
This section introduces several techniques used to learn from stream data when the true label for each instance is available. In particular, we present linear, non-linear, and ensemble-based algorithms adapted to incremental learning, as well as methods required in the evaluation and validation of these models, keeping in mind that learning is constrained by limits on memory and CPU time.
The modeling techniques are divided into linear algorithms, non-linear algorithms, and ensemble methods.
The linear methods described here require little to no adaptation to handle stream data.
Different loss functions such as hinge, logistic, and squared error can be used in this algorithm.
Only numeric features are used in these methods. The choice of loss function l and learning rate λ at which to apply the weight updates are taken as input parameters. The output is typically updatable models that give predictions accompanied by confidence values.
The basic algorithm assumes linear weight combinations similar to linear/logistic regression explained in Chapter 2, Practical Approach to Real-World Supervised Learning. The stream or online learning algorithm can be summed up as:
- for(t=1,2,…T) do
- xt = receive(); // receive the data
 ; //predict the label
; //predict the label
- yt = obtainTrueLabel(); // get the true label
- loss = l(wt, (xt, wt)); // calculate the loss
- if(l(wt,(xt, wt )) > 0 then
 ; //update the weights
; //update the weights
- end
- end
Different loss functions can be plugged in based on types of problems; some of the well-known types are shown here:
- Classification:
- Hinge loss: l(wt, (xt, wt)) = max(0, 1 – yf(xt, wt))
-
Logistic loss:

- Regression:
-
Squared loss:

-
Squared loss:
Stochastic Gradient Descent (SGD) can be thought of as changing the weights to minimize the squared loss as in the preceding loss functions but going in the direction of the gradient with each example. The update of weights can be described as:

Online linear models have similar advantages and disadvantages as the linear models described in Chapter 2, Practical Approach to Real-World Supervised Learning:
- Interpretable to some level as the weights of each features give insights on the impact of each feature
- Assumes linear relationship, additive and uncorrelated features, and hence doesn't model complex non-linear real-world data
- Very susceptible to outliers in the data
- Very fast and normally one of the first algorithms to try or baseline
Bayes theorem is applied to get predictions as the posterior probability, given for an m dimensional input:

Online Naïve Bayes can accept both categorical and continuous inputs. The categorical features are easier, as the algorithm must maintain counts for each class while computing the P(Xj|Y) probability for each feature given the class. For continuous features, we must either assume a distribution, such as Gaussian, or to compute online Kernel Density estimates in an incremental way or discretize the numeric features incrementally. The outputs are updatable models and can predict the class accompanied by confidence value. Being probabilistic models, they have better confidence scores distributed between 0 and 1.
One of the most popular non-linear stream learning classifiers in use is the Hoeffding Tree. In the following subsections, the notion of the Hoeffding bound is introduced, followed by the algorithm itself.
The key idea behind Hoeffding Trees (HT) is the concept of the Hoeffding bound. Given a real-valued random variable x whose range of values has size R, suppose we have n independent observations of
x and compute the mean as ![]() .
.
The Hoeffding bound states that, with a probability of 1 – δ, the actual mean of the variable x is at least ![]() where
where 
The Hoeffding bound is independent of the probability distribution generating the samples and gives a good approximation with just n examples.
The idea of the Hoeffding bound is used in the leaf expansion. If x1 is the most informative feature and x2 ranks second, then split using a user-defined split function G(.) in a way such that:

Both categorical and continuous data can be part of the data input. Continuous features are discretized in many implementations. The desired probability parameter 1 – δ and the split function common to Decision Trees G(.) becomes part of the input. The output is the interpretable Decision Tree model and can predict/learn with class and confidence values.
HoeffdingTree(x:inputstream,G(.):splitFunction,δ:probabilityBound)
- Let HT be a tree with single leaf(root)
- InitCounts(nijk, root)
- for(t=1,2,…T) do //all data from stream
- xt = receive(); //receive the data
- yt = obtainTrueLabel(); //get the true label
- HTGrow((xt, yt), HT, δ)
- end
HTGrow((xt, yt), HT, G(.), δ)
- l = sort((xt, yt), HT); //sort the data to leaf l using HT
- updateCounts(nijk, l); // update the counts at leaf l
- if(examplesSoFarNotOfSameClass();// check if there are multiple classes
- computeForEachFeature(,G(.))

Hoeffding Trees have interesting properties, such as:
- They are a robust low variance model
- They exhibit lower overfitting
- Theoretical guarantees with high probability on the error rate exist due to Hoeffding bounds
There are variations to Hoeffding Trees that can adapt concept drift, known as Concept-Adapting VFDT. They use the sliding window concept on the stream. Each node in the decision tree keeps sufficient statistics; based on the Hoeffding test, an alternate subtree is grown and swapped in when the accuracy is better.
The advantages and limitations are as follows:
- The basic HT has issues with attributes being close to the chosen ϵ and breaks the ties. Deciding the number of attributes at any node is again an issue. Some of it is resolved in VFDT.
- Memory constraints on expansion of the trees as well as time spent on an instance becomes an issue as the tree changes.
- VFDT has issues with changes in patterns and CVFDT tries to overcome these as discussed previously. It is one of the most elegant, fast, interpretable algorithms for real-time and big data.
The idea behind ensemble learning is similar to batch supervised learning where multiple algorithms are trained and combined in some form to predict unseen data. The same benefits accrue even in the online setting from different approaches to ensembles; for example, using multiple algorithms of different types, using models of similar type but with different parameters or sampled data, all so that different search spaces or patterns are found and the total error is reduced.
The weighted majority algorithm (WMA) trains a set of base classifiers and combines their votes, weighted in some way, and makes predictions based on the majority.
The constraint on types of inputs (categorical only, continuous only, or mixed) depends on the chosen base classifiers. The interpretability of the model depends on the base model(s) selected but it is difficult to interpret the outputs of a combination of models. The weights for each model get updated by a factor (β) per example/instance when the prediction is incorrect. The combination of weights and models can give some idea of interpretability.
WeightedMajorityAlgorithm(x: inputstream, hm: m learner models)
- initializeWeights(wi)
- for(t=1, 2,…T) do
- xt = receive();
- foreach model hk ∈ h
- yi ← hk(xt);


-
else

- if y is known then
- for i = 1 to m do
- if yi ≠ y then
- wi ← wi * β
end if
end for
- end
As we saw in the chapter on supervised learning, the bagging algorithm, which creates different samples from the training sets and uses multiple algorithms to learn and predict, reduces the variance and is very effective in learning.
The constraint on the types of inputs (categorical only, continuous only, or mixed) depends on the chosen base classifiers. The base classifier algorithm with parameter choices corresponding to the algorithm are also the inputs. The output is the learned model that can predict the class/confidence based on the classifier chosen.
The basic batch bagging algorithm requires the entire data to be available to create different samples and provide these samples to different classifiers. Oza's Online Bagging algorithm changes this constraint and makes it possible to learn from unbounded data streams. Based on sampling, each training instance in the original algorithm gets replicated many times and each base model is trained with k copies of the original instances where:
P(k) = exp(–1)/k!
This is equivalent to taking one training example and choosing for each classifier k~Poisson(1) and updating the base classifier k times. Thus, the dependency on the number of examples is removed and the algorithm can run on an infinite stream:
OnlineBagging(x: inputstream, hm: m learner models)
- initialize base models hm for all m ∈ {1,2,..M}
- for(t=1,2,…T) do
- xt=receive();
- foreach model m = {1,2,..M}
w = Poisson(1)
updateModel(hm, w, xt)
- end
- return

The advantages and limitaions are as follows:
The performance is entirely determined by the choice of the M learners—the type of learner used for the problem domain. We can only decide on this choice by adopting different validation techniques described in the section on model validation techniques.
The supervised boosting algorithm takes many weak learners whose accuracy is slightly greater than random and combines them to produce a strong learner by iteratively sampling the misclassified examples. The concept is identical in Oza's Online Boosting algorithm with modification done for a continuous data stream.
The constraint on types of inputs (categorical only, continuous only, or mixed) depends on the chosen base classifiers. The base classifier algorithms and their respective parameters are inputs. The output is the learned model that can predict the class/confidence based on the classifier chosen.
The modification of batch boosting to online boosting is done as follows:
- Keep two sets of weights for M base models, λc is a vector of dimension M which carries the sum of weights of correctly classified instances, and λw is a vector of dimension M, which carries the sum of weights of incorrectly classified instances.
- The weights are initialized to 1.
- Given a new instance (xt, yt), the algorithm goes through the iterations of updating the base models.
- For each base model, the following steps are repeated:
- For the first iteration, k = Poisson(λ) is set and the learning classifier updates the algorithm (denoted here by h1) k times using (xt, yt):
- If h1 incorrectly classifies the instance, the λw1 is incremented, ϵ1, the weighted fraction, incorrectly classified by h1, is computed and the weight of the example is multiplied by 1/2 ϵ1.
The advantages and limitations are as follows:
- Again, the performance is determined by the choice of the multiple learners, their types and the particular domain of the problem. The different methods described in the section on model validation techniques help us in choosing the learners.
- Oza's Online Boosting has been shown theoretically and empirically not to be "lossless"; that is, the model is different compared to its batch version. Thus, it suffers from performance issues and different extensions have been studied in recent years to improve performance.
In contrast to the modes of machine learning we saw in the previous chapters, stream learning presents unique challenges to performing the core steps of validation and evaluation. The fact that we are no longer dealing with batch data means the standard techniques for validation evaluation and model comparison must be adapted for incremental learning.
In the off-line or the batch setting, we discussed various methods of tuning the parameters of the algorithm or testing the generalization capability of the algorithms as a counter-measure against overfitting. Some of the techniques in the batch labeled data, such as cross-validation, are not directly applicable in the online or stream settings. The most common techniques used in online or stream settings are given next.
The prequential evaluation method is a method where instances are provided to the algorithm and the output prediction of the algorithm is then measured in comparison with the actual label using a loss function. Thus, the algorithm is always tested on the unseen data and needs no "holdout" data to estimate the generalization. The prequential error is computed based on the sum of the accumulated loss function between actual values and predicted values, given by:

Three variations of basic prequential evaluation are done for better estimation on changing data, which are:
- Using Landmark Window (basic)
- Using Sliding Window
- Using forgetting mechanism
The last two methods are extensions of previously described techniques where you put weights or fading factors on the predictions that reduce over time.
This is the extension of the holdout mechanism or "independent test set" methodology of the batch learning. Here the total labeled set or stream data is separated into training and testing sets, either based on some fixed intervals or the number of examples/instances the algorithm has seen. Imagine a continuous stream of data and we place well-known intervals at ![]() and
and ![]() to compare the evaluation metrics, as discussed in next section, for performance.
to compare the evaluation metrics, as discussed in next section, for performance.
The issue with the aforementioned mechanisms is that they provide "average" behavior over time and can mask some basic issues such as the algorithm doing well at the start and very poorly at the end due to drift, for example. The advantage of the preceding methods is that they can be applied to real incoming streams to get estimates. One way to overcome the disadvantage is to create different random sets of the data where the order is shuffled a bit while maintaining the proximity in time and the evaluation is done over a number of these random sets.
Most of the evaluation criteria are the same as described in the chapter on supervised learning and should be chosen based on the business problem, the mapping of the business problem to the machine learning techniques, and on the benefits derived. In this section, the most commonly used online supervised learning evaluation criteria are summarized for the reader:
- Accuracy: A measure of getting the true positives and true negatives correctly classified by the learning algorithm:

- Balanced accuracy: When the classes are imbalanced, balanced accuracy is often used as a measure. Balanced accuracy is an arithmetic mean of specificity and sensitivity. It can be also thought of as accuracy when positive and negative instances are drawn from the same probability in a binary classification problem.
- Area under the ROC curve (AUC): Area under the ROC curve gives a good measure of generalization of the algorithm. Closer to 1.0 means the algorithm has good generalization capability while close to 0.5 means it is closer to a random guess.
- Kappa statistic (K): The Kappa statistic is used to measure the observed accuracy with the expected accuracy of random guessing in the classification. In online learning, the Kappa statistic is used by computing the prequential accuracy (po) and the random classifier accuracy (pc) and is given by:

- Kappa Plus statistic: The Kappa Plus statistic is a modification to the Kappa statistic obtained by replacing the random classifier by the persistent classifier. The persistent classifier is a classifier which predicts the next instance based on the label or outcome of the previous instance.
When considering "drift" or change in the concept as discussed earlier, in addition to these standard measures, some well-known measures given are used to give a quantitative measure:
- Probability of true change detection: Usually, measured with synthetic data or data where the changes are known. It gives the ability of the learning algorithm to detect the change.
- Probability of false alarm: Instead of using the False Positive Rate in the off-line setting, the online setting uses the inverse of time to detection or the average run length which is computed using the expected time between false positive detections.
- Delay of detection: This is measured as the time required, terms of instances, to identify the drift.
When comparing two classifiers or learners in online settings, the usual mechanism is the method of taking a performance metric, such as the error rate, and using a statistical test adapted to online learning. Two widely used methods are described next:
- McNemar test: McNemar's test is a non-parametric statistical test normally employed to compare two classifiers' evaluation metrics, such as "error rate", by storing simple statistics about the two classifiers. By computing statistic a, the number of correctly classified points by one algorithm that are incorrectly classified by the other, and statistic b, which is the inverse, we obtain the McNemar's Test as:
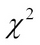
The test follows a χ2 distribution and the p-value can be used to check for statistical significance.
- Nemenyi test: When there are multiple algorithms and multiple datasets, we use the Nemenyi test for statistical significance, which is based on average ranks across all. Two algorithms are considered to be performing differently in a statistically significant way if the ranks differ by a critical difference given by:

Here, K=number of algorithms, N=number of datasets.
The critical difference values are assumed to follow a Student-T distribution.