
The use of sound, images, and videos is becoming a more important aspect of our day-to-day lives. Phone conversations and devices reliant on voice commands are increasingly common. People regularly conduct video chats with other people around the world. There has been a rapid proliferation of photo and video sharing sites. Applications that utilize images, video, and sound from a variety of sources are becoming more common.
In this chapter, we will demonstrate several techniques available to Java to process sounds and images. The first part of the chapter addresses sound processing. Both speech recognition and Text-To-Speech (TTS) APIs will be demonstrated. Specifically, we will use the FreeTTS (http://freetts.sourceforge.net/docs/index.php) API to convert text to speech, followed with a demonstration of the CMU Sphinx toolkit for speech recognition.
The Java Speech API (JSAPI) (http://www.oracle.com/technetwork/java/index-140170.html) provides access to speech technology. It is not part of the standard JDK but is supported by third-party vendors. Its intent is to support speech recognition and speech synthesizers. There are several vendors that support JSAPI, including FreeTTS and Festival (http://www.cstr.ed.ac.uk/projects/festival/).
In addition, there are several cloud-based speech APIs, including IBM's support through Watson Cloud speech-to-text capabilities.
Next, we will examine image processing techniques, including facial recognition. This involves identifying faces within an image. This technique is easy to accomplish using OpenCV (http://opencv.org/) which we will demonstrate in the Identifying faces section.
We will end the chapter with a discussion of Neuroph Studio, a neural network Java-based editor, to classify images and perform image recognition. We will continue to use faces here and attempt to train a network to recognize images of human faces.
Speech synthesis generates human speech. TTS converts text to speech and is useful for a number of different applications. It is used in many places, including phone help desk systems and ordering systems. The TTS process typically consists of two parts. The first part tokenizes and otherwise processes the text into speech units. The second part converts these units into speech.
The two primary approaches for TTS uses concatenation synthesis and formant synthesis. Concatenation synthesis frequently combines prerecorded human speech to create the desired output. Formant synthesis does not use human speech but generates speech by creating electronic waveforms.
We will be using FreeTTS (http://freetts.sourceforge.net/docs/index.php) to demonstrate TTS. The latest version can be downloaded from https://sourceforge.net/projects/freetts/files/. This approach uses concatenation to generate speech.
There are several important terms used in TTS/FreeTTS:
- Utterance - This concept corresponds roughly to the vocal sounds that make up a word or phrase
- Items - Sets of features (name/value pairs) that represent parts of an utterance
- Relationship - A list of items, used by FreeTTS to iterate back and forward through an utterance
- Phone - A distinct sound
- Diphone - A pair of adjacent phones
The FreeTTS Programmer's Guide (http://freetts.sourceforge.net/docs/ProgrammerGuide.html) details the process of converting text to speech. This is a multi-step process whose major steps include the following:
- Tokenization - Extracting the tokens from the text
- TokenToWords - Converting certain words, such as 1910 to nineteen ten
- PartOfSpeechTagger - This step currently does nothing, but is intended to identify the parts of speech
- Phraser - Creates a phrase relationship for the utterance
- Segmenter - Determines where syllable breaks occur
- PauseGenerator - This step inserts pauses within speech, such as before utterances
- Intonator - Determines the accents and tones
- PostLexicalAnalyzer - This step fixes problems such as a mismatch between the available diphones and the one that needs to be spoken
- Durator - Determines the duration of the syllables
- ContourGenerator - Calculates the fundamental frequency curve for an utterance, which maps the frequency against time and contributes to the generation of tones
- UnitSelector - Groups related diphones into a unit
- PitchMarkGenerator - Determines the pitches for an utterance
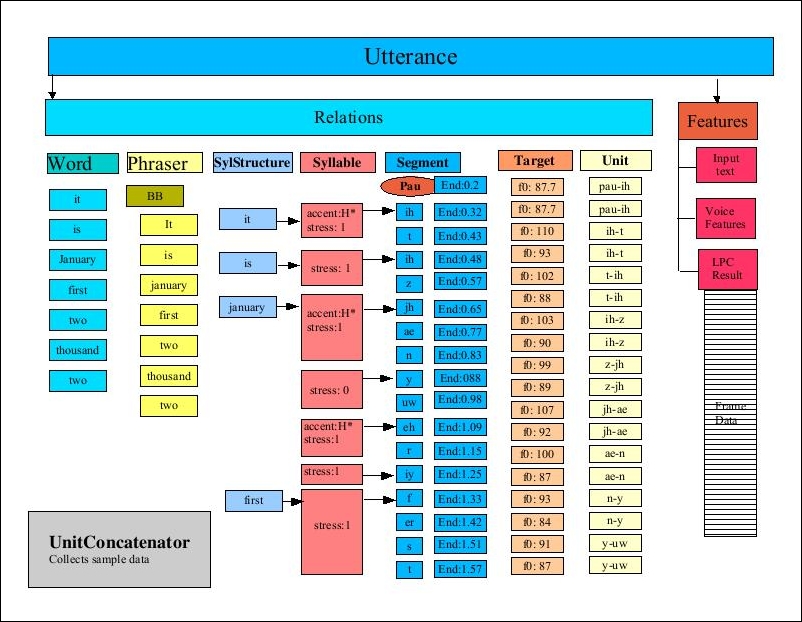
- UnitConcatenator - Concatenates the diphone data together
The following figure is from the FreeTTS Programmer's Guide, Figure 11: The Utterance after UnitConcatenator processing, and depicts the process. This high-level overview of the TTS process provides a hint at the complexity of the process:
TTS system facilitates the use of different voices. For example, these differences may be in the language, the sex of the speaker, or the age of the speaker.
The MBROLA Project's (http://tcts.fpms.ac.be/synthesis/mbrola.html) objective is to support voice synthesizers for as many languages as possible. MBROLA is a speech synthesizer that can be used with a TTS system such as FreeTTS to support TTS synthesis.
Download MBROLA for the appropriate platform binary from http://tcts.fpms.ac.be/synthesis/mbrola.html. From the same page, download any desired MBROLA voices found at the bottom of the page. For our examples we will use usa1, usa2, and usa3. Further details about the setup are found at http://freetts.sourceforge.net/mbrola/README.html.
The following statement illustrates the code needed to access the MBROLA voices. The setProperty method assigns the path where the MBROLA resources are found:
System.setProperty("mbrola.base", "path-to-mbrola-directory");
To demonstrate how to use TTS, we use the following statement. We obtain an instance of the VoiceManager class, which will provide access to various voices:
VoiceManager voiceManager = VoiceManager.getInstance();
To use a specific voice the getVoice method is passed the name of the voice and returns an instance of the Voice class. In this example, we used mbrola_us1, which is a US English, young, female voice:
Voice voice = voiceManager.getVoice("mbrola_us1");
Once we have obtained the Voice instance, use the allocate method to load the voice. The speak method is then used to synthesize the words passed to the method as a string, as illustrated here:
voice.allocate();
voice.speak("Hello World");
When executed, the words "Hello World" should be heard. Try this with other voices, as described in the next section, and text to see which combination is best suited for an application.
The VoiceManager class' getVoices method is used to obtain an array of the voices currently available. This can be useful to provide users with a list of voices to choose from. We will use the method here to illustrate some of the voices available. In the next code sequence, the method returns the array, whose elements are then displayed:
Voice[] voices = voiceManager.getVoices();
for (Voice v : voices) {
out.println(v);
}
The output will be similar to the following:
CMUClusterUnitVoice CMUDiphoneVoice CMUDiphoneVoice MbrolaVoice MbrolaVoice MbrolaVoice
The getVoiceInfo method provides potentially more useful information, though it is somewhat verbose:
out.println(voiceManager.getVoiceInfo());
The first part of the output follows; the VoiceDirectory directory is displayed followed by the details of the voice. Notice that the directory name contains the name of the voice. The KevinVoiceDirectory contains two voices: kevin and kevin16:
VoiceDirectory 'com.sun.speech.freetts.en.us.cmu_time_awb.AlanVoiceDirectory' Name: alan Description: default time-domain cluster unit voice Organization: cmu Domain: time Locale: en_US Style: standard Gender: MALE Age: YOUNGER_ADULT Pitch: 100.0 Pitch Range: 12.0 Pitch Shift: 1.0 Rate: 150.0 Volume: 1.0 VoiceDirectory 'com.sun.speech.freetts.en.us.cmu_us_kal.KevinVoiceDirectory' Name: kevin Description: default 8-bit diphone voice Organization: cmu Domain: general Locale: en_US Style: standard Gender: MALE Age: YOUNGER_ADULT Pitch: 100.0 Pitch Range: 11.0 Pitch Shift: 1.0 Rate: 150.0 Volume: 1.0 Name: kevin16 Description: default 16-bit diphone voice Organization: cmu Domain: general Locale: en_US Style: standard Gender: MALE Age: YOUNGER_ADULT Pitch: 100.0 Pitch Range: 11.0 Pitch Shift: 1.0 Rate: 150.0 Volume: 1.0 ... Using voices from a JAR file
Voices can be stored in JAR files. The VoiceDirectory class provides access to voices stored in this manner. The voice directories available to FreeTTs are found in the lib directory and include the following:
cmu_time_awb.jarcmu_us_kal.jar
The name of a voice directory can be obtained from the command prompt:
java -jar fileName.jar
For example, execute the following command:
java -jar cmu_time_awb.jar
It generates the following output:
VoiceDirectory 'com.sun.speech.freetts.en.us.cmu_time_awb.AlanVoiceDirectory' Name: alan Description: default time-domain cluster unit voice Organization: cmu Domain: time Locale: en_US Style: standard Gender: MALE Age: YOUNGER_ADULT Pitch: 100.0 Pitch Range: 12.0 Pitch Shift: 1.0 Rate: 150.0 Volume: 1.0
The Voice class provides a number of methods that permit the extraction or setting of speech characteristics. As we demonstrated earlier, the VoiceManager class' getVoiceInfo method provided information about the voices currently available. However, we can use the Voice class to get information about a specific voice.
In the following example, we will display information about the voice kevin16. We start by getting an instance of this voice using the getVoice method:
VoiceManager vm = VoiceManager.getInstance();
Voice voice = vm.getVoice("kevin16");
voice.allocate();
Next, we call a number of the Voice class' get method to obtain specific information about the voice. This includes previous information provided by the getVoiceInfo method and other information that is not otherwise available:
out.println("Name: " + voice.getName());
out.println("Description: " + voice.getDescription());
out.println("Organization: " + voice.getOrganization());
out.println("Age: " + voice.getAge());
out.println("Gender: " + voice.getGender());
out.println("Rate: " + voice.getRate());
out.println("Pitch: " + voice.getPitch());
out.println("Style: " + voice.getStyle());
The output of this example follows:
Name: kevin16 Description: default 16-bit diphone voice Organization: cmu Age: YOUNGER_ADULT Gender: MALE Rate: 150.0 Pitch: 100.0 Style: standard
These results are self-explanatory and give you an idea of the type of information available. There are additional methods that give you access to details regarding the TTS process that are not normally of interest. This includes information such as the audio player being used, utterance-specific data, and features of a specific phone.
Having demonstrated how text can be converted to speech, we will now examine how we can convert speech to text.