
If you play a little and increase the value of the global constant NUM_BALLS from 50 to 500, you will start noticing degradation in the frame rate at which the simulation runs as shown in the following screenshot:
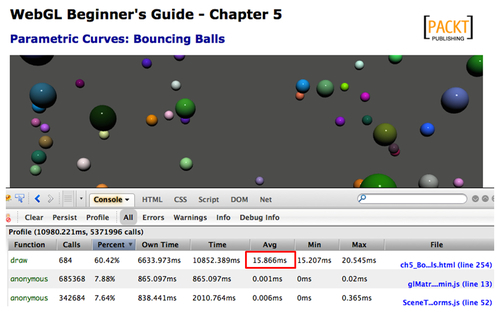
Depending on your computer, the average time for the draw function can be higher than the frequency at which the animation timer callback is invoked. This will result in dropped frames. We need to make the draw function faster. Let's see a couple of strategies to do this.
We can use geometry caching as a way to optimize the animation of a scene full of similar objects. This is the case of the bouncing balls example. Each bouncing ball has a different position and color. These features are unique and independent for each ball. However, all balls share the same geometry.
In the load function, for ch5_BouncingBalls.html we created 50 vertex buffer objects (VBOs) one for each ball. Additionally, the same geometry is loaded 50 times, and on every rendering loop (draw function) a different VBO is bound every time, despite of the fact that the geometry is the same for all the balls!
In ch5_BouncingBalls_Optimized.html we modified the functions load and draw to handle geometry caching. In the first place, the geometry is loaded just once (load function):
Scene.loadObject('models/geometry/ball.json','ball'),
Secondly, when the object with alias'ball' is the current object in the rendering loop (draw function), the delegate drawBalls function is invoked. This function sets some of the uniforms that are common to all bouncing balls (so we do not waste time passing them every time to the program for every ball). After that, the drawBall function is invoked. This function will set up those elements that are unique for each ball. In our case, we set up the program uniform that corresponds to the ball color, and the Model-View matrix, which is unique for each ball too because of the local transformation (ball position).

If you take a look at the code in ch5_BouncingBalls_Optimized.html, you may notice that we have taken an extra step and that the Model-View matrix is cached!
The basic idea behind it is to transfer once the original matrix to the GPU (global) and then perform the translation for each ball (local) directly into the vertex shader. This change improves performance considerably because of the parallel nature of the vertex shader.
This is what we do, step-by-step:
- Create a new uniform that tells the vertex shader if it should perform a translation or not (
uTranslate). - Create a new uniform that contains the ball position for each ball (
uTranslation). - Map these two new uniforms to JavaScript variables (we do this in the
configurefunction).prg.uTranslation = gl.getUniformLocation(prg, "uTranslation"); gl.uniform3fv(prg.uTranslation, [0,0,0]); prg.uTranslate = gl.getUniformLocation(prg, "uTranslate"); gl.uniform1i(prg.uTranslate, false);
- Perform the translation inside the vertex shader. This part is probably the trickiest as it implies a little bit of ESSL programming.
//translate vertex if there is a translation uniform vec3 vecPosition = aVertexPosition; if (uTranslate){ vecPosition += uTranslation; } //Transformed vertex position vec4 vertex = uMVMatrix * vec4(vecPosition, 1.0);In this code fragment we are defining
vecPosition, a variable ofvec3type. This vector is initialized to the vertex position. If theuTranslateuniform is active (meaning we are trying to render a bouncing ball) then we updatevecPositionwith the translation. This is implemented using vector addition.After this we need to make sure that the transformed vertex carries the translation in case of having one. So the next line looks like the following code:
//Transformed vertex position vec4 vertex = MV * vec4(vecPosition, 1.0);
- In
drawBallwe pass the current ball position as the content for the uniformuTranslation:gl.uniform3fv(prg.uTranslation, ball.position);
- In
drawBallswe set the uniformuTranslatetotrue:gl.uniform1i(prg.uTranslate, true);
- In
drawwe pass the Model-View matrix once for all balls by using the following line of code:transforms.setMatrixUniforms();
After making these changes we can increase the global variable NUM_BALLS from 50 to 300 and see how the application keeps performing reasonably well regardless of the increased scene complexity. The improvement in execution times is shown in the following screenshot:
