
An Approach to Facilitate Security Assurance for Information Sharing and Exchange in Big-Data Applications
Alberto De la Rosa Algarín and Steven A. Demurjian, University of Connecticut, Storrs, CT, USA
Security assurance is the guarantee provided with regard to access control, security privileges, and enforcement over time as users interact with an application. For a big-data application that shares and exchanges information from multiple sources in different formats, security assurance must reconcile local security capabilities to meet stakeholder needs. This chapter presents a role-based access control (RBAC) approach to modeling a global security policy and generating an enforcement mechanism for a big-data application by integrating the local policies of the sources, which are assumed to communicate via XML, the de facto standard for information sharing/exchange. Towards this goal, the Unified Modeling Language (UML) is extended to define new diagrams to capture XML for RBAC security and for policy modeling. To illustrate, we use a big-data application in law enforcement for motor vehicle crashes, showing how global security can be achieved in a repository that links different crash data repositories from multiple sources.
Keywords
security modeling; policy integration; big-data application security; information exchange; policy definition; Unified Modeling Language; XML security
Information in this chapter
Introduction
Security assurance for an application is the guarantee that a security officer seeks to provide regarding the utilized access control model, its defined security privileges, and their enforcement over time as users simultaneously interact with the system. For a big-data application constructed as a meta-system (system of systems) that shares and exchanges a wide variety and high volume of information in potentially different formats (e.g., XML - http://www.w3.org/XML/, RDF-http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/, JSON-http://www.json.org/, etc.), security assurance must address the different and potentially conflicting security capabilities of constituent systems, the diverse set of stakeholders, and the overall security logic to be attained. A security approach to control the how, what, and when of stakeholders accessing a big-data application must insure that the local security policies of constituent systems are reconcilable with one another to yield a consistent and usable global security policy. From the perspective of information integration that allows the big-data application to be constructed, translations among the data formats of the constituent systems that maintain the structure and semantics of the local systems must be available. From a security perspective, these data formats must be reconciled to allow data sharing and exchange to occur in a secure fashion as users of the big-data application indirectly access local systems. The main objective of this chapter is to present and explain a role-based access control (RBAC) [1] approach to integrate and reconcile local security policies of the systems that comprise a big-data application, thereby providing a means to define a global security policy that contains the roles, privileges, and rules of the constituent systems. For security enforcement, this approach can generate a global policy for the big-data application, targeting the information shared by each constituent (local) system using rules that define security assurance on internal and shared resources.
To facilitate the discussion in this chapter, we focus on an area of law enforcement that has the potential for many different big-data applications. Law enforcement in the United States is organized in a very hierarchical fashion. For example, in the state of Connecticut, cities and larger towns have their own police forces. From a road management perspective, the local police forces concentrate on their local roads, while the state police force manages all of the state highways and interstate highways. For smaller towns that do not have their own police force, resident state troopers manage the roads. State and local police forces can also work with the Federal Bureau of Investigation at the national level when crimes cross state boundaries.
Other states have a similar hierarchical structure of law enforcement personnel. Each law enforcement official, from the lowest to the highest ranking, generates information regarding criminal activities, traffic accidents, and so on. As a result, there is a wide range of information that can potentially be linked within and across states. An example is the Integrated Automated Fingerprint Identification System (IAFIS, http://www.fbi.gov/about-us/cjis/fingerprints_biometrics/iafis/iafis), which is in a national database that already includes criminal histories, pictures, physical traits, and so on, as well as fingerprints from civilian (that is, governmental, ranging from local to state to federal) and military sources. Another example is the National Missing and Unidentified Persons System (NamUs, http://www.namus.gov/) of the US Department of Justice (DoJ).
In this chapter, we focus on the collection of data on motor vehicle crashes by law enforcement personnel that are then made available to a wide range of stakeholders. For example, faculty and graduate students in the departments of Civil Engineering and Computer Science and Engineering at the University of Connecticut have worked under the leadership of the State of Connecticut Transportation Department and the Department of Public Safety to establish a Connecticut Crash Data Repository (CTCDR, http://www.ctcrash.uconn.edu/) that contains data back to 1995 on crashes on state roads. Many other states have similar repositories: Florida (http://www.flhsmv.gov/ddl/ecrash/), Indiana (http://www.in.gov/cji/2481.htm), Wisconsin (http://transportal.cee.wisc.edu/services/crash-data/), Louisiana (http://datareports.lsu.edu/), and New Jersey (http://www.state.nj.us/transportation/refdata/accident/), to name a few.
From a security perspective, many stakeholders are interested in doing research and discovery using these large date sets (e.g., to identify road locations that have more accidents, study the impact of road work on traffic, etc.). For instance, a Department of Transportation (DoT) employee at the local, state, or federal level could read and curate (correct) the crash data; a police officer could enter new crash reports; a researcher might be interested in aggregate and other trend-oriented queries; while an attorney representing a client in an accident may want to see if prior accidents occurred at that location (akin to an FOI request). What is not supported is the ability to marshal information across all crash data for all states (local repositories) to form a crash report big-data application (global repository) that allows queries that cross state boundaries, enabling stakeholders to explore crashes and accidents across an area larger than a state. In fact, such a scenario is actually being explored. The Governors Highway Safety Association (http://www.ghsa.org/html/media/pressreleases/2012/20120702_mmucc.html) is promoting a unification of format on crash data collection (http://www.mmucc.us/). Once unified, the result will be a big-data application of crash data.
A big-data application is constructed by marshaling information from multiple sources to form an information exchange repository application that, as shown in Figure 4.1, includes data from multiple state sources that warehouse crash data (road accidents). The multiple data sources are brought together to create a big-data Crash Repository to support access across multiple sources in a secure manner for three types of users: police officers (denoted with a role of PoliceOfficer), DoT workers (DOTWorker), attorneys (Attorney), and data researchers (Researchers). This big-data Crash Repository can support the consolidation of accident data, included meta-data (driver, road, time of accident, cars involved, etc.) for research purposes (e.g., to find out which roads are more susceptible to crashes) to better allocate resources.
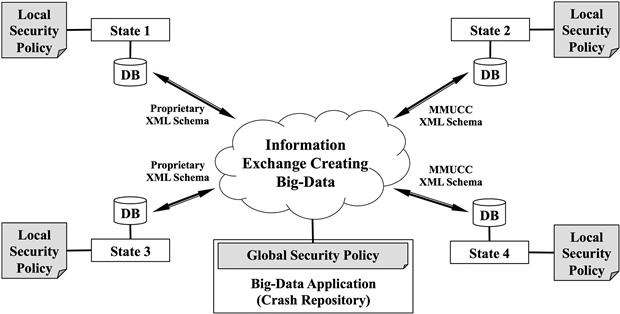
Figure 4.1 An information exchange scenario and intended policy integration for a big-data application.
To illustrate, in Figure 4.1, States 1 and 3 might utilize a proprietary or state-recommended XML schema as their format for structuring information, while the States 2 and 4 might have already adopted the national MMUCC standard (http://mmucc.us/sites/default/files/MMUCC_4th_Ed.pdf). Each State/system in the figure has its own role-based access control (RBAC [1,2]) policies, in which different stakeholders have permissions defined at the local level to access the constituent systems. A new big-data Crash Repository using data from the four states in Figure 4.1 would have to consider the differences in permissions of logically equivalent roles (PoliceOfficer, DOTWorker, Attorney and Researcher), which may be different in different systems, and data provided by systems that may not match user needs. Our focus is on the security policies that dictate which resources can be accessed by whom, when, where, and how. We assume each local system has its own security policy for supporting the big-data Crash Repository with potential complementary and conflicting requirements. We also assume that each of the constituent systems provides data in either XML or a format that can be easily converted to XML so the big-data Crash Repository application has a unifying data format.
This chapter extends our prior work on a security modeling framework for XML schemas and documents achieved via Unified Modeling Language (UML) extensions to model generic security policies and generate extensible markup access control language (XACML, https://www.oasis-open.org/committees/tc_home.php?wg_abbrev=xacml) policies [3,4] with an approach that reconciles multiple local security policies (policies for States 1 through 4 in Figure 4.1) in support of global security for a big-data application (Crash Repository in Figure 4.1). In our work, we assume that the constituent applications (e.g., States) that support a big-data application (e.g., Crash Repository) are each composed of a set of XML schemas and associated instances, such that when a user attempts access, the instance will be customized and filtered based on privileges. This chapter significantly extends [3,4] by providing the ability for more precise definitions of security policies. This allows local security policies (or portions thereof) to be enforceable for a big-data application, like Crash Repository, that is capable of obtaining, sharing, and changing information found in the constituent systems, thereby attaining a global security policy. We envision these policies to operate within a publish/subscribe model, where local systems as data owners decide which portion of their information (for their state) can be exposed (published) for use by other systems (in this case, the big-data Crash Repository application). While we use the Crash Repository for the example, this work is applicable to all big-data applications used in varied domains (science, engineering, biomedical informatics, finance, e-commerce, telecommunication, etc.) that seek to bring together and control access to data stored in multiple locations.
The main objective of this chapter is to model RBAC security of local systems regardless of their form and structure (XACML policy, database table with security definitions, etc.) while simultaneously integrating these local security policies acting on independent systems. The end result is a global security policy for a big-data application that is heavily structured around information sharing, using resources from its constituent systems, and provides a degree of security assurance. With this as its basis, this chapter focuses on both policy definition and integration processes to link the local policies (states) into a global context for the Crash Repository (country) as shown in Figure 4.1. The intent is to provide a means to reconcile the local polices of the constituent systems to allow their use for information exchange without sacrificing security assurance of those local systems. In the process, the security of a big-data application (e.g., Crash Repository) can leverage and integrate existing local security, resulting in a global policy that respects and privileges of the constituent systems.
The remainder of this chapter has five sections. The first section, “UML Extensions for XML Security,” provides a brief overview of our XML framework for RBAC [3,4]. The second, “Extensions for Policy Modeling and Integration,” extends this work to capture local and global security policies in support of the security for a big-data application. The third section, “Integrating Local Security Policies into a Global Security Policy,” details the process of integrating multiple local security policies into a global policy for a big-data application, including reconciling conflicts across local systems, roles, and permissions in order to attain a global policy that can be assured. The next section, “Related Work,” details related work on policy/security modeling and policy integration. The chapter ends with concluding remarks.
UML extensions for XML security
In this section, we provide a brief summary of our XML security framework [3,4] that utilizes schemas and instances to separate the security policy definition from the application’s XML schema. It accomplishes this by using two new UML diagrams for modeling XML schemas and roles along with a mapping algorithm that places the XACML policies in the same layer of conceptual design as UML diagrams. The XML Schema Class Diagram (XSCD), in the top of Figure 4.2(a), is an artifact produced with a custom UML profile that holds all of the architecture and characteristics of the XML schema, including structure, data type constraints, and value constraints. In Figure 4.2(a), a crash report’s alcohol component (following the MMUCC standard) can include the mmucc:AlcoholInvolvementSuspisionCodeType (whether there is a suspicion of alcohol involvement in the accident), the mmucc:AlcoholTestCategoryCodeType (what type of alcohol test was given e.g., blood, breath, etc.), the mmucc:AlcoholTestResultCodeType (whether the test results are pending), and the mmucc:AlcoholTestStatusCodeType (whether the person involved refused to take the test or not). The same crash report can include other information, such as the involved parties’ information (name, address, license plate number, etc., not pictured in the XSCD), location (GPS or road markings).
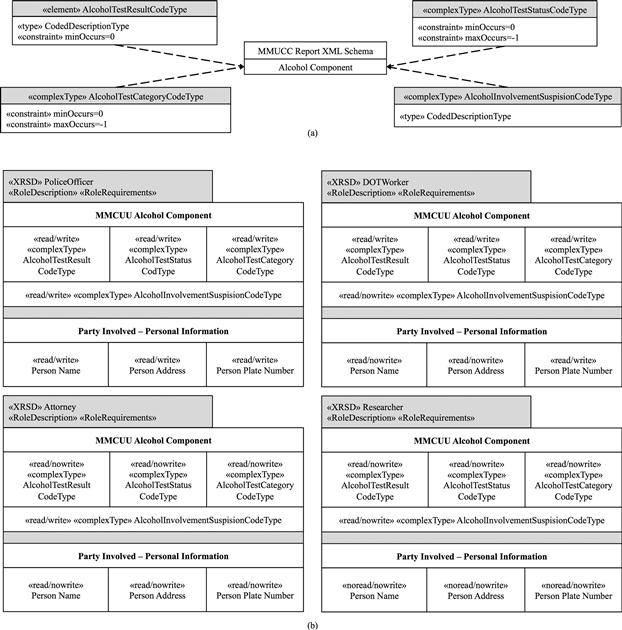
The XML Role Slice Diagram (XRSD), shown in Figure 4.2(b), defines permissions such as read, no read, write and no write, to the attributes modeled in the XSCD. In the figure, PoliceOfficer and DOTWorker have the same read/write permissions on the alcohol and involved parties information, but the Attorney and Researcher differ on the alcohol attribute (an Attorney might be able to update this information as a result of a federal investigation, but the Researcher might not be able to write under any circumstances).
By utilizing these diagrams for security definition (the XSCD and the XRSD), a system’s information security can be included as part of the overall software engineering process. Once defined, the XSCDs and XRSDs are used to generate an XACML policy that targets the initially modeled XML schema, and in turn all the respective instances, from the perspective of the local system (e.g., States 1 through 4 in Figure 4.1). As a result, policies affecting a large number of XML instances can change and be updated without incurring an overhead of updating each instances [4], unlike security methods that embed the security in the data itself.
Extensions for policy modeling and integration
This section details the three proposed extensions to the model described in the preceding section and in [3,4] to support local policy modeling and their global integration. These extensions are: the Master Role Index (MRI), which is an XML schema to track roles across systems; a new UML Policy Slice Diagram (PSD) that models a specific segment of an established security policy with respect to a role, its permission, and the entities on which the permissions act; and a new UML Security Policy Schema Set (SPSS) that represents the complete security policy as an interconnection of the PSDs.
To begin, the Master Role Index (MRI) is an XML schema that keeps track of the many different roles across all the constituent local systems that are exchanging information to provide services to the IE big-data application. The MRI schema (left side of Figure 4.3) allows each role to have a unique identifier, a name, and a role description, and to indicate the type of information that the role can read and/or write. Instances (right side of Figure 4.3) are created for each role, as shown for the PoliceOfficer role.

The second extension, the Policy Slice Diagram (PSD), shown in Figure 4.4, is a new UML diagram that models a segment of the local security policy of an application (e.g., State 1 in Figure 4.1) from the perspective of representing security rules (SR) as triples. These triples have the form: SR=<Role (r), Permission (p), Entities (ents)>, where an entity can be an object, an XML attribute, an XML complexType, an XML XQuery, an XML schema, and so on; this is left very general to allow for all of the types of access that the different systems could provide (see Figure 4.1). In Figure 4.4(b), the PoliceOfficer PSD links to the PSD for the application and indicates that PoliceOfficer can read the attribute mmucc:AlcoholInvolvementSuspisionCodeType. Figure 4.4(b) represents a total of 14 security rules: Read and Write in combination with AlcoholInvolvementSuspisionCodeType, AlcoholTestCategoryCodeType, AlcoholTestResultCodeType, AlcoholTestStatusCodeType, Person Name, Person Address, and Person License Plate. In comparison, the Researcher PSD in Figure 4.4(c) would have a Read and Nowrite with the alcohol components (eight security rules) and Noread/Nowrite on the personal components (six security rules). A sample security rule from Figure 4.4(b) is <PoliceOfficer, <<read>>, AlcoholInvolvementSuspisionCodeType>, which indicates that PoliceOfficer can read the attribute AlcoholInvolvementSuspisionCodeType.
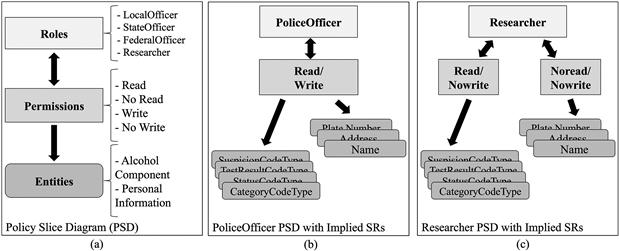
Figure 4.4 Policy slice diagram (a), policeofficer slice example (b), and researcher slice example (c).
In practice, the set of PSDs define all of the security rules for a local application (e.g., State 1 in Figure 4.1) that are published, which may be fewer than the rules available in the local system. Security rules are also defined using an XML schema (left side of Figure 4.5) and an instance for the security rules of PoliceOfficer (right side of Figure 4.5, shortened due to space limitations).

The union of all PSDs for a system (e.g., State 1 in Figure 4.1) defines a local security policy that is represented in the third extension, a new UML Security Policy Schema Set (SPSS). In the policy integration process, to be discussed in the next section, the SPSS (as shown in Figure 4.6) is published as the local security policy (e.g., State 1’s local security policy). At the top of Figure 4.6, UML classes represent: Roles, with RoleID, RoleN, RoleD. and RoleR as string type members (defined in the MRI schema); Permissions, with read and write as Boolean members; and Entities with two generic object members, one extended with the «atomic» stereotype and the other with a «nonatomic» stereotype. Since entities can exhibit structural differences (e.g., an element in an XML schema can have multiple node children, or the XML element might be a leaf in the XML schema tree), we categorize utilizing two stereotypes, «atomic» and «nonatomic».
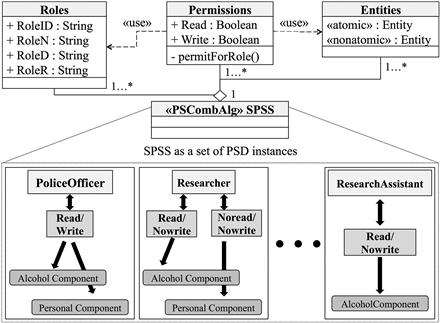
The Permissions class has a dependency relationship between the Roles and Entities classes to grant permission and verify the role and entity of the permission targets. All three classes have an instance level relationship of composition with the parent local security policy SPSS, which is shown at the bottom of Figure 4.6, where SPSS is a union of the various PSDs.
Note that the union of PSDs that yields the local security policy is not performed as a traditional mathematical set union. In order for security policies to maintain a proper degree of semantics, policy combination algorithms exist to determine the result of a policy evaluation when one or more rules (or policies in the case of policy sets in XACML) is inconsistent. For example, the XACML specification offers combination algorithms such as: Deny-overrides, in which a policy is denied if at least one of the rules is denied; Permit-overrides, in which a policy is permitted if at least one of the rules is permitted; First-applicable, in which the result of the first rule’s evaluation is treated as the result of all evaluations; and Only-one-applicable, in which the combined result is the corresponding result to the acting rule. To maintain an equivalent level of knowledge in the SPSS, the union of its PSDs must be performed in a similar manner (to respect the local system’s enforcement definitions). Towards this end, four corresponding policy slice combination algorithm stereotypes («deny-overrides», «permit-overrides», «first-applicable», «only-one-applicable») are assigned to the SPSS, which specifies which combination policy is enforced by local security policy (not shown due to space limits). In Figure 4.6, one of these four stereotypes would take the place of the «PSCombAlg».
Integrating local security policies into a global security policy
With the constituent security policies modeled as Local SPSS (LSPSS, with their granular segments with respect to roles represented as PSDs with the implied security rules), policy integration can be performed at the model level for a Global SPSS (GSPSS). In this section, we present a process for integrating a set of LSPSSs (for different states) into a GSPSS for the new big-data Crash Repository by using the MRI and security rules for each local SPSS. The four subsections discuss the following topics, respectively: our assumptions and various new concepts; the integration process of LSPPSs into a GSPSS; the security rule conflict resolution process; and the GSPSS that is generated for the big-data IE repository from the integration process that can be used via the big-data Crash Repository to provide access to constituent systems.
Assumptions and equivalence finding
The intent of the LSPPS is to allow each constituent local system (e.g., State 1 in Figure 4.1) to define one or multiple LSPSSs that contain different PSDs in order to tailor the information they are interested in publishing for inclusion in the GSPSS, which supports the big-data Crash Repository used by various stakeholders. In support of these ideas, there is an associated three-step development process as shown in Figure 4.7:
1. Local systems create one or more security policies (or specialized security policies) for information exchange that are publishable for public use by the big-data Crash Repository, which wants to subscribe to some or all of the information, functionality, or other entities governed by local security policies. This is shown in the leftmost box of Figure 4.7.
2. A new big-data application, like Crash Repository, is developed that will utilize resources from the local systems (specific LPSSs for states) by examining the exposed (published) instances, that is, the available LPSSs per constituent system. The new big-data application can subscribe to any policies exposed for public use that are relevant.
3. The new global security policy GSPSS for the new big-data application (Crash Repository) needs to integrate the exposed (published) local policies (LSPSSs of states) that have been subscribed to and merge them appropriately with the new security requirements of the new big-data application. This is shown in far right of the fourth box of Figure 4.7.
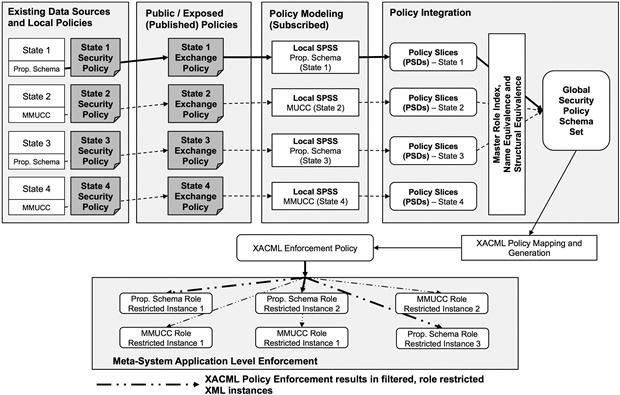
The publisher/subscriber paradigm (second and third boxes from left in Figure 4.7) provides an ideal way for the data source owner (local system) to decide what to present to whom, in order to reconcile the naming conventions of roles and their permissions and to clearly understand the way information can be shared and the scope of roles and their permissions against that information (entities). We assume that each LSPSS has its own set of security rules captured as XML instance triples <role, permission, entity>, and that the local application (e.g., State 1 in Figure 4.1) may have multiple policies (see Figures 4.4, 4.5, and 4.6 again). We further assume that it possible in an automated fashion to attempt to match across a given set of LSPSSs to determine which policy slices (or portions of policy slices) have some level of equivalence. To accomplish this, we apply two types of equivalence used in programming language typing: name equivalence and structural equivalence, as shown in the Policy Integration box (upper right of Figure 4.7).
In name equivalence, recall that the MRI schema (discussed in the previous section ‘Extensions for Policy Modeling and Integration) is a shared resource instantiated with an initial set of roles (in our case, for IE Repository, the roles PoliceOfficer, DOTWorker, Attorney, and Researcher). As each State/system (see Figure 4.1) establishes its own LSPSS (publishes a PSD or portion thereof), it is free to use existing instances (roles) in MRI, or to define new roles, thereby expanding this shared role repository. Notably, State 1 or State 2 may wish to expose only some of its PSDs, and, for each PSD, may want to limit the security rules even further. For name equivalence, if State 1 (from Figure 4.1) has a PSD with RoleID “1234” (PoliceOfficer) with RoleDescription and RoleRequirements (see Figure 4.2), and State 2 has a PSD with Role “1234” (PoliceOfficer) with the same RoleDescription and RoleRequirements values, these are clearly equivalent by name. This means they have the potential to also be structurally equivalent, but only to some degree. This is because the security rules are unique for each system: State 1 has its own set of security rules, and the ones for the PoliceOfficer role might be different from the security rules for the PoliceOfficer role in State 2. To see if the rules are the same, an algorithm for structural equivalence needs to be executed. We ask ourselves, does PoliceOfficer, as given in Figure 4.4(b) for State 1, have the exact same list of 14 security rules as the PoliceOfficer PSD for State 2? The hierarchies do not have to be identical, but the security rules that are constructed from each PSD must be equivalent, namely:
![]()
The level of structural equivalence can vary, if for instance:
![]()
meaning that there are some rules in PoliceOfficer PSD for State 2 that are not present in State 1.
These equivalences (and containment) at the structural level are crucial to allow sharing among systems in a consistent manner. A GSPSS can be constructed for Crash Repository by its subscription to the available LSPSSs of the constituent systems (states). Unlike integrating homogeneous policies (policies utilized on the same application, with roles, permissions, rules, and so on that target a limited, unchanged set of resources), our process aims to integrate heterogeneous policies (which contain equivalent and nonequivalent roles and permissions) that act on different resources utilized and provided by different local systems. To successfully create the GSPSS for a new system like Crash Repository, the SPSSs need to be integrated via similarity finding (name equivalence and structural equivalence) and other techniques that analyze PSDs and their security rules across a set of published LSPSSs requested by the GSPSS.
Integration process for local SPSS
The integration process among multiple LSPSSs that are made available to the big-data application (Crash Repository) involves a name equivalence (among roles), utilizing the MRI, and structural equivalences (between security rules). Name equivalence verification among roles of heterogeneous local systems can be achieved by utilizing the MRI, where two roles are name equivalent if and only if their respective RoleName, Role Description, and RoleRequirements are the same (see right side of Figure 4.2 for XRSD). The formal definition is as follows:

Finding name equivalences results in two sets of roles, an equivalent set (EqualRoles), which satisfy the above definition, and an unmatched set of roles (DistinctRoles), which do not match any other roles. The PSDs that correspond to the roles in the set DistinctRoles can automatically become part of the new GSPSS (if the LSPSS is subscribed to), as there is no risk of conflict with other roles and their respective security rules. Note that two roles that are name equivalent may still have differing sets of security rules in their respective PSDs. As a result, structural equivalence must also be quantified.
Structural equivalence is a process that assumes name equivalence is met and then proceeds to examine the actual security rules for each of the involved PSDs of LSPSSs. To verify structural equivalence, it is necessary to examine the security rules set (SRSet) of each involved PSD. Four possible combinations can result from comparing two security rule sets (SRSets):
• Equality, where the SRSets of two systems are contained within one another;
• Containment, where the SRSet of one PSD fully contains the SRSet of another PSD (proper containment, hence not equal);
• Intersection, where the SRSets of two PSDs have at least one SR rule in common (intersection is not empty); and
• Disjoint, where the SRSets of two systems with equivalent roles have no security rules in common (intersection is the empty set).
These relationships can result from either security rules overlapping with one another or different entities being available as resources on one system but not the rest (recall the security rule triple discussed in the section on extensions for policy modeling and integration).
Successfully integrating these SRSets while maintaining a proper level of security that complies with the local security requirements of constituent systems depends on the resulting relation between SRSets. Equality between SRSets is trivial; since no conflict can arise, both security rule sets can be consolidated and made part of the GSPSS. Handling SRSets that have a containment relation (proper subset) results in a subset of security rules being added to the GSPSS (all of the security rules of the contained smaller set), leaving the complement of the contained set in a state of conflict. There are two cases of intersection between two SRSets: When null, the SRSets are disjoint, both SRSets are in a state of conflict and there are two options: either include them both or omit them both from the GSPSS. When non-null, only the intersection is included, which means that security rules not in the intersection must be excluded.
Resolving conflicts of integrated security rule sets
This subsection discusses alternatives to resolve conflicts between intersected sets (security rules not in the intersection) and disjoint sets (SRSets that have no rules in common). Conflict resolution can be achieved through either a fully automated approach, which makes hard assumptions in order to provide the highest level of access control, or a human-guided approach, where human intervention is necessary to select which security rules will become part of the GSPSS, due to the intersection and disjoint cases. For an automated approach, there are different options capable of maintaining a proper sense of security:
• Safe and lazy approach: The GSPSS (e.g., Crash Repository) utilizes the most restrictive security rules, with respect to the entity involved, ensuring that no destructive operations (write) or breach in access (reading) can be performed; security rules are excluded if not held in common.
• Data Owner over Requester: The GSPSS utilizes the security rules specified by the data owner (e.g., a repository, and only if available), disregarding other, conflicting security rules.
• Hierarchical approach: A hierarchical order is given to the constituent local systems (and their LSPPSs of state repositories) to determine which security rules takes precedence over others. This order of priority results in security rules for a local system that can cover a wide spectrum in terms of the information to be published. That is, the granularity of data could range from a detailed patient record (lower level of a hierarchy) to an aggregation of records from a patient cohort (group that shares similar characteristics) for a population study (higher in the hierarchy).
While these automated approaches maintain a robust level of security, they also present limitations. In the case of the safe and lazy approach, there could be automatic denials of access that might have been authorized in the local system via human intervention. The data owner approach makes it possible to grant access to an otherwise secured request. In our example, State 1 can allow read permissions to Researchers in a localized manner (only when using the local system), but the big-data Crash Repository may want to limit the number of reads to a subset of the information or to the entire operation. The hierarchical approach offers the best alternative for resolving conflicts, but the implementation depends highly on the information published by LSPSSs being ranked by some process (or human). While there are natural hierarchies of information and its granularity in some domains such as health care, this is not necessarily the case in others.
Clearly, the safest approach to conflict resolution relies on human intervention in order to more create the appropriate GSPSS for a big-data application like Crash Repository. This is not an unreasonable requirement, given our modeling and engineering approach to policy integration, since the human designer of the new application is already examining the published PSDs for each LSPSS in order to decide which ones are relevant for the new information exchange/sharing application. The only additional task for the designer would be to make a final decision regarding any conflicting security rules. Potentially, if no name equivalence or structural equivalence exists between SRSets, the designer has to select each security rule that will become part of the system.
Creating the global SPSS
The software engineer who is creating the big-data Crash Repository will use the capabilities and the potential integration of LSPPs discussed in the preceding two subsections to arrive at a GSPSS that contains all of the relevant security rules for Crash Repository, with respect to the roles, packaged into respective Global Policy Slices. Using the approach discussed in this chapter, we deconstruct the local security policies by modeling them as SPSS (higher level), PSD (intermediate level), and SRSet (lower level), and we build the GSPSS following a bottom-up approach (from SRSets to Global PSDs to Global SPSS). Assuming that all of the SRSet conflicts have been resolved, whether using a human-guided or an automated approach that satisfies the new system’s security requirements, the process of building the GSPSS involves three steps.
In the first step, Global Policy Slice Diagrams are built utilizing the SRSets with respect to roles. This is done with the aid of the MRI, following Definition 1 (see the subsection on integrating the local SPSS), ensuring that name equivalence is correct and that we are packaging the properly equivalent SRSets.
In the second step, a translation between the security rules represented in the PSDs (recall the triple SR=<Role (r), Permission (p), Entities (ents)> and see Figures 4.4 and 4.6) and UML class members for the Global Policy Slice Diagrams is performed. To achieve this, we group the security rules by Role and Entities, and propose the following equivalence:
• The combination of possible permissions (read, write) and entities from the SR will result in a class method with a stereotype that determines whether execution of the method is permitted («allow») or denied («deny»).
The third and final step is structuring the UML GSPSS artifact with respect to roles, as shown for the Crash Repository in Figure 4.8. This involves several rules and steps:
• Roles that will be part of the GSPSS (e.g., Crash Repository) are represented as UML subclasses of the GSPSS class (Figure 4.8). The role classes are named after their respective roles.
• Each role class will have descriptive string members, RoleDescription and RoleRequirements, per the MRI.
• Each role class will have methods as given in the second step of the integration. This means that two methods per targeted entity of each role will be given, as dictated by the SRs.
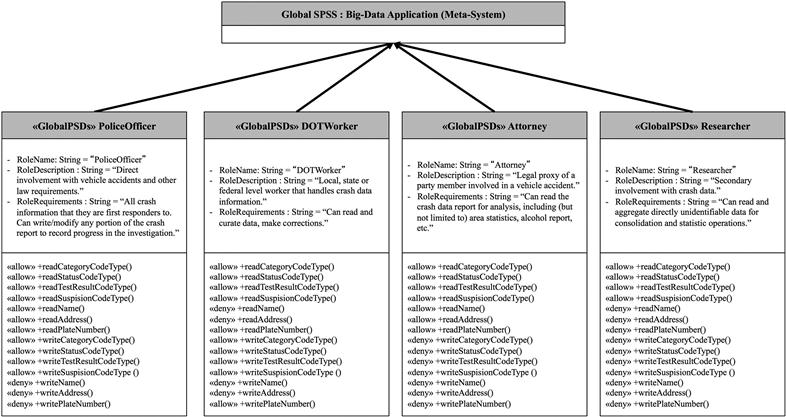
Figure 4.8 Example of a global security policy schema set.
As an example, assume that multiple PoliceOfficer, DOTWorker, Attorney, and Researcher PSDs were integrated from State 1 and State 2 (from Figure 4.1). Roles are represented as subclasses of the parent GSPSS class of Crash Repository as shown in Figure 4.8. The subclasses named after the respective roles (PoliceOfficer, DOTWorker, Attorney, and Researcher) have two string members, which are instantiated to the MRI values of the RoleDescription and RoleRequirements. In turn, these classes have one method per each security rule, and their permissions are given as attached UML stereotypes. The DOTWorker and Attorney roles are structured similarly.
Note that the structure of the GSPSS is different from the local (L) SPSS structure (shown in Figure 4.6). The justification for this lies in the end use of each of these structures. In the case of the LSPSS (Figure 4.6), it tries to model an already existing security policy in order to obtain the policy slices (and in turn, security rules) without the loss of structure or information. The GSPSS for Crash Repository, on the other hand, is the result of integration that will be utilized as a blueprint for the generation of an actual enforcement policy. For this reason, we chose to structure the GSPSS in a role centric way, which simplifies the mapping process for the enforcement policy generation.
Finally, as shown in the bottom portion of Figure 4.7, the generation of XACML Enforcement Policy from the GSPSS follows a process similar to the one we used in our earlier research [4], where XACML policies were generated from modeled Role Slice Diagrams (see Figure 4.2 again). The benefit of utilizing the GSPSS as the blueprint for generating an XACML policy is that a similarity finding does not need to be performed (since it was done as part of the name and structural equivalence); instead, we are provided with an already organized diagram that only requires direct translation to code. As also shown in the bottom of Figure 4.7, the generated XACML policy, when applied to instances of the XML Schema (modeled as an XSCD in Figure 4.2), yields a set of role-restricted instances for the Crash Repository that interact with the LPSSs of the states. This means that the instances for each stakeholder are filtered by role prior to delivery for use via a combination of the XACML enforcement policies at both the LSPSS and GSPSS levels.
Related work
In this section, we describe and compare related research work done in three areas: big-data security, policy and security modeling, and policy integration methods. Big-data security is often aimed at the data storage system, the back end of the system. For example, security approaches for big-data are often aimed at the data warehouses or storage systems (https://securosis.com/assets/library/reports/SecuringBigData_FINAL.pdf). While this information is important, we have instead focused on the front end, the users of the big-data application, in this case, control access to IE Repository. Another common approach to relating big-data with security is to exploit the former to improve the latter. Big-data repositories can serve as knowledge bases to create more robust reactive and proactive security mechanisms (http://codeascraft.com/2013/06/04/leveraging-big-data-to-create-more-secure-web-applications/). As a matter of fact, the nature of the big-data security problem reduces the importance of security at the user level, and encourages problem-solving efforts to be focused instead on performance and reliability of operations (http://www.darkreading.com/applications/security-implications-of-big-data-strate/240151074), as well as the development of applications devoted to efficient data exploration and discovery (http://www.ibm.com/developerworks/library/bd-exploration/).
While the motivation for security in big-data scenarios is well defined (http://unm2020.unm.edu/knowledgebase/technology-2020/14-are-you-ready-for-the-era-of-big-data-mckinsey-quarterly-11-10.pdf; http://www.stanfordlawreview.org/online/privacy-paradox/big-data) [5,6], at the time of this writing, despite extensive literature research, we were unable to find any related work on big-data security from the meta-system perspective, for example, defining and controlling what the stakeholders of IE Repository are allowed to do at what times. We believe that the work presented in this chapter is one of the earliest attempts at interpreting big-data security from the perspective of the application (IE Repository) and its stakeholders.
For security and policy modeling, SecureUML [7], an approach based on RBAC and UML, combines a graphical notation for RBAC with constraints. It allows policies to be expressed using RBAC permissions, and complex security requirements can be done with a combination of authorization constraints. In our work, we take a similar graphical approach but concentrate on modeling and securing XML via the XSCD and XRSD diagrams (see Figure 4.2). A later effort [8] presents a model-driven security approach for designers to set security requirements along with system models to automatically generate an access control infrastructure. This approach combines UML with a security modeling language defining a set of modeling transformations; the former produces infrastructures for JavaBeans, and the latter can generate secure infrastructures for Web applications. Our work is done at a higher conceptual level. With respect to Web service security, [9] utilizes the model-driven architecture paradigm to achieve security for e-government scenarios with inter-collaboration/communication. This is achieved by describing security requirements at a high level (models), with relevant security artifacts being automatically generated for target architectures. This removes the otherwise present learning curve concerning specifying security requirements by domain experts with no technical know-how. This is dramatically different from our work, which is focused on information exchange and its security assurance. Similar to our presented work, [10] uses aspect-oriented programming and a generic security meta-model for the automatic generation of platform specific XACML. In contrast, our approach’s objective is to model security policies for eventual integration for a distributed scope.
Policy integration approaches vary from similarity finding to specialized algebraic approaches. For example, [11,12] present a policy integration methodology to find similarity of policies on distinct levels (rule effects, targets, roles), and to integrate a set of defined rules with regard to policy decision conflicts. This is similar to our work, but differs in that our integration is done at the instance level (XACML) and involves homogeneous policies, while heterogeneous policies (LSPSSs) are integrated into a global one (GSPSS). Another approach [13] addresses the problem of integrating complex security policies at a detailed granular level using an algebraic solution that consists of five unary operations (three binary and two unary). This algebra is utilized as part of a framework for generating an instance policy automatically. Like [12], this approach also focuses on the instance level, creating a dependency on the OASIS XACML specification and policy structure to achieve proper results. These methods could not be used on security requirements defined in any other method (e.g., a database table with security rules, policies modeled with a different language, etc.).
Conclusion
In this chapter, we have presented a local policy integration process for sharing and exchanging XML that leverages UML as a policy-modeling tool, which has also been integrated into our prior work of security at a modeling level (Section 2 and [3,4]) and allows definition of a global security policy that supports a role-based access control approach for the stakeholders of a big-data application. We began by briefly reviewing our prior work [3,4] and introducing the XML schema class diagram (XSCD) and XML role slice diagram (XRSD) as given in Figure 4.2. Next, we introduced new modeling artifacts to support security policy definition in XML. These are a Master Role Index (MRI) that tracks the roles by names that can occur in multiple constituent systems that are used by a big application, and,two new UML diagrams to represent security policies for both the local and global systems: the Policy Slice Diagram (PSD) to track roles across systems, and the Security Policy Schema Set (SPSS) to represent the security policy for a set of interconnected PSDs. Using this as a basis, we are able to define local, heterogeneous SPSSs and integrate them into an all-encompassing global SPSS that contains all of the logic and semantic information of the constituent LSPSSs. In turn, this GSPSS can be utilized as a blueprint to automatically generate an enforcement XACML policy that can be readily deployed to a newly developed meta-system that uses data from across distinct repositories, such as the big-data Crash Repository example. Throughout the chapter we have employed an Crash Repository big-data application but focus the security on stakeholders and their access to the information.
The work presented in this chapter dovetails with our other three related research efforts. First, in [3] we proposed role-based access control extensions to UML that are capable of modeling XML schemas as a class level via the XSCD and capturing their role-based privileges via XRSD; as a result, security can be represented as a set of rules and permissions that a role has with respect to a specific element of an XML schema. Second, in [4], we presented the automatic generation of XACML security policies from the XML Role Slice Diagram, which can be used to model the XML security for a single local system, the predecessor of LSPSS in this chapter. Finally, in [14], we applied our work in [3,4] to a distributed, information exchange context where each local system in a group provides a set of resources that can define applications to use one or more of the local systems, with security enforced against XML using our approach in [3].
References
1. Ferraiolo DF, Sandhu R, Gavrila S, Kuhn DR, Chandramouli R. Proposed NIST standard for role-based access control. ACM Transactions on Information and System Security (TISSEC). 2001;4:224–274.
2. Liebrand M, Ellis H, Phillips C, Ting T. Role delegation for a distributed, unified RBAC/MAC. In: Proceedings of Sixteenth Annual IFIP WG 11.3 Working Conference on Data and Application Security King’s College; 2002. p. 29–31.
3. De la Rosa Algarín A, Demurjian SA, Berhe S, Pavlich-Mariscal J. A security framework for XML schemas and documents for healthcare. Proceedings of 2012 International Workshop on Biomedical and Health Informatics 2012;782–789.
4. De la Rosa Algarín A, Ziminski TB, Demurjian SA, Kuykendall R, Rivera Sánchez Y. Defining and enforcing XACML role-based security policies within an XML security framework. Proceedings of 9th International Conference on Web Information Systems and Technologies (WEBIST 2013) 2013;16–25.
5. Boyd D, Crawford K. Critical questions for big-data: Provocations for a cultural, technological, and scholarly phenomenon. Information, Communication & Society. 2012;15:662–679.
6. Chaudhuri S. What next?: A half-dozen data management research goals for big-data and the cloud. Proceedings of the 31st symposium on Principles of Database Systems 2012;1–4.
7. Lodderstedt T, Basin D, Doser J. SecureUML: a UML-based modeling language for model-driven security. «UML» 2002—The Unified Modeling Language; 2002. p. 426–441.
8. Mouelhi T, Fleurey F, Baudry B, Le Traon Y. A model-based framework for security policy specification, deployment and testing. Model Driven Engineering Languages and Systems 2008;537–552.
9. Basin D, Doser J, Lodderstedt T. Model driven security: From UML models to access control infrastructures. ACM Transactions on Software Engineering and Methodology (TOSEM). 2006;15:39–91.
10. Breu R, Hafner M, Weber B, Novak A. Model driven security for inter-organizational workflows in e-government. E-Government: Towards Electronic Democracy 2005;122–133.
11. Mazzoleni P, Bertino E, Crispo B, Sivasubramanian S. XACML policy integration algorithms: Not to be confused with XACML policy combination algorithms!. Proceedings of the eleventh ACM symposium on access control models and technologies 2006;219–227.
12. Mazzoleni P, Crispo B, Sivasubramanian S, Bertino E. XACML policy integration algorithms. ACM Transactions on Information and System Security (TISSEC). 2008;11:4.
13. Rao P, Lin D, Bertino E, Li N, Lobo J. An algebra for fine-grained integration of XACML policies. Proceedings of the 14th ACM symposium on access control models and technologies 2009;63–72.
14. De la Rosa Algarín A, Demurjian SA, Ziminski TB, Rivera Sanchez YK, Kuykendall R. Securing XML with role-based access control: Case study in health care. In: Ruiz Martínez A, Pereñíguez García F, Marín López R, editors. Architectures and Protocols for Secure Information Technology. p. 334–65. IGI Global; 2013.