
MODULE 18
Storage Security
In this book, we give a great deal of attention to securing data in transit—data that is being transmitted over networks. We cover security while data is being transmitted or received between network-connected hosts. We also have to talk about securing data at rest—data in storage. There are certainly threats to data in transit, as it is vulnerable to being intercepted and modified. However, data at rest also faces significant threats. Some of the same measures that we take to secure data during transmission are also used during storage as well, such as encryption and authentication requirements to access the data. In this module, we’ll discuss these and other measures used to secure data at rest, and we’ll briefly discuss some of the different storage methods available for keeping data safe from unauthorized access or modification, making sure it’s available to the people who need it when it’s needed.
Securing Data Storage
In the next few sections, we’ll look at a range of data storage solutions, from small host-based storage solutions (such as removable media) to larger network-based enterprise storage solutions. You’ll find that many of the security issues we discuss are actually common to all of these, regardless of size or scale, such as unauthorized access or data modification. Likewise, some of the security controls we implement on data while it is in storage are equally applicable. Encryption, for example, is a good security measure to take, whether the data resides on a thumb drive or on a storage area network (SAN) solution. We’ll discuss network storage protocols, as well as the different methods used to store and secure data.
Storage Protocols
Gone are the days when large enterprise-based storage used clunky, directly connected cables and interfaces to provide storage for hosts. These days, modern storage solutions typically don’t connect directly to workstations or servers; they’re almost always network-based. Because they are network-based, they may use standard network communications protocols or sometimes even specialized interfaces that connect to the network. The next two items we’ll discuss are storage protocols that provide communications between workstations and network storage solutions.
iSCSI
You’ve probably heard of the Small Computer System Interface (SCSI), which has been used for years to provide access to peripheral storage devices through a robust communications interface protocol. For years, SCSI has been used in higher-end workstations and servers. Although, for the most part, older versions of SCSI have been replaced with technologies such as external serial advanced technology attachment (eSATA), a new SCSI version has appeared on the market and is used primarily for communications with high-capacity, robust storage solutions that are connected to hosts via a network. This new version of the protocol, called iSCSI (for Internet SCSI) is based on the Internet protocol (IP). It’s used to connect network-based storage solutions to enterprise hosts. Because it’s IP-based, it can be treated as an ordinary network protocol and can be routed, encrypted, and so on. This also means that the storage devices don’t have to be physically located near the hosts that use them. They can be located across the network, or even across the country, and connected to the local network using WAN links. Since iSCSI is a network protocol, you should probably know that it uses TCP ports 860 and 3260.
Fibre Channel
A fibre channel is another piece of technology used to connect high-capacity, high-speed network-based storage solutions to networks to allow host access. This technology was originally designed to carry data between mainframes and supercomputers, but has been adapted to standard LAN and WAN technologies. It’s not based on any particular protocol; this technology works more at the lower levels of the OSI model. Fibre channel over Ethernet (FCoE) is an implementation of this technology used over standard Ethernet networks.
Data Storage Controls and Methods
Whether data resides in storage that is connected directly to the host or on network-based storage solutions, several different security controls should be used to provide security. These controls include data encryption, as well as the use of hardware-based encryption devices. In this part of the module, we’ll focus on implementing the appropriate controls to ensure data security, regardless of the storage media or how it is connected to the host. We’ll also discuss different methods of storing data for large enterprise networks.
Data Encryption
We’ve discussed encryption throughout this book, and since the focus of this module is on data at rest, we should also discuss encrypting data while it’s in storage. We can look at data encryption for data in storage in several different ways. First, we need to use robust, secure data encryption protocols, such as the Advanced Encryption Standard (AES). We should also look at secure authentication to access encrypted data, using two-factor authentication, or complex passwords and decryption keys, for instance. Finally, we should make sure that we have known good backups of encrypted data, so that in the off-chance that encryption fails, data is not lost forever.
Different types of media and data structures may have different encryption requirements. For example, data in a database would typically require encryption of the entire database file, versus individual records. Other methods of securing data within the encrypted database file should also be used, including constrained interfaces and database permissions.
When encrypting data, you could consider encrypting individual files or creating an encrypted container in which to store files. This container would appear to be a single large file while encrypted, but when decrypted it would likely appear in the form of a mounted drive on the system. Individual files can be cumbersome to encrypt and may require the use of a special program on any hosts used to access that file. Additionally, when using multiple encrypted files, the user has to keep track of different encryption keys, unless they use the same key for each individual file. The bad part about this is that if one key is compromised, an attacker could access all of the other individual encrypted files.
An encrypted container or folder, on the other hand, may be a much better way to manage multiple encrypted files without having to keep track of several different decryption keys. Encrypted containers also usually require specialized software to access the files stored in it. One such program used to create encrypted containers is TrueCrypt, a popular encryption program used by regular users and security professionals alike. Although the creators of TrueCrypt recently advised against its continued use due to weaknesses in its algorithms, many people have been using it for a long time (and may still continue to until a viable replacement program is developed). An example of an encrypted container created with TrueCrypt is shown in Figure 18-1.
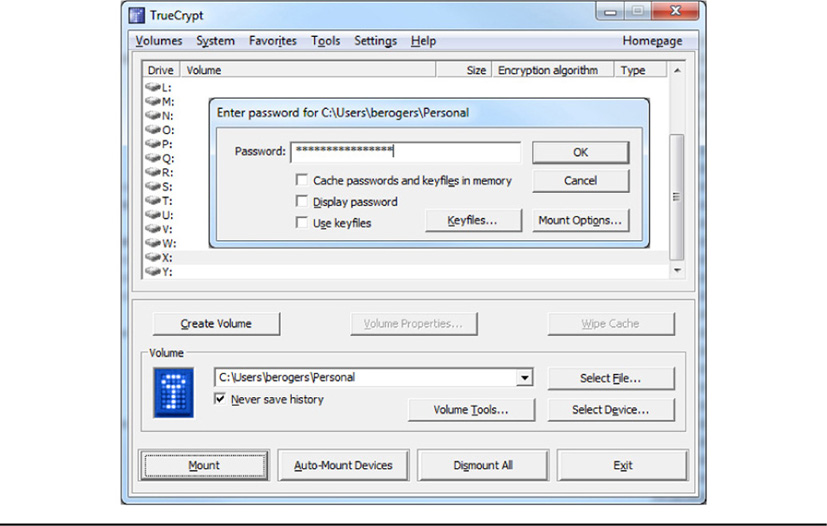
Figure 18-1 An encrypted container created with TrueCrypt
Another option is to encrypt the entire hard drive on a host. This can be accomplished through independent software applications, through utilities built into the operating system (such as Windows BitLocker), or through the use of a special chip located on the main board of the host, called a Trusted Platform Module (TPM), which we’ll discuss in a moment. Encrypting the entire disk prevents anyone from booting a machine or accessing any data on the hard drive unless they enter a preconfigured password or use a decryption key located on removable media at boot time. In lieu of a TPM installed on a host, a user could also use built-in encryption capabilities that come with some operating systems or third-party tools to encrypt entire disks. Windows BitLocker is one such tool, and there are tools built into Linux operating systems as well that can encrypt the entire drive for those hosts. Figure 18-2 shows the options for BitLocker that allow encryption of the entire drive. In Figure 18-3, you can see a part of how Linux creates an encrypted partition during its setup process.

Figure 18-2 Encrypting an entire hard disk with BitLocker

Figure 18-3 Encrypting a partition during Linux setup
An additional aspect of using encryption for data in storage involves the use of removable media. Hardware such as USB sticks, Secure Digital (SD) cards, external hard drives, and other types of removable storage media are prone to being lost or stolen, and any data residing on those media is subject to unauthorized access. That’s why it’s so vitally important to encrypt removable media, so that in the event they are lost, at least the data is secure. Removable media can be encrypted using native file system programs, such as Window’s BitLocker, or using third-party software, sometimes provided with the USB media itself. Figure 18-4 shows how Microsoft’s BitLocker is used to encrypt and decrypt USB removable media.
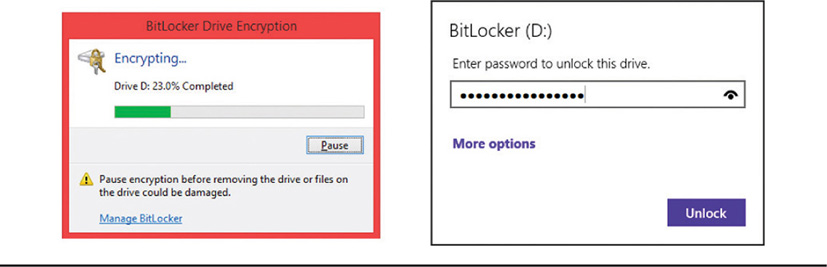
Figure 18-4 Encrypting and decrypting removable media with BitLocker
Hardware-Based Encryption
Hardware-based encryption was previously used almost exclusively in military and high-security industrial applications. More recently, however, hardware-based encryption has become more available for businesses and individuals. Hardware-based encryption can be used to protect data in storage several different ways. The first is the use of the TPM, as mentioned earlier. The TPM is a chip installed on the main board of a computer, usually a laptop or mobile device (although we’re also now seeing it installed on the motherboards of workstations and servers). The TPM is used primarily for full disk encryption. TPMs store and generate encryption keys and are much more efficient, as well as more secure, than software-based disk encryption.
Another hardware-based encryption device is the Hardware Security Module, or HSM. While the TPM is installed on the individual device, an HSM is usually a hardware appliance used to provide hardware encryption services for specific hosts. It can, in some cases, also be an add-on card for servers. HSMs provide a wide range of encryption functions, such as key generation, storage, and management. Additionally, they can also be used to store encrypted data. You might find HSMs used in very specific applications, such as secure kiosks in public areas or automated teller machines.
We also mentioned the use of software to encrypt USB devices, though many USB storage devices come with built-in hardware encryption. Although these USBs are rather expensive for consumer use, many businesses are purchasing them and issuing them to their employees to protect against loss of business-sensitive data when it’s required to be on removable media. These devices look like typical USB thumb drives, but specially built circuitry in them provides hardware-based encryption services. They typically also require specialized applications to read and access the data from the host, as well as to configure the encryption keys on the device during the initial setup. Some specialized hard drive manufacturers also include hardware encryption circuits in their products, although, again, these are more expensive solutions that are more likely to be found in a business environment rather than used by individual consumers.
SAN
A storage area network (SAN) is a network-based storage structure that provides a high-capacity, robust storage capability in an enterprise. In a SAN, data storage appears to local hosts as a locally attached drive or storage area. However, SANs are actually dedicated networks of devices that have their own operating systems and network protocols. SANs typically take the place of older storage technologies such as tapes, optical drives, and massive disk arrays. SANs don’t store data in file systems; instead, they use block level storage. This abstracts the data from any file system, so that different operating systems can access the data seamlessly, as if the data resided on a native file system for that OS.
NAS
Network attached storage (NAS) devices are different from SANs in that NAS devices are attached to a central server that provides for file access on a file system level, rather than using the block level storage that SANs use. In some cases, the user sees a shared folder on the NAS the way they would see one on a typical network file server. This network share could be mapped to a drive letter as any other file server share might be. Additionally, some OSes require specialized application software to access storage on the devices.
Handling Big Data
Big data is a term that has only recently become commonplace. This term refers to large, aggregate amounts of data from disparate sources and databases. These data sources could be scattered across a wide variety of servers, locations, and even organizations. Individual organizations can also maintain their versions of big data, which may be aggregates of all the different data sources within that organization. Many times, big data consist not only of relevant data about a particular person, process, or other item, but also the metadata that goes with those things. Big data could also include log files, metadata about systems, and so on.
Consider this scenario: Suppose databases contain healthcare information about individuals, such as medical records, diagnoses, treatments, and so on. Because healthcare costs money, consider that this healthcare data might also be linked to other types of data in order to bill patients for medical services. So it may be linked to databases that contain billing and financial information, such as credit card data bank accounts and so forth. It also may be further linked to information that uniquely identifies individuals, such as names, addresses, driver’s license numbers, Social Security numbers, and so on. At some point, all of this data gets linked together through interfaces between organizations, or subsets of data are shared between businesses and the government. There are ways to gather, or mine, this data to assemble larger pieces of an individual’s life if an organization needed to know not only health information, but also financial information about an individual. Keep in mind that big data isn’t really used for storage and retrieval of data; it’s more often used for data analytics. This data analytics could include historical or trend analysis or extrapolation of data from different sources into coherent, predictive models. In this example, an organization might use all these different data sources to predict trends and relationships between healthcare and finances, which could be further used to justify the rising costs of insurance or medical services. It could also be used to justify the passage of certain laws or regulations that cover both healthcare and finance.
Big data has been considered an increasing threat to personal privacy, since it can be used to paint a complete picture of a user’s actions, data history, and so on. Advertisers use the data to target marketing programs and advertisements at users; governments use big data to determine if there are indicators of criminal or terrorist acts; merchants use it to develop information on buying trends and feedback on products. Instead of knowing only a particular fact or piece of information about an individual, big data can help create a very large, overarching, multifaceted profile of individuals and their locations, habits, and activities. Organizations that deal with big data should carefully consider privacy implications for the collection and analysis of this type of data, as well as the serious security protections it requires.
Data Storage Policies
As we’ve discussed many times throughout this book, any type of security control begins with policy. To protect data, regardless of whether its data stored on a workstation or in a very large SAN, data storage policies are necessary to establish the requirements and standards for protecting data throughout all the different phases of its lifecycle (creation, use, storage, transmission, reception, and eventual disposal). A good data storage policy should address a few minimum requirements, such as the policy on wiping media to protect against the disclosure of sensitive data for media that will be reused or disposed of. Another topic would be how sensitive data is disposed of, to include methods of destruction. Data retention is another issue that a data storage policy should address. This will often come in line with higher level governance, since some categories of data are required to be kept for a specified amount of time for legal and compliance purposes. The policy should also address how the data is stored, whether it is encrypted or not, if it should be stored onsite or offsite, and how permissions will be set for authorized personnel to access data in storage. The data storage policy may also address transport of data, particularly for data that is stored offsite for archival purposes. This policy might specify that data transported must be encrypted and secured through physical means to prevent anyone from intercepting or stealing it. In any event, data storage policies should be directive in nature and specify requirements that all personnel should have to obey for handling data.
Data Storage Best Practices
In this section, we’ll discuss some of the best practices used in data storage as well as in helping the organization manage its overall risk with data at rest. We’ve already discussed some of these risk management strategies, including encryption and offsite storage. The next topics will address security from the perspectives of confidentiality, integrity, and, of course, availability. We’ll take a look at the different aspects of hardware redundancy in particular.
Fault Tolerance
Fault tolerance is a concept that describes the ability of the infrastructure to resist hardware and capability failure. Fault tolerance can be achieved through several means, including redundant equipment, backup capability, use of failover technologies, and so on. Fault tolerance directly supports the concept of high availability, in that it prevents even the momentary loss of services or data and provides a constant means for data and services to be available. Several different technologies support fault tolerance, as we’ll discuss in the next few sections.
Hardware
Hardware is one aspect of fault tolerance. To maintain fault tolerance, typically redundant hardware is required—this means spares of almost everything required to maintain operations around the clock, including spare parts, workstations, servers, and so on. We discuss business continuity and disaster recovery later on in the book; you’ll see how having redundant hardware is necessary for those aspects of fault tolerance. Additionally, having redundant hardware for capabilities such as network connections and data backup are equally important.
Servers
Servers are another important piece of equipment. Since servers are the backbone of providing data storage access, as well as network services in an organization, you can never have too many. And you must give some consideration to fault tolerance and redundancy for those important items. Redundant servers are necessary for backup in the event that the primary host providing those services to the organization fails or is no longer available. Obviously, having redundant servers comes at a high cost, which is why many organizations are now turning to virtualization to provide redundant server capability. This eliminates the necessity for many physical boxes, but it does require more robust, powerful individual hosts for virtualized servers to run on. A business can use virtualization to provide redundant servers for network services, such as Domain Name System (DNS) and Dynamic Host Configuration Protocol (DHCP), file storage services, and so on. Having redundant servers (whether physical or virtual) is a first step, but not the only one. How these redundant servers communicate with each other and the hosts on the network is also vitally important in terms of fault tolerance. That’s where load balancing and clustering technologies come in, which we’ll discuss next.
Load Balancing
Load balancing is a technique that supports fault tolerance by using redundant servers to share the workload in a large environment. This reduces the workload on any single server, in terms of processing power or memory usage, so that the server never becomes too taxed during high use periods, which could contribute to latency, delays, or service failure. In simple load balancing, identically configured servers each respond to user requests, based upon number of requests per minute, network traffic load, or other criteria. In more complex load balancing configurations, technologies such as clustering (discussed next) provide not only load balancing services, but also fault tolerance and redundancy in high-availability environments. Examples of servers that usually benefit from load balancing include proxy servers, DNS servers, and high-traffic web servers. Load balancing can be configured through software installed on each server, or, more often than not, through load balancing appliances that control user requests between servers.
Clustering
Clustering is a technology that allows you to have several identically configured servers running at one time, which appear as one logical server to the network. This enables fault tolerance, because if one server fails for any reason, the others continue to perform its tasks without the hosts on the network even being aware of the failure. Clustering requires specialized hardware and software, but is a must in environments that require any level of high-availability.
Two types of clusters are usually found in high-availability environments. The first is called an active/active configuration, where all servers in the cluster are up and running constantly, load balancing, and responding to all requests. If any server in the cluster fails, the others are already up and running and providing those services. The other type of cluster is called an active/passive configuration. In this setup, only one server is actively responding to host requests, with other servers in the cluster in a standby mode. If the server providing services fails, the standby servers become the active cluster member and respond to requests. Active/active configurations provide immediate availability, since they are already up and running; active/passive configurations may incur some latency or delay while the standby server becomes active.
RAID
Redundant Array of Independent Disks, or RAID, is a fault tolerance technology that spans data across multiple hard drives within a server. This level of fault tolerance specifically addresses hard drive failure and balances the need for data redundancy with speed and performance. RAID uses multiple physical hard drives to create logical drives on a server, usually making it transparent to users. Data is spanned across the different physical drives, along with metadata (usually parity information), so that if any one drive fails, the other drives in the RAID set can continue to provide data while the single drive is replaced. There are also methods built-in to RAID to rebuild lost data on any replaced drive. Most enterprise-level RAID solutions are referred to as hot-swappable, because they can continue to operate and provide data services to users after a failure, even while technicians are installing a replacement drive. Simple RAID solutions are software controlled and are usually appropriate only for small server setups. Hardware RAID solutions are more robust and complex, and are usually needed for enterprise-level fault tolerance. RAID solutions can also use multiple disk controllers, in addition to the multiple physical disks it uses.
There are several different RAID levels; which one used depends upon different factors, including the number of available disks and the balance of total available space for storage, versus speed and performance. RAID levels can be implemented through striping (writing pieces of data equally across all the different physical disks) and mirroring (completely duplicating data on each disk), and can include parity information (which enables data to be restored in the event of a single disk failure), or combinations of all these. Figure 18-5 illustrates examples of different RAID levels using these techniques.
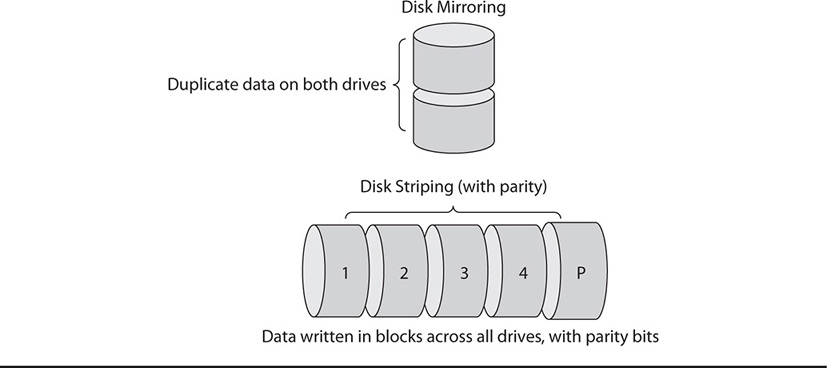
Figure 18-5 Examples of RAID configurations
There are trade-offs for each of these different methods, which include total amount of storage space, speed, performance, and the number of disks required in the RAID array. To configure these different RAID levels, a minimum number of disks is the array is also needed. Table 18-1 summarizes some of the different RAID levels and their details.

Table 18-1 Summary of RAID Levels
Module 18 Questions and Answers
Questions
1. Which of the following is a storage protocol used to connect network-based storage solutions to an IP network?
A. FCoE
B. USB
C. iSCSI
D. eSATA
2. Which of the following is an Ethernet-based storage protocol?
A. PoE
B. FCoE
C. NBT
D. iSCSI
3. Which of the following are valid options for encrypting particular individual files on a host? (Choose two.)
A. Use of encrypted folders or containers
B. Use of a TPM to encrypt files
C. Individual file encryption
D. Encrypting the entire hard drive
4. Which of the following is a chip installed on the main board of the device and is used to store and generate encryption keys?
A. TPM
B. HSM
C. EFS
D. NAS
5. Which of the following types of hardware encryption devices are most likely found as an appliance or add-in card for servers?
A. TPM
B. HSM
C. SAN
D. NAS
6. You need to implement a storage solution on your enterprise network that presents data to individual hosts as if it were on their own native file system. Which of the following storage solutions would meet this requirement?
A. iSCSI
B. Fibre channel over Ethernet
C. Network attached storage
D. Storage area network
7. All of the following are characteristics of network attached storage (NAS), except:
A. Device that is attached to a central server
B. Works on the file system level
C. Uses block-level storage
D. Usually seen on the client is a file share or mapped drive letter
8. Which of the following is used more for data analytics than data storage and access?
A. SAN
B. NAS
C. Big data
D. Enterprise database
9. All of the following are characteristics of fault tolerance, except:
A. Redundant hardware
B. Load balancing
C. Immediate failover
D. Single point of failure
10. Which of the following describes several identically configured servers running at one time, which appear as one logical server to the network, capable of continual operation in the event one server fails?
A. Clustering
B. RAID
C. NAS
D. Load balancing
Answers
1. C. iSCSI is a storage protocol used to connect network-based storage solutions to an IP network.
2. B. FCoE is an Ethernet-based storage protocol.
3. A, C. Use of encrypted folders or containers, and encrypting individual files are both valid options for encrypting particular individual files on a host. TPMs are not normally used to encrypt individual files, and encrypting the entire hard drive will encrypt more files than the user desires.
4. A. A Trusted Platform Module (TPM) is a chip installed on the main board of the device, and is used to store and generate encryption keys.
5. B. A Hardware Security Module (HSM) is usually implemented as a hardware appliance or even as an add-in card for workstations or servers.
6. D. A storage area network (SAN) uses block-level storage, which abstracts data from any file system, so that individual hosts access data as if it used their native file systems.
7. C. Network attached storage does not use block-level storage; it works on a file system level.
8. C. Big data is a concept used more for data analytics than data storage and access.
9. D. A single point of failure is not a characteristic of fault tolerance; this is actually what fault tolerance seeks to avoid.
10. A. Clustering describes several identically configured servers running at one time, which appear as one logical server to the network, capable of continual operation in the event one server fails.