are interacting with.
This idea is somewhat similar to the security scheme used in the Symbian OS. In Symbian, a process needs to hold a specific token (e.g., an unforgeable data value) in order to use a system resource [15]. Each resource is guarded by a service process to which other processes have to present their tokens.
Of course, the malware might find out the communication mechanism and try to use it to impersonate some component of the system. That is, the malware might learn to use the cryptographic protocol. This is why the integrity of the separate components should be checked regularly by a separate monitor.
In general, loading external dynamic libraries into a running process can be considered a very weak solution from the security point of view. This is why we propose a model where libraries are replaced by processes that use cryptographic protocols and possess unforgeable IDs. That is, the service interfaces should not be put behind passive libraries, but behind process interfaces that actively monitor the usage of resources.
Using cryptographic protocols
On the Web application level, encrypting user input may provide some advantages. For example, if user input is encrypted, malware that intercepts the HTTP request using the operating system’s network APIs would not be able to easily manipulate or spy on the data. At the very least, some knowledge about the Web application’s functionality and structure would be needed.
However, there would still be several components in the browser that would be able to see this data in plaintext. For example, if the data is encrypted using JavaScript, the interpreter can see data in both plaintext and encrypted form. This is why we ultimately need to build trust between software layers and monitor their integrity.
Using obfuscation
As noted previously, encrypting user input moves attacks to the upper layers such as the Web application layer. To protect Web applications, we can obfuscate their source code and the code that is being executed. Obfuscation refers to transforming the code into a form that is functionally equivalent to the original code. However, transforming the code makes it more difficult to understand or de-obfuscate using automatic tools. Obfuscated code will not be impossible to de-obfuscate, but the time and cost of de-obfuscating and understanding the code can be increased. In this sense, obfuscation bears some resemblance to encryption.
Obfuscating and randomizing a Web application’s JavaScript and HTML code provide some protection against automated large-scale attacks that target a Web application’s source code or the DOM structure of a Web page. Targeting these attack points in an automated large-scale attack requires much more work from the attacker if the application’s source code and DOM structure are uniquely obfuscated for each session.
Furthermore, the Web application’s code may also be changed dynamically during its execution [8]. In modern Web applications, this is made possible by Ajax techniques that allow for changing the contents of a Web page—and an Ajax application’s source code—dynamically without the need to reload the whole page.
This is similar to building trust between software layers; we are not trying to block all the security holes here. Instead, we are aiming to make it very difficult for the malware to call the resources it needs, especially in the large scale.
Miscellaneous observations
It is noteworthy that the three techniques presented here, building trust between software layers, using cryptographic protocols, and using obfuscation, differ in their implementation requirements. Building trust between software layers requires replacing the layers in the Web browser with independent processes, so software has to be rewritten. Encryption and obfuscation in the Web application’s code, however, only require the code to be modified by an obfuscating engine. That is, the programmer does not have to worry about obfuscation, which is a great advantage. Moreover, none of the three techniques require any user involvement.
Obfuscation might not only be useful on the Web application level, but on other software layers as well. Obfuscating lower layers like operating system libraries makes it possible to build trust between all software layers. Naturally, this requires an open source operating system, but the idea is still very interesting.
The integrity of browser extensions is also a concern. Firefox allows signed browser extensions, but hardly anyone uses this feature. Moreover, this signature is only used to check that the extension is genuine and really comes from the right source. Consequently, the integrity of signed extensions is not checked at runtime, so malware could still change them as it pleases after installation.
Therefore, the scheme we described above should also be applied to extensions to verify their integrity. At the same time, the privileges of browser extensions should be considerably restricted and their runtime actions should be monitored, even though this would probably cause some performance losses. Antivirus vendors should always treat browser extensions as possible threats to the browser and the user.
Conclusion
In this chapter, we examine a browser’s components and possible attack vectors that malware can target to perform man-in-the-browser attacks. We also propose a conceptual, threefold solution that makes use of cryptographic identification and integrity monitoring of software components, encryption, and source code obfuscation.
There are many possible points of attack in a browser that this chapter has not covered in detail. After all, there is a huge number of functions in the call stack the malware could attach itself to. Still, we hope it is clear to the reader that a large number of possible points of attack exist in different software layers and components. This further emphasizes the fact that the man-in-the-browser attack is a serious threat to online security.
Even though the adversary, with enough hard work, can probably always find some way to alter online transactions, it is a decent goal to be able to prevent at least automated and generic large-scale man-in-the-browser attacks in the future.
References
1. RSA. Making sense of man-in-the-browser attacks: Threat analysis and mitigation for financial institutions. [Internet]. Retrieved from: <http://www.rsa.com/products/consumer/whitepapers/10459\_MITB\_WP\_0611.pdf>; 2011.
2. Ståhlberg M. The Trojan money spinner. In: Virus Bulleting Conference; 2007.
3. Dougan T, Curran K. Man-in-the-browser attacks. International Journal of Ambient Computing and Intelligence. 2012;4(1):29–39.
4. Gühring P. Concepts against man-in-the-browser attacks. [Internet]. Retrieved from: <http://www.cacert.at/svn/sourcerer/CAcert/SecureClient.pdf>; 2006.
5. Sook AK, Enbody RJ. Spying on the browser: Dissecting the design of malicious extensions. Network Security. 2011;5:8–12.
6. Ter Louw M, Lim JS, Venkatakrishnan VN. Enhancing web browser security against malware extensions. Journal in Computer Virology. 2008;4(3):179–195.
7. Rauti S, Leppänen V. Browser extension-based man-in-the-browser attacks against Ajax applications with countermeasures. Proceedings of the 13th International Conference on Computer Systems and Technologies 2012;251–258.
8. Rauti S, Leppänen V. Resilient JavaScript and HTML obfuscation and code protection for Ajax applications against man-in-the-browser attacks. Under review; 2013.
9. Bandhakavi S, King ST, Madhusudan P, Winslett M. Vex: Vetting browser extensions for security vulnerabilities. Commun ACM. 2011;54(9):91–99.
10. Grosskurth A. A reference architecture for web browsers. Proceedings of the 21st IEEE International Conference on Software Maintenance 2005;661–664.
11. IOActive. Reversal and analysis of Zeus and SpyEye banking Trojans. [Internet]. <http://www.ioactive.com/pdfs/ZeusSpyEyeBankingTrojanAnalysis.pdf>.
12. Russinovich M, Solomon DA. Windows internals Part 1. 6th ed. Waypoint Press; 2012.
13. Microsoft Developer Network. Windows filtering platform. [Internet]. 2012. <http://msdn.microsoft.com/en-us/library/windows/desktop/aa366510>(v=vs.85).aspx.
14. Hunt G, Brubacher D. Detours: Binary interception of win32 functions. Proceedings of the 3rd conference on USENIX Windows NT Symposium 1999;14.
15. Heath C, Symbian OS. platform security. Wiley & Sons Ltd 2006.