
MODULE 42
Disaster Recovery
Now that you understand the business continuity planning process, let’s look at another part of the process: disaster recovery. Up until this point, the discussion has centered on the planning piece. In this module, we’ll look at some important concepts in executing that planning. Disaster recovery is concerned with all of the activities that have to happen after a disaster or incident has occurred, in order to protect lives and equipment and stabilize the environment within which the business operates. Internal factors, such as personnel, resources, training, and planning, all affect how well an organization responds to a disaster. External factors also affect disaster response, since the organization must depend upon utility companies, communications systems, emergency services, and other important aspects of the public infrastructure to respond to and recover from a disaster. In this module, the importance of planning and how it affects the ability of an organization to recover from a disaster will be discussed.
Disaster Recovery Concepts
Disaster recovery planning should be a part of business continuity planning. There are subtle differences between these two processes, but essentially, DRP is a subset of the BCP an organization performs to ensure that it sustains its operations before, during, and after an incident or disaster. BCP is normally the first part of the process and usually involves a great deal of careful consideration. DRP is also performed during this process, but the actual disaster recovery operation occurs when a disaster or incident happens and the organization has to react and recover. The DRP is typically a concrete, step-by-step procedure and process the organization executes to save lives, prevent injury, preserve data and systems, and return to an operational status.
Most information security texts and professionals break up disasters and incidents into two main categories: natural and man-made. This is because some of the reactions to the different kinds of disasters and incidents may be dependent on whether the disaster is an act of nature (unintentional, relying on environmental and physical security controls more than technical ones) or an act of man (hacking, data theft, insider threat, arson and so on, relying on more precise technical controls). Natural disasters include weather (hurricanes, tornadoes, and flooding), earthquakes, lightning strikes, wind damage, and sometimes fires. Man-made disasters can also include fire (if set intentionally), accidents, theft, hacking, and so on. As part of the organization’s risk assessment and business continuity planning processes, different disasters are considered for likelihood of occurring and planned for appropriately. For example, a business located in Kansas may not necessarily have to do a lot of planning for hurricanes, but it should definitely consider tornadoes as a likely disaster that could occur and affect the business.
Disaster recovery plans should include considerations such as sounding alarms, notifying personnel, assembling the disaster recovery team, obtaining equipment and supplies, and the logistical planning necessary to move equipment physically and recover data when needed. This should be done based upon system and data criticality and impact if lost, as determined during the BIA process. One important aspect of DRPs that you should remember for the exam (and in real life) is that the top priority in disaster response and recovery is saving human lives and preventing injury whenever possible. This is a higher priority than saving equipment, data, or facilities. DRPs should include personnel protection and safety measures as well. Of course, keep in mind that as IT security folks, it’s not your sole responsibility to plan for things like safety; other more appropriate people in the organization will plan those parts of the response. Nevertheless, in an actual emergency or disaster situation, everyone is responsible for safety.
Backup Plans and Policies
One of the key areas in preparing for a disaster is backing up data to prevent data loss in case the business loses a server or a disaster occurs and the business loses its entire data center. Because everything in security begins with policy, having a well-defined backup policy is an important start to being prepared for data loss in the event of a disaster. The overall backup strategy should specify the frequency and types of backups, of course, but, beyond that, it should specify what data is to be backed up and how. An organization can use several different methods to back up data, and these should be specified in the policy. Policy should also dictate which functional area is responsible for data backups, as well as how quickly data must be restored. The policy may also indicate whether data backups should be stored offsite, how they should be transported, if they should be encrypted, and so on, to protect organizational data further. The policy will also specify who is responsible for data backups, such as the IT department or server management team, for example. During a disaster, certain key positions may be designated as responsible for backups and restorations, if the disaster response team is not organized in the same way as the normal business operations are.
Supporting the backup policy should be the actual plans and procedures that will be used to perform backups. Policy gives direction on what must be done and why, but not necessarily how. For example, a policy would state that all information regarding customer credit card data must be recoverable within two days of a disaster to meet customer expectations and cannot be accessed by the third-party data storage vendor to remain in compliance with PCI regulations. This is where plans and procedures come in. The plans and procedures would then specify details such as how both the flat files and the database information is backed up and which encryption method to use. Backup plans and procedures should further define how backups are performed, the methods used, and particulars regarding restoration. Management will normally write policy (hopefully based upon input from the appropriate technical folks), and the people implementing the policy will usually write the plans and procedures. These policies, plans, and procedures all support the overarching business continuity plan as well as any disaster recovery plans that must be implemented. Together, they ensure that the organization will be able to restore critical data in the event of a disaster or incident.
Backup Execution and Frequency
You can perform backups in several ways. There’s no one particular right way; the methods you use depend upon several factors that the organization must consider. One of the most important factors is the criticality of data. In other words, how important is the data that must be backed up, and how quickly must it be restored to get the organization back up and running? Some backup methods can back up data more quickly than others but may restore data more slowly. Other methods back up data in certain increments based upon file archive bits. Any combination of these methods may be used for the optimum backup solution for the organization.
Backup frequency is another factor that the organization must determine. Data that rarely changes may need to be backed up on a monthly basis only. However, daily transactional data, such as the type produced in financial or commercial transactions, may need to be backed up on a minute-by-minute basis, or even in near real-time, to ensure that the most current data is available and all important transactions have processed. For example, if an earthquake suddenly hit and destroyed a company’s primary e-commerce server, in a well-designed transactional backup system, the speed of recovery and failover is so lightning fast that a customer could click “Buy” and not even realize that the computer that registered the purchase was destroyed, because a new system came online 1000 miles away and recovered their transaction without a visible slowdown. That is totally amazing! Backup frequency is also related to criticality of data, as are the other backup considerations. If the organization has a low tolerance for losing data because of its criticality, the backup frequency increases. The tolerance for (and measurement of) the amount of data that an organization can afford to lose for any given time frame is discussed later in the module.
Backup Types
There are three basic types of backups: full backups, incremental backups, and differential backups. Let’s briefly discuss each.
In a full backup, regardless of whether you are backing up a shared folder, a single hard drive, a RAID array, or an entire server, everything is included in the backup set. At the basic file system level, a full backup also sets the archive bits on files to indicate that the files have been backed up. You can think of an archive bit as an on/off switch. If the archive bit is turned “on” (shown by a binary one in the file metadata), the file has been changed and requires a backup. If the archive bit is turned “off” (signified by a binary zero), the file has been backed up and the archive bit is said to have been “cleared.” Full backups clear archive bits to show that the files have been backed up recently. Any changes to any of the files results in the archive bits being turned back on for those files. A full backup may be executed once weekly, for example, or even daily, as needed by the organization and depending upon the backup system available to the business. Of course, the concept of archive bits applies only to files in the file system itself; it wouldn’t necessarily apply to other types of data structures, such as database tables, for instance. However, other data structures may have similar metadata that indicates its backup or archive status.
The incremental backup typically backs up only files that have changed since the last full backup. In other words, when an incremental backup is run, it will back up only the files that have the archive bits turned on. After it backs up those files, it will turn off the archive bits. If a full backup is run, and then files subsequently change, an incremental backup backs up only those particular files. Because data can change daily, additional incremental backups are run. If there is a data loss on the backup source itself, the data can be restored by first restoring the full backup and then all following incremental backups in the order they were run. Figure 42-1 shows conceptually how a backup scheme involving incremental backups might work.
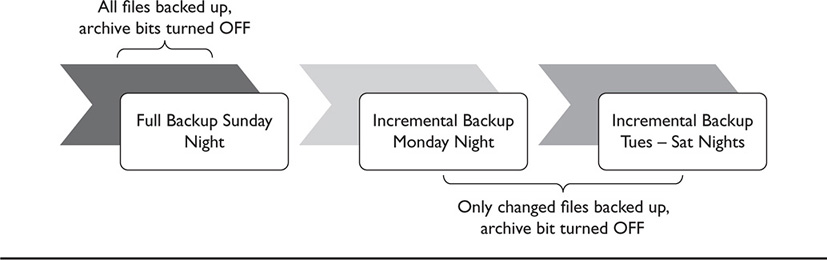
Figure 42-1 A backup scheme using full and incremental backups
The differential backup also gets only a subset of the total data and is also based upon the archive bit setting. However, the major difference between a differential backup and an incremental backup is that the differential backup does not clear the archive bit—it leaves it turned on. So when a full backup is run, and then data changes, a differential backup can be run and will back up the data files that have the archive bits turned on. Since a differential backup does not clear the archive bit, the next differential backup that is run will not only back up that same data, but will also add any additional files that have changed since the last differential (and full) backup. Differential backups, then, are cumulative. Normally, the first differential backup run may not take very long to execute, but as more and more differential backups are executed, because they are backing up more and more data, they take longer to back up. One advantage to differential backups, however, is that if data has to be restored, the full backup is restored first, followed by only the last differential backup to be executed. No other differential backup is necessary for the restoration process, since the last backup contains all the accumulated changed data. Figure 42-2 illustrates the concept of using a combination of full and differential backups.
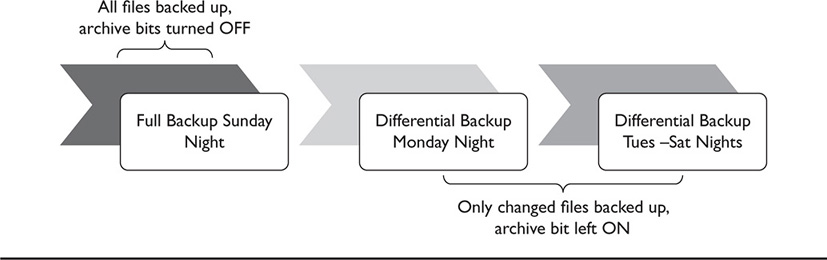
Figure 42-2 Using full and differential backups
To summarize, full backups must be run first and restored first. If incremental backups are used, then any and all incremental backups must be restored in the order they were executed. Incremental backups do not take very long to back up data, but because you must restore all of them, they can make restoration time a bit lengthy. Differential backups, on the other hand, initially back up data quickly, but slowly take longer and longer to back up. However, when a differential backup is restored, only the last backup needs to be restored after the full backup. A typical scenario might involve an organization executing a full backup on a weekly basis, followed by daily incremental or differential backups. It’s also possible to mix and match these types of backups, but that is usually dependent on the type of backup software and system used.
Full, incremental, and differential backups are the most basic types but not the only types of backups. These three categories also tend to apply more to traditional backup sets (defined groups of files) than to arbitrary or loosely defined data. Think of financial transactions, for example, that come in many different formats, files, applications, and so on, and may be generated so fast that even a nightly backup would be too slow and inadequate to capture all the data needed to recover an operation if the data were lost. These types of datasets may be backed up on a near real-time basis using transaction or journaling methods, and back up data on a transaction or record basis instead of on a file-by-file basis. In addition to providing recovery during a disaster scenario, transaction-based backups and recovery can help you solve detailed problems and make it easier to correct certain transactions that failed, that were corrupted, or that were intentionally altered, instead of having to roll back a dataset to a certain point in time, destroying what could be perfectly intact, current data in the process.
Alternate Sites
Alternate sites are an important consideration in disaster recovery planning. Unfortunately, until they actually need it, your bosses may not understand the need for such a site. The reason for having an alternate site is to prepare for a disaster so that the business can operate if the primary site is compromised due to damage or destruction from a natural disaster, mass power outage, communications interruption, and so on. Even if your business primarily has an Internet storefront, it probably has a physical location that houses personnel, data, records, and business processes. Although the servers and infrastructure may be outsourced to a third party, the business’s physical location may be rendered unusable during a disaster, and this alone may prevent the business from operating. With this in mind, it’s a good idea to provide for an alternate processing site for your business.
You should know about three types of alternate sites to consider in disaster recovery planning. These are the three types you’re likely to see on the Security+ exam. The one you use depends upon a variety of factors, including cost and expense, the ability to provision an alternate site, and the need to recover the business either very quickly or to have the luxury of being able to wait a longer amount of time before recovering the business to an alternate location.
The three types of alternate sites that you need to know about, in order of increasing cost and required infrastructure, are the cold site, the warm site, and the hot site.
Cold Site
The cold site is attractive to a lot of organizations simply because it’s probably the cheapest of the three. This is essentially empty floor space where you can set up business operations. The site may have no utilities connected and running at all, or it may have, at minimum, electricity and running water. It also may have heating and air conditioning, but will probably not have any communications connections, such as phone or Internet service. A cold site typically doesn’t have any equipment or work areas set up—it’s essentially just empty floor space waiting for the organization to move in if necessary. The best thing about a cold site is that it’s cheap. The worst thing about a cold site is that it’s so bare in terms of what it provides that it will likely take a long time to move the business into it and set up operations. The organization should decide which is more important, cost or recovery time, and make a decision on whether a cold site is appropriate. An organization that uses a cold site may have the luxury of great deal of time before it has to recover the business to normal processing levels.
If you’ve never encountered a cold site, it may be because they are more rare than warm or hot sites. Organizations that use them either never expect to need them, also have backup warm or hot sites and the cold site is just a second backup, or they use a similar concept in establishing alternate processing sites. For example, suppose a small grocery store chain has four grocery stores and outsources its IT processes. A single desktop computer in one store contains all employee data and graphics for newspaper ads for all of the stores. If that computer goes down, weekly full backups could be sent over to another store; if a disaster hits, they can simply buy a new desktop and keep it in one of the other stores. This is like having a “cold” capability, but at a “hot” site, if that makes sense.
Warm Site
As Goldilocks thought, a warm site may turn out to be just right for an organization. It’s a little bit more expensive than a cold site, because it provides a little more than empty floor space. It will likely come with full utilities, including heat and air conditioning, electricity and running water, and perhaps even phone and Internet service already provided. A warm site could also come with some rudimentary workspace set up, such as tables and chairs. An organization that uses a warm site will typically also install some basic equipment that it would need for processing, such as workstations and some servers—probably not enough to run the full operations, but enough at least to get started while recovering the rest of the business to the alternate site. The organization may also install peripherals such as printers, scanners, and so on. Typically, this spare equipment likely wouldn’t be updated with the latest operating systems, patches, applications, or even transactional data the business needs in order to get going again. But at least having all of this equipment in place could cut down on the time it would take to recover the business to the alternate site and start processing again. It may be a little bit more expensive than a cold site, but it may also provide a happy medium between cost and recovery time. An organization that uses a warm site usually has a need to recover operations reasonably fast, but it doesn’t have to do it immediately.
Hot Site
As you might’ve guessed, the hot site is the most expensive alternate processing site. However, it offers a bigger bang for your buck, because a hot site has all of the amenities—floor space, utilities, workspace, and fully mission-capable equipment—required to switch business processing from the primary site to the alternate site, with little interruption. This means that an organization can quickly resume operations after a disaster. All the equipment, applications, and data, including current backups and transaction data, are in place at the hot site, or at least they are readily available for restoration in the event of a disaster.
This can be accomplished in several ways, including storing current backups at the alternate site, real-time transactional journaling, and sending live data to the alternate site frequently. As mentioned, there’s a heavy price to pay in terms of cost and infrastructure for having a hot site available to the organization. But if the business requires an almost immediate recovery back to full operations, the expense could be well justified. Many businesses would stand to lose a great deal of money by the hour or day if they could not restore processing quickly after a significant disaster. The bottom line is that the hot site can provide for almost immediate recovery, but at a greater cost.
One interesting note about hot (and even, to a degree, warm) sites is that because of big leaps in certain technologies, such as virtualization technologies in particular, organizations are finding it much easier to establish and maintain these sites. Ten years ago, hardly anyone had a hot site, but it’s much more common to see them now because the equipment and space requirements for virtual machines (VMs) is so much less, and because it’s so easy to keep the hot site VMs looking just like the live sites by just creating snapshots, cloning, or other technology built into the VM software.
![]()
An old trick to handling CompTIA alternate site questions is to remember the following: Hot sites are ready in hours, warm sites are ready in a day, and cold sites are ready in a week. This isn’t exactly the case in the real world, but it will help on the exam.
So, how would an organization determine whether it needed a cold, warm, or hot site? Go back to the business impact analysis (BIA) that was conducted during your business continuity planning. The BIA process helps your organization to determine its assets, to prioritize those assets, and to determine how losing them would impact the organization in terms of cost, productivity, and so on. This analysis leads to determining two other critical pieces of information that can help decide what type of alternate processing site the business may need: recovery time objective and recovery point objective, discussed next.
Recovery Time and Recovery Point Objectives
As part of the business continuity and disaster recovery planning process, your organization will need to determine two important factors that influence how quickly it must recover operations, and how much data it can afford to lose during a disaster without preventing it from recovering. Normally, an organization would determine this during its business impact analysis. These factors are the recovery time objective (RTO) and the recovery point objective (RPO).
Recovery Time Objective
The RTO is the maximum amount of time an organization can be down due to a disaster or an incident. It could be hours or days, depending on the organization’s tolerance for downtime. RTO can be calculated a number of ways, including averaging several RTOs for given processes and systems; or it could be standardized as the shortest amount of downtime allowable for the most critical business processes or systems. It could also be calculated as a cumulative result of the minimum time necessary it takes to restore several critical systems back into operation (using a process called critical path analysis).
Recovery Point Objective
The RPO is also measured in time, but in the context of data. It’s the maximum amount of data that can be lost for the organization, after which the business cannot recover or would suffer significant loss. For example, in a near real-time transaction processing system, the RPO might be only a few minutes’ worth of data that can afford to be lost. Another business may have a more tolerable level of data loss, and their RPO may be 24 hours’ worth of data. RPO can be affected by several factors, including data criticality, as well as the amount of data an organization creates or processes in a given timeframe. In the first example, the organization may have high volumes of data that must be processed quickly, such as financial or inventory data. The second example may indicate a business whose data throughput, in terms of creation or processing, is low or less frequent.
In bringing back the importance of our discussion earlier on transactional backups, let’s say that an organization’s RPO is very small and they can afford to lose only a few minutes of data. But let’s also say that they have been the victim of a hacking attack that may have started a few days earlier. Obviously, they can’t just wipe out the last few days’ worth of data without a significant (and probably serious) impact to operations. How could they maintain their RPO, yet track down faulty or changed data? By using transaction-based recovery, and rolling back only certain records within the past few days of business, those that are suspect due to the hacking attack, that’s how.
Module 42 Questions and Answers
Questions
1. All of the following are considered natural disasters, except:
A. Hurricanes
B. Tornadoes
C. Lightning strikes
D. Arson
2. Which of the following is considered the most important priority during a disaster recovery operation?
A. Saving critical financial data
B. Preventing injury to workers
C. Ensuring critical equipment is removed
D. Saving backup tapes stored in the data center
3. Which of the following dictates what must be done with regard to backup processes?
A. Backup procedures
B. Disaster recovery policy
C. Backup policy
D. Business impact analysis
4. Which of the following determines the frequency of backups in an organization? (Choose two.)
A. Time it takes to restore a backup
B. Data criticality
C. Time it takes to execute a backup
D. Frequency of data change
5. Which of the following basic backup types does not clear the archive bit on a file?
A. Full
B. Incremental
C. Differential
D. Partial
6. Your business needs to be able to resume processing within 12 hours after a disaster. You are looking at alternate site options and decide that the site must have all utilities, redundant equipment, and daily data backups restored to the site. What type of alternate site have you decided to implement?
A. Cold site
B. Warm site
C. Hot site
D. Shared site
7. You are evaluating several possible solutions for alternate processing sites for your business. You decide that you can afford the expense of a warm site and balance it against the time it will take to set up and recover the business operations to the site. Which of the following are characteristics of a warm site? (Choose two.)
A. Fully redundant equipment located at the site, loaded with the most current daily backups
B. Some equipment located at the site to begin limited operations
C. Heat, water, electricity, and communications in a standby mode
D. No utilities
8. Which of the following alternate site options is best to use if the organization has limited resources and can afford to wait a longer period of time before recovering operations?
A. Leased site
B. Hot site
C. Warm site
D. Cold site
9. Which of the following statements best defines the recovery time objective (RTO)?
A. Minimum time the organization can be expected to be down during a disaster or incident
B. Minimum amount of data the organization is expected to lose during a disaster or incident
C. Maximum amount of data the organization can afford to lose during a disaster or incident
D. Maximum amount of time the organization can afford to be down from normal processing
10. Which of the following is considered by the organization to be the maximum amount of data that can be lost during a disaster or incident?
A. Recovery point objective (RPO)
B. Mean time to restore (MTTR)
C. Recovery time objective (RTO)
D. Mean time to backup (MTTB)
Answers
1. D. Arson is a fire set intentionally and is considered a man-made incident or disaster.
2. B. Preventing injury to workers is the most important consideration during disaster recovery operations.
3. C. The organization’s backup policy dictates what must be done to ensure data is backed up.
4. B, D. The criticality of data and how often data changes are two factors that determine the frequency of data backups in an organization.
5. C. A differential backup does not clear the archive bit on a file.
6. C. Given the desired timeframe to recover the business operations, and the level of equipment and support at the site the business needs, this would be a hot site.
7. B, C. A warm site is characterized by having heat, water, electricity, and communications, often in a standby mode, as well as having some equipment located at the site to begin limited operations during a recovery.
8. D. A cold site is the least expensive to acquire and maintain, but it should be used only if the organization has a longer tolerable downtime, because it offers very little other than floor space and requires a longer time to set up and use.
9. D. The recovery time objective (RTO) is the maximum amount of time the organization can afford to be down from normal processing.
10. A. The recovery point objective (RPO) is the maximum allowable amount of data (measured in terms of time) that the organization can afford to lose during a disaster or incident.