
MODULE 23
Network Monitoring
Network monitoring is a necessary evil in the network and security business. Without monitoring, you can’t tell how well your network is performing or know how secure your systems truly are. Monitoring also helps establish accountability, because the actions of users can be traced directly to a particular user.
In this module, we will examine the different aspects of network monitoring and discuss some of the ways it can help you secure your environment. We’ll also look at how logs can provide different types of relevant information to help you monitor and secure the network. Network monitoring isn’t only about logs, however. We’re also going to look at different techniques used to monitor the network, including intrusion detection systems and networks sniffers. Keep in mind that most of the techniques and methods used to manage network monitoring are also quite effective on individual systems and hosts.
Monitoring Networks
We usually monitor networks so that we can collect data on performance and security. This data can come from a wide variety of sources, the most common being device and system logs. Other types of information that we use for network monitoring include intrusion detection/prevention system alerts, firewall alerts and logs, and real-time network monitoring. Real-time network monitoring can involve protocol and traffic monitoring (also known as sniffing) using a protocol analyzer, so that we can collect and store real-time data for later analysis. We can also use certain protocols designed specifically for network monitoring, such as the Simple Network Management Protocol, or SNMP.
Other network monitoring data points may include data that is not normally generated through logs or real-time monitoring. For example, we may routinely record changes in network or host devices that occasionally pop up on the network without warning, through configuration management and control processes. Also, reviewing configuration files on hosts and devices for changes and integrity, either through automated or manual means, can contribute to network monitoring. Other types of monitoring include password cracking, manual audits, inventories, and so on.
Because the most common form of network monitoring involves log file management and real-time monitoring, we’ll focus on those activities in the next few sections.
Log Management
Device and system logs are basically the files, or audit trails, that exist on the device and are generated through a logging service or facility on the host. These logs can contain a wide variety of information, including performance and security information, of course, but also may include a much deeper, detailed level of information on applications, operating system operations, and other types of information that may be useful in certain circumstances, but not necessarily on a daily or routine basis. You’d be surprised at how much data can build up in log files on a device; if you are not proactive in monitoring them and reviewing them, they can lose their usefulness.
Log management is concerned with the logistics of managing all the device logs in your network. In addition to reviewing log files on a periodic basis, you’ll need to consider a few other aspects of log management. First, you have to decide how long to keep log files, since they take up a lot of space and may not exactly contain a lot of relevant information—unless you need to look at a specific event. Sometimes governance, including regulations and other legal requirements, may require you to keep system log files for a certain amount of time, so log management is also concerned with secure storage and retrieval of archived log files for a defined period of time.
Secure storage and retrieval of archived logs is required simply because log files can contain sensitive information about systems and networks, as well as other types of sensitive data. You must ensure that log files are accessible only to personnel authorized to review them and protected from unauthorized access or modification. You must also be able to retrieve the log files from storage in the event of an investigation or legal action against your organization, as well as comply with audit requirements imposed by law. Log management is concerned with all of these things, and effective policy regarding managing the logs in the organization should address all these issues.
Because we are looking for particular types of information on a routine basis, we want to configure logging to give us only that pertinent information. This will help us easily find the relevant information we need and will eliminate the massive amounts of information we really don’t need on a routine basis. For event-specific information, such as a major performance issue, an outage, or even a significant security event, a lot more information may be needed during those specific circumstances only, so we may go into the system and temporarily configure logging to give us far more detailed information when we really need it. Getting that level of detail on a routine basis, however, would likely make our logs unmanageable and limit their usefulness.
For example, let’s say that you are monitoring a potential hacking attempt. You may change the audit level of your network devices or internal hosts to include more detailed information on processes, threads, and interactions with lower level hardware. This level of detail can produce a vast amount of logs very quickly, which can fill up device storage and be very unwieldy to examine. Because of this, you’d want to enable this level of logging only for a short while, just long enough to get the information you need. After that, you’d want to reduce the logging level back to normal.
Decentralized vs. Centralized Log Management
Daily log management and analysis activities are essentially how security professionals handle security events throughout the network and on different systems; they simply review the log files that most operating systems and network devices generate. There are two common ways to achieve log management: the decentralized way or centralized logging management. In smaller environments, such as very small networks that don’t have large infrastructures or in isolated network segments, decentralized log management is usually the norm. This means that administrators usually must visit each and every network host, collecting the logs manually and reviewing them either there at the host or by manually offloading them to a centralized storage area for later analysis.
Centralized logging means that the log files from different machines are automatically sent to a centralized logging facility or server, such as a syslog server, for example. This is more what enterprise-level log management is about. Most modern administrators usually review logs from a central logging facility on the network. Enterprise-level log management products are designed to collect logs from various sources and correlate them into one unified management interface, so the administrator can look for trends or events and timeline correlation.
Log Types
Let’s take a look at the different types of logs you can find on a system or network device. In general, logs can be referred to by several names, depending on the type of system and type of logs that you are collecting. For the most part, logs record events on the system and are often referred to as event logs, as in the case of Microsoft Windows operating systems. Linux systems refer to them as syslogs, or system logs.
Operating systems also store their log files in various locations and in various formats, some of which are compatible and some of which are not. In any event, security personnel often refer to these logs as security or audit logs, or sometimes as audit trails, because they provide information on events that are of a security interest. From a security perspective, we’re auditing access to a particular resource or system. Audit logs can record very specific information about an event, to include usernames, workstation or host names, IP addresses, media access control (MAC) addresses, the resource that was accessed, and the type of action that occurred on the resource. This action could be something such as a file deletion or creation; it also could be use of elevated or administrative privileges. Very often, for example, security personnel may audit when users with administrative privileges are able to create additional user accounts, for example, or change host configurations. An example of a Linux audit log is shown in Figure 23-1.
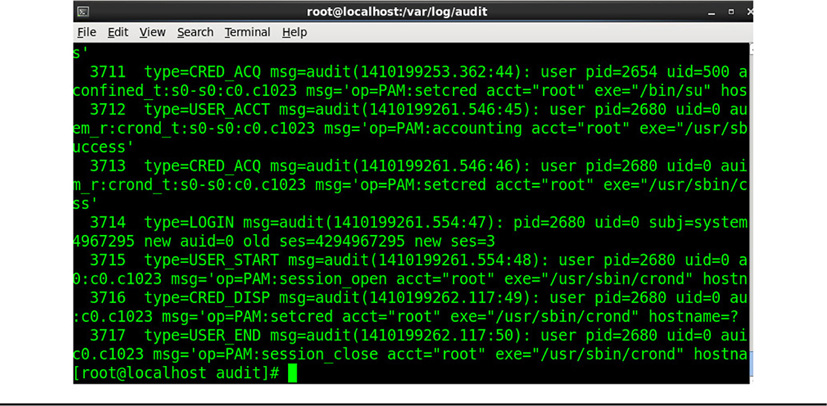
Figure 23-1 An example of a Linux audit log file
Access logs are another type of log that you may hear about; usually these are resource-oriented and list all the different types of access that occur on a particular resource, such as a shared folder, file, or other object. Most systems can produce access logs for a particular resource, but often this has to be configured on the resource itself in order to generate those logs. You could also have access logs that are not system-generated. For example, you can have access logs that are generated manually for entrance into a facility or restricted area.
One of the biggest issues in network security and monitoring is keeping up with all the different log files that are available to you and being able to use them in the most efficient and reasonable way possible. This can be a challenge when you may collect logs from thousands of devices, which record hundreds of thousands of network and security events per day. Being able to produce useful and accurate information from these log files, especially in an enterprise-level network, can be an impossible task if performed manually.
Log Analysis
Log analysis usually means reviewing logs and looking for particular things that the log files contain, such as security events, and then correlating those individual events with an overall problem or issue comprising a series of related events over a specific time frame. The purpose of this is to gather relevant information, both from logs and other sources, to determine the nature of a problem, how it occurred, how to deal with it, and how to prevent it from happening again in the future. Log analysis also allows us to detect trends on our network and devices that may affect long-term performance and security. The different types of events that we may analyze and correlate are discussed in the next section.
Security Events
Security events show you what potentially unauthorized activities or data access is happening on the network, and they can take a wide variety of forms. In some cases, a security event may point to a particular instance of unauthorized access or network misuse; in other cases you may have to collect a series of events from different logs across several devices, as well as other information from the infrastructure, to determine if a security event occurred.
Examples of important security events include unauthorized access to resources, unauthorized users, and even actions by authorized personnel. Even if a particular event is not considered successful, such as a number of unsuccessful login attempts by an external unauthorized user, you still may want to be aware of these events so that you can proactively detect and prevent this type of incident in the future. Network-specific events that you may monitor include detection of rogue machines (unauthorized machines that connect to your wireless or wired networks), interfaces that don’t normally have hosts connected to them, or certain types of traffic passing over them. Other networking events that may warrant monitoring include the use of ports or protocols that aren’t used by any of your applications on the network, and unusually large amounts of traffic targeted at a particular host or using a unusual protocol. These are, of course, not all-inclusive instances of all of the types of things you might want to monitor on the network, but they are fairly common starting points.
Elements of security events recorded in log files that you need in order to investigate include information about the users or entities that access (or attempt access to) objects and resources, and the resources themselves. To collect all data regarding a security event, you must enable logging or auditing both within the system and on the object itself. An example of a Windows Server 2012 security event log is shown in Figure 23-2.

Figure 23-2 A Windows Server 2012 security event log
Continuous Monitoring
Continuous monitoring is a proactive way of ensuring that the network administrator receives all of the different logs and other data points throughout the network from all network devices and all systems, on a constant basis. This data is continually fed into centralized monitoring consoles and applications, which provide the real-time ability to combine it with all the different other types of data received, so that the administrator can correlate it and look for performance or security issues happening on the network. Continuous monitoring also allows network and security personnel to perform trend analysis and detect possible issues that haven’t even occurred yet, but that may occur if events are allowed to unfold as they are without further prevention or mitigation. This is as opposed to manual, ad-hoc log management that is frequently seen in smaller or older networks, where an administrator may go to a dozen different hosts and manually review logs. Continuous monitoring can also ensure that security personnel receive alerts on different events when those events reach certain thresholds.
Auditing
Auditing is an important part of ensuring accountability on the network, and it serves several purposes. Auditing enables traceability between actions taken by the user on a particular resource and a user entity. This type of auditing is effective because you can examine logs and other data points to analyze certain events and construct a timeframe and event sequence surrounding an incident.
Auditing is also used to confirm or verify that security policies are being followed and obeyed. It can also help determine that the technical security procedures and configuration rules implemented on the network are fulfilling and supporting security policies, ensuring that the policies are followed. In addition to monitoring log files, auditing also consists of other activities, such as performing network sniffing traffic analysis, password cracking, vulnerability assessments, penetration tests, compliance audits, and other types of security assessments. Auditing is an important part of risk management simply because it provides a means to confirm that risk mitigations are in place and functioning.
Real-time Monitoring
There are occasions when simply reviewing log files or receiving alerts from logs just isn’t fast enough to detect or prevent security issues. The worst time to discover that a serious security issue has occurred is after it’s over, since you can’t stop an attack or prevent damage to systems and data after the fact. At that point, you’re in reactive mode, and the best you can do is try to determine what exactly happened and prevent it from occurring again. Although damage control after an event is important, a better solution is to have real-time monitoring techniques and methods employed in addition to system and device logs. Real-time monitoring can take several forms, including traffic monitoring, as well as device health and status updates, which are continuously sent to a centralized console. Real-time monitoring enables a network administrator to receive alerts or alarms as the event is happening, giving them the time and resources to stop an attack or security issue actively and prevent damage to systems and data. Real-time monitoring is a form of continuous monitoring and also closely links to enterprise-wide security event information management, which we’ll discuss momentarily.
SNMP
The Simple Network Management Protocol is a way of proactively monitoring network hosts in real-time. Devices that use SNMP have a small piece of software known as an agent installed on them, and this agent can report certain types of data back to a centralized monitoring server. This agent is configured with a Management Information Base (MIB), which is a very specific set of configuration items tailored for the device. Using the MIB, the agent can relay very specific event information to a centralized console in real-time. These events are known as traps and are essentially specific events configured with certain thresholds. If a configured threshold is reached for particular event, the trap is triggered and the notification or alert is sent to the management console. These traps and messages can let an administrator know about the device status and health; in other words, the administrator could get information on when the device is up or down, whether its hardware is functioning properly or not, if its memory or CPU use is too high, and other interesting details about the device. In some cases, these trap messages could indicate an active attack against the device or some other type of unauthorized access or misuse.
Security Information and Event Management
Until recently, the traditional way to manage logging and monitoring in a network was to sit down at a particular system and look at the log files generated by the system, reviewing them for the events of interest; however, this is not the most efficient way to manage network monitoring and analysis activities. Another new paradigm that falls under continuous monitoring is Security Information and Event Management (SIEM). SIEM is an enterprise-level technology and infrastructure that collects all of the different data points from the network, including log files, traffic captures, SNMP messages, and so on, from every host on the network. It can collect all this different data into one centralized location and correlate it for analysis to look for security and performance issues, as well as negative trends, all in real-time. SIEM infrastructures usually require a multitier setup consisting of servers designated as centralized log collectors, which pass log events onto other servers designated for mass log storage, which are accessed by devices focused purely on real-time correlation and analysis.
Note that although SIEM requires real-time monitoring technologies, just because you’re using some of these real-time technologies doesn’t necessarily mean you are using SIEM. SIEM unifies and correlates all the real-time events from a multitude of disparate sources, including network alerts, log files, physical security logs, and so on. You could still have real-time monitoring going on, but without combining and correlating all of those different event sources. A true unified SIEM system is required to do that.
Alarms and Alerts
Alarms and alerts are produced as a result of a significant security or performance event occurring on the network. Ideally, alarms and alerts are sent from host and device monitoring systems in real-time, so that they can be acted on quickly. They are usually set to notify an administrator in the event that a certain type of occurrence or activity is happening on the network. This could be a certain protocol or port being accessed, certain types of traffic coming into the network, or a particular resource being accessed by a certain individual, for instance. Alarms and alerts are usually configured in advance via rules set up on the network monitoring or intrusion detection systems so that if any of these preconfigured events occur or exceed a specified threshold, the systems will send an alarm or an alert to a centralized management console or to an administrator. For example, if network traffic exceeds a certain level for a certain protocol, or it is directed at a certain network host, for example, then an alert can be triggered and the network administrator will be notified. Since most network alarms and alerts can be configured to send in real-time, the administrator is better able to take timely action to eliminate the threat, reduce the risk, or even prevent a negative event from doing damage to systems and data on the network.
Trend Analysis
Trend analysis enables a network administrator to correlate different data sources and data points from various places in the network, such as log files, intrusion detection system logs, wireless and wired sniffing, as well as other event sources, and seek to identify ongoing trends in both performance and security. Trend analysis enables an administrator to look at seemingly unrelated events for patterns, which can indicate emerging issues or areas of concern. For example, if we see a user who unsuccessfully attempts to access a restricted file only one time, it’s likely unintentional and may not be cause for alarm. However, if we look for patterns of usage from a certain user who continually attempts to access files to which he does not have access, we would see that a trend exists, showing that the user is attempting to access data that he shouldn’t, and this may be an ongoing or long-term security risk. We could then notify the individual’s supervisor for remedial security training or disciplinary action for attempting unauthorized access to sensitive data. Trend analysis is very important in being able to use network monitoring proactively, rather than simply reacting to every security event that occurs.
Reporting
Reporting is the portion of network monitoring at which the administrator receives reports from the different data points from different audit trails and logs, from network intrusion detection systems, and so on, and correlates this data in a report that shows different types of trends or activities occurring on the network. Reporting can be used to identify performance and security issues—in some cases well in advance of their actual occurrence, through trend analysis. Reports should be clear and concise, and should identify clearly what’s happening on the network with regard to security. Reporting should happen not only at the event level, when certain alarms or alerts are triggered and the administrator is notified, but also on a larger, macro level, so security administrators and management are able to develop an idea of what kind of security trends are occurring on the network because of different network monitoring data points, such as user activities, network traffic, resource access, and so on. Most network monitoring devices and utilities provide different levels of reports that can be consolidated and produced for both event-level activities as well as emerging trends over time.
Module 23 Questions and Answers
Questions
1. Which of the following are valid sources of data for network monitoring? (Choose all that apply.)
A. User complaints
B. Log files
C. Traffic captures
D. SNMP traps
2. Which of the following is an important aspect of good log management?
A. Secure log storage
B. Deleting logs due to storage space constraints
C. Reviewing only logs produced in the last seven days
D. Retaining and reviewing log data only from servers
3. Which of the following are valid reasons to monitor networks?
A. To identify workstations and servers that can be decommissioned
B. To identify performance issues
C. To identify security issues
D. To identify workers who surf the Internet too much
4. Your manager wants you to institute log management and analysis on a small group of workstations and servers that are not connected to the larger enterprise network for data sensitivity reasons. Based upon the level of routine usage and logging, you decide not to implement a management console but intend to examine each log separately on the individual hosts. What type of log management are you using in this scenario?
A. Centralized
B. Enterprise-level log management
C. Decentralized
D. Workgroup-level log management
5. Which of the following types of logs are you most likely interested in reviewing to discover whether a resource has been accessed by an unauthorized individual?
A. Audit log
B. Application log
C. System log
D. Maintenance log
6. All of the following characteristics describe log analysis, except:
A. Reviewing logs
B. Correlating logs event
C. Trend analysis
D. Securing stored log files
7. Which of the following would be considered a security event of interest that you might discover in a log file?
A. An increase in network traffic during the time the majority of employees come into work
B. A user account repeatedly locked several times after invalid login attempts
C. A user successfully accessing a restricted document several times
D. A user unsuccessfully accessing a restricted document one time
8. Which of the following could be considered a real-time network monitoring technique?
A. Log review
B. Traffic sniffing
C. Monthly password audits
D. Configuration file review
9. Which of the following might result in an alert being sent to a network administrator?
A. A new restricted financial data folder created by the director of finance
B. An increase in HTTP traffic during lunchtime
C. Network traffic using a specific protocol exceeding a certain threshold
D. A helpdesk technician creating a new user account
10. Which of the following refers to correlating and analyzing different types of data to determine security issues that may happen over longer periods of time?
A. Trend analysis
B. Log analysis
C. Network monitoring
D. Traffic analysis
Answers
1. B, C, D. User complaints are not really a valid source of network monitoring data, but log files, network traffic captures, and information from SNMP traps are valid data.
2. A. Secure log storage is an important aspect of good log management. The other choices are examples of inefficient or ineffective log management.
3. B, C. Identifying both performance and security issues are valid reasons to monitor networks.
4. C. In this scenario, you are using decentralized log management, since you are not using a centralized log management facility or console to collect all of the applicable logs and review them in one place.
5. A. An audit log (or security log) is the log you want to review to discover whether a resource has been accessed by an unauthorized individual.
6. D. Securing stored log files is not part of log analysis, but it is part of effective log management.
7. B. A user account locked several times after repeated invalid login attempts would be a security event of interest, since this could indicate a brute-force attack.
8. B. Traffic sniffing could be considered a real-time network monitoring technique, since the administrator can view network traffic instantly, as it occurs.
9. C. Network traffic using a specific protocol and exceeding a certain threshold might be a valid reason to send an alert to a network administrator, since this can indicate a network attack.
10. A. Trend analysis refers to correlating and analyzing different types of data to determine security issues that may happen over longer periods of time.