
DR Architecture for Windows Server 2012 Hyper-V
In this section, you will look at the high-level architecture of how to build a DR solution by using Windows Server 2012 Hyper-V. Please remember that the exact mechanisms and detailed designs vary wildly depending on the specific server, storage, and replication product(s) that you use. If you are planning to use storage to replicate virtual machines, your storage manufacturer will be dictating most of the design.
DR Requirements
There are many ways to replicate virtual machines from one site to another for the purposes of disaster recovery. They run from the very economical to the very expensive, from simple-to-implement to requiring great skill in engineering, and from completely automated and rapidly invoked to time-consuming to recover. Choosing the right option requires understanding the requirements of the business. Remember, these are not IT-dictated requirements; you will need guidance from the directors of the organization in question. Of course, you also need to be aware of the technical limitations of each replication solution. Some requirements are as follows:
- Level of automation for invoking the failover
- Complexity of the failover
- The need to fail over systems in a particular order
- The availability of a copy of the data at the right location
Before you look at specific solutions, you need to understand the two basic methods of getting data from one site to another.
Synchronous and Asynchronous Replication
Every method of replicating data (such as virtual machines) from a production site to a DR site falls into one of two categories: synchronous or asynchronous. This has a direct impact on the RPO of the solution.
Synchronous replication, shown in Figure 11-1, works as follows. Note that this is a generalized example, and specific systems may work slightly differently, but the concept remains the same:
Figure 11-1 Synchronous replication
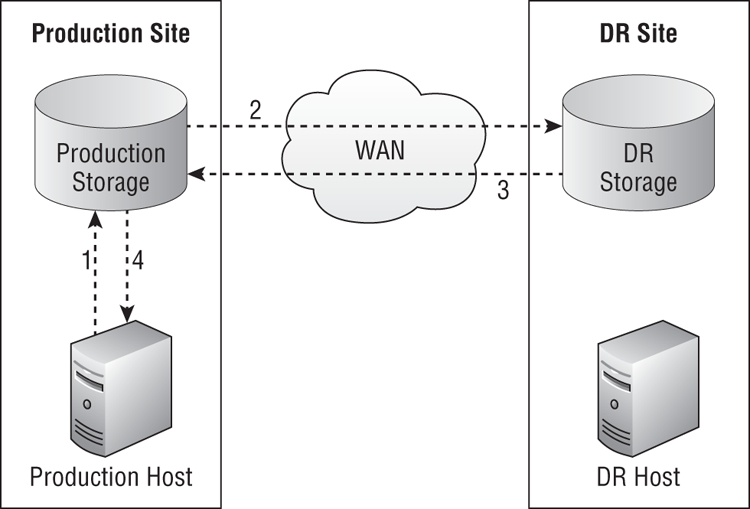
Synchronous replication offers zero or near-zero data loss, or RPO. If something is written in site A, it is guaranteed to also be written in site B. This comes at a great cost; the link between the production and DR sites must be of a very high quality, with the following characteristics, so as not to impact the write performance of the storage:
- High bandwidth, offering high throughput
- Low latency, meaning high speed and short distances between the sites
Very often, you need multi-gigabit links with 2 milliseconds or lower latency, depending on the solution. This sort of link can be expensive, assuming that it is even available in the area, meaning that a small percentage of organizations will use it.
Keep in mind that this requirement for very low latency (usually dictated by the storage manufacturer) will restrict how far away the DR site can be. The need for distance between sites to avoid disasters may prevent synchronous replication.
Figure 11-2 shows asynchronous replication in action. Once again, this is a high-level illustration. Many types of replication can fall under the category of asynchronous replication, and they may not use replication LUNs as shown in this figure. However, the high-level concept remains the same:
Figure 11-2 Asynchronous replication
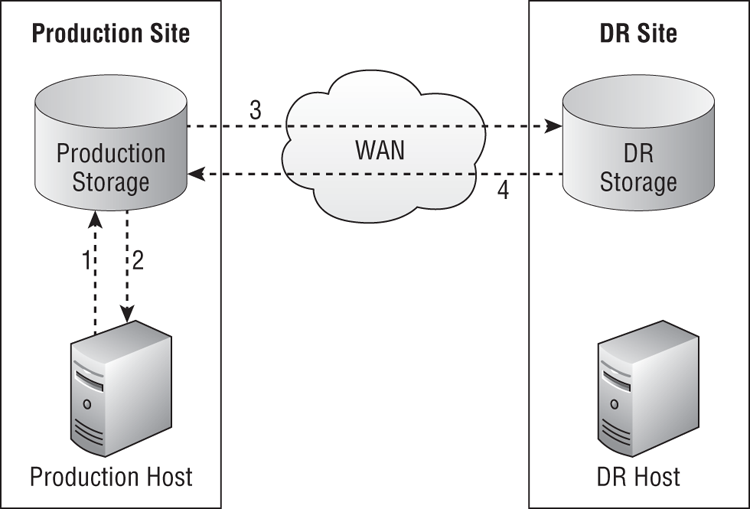
Although asynchronous replication still requires sufficient bandwidth to replicate the data in the required time frame (the rate of replication must be faster than the rate of change), there is little or no impact on the write performance of the Hyper-V host in the production site. That means you don’t need the same low-latency links (such as under 2 milliseconds) and that sites can be farther apart—for example, an office in Wellington, New Zealand could replicate to a datacenter in Dublin, Ireland if there was sufficient bandwidth.
Asynchronous replication can offer an RPO of maybe a few seconds to a few days depending on the solution being used. While this offers more geographic latitude and more-economical DR solutions, this can rule out asynchronous solutions for the few organizations that really do have a genuine requirement for a 0-second RPO.
Armed with this information, you are now ready to look at architectures and solutions for enabling DR replication of virtual machines hosted on Windows Server 2012 Hyper-V.
DR Architectures
There are a number of architectures that a business can deploy for enabling DR with Hyper-V. The one you choose will depend on the storage you use, your desired RPO and RTO, the amount of automation you want to have in failover, and of course, your budget.
Replication between Nonclustered Hosts
A small business may run two or more virtual machines on a nonclustered host. Just because the business is small doesn’t mean that it doesn’t have a need or responsibility for a DR plan.
The Great Big Hyper-V Survey of 2011 (www.greatbighypervsurvey.com) found that one-third of organizations used only nonclustered hosts. Another third of organizations had a mixture of clustered and nonclustered hosts. It is also known that hosting companies (public cloud) like nonclustered hosts because of the lower costs (DAS instead of SAN and no need for host fault tolerance). These organizations need the ability to replicate their nonclustered hosts, possibly to another nonclustered host.
A common example of this particular requirement is a small hotel chain, in which each hotel runs a single Hyper-V host with a number of virtual machines for managing that hotel’s operations. In this case, a solution could be engineered whereby each hotel would replicate to another neighboring hotel, as shown in Figure 11-3. This mutual DR site solution is not unusual in small to medium enterprises. If two sites each require a Hyper-V host and a DR site, then each site’s host would be given additional capacity and be configured to replicate.
Figure 11-3 Nonclustered hosts replicating in a hotel chain
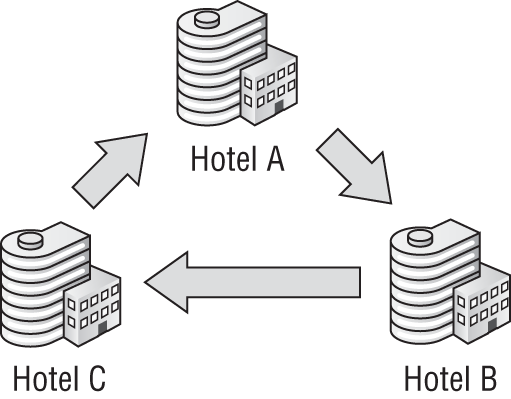
The costs of DR are minimized by using the already existing remote location and by simply adding RAM, storage, or CPUs to existing host hardware. There might be minimal or even no additional Windows Server licensing costs if the original licensing was Windows Server 2012 Datacenter with its unlimited virtualization rights.
Multi-site Cluster
In Chapter 8, “Building Hyper-V Clusters,” you learned how to build a cluster within a site. A cluster can also be built to span more than one site. With this design, shown in Figure 11-4, if the hosts in the production site fail to communicate their availability to the DR site hosts via a heartbeat, the virtual machines will fail over to the hosts in the DR site. Combining this with synchronous replication will give you an RPO of 0. With the automated failover of a cluster, you get a simple invocation plan, and the RTO is the time it takes for virtual machines to fail over and boot. This can make the multi-site cluster a very attractive option.
A cluster requires shared storage such as a SAN, a file server, or a Scale-Out File Server. In a multi-site cluster (sometimes called a geo-cluster, a metro-cluster, or a stretch cluster), as you can see in Figure 11-4, there are replicating SANs between the production site and the DR site. Many SANs will require expensive extensions to enable this functionality. The SAN replication copies the virtual machines to the DR site. The independent SAN in the DR site allows the virtual machines to fail over even if the SAN in the production site is lost. This aspect of the design changes depending on the DR replication solution and the model and manufacturer of the SAN.
Figure 11-4 A multi-site cluster
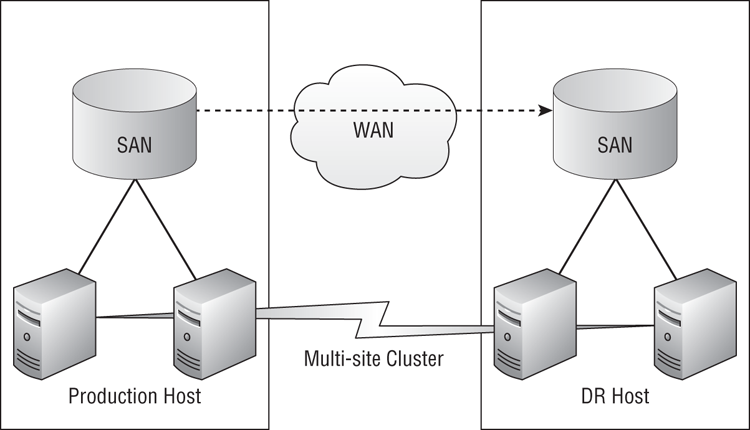
Traditionally, a multi-site cluster is designed to have active/passive sites. All of the virtual machines will normally run on hosts in the production site. There will be sufficient host capacity in the production site to deal with normal host maintenance or the occasional failure, without failing virtual machines to the DR site.
In an interesting variation of the multi-site cluster, both of the sites are active. Virtual machines are running in both sites. Ideally, virtual machines that provide services to site A are running in site A, and virtual machines that provide services to site B are running in site B. This was a nightmare scenario in Windows Server 2008 R2 Hyper-V, thanks to redirected I/O during backup. Although that issue has gone away, we still have some backup considerations:
- What host in the multi-site cluster will the backup server connect to, and will there be cross-WAN backup traffic?
- Will agents in virtual machines be backed up across the replication link? The active/active multi-site cluster requires much more consideration, and make sure you do not deploy one while incorrectly thinking that there is just a single site.
Replication between Clusters
An alternative to the multi-site cluster is to create two Hyper-V clusters, whereby the virtual machines are replicated from the cluster in the production site to the cluster in the DR site. Each cluster has completely independent storage, and can be very different. For example, one site might be using a high-end Fibre Channel SAN, and the other site might be using a lower-cost Scale-Out File Server.
Usually the replication uses a host-based solution instead of hardware-driven SAN replication. This makes it more flexible and allows heterogeneous Hyper-V clusters that can span security boundaries. For example, an HP-based Hyper-V cluster with NetApp storage in a customer site could replicate to a Dell Hyper-V cluster with EMC storage in a hosting company’s site, assuming that the replication software supported this security model.
Mixing Clustered and Nonclustered Hosts
The concept of mixing clustered and nonclustered hosts is an extension of the architect where one cluster replicates to another cluster, whereby the host-based replication now supports heterogeneous host architectures rather than just heterogeneous storage. There are several reasons that you would want to be able to replicate from a Hyper-V cluster to nonclustered hosts, and vice versa:
- A service provider could sell space on a DR cloud, and that cloud is made up of economical nonclustered hosts. The solution must be open to customers who own Hyper-V hosts, clustered or not.
- Alternatively, the service provider could offer a higher-value DR cloud with very high levels of uptime into which businesses with clustered and nonclustered hosts can replicate.
- A business has the option of implementing a budget DR solution without shared storage while using a Hyper-V cluster with higher-quality hosts and storage in the production site.
Once again, we are looking at using host-based storage for this hardware- and storage-agnostic solution with great flexibility.
You have seen how the Hyper-V hosts can be architected, and now you must look at how virtual machines will be replicated from the production site to the DR site.
DR Replication Solutions
This section presents each DR option for Hyper-V at a high level, without using any vendor specifics. You will learn how they work, and what their impacts will be in terms of RTO, RPO, and budget. Each solution may have dozens of variations from the many manufacturers in the world. This text cannot cover every unique feature and requirement but will help you understand the mechanisms, merits, and problems of each type of solution, giving you a starting point for talking to vendors about the products that they offer.
SAN-to-SAN Replication
You can use SAN-to-SAN replication to create a multisite cluster. With this type of solution, which is normally a licensed feature of the most expensive SAN products, a SAN administrator can enable replication of LUNs in a SAN (usually) to an identical model of SAN in the DR site. The replication can be synchronous or asynchronous depending on the model of the SAN.
There is a chance that some SAN-to-SAN replication solutions will not support replicating CSVs if you want to create a multi-site Hyper-V cluster. If you have one of these SANs and you want to replicate highly available virtual machines in a multi-site Hyper-V cluster, you have two choices:
- You can use the SAN’s replication mechanism but will have to create an individual LUN for every virtual machine. This is a pretty dreadful solution that will require an incredible amount of automation and attention to detail. It is not at all cloud-friendly because of the amount of human effort that will be required, thus limiting the effectiveness or even the possibility of self-service virtual machine or service deployment. If running a cloud and using SAN-based replication are your goals, you need a different SAN that can support the replication of CSV.
- Alternatively, you can continue to use the SAN for its storage and backup features, and use a host-based replication solution instead to replicate virtual machines that are stored on CSVs.
Be sure you have verified the functionality of the SAN and decided this strategy before you purchase a SAN or replication licensing.
In theory, it is possible to use SAN-to-SAN replication to copy virtual machines from a Hyper-V cluster in the production site to a Hyper-V cluster in the DR site. However, the DR site cluster would have no awareness of virtual machine creation, deletion, or modification on the storage. The virtual machines would have to be imported into the Hyper-V cluster. Maybe that is something that the SAN manufacturer can offer or that you could script by using PowerShell?
SAN-to-SAN replication is a feature of the highest range of SANs, the ones that offer huge scalability, performance, and that the hardware vendors claim are cloud storage platforms. All of this can be true; just be sure that you have a solution for CSV replication before you make a commitment.
Meshed SAN Storage
A new type of iSCSI SAN has become very popular over the last three years that is based on using appliances instead of the traditional controllers and disk trays. Each appliance looks like a server filled with disks; it runs a special storage operating system, and the appliances can be stacked to create a single SAN.
A possible architecture with this meshed storage is a variation on the SAN-to-SAN replication method to build a multi-site cluster. Meshed SAN storage is more economical than the SANs used in SAN-to-SAN replication, and it normally supports the replication of CSV because it is a multi-master storage system.
You can see an example of the more common types of these solutions in Figure 11-5. This particular SAN, which has proven to be a very popular DR solution for Hyper-V, uses several appliances spread between the production site and the DR site. Any LUN created on the appliances in the production site is also created and updated by using synchronous replication in the DR site.
This design features near-zero RTO and zero RPO. An iSCSI mesh connects every host to every SAN appliance, and this is used to create synchronous replication with zero data loss in the event of a disaster. If connectivity with the hosts in the production site is lost, the multi-site cluster will cause virtual machines to fail over from the hosts in the production site to the hosts in the DR site where they will boot up. The price of the solution in Figure 11-5 includes requiring a multi-gigabit WAN link with less than 2 milliseconds’ latency between the two sites. It also supports a very restricted number of hosts and CSVs. Each host has two connections to each appliance, including those in the other site, and this consumes a lot of SCSI-3 reservations.
Figure 11-5 Mesh SAN storage with synchronous replication
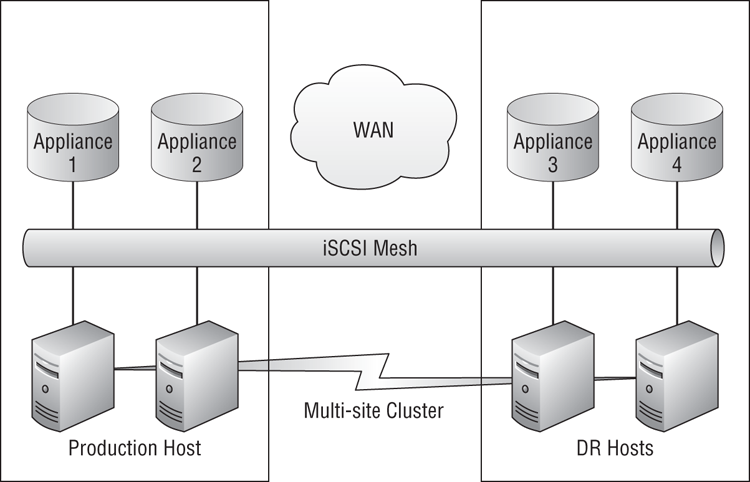
There are several SAN mesh solutions similar to this one. Each has designs and features that are unique to the manufacturer. While this one features synchronous replication, others may provide asynchronous replication or both. The design of the entire multi-site cluster will be dictated by the manufacturer and could include the following specifics:
- What networking offloads to use (or not use) on iSCSI network cards and how to configure them.
- Whether to use dedicated switches for the SAN and how to configure them (memory consumption by jumbo frames is an issue).
- The version of DSM/MPIO to use for iSCSI path fault tolerance.
- Any requirements and configuration of the WAN connection.
- Whether or not a third site is required where a virtual SAN appliance is placed to provide quorum to this SAN “cluster.” This third site may require independent links to the production site and the DR site to avoid a split-brain scenario if the DR replication link (SAN heartbeat) fails.
The major benefit of the SAN mesh is that it is a fire-and-forget solution. You could choose to replicate all LUNs by default, and therefore everything is protected by default in the DR site. Alternatively, you could choose to replicate some LUNs. This would limit the amount of replication traffic and reduce the amount of storage required in the DR site SAN.
SAN-based replication is a one policy per LUN system. If you want to replicate some virtual machines but not others, you need at least two LUNs. That’s just a very simple and small example. An enterprise with thousands of virtual machines could have many LUNs, some not replicating, some that are. And even those LUNs that are replicating might have different policies. You should consider the following if this is the case:
- You will have to architect the self-service of a cloud to enable the end user to choose and switch between replication policies. This will dictate where virtual machines are placed.
- You will not be able to just enable/disable or switch replication policies. Instead you will be using Storage Live Migration to relocate virtual machines to different LUNs in the SAN with zero service downtime. Offloaded Data Transfer (ODX, if supported by the SAN) will speed this up with Windows Server 2012 Hyper-V hosts.
While SAN mesh storage can provide a superb architecture, it does have scalability limitations. This can be fine for a mid-sized enterprise multi-site cluster that has tight control over the number of CSVs that are deployed, disks that are required, and dense hosts (which also offer the best cost of ownership over the life of the hardware) that are used. But this is not a solution for a large enterprise or a large public cloud because of the (relatively) limited clustered storage scalability.
Software-SAN Replication
Small and medium enterprises (SMEs) often cannot afford a hardware SAN, so they purchase a software SAN simulator that turns an economical storage server into an iSCSI SAN. While Windows Server does include the iSCSI target to offer this same basic functionality, these third-party solutions can sometimes offer other features, such as these:
- The ability to create a SAN mesh solution by using this software running on storage servers instead of dedicated appliances
- A VSS provider to improve the performance of storage-level backups
- The ability to replicate LUNs from one site to another by using asynchronous replication
It is this latter feature that draws the attention of SMEs to this type of solution, which is sold at a fraction of the cost of even the most basic SAS-attached SAN without any replication mechanism.
You must be careful of one particular aspect of these solutions. Consider the following scenario:
- A volume containing virtual machines is being replicated from the production site to the DR site.
- There might be no software VSS provider for the SAN, so the system VSS provider creates a VSS snapshot within the volume every time a storage-level backup is performed.
In this case, the SAN can start replicating the data in the VSS snapshot every time a backup job runs. This can be quite a shock for an SME that has a modest connection to the DR site. Ideally, you will have a solution that does have a VSS provider and that creates the snapshot outside of the LUN being backed up so that the snapshot can be excluded from replication.
We have now looked at three kinds of SAN-based replication. They can offer an amazing DR solution with low RPO, low RTO, complete automation, and a simple BCP when used in a multi-site cluster. But there are some drawbacks:
- SANs with SAN replication licensing can be prohibitively expensive for some.
- An enterprise can find it challenging to provide a central DR site if each branch office is buying a different model or manufacturer of SAN. The complexity and variety of skills can make centralization impossible.
- The networking can be very complex.
- SAN-based replication does imply a level of trust between the sites. What if a service provider wants to offer a hosted DR service? Should they buy matching SANs and hire the required skills for every client?
The SME, the service provider, and the enterprise might like something that is storage and host agnostic.
Host-Based Replication
Each of the solutions so far assumes that you have bought a SAN that includes or can include (at a price) replication. What solution can you use for DR replication if you are using one of the following storage systems?
- Standalone hosts with DAS.
- An SMB 3.0 solution such as a file server or Scale-Out File Server.
- A low-end SAN with no built-in replication.
- A high-end SAN that won’t support CSV in a multi-site cluster.
- The storage in the production and in the DR site are completely different and have no common replication systems.
- There is no trust between the storage in the production and the storage in the DR site—for example, a customer and a service provider.
You can use a host-based replication solution to replicate the virtual machines of your choosing from one host or cluster in the production site to another site or cluster in the DR site. Typically (but not always), this is an asynchronous-based replication product that costs several thousand dollars per host. Microsoft has included the ability to support third-party filter drivers in Windows Server 2012 CSVs so that these volumes can be replicated by host-based products, assuming that the manufacturers support CSV replication.
For a business, this can often be the only realistic way to get virtual machines replicated to the DR site with a reasonable RPO and RTO at a fraction of the cost of SAN-based solutions. Unfortunately, the following factors are also true:
- The problems that some third-party replication solutions can cause can be greater than the risk of a disaster. Make sure you evaluate and test as much as you can and do lots of market research before you commit to purchase.
- The solutions may not be all that flexible. For example, they might not be able to replicate from nonclustered host to cluster or vice versa.
- These products cost several thousand dollars per host, and even this can put the solution out of reach of an SME.
Windows Server 2012 Hyper-V includes a new feature called Hyper-V Replica. With no additional license cost, Hyper-V Replica offers the following:
- A solution that was designed for small businesses with commercial broadband, but can be used by enterprises
- Asynchronous interval-based inter-site change-only replication of selected virtual hard disks from selected virtual machines
- Storage type abstraction
- The ability to replicate between nonclustered hosts, clusters, and between nonclustered hosts and clusters
- Replication inside a company (Kerberos authentication) and to a service provider (X.509 v3 certificate authentication)
- IP address injection for use in the DR site
- The ability to do test failovers, planned failovers, and unplanned failovers of virtual machines
- The ability to invoke a past version of a virtual machine to keep inter-virtual machine consistency
- Support for VSS if using applications that require data consistency
You will return to the subject of Hyper-V Replica in the next chapter. It is being referred to as a killer feature because it is quite powerful and is included in Windows Server 2012 for free with unlimited usage rights. Because it has a small RTO and RPO and is included for free in Windows Server 2012, you can expect to see lots of organizations, from SMEs to enterprises, adopting Hyper-V Replica.
Offsite Backup
Having an offsite backup is normally considered good practice. It gives a business an offsite archive of machines and data, with the ability to restore information from a week ago, a month ago, a year ago, or even longer. For some businesses, this is not a choice but a requirement of the law. Some SMEs decided to kill two birds with one stone: they could not afford SAN-based replication or host-based replication, so they decided to replicate their backup to another site. This other site could be a public cloud (hosting company), a service provider, or another office in the company. In the event of a disaster, the company would restore the lost virtual machines from backup.
The solution offers abstractions from host and storage architecture. But it does have a very long RPO and RTO. While a backup solution (such as System Center Data Protection Manager) might be able to synchronize many times per day, it might create only one or two restoration points per day; it is from these times that a virtual machine is restored. If a virtual machine’s restoration point is at midnight, there would be a 12-hour RPO if the virtual machine was restored at midday the following day. The RTO would also be quite long; how long does it take to restore all of your virtual machines from backup? Ideally, this is a disk-disk backup with a disk replica in the DR site. But if you’re talking about tapes being sent offsite, the RPO could be never if the disaster prevents the courier from getting to your DR site.
The emergence of Hyper-V Replica, a free host-based replication solution, does not eradicate the need for offsite backup. Replication and backup do two very different things. Replication creates an instant or near-instant copy of the virtual machine in a remote location. If data is corrupted (maybe via a malware attack or database corruption) in the primary site, it is corrupted in the secondary site. Backup will retain archives of data going back days, weeks, or potentially longer if there is sufficient storage.
You might introduce Hyper-V Replica as the new mechanism for DR because of the lower RTO and RPO, but your replicated backup still will have a role in the DR site. The requirement for an archive that you can restore from does not disappear when you invoke the BCP. You will still have people deleting files, systems corrupting databases, and maybe even still have a legal requirement to be able to restore aged files.
Virtual Machine Connectivity
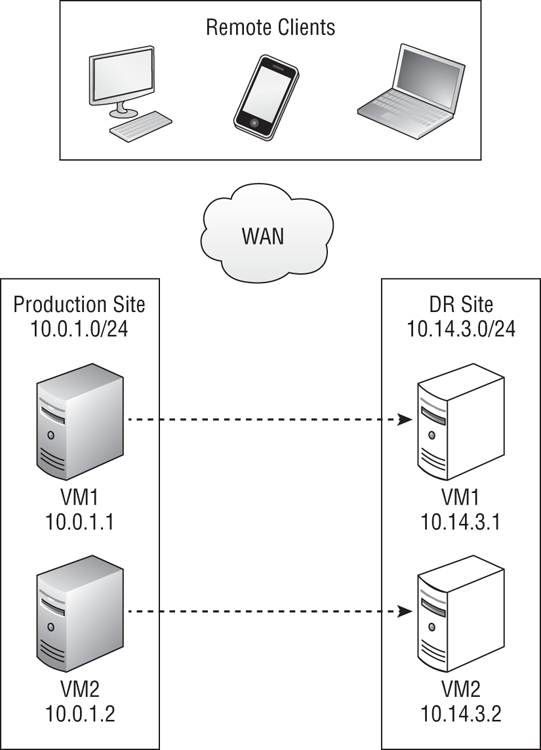
How will you configure the networking of your virtual machines if they can fail over to another site, possibly one with a different collection of subnets, as shown in Figure 11-6? Do you measure RTO based on how long it takes to get your services back online in the DR site, or do you measure it based on how long it takes to get your services available to all of your clients? The business cares about service, not servers, and that is why RTO measures the time that it takes to get your applications back online for users.
The solutions vary—from basic to complex, from free to costly add-ons, from easy-to-manage to complex, and from quick to very slow.
Keep this in mind: your virtual machines will be booting up in the DR site after failing over. That means that they will register their IP addresses and start with an empty DNS cache. But what about clients in other locations who accessed the services provided before the disaster?
Figure 11-6 Virtual machines failing over to another site and subnet
DHCP for the Virtual Machines
A free solution that you could use is to configure the IP stacks of the virtual machines to use DHCP-allocated IP addresses (Figure 11-7). A DHCP server in the production site would allocate IP addresses to virtual machines that are suitable for the production-site networks. An alternative DHCP server in the DR site would allocate IP addresses to virtual machines that are suitable for the DR site. This would allow virtual machines to be automatically re-addressed for the network as soon as they come online in either site. Remember that service availability, and therefore RTO, will be subject to DNS record time-to-live (TTL) lengths.
It would not be realistic to use any random IP address from the DHCP pool(s); network policies and firewall rules, and even some applications will need some level of IP address predictability. You could configure each virtual machine’s IP stack to use a reserved DHCP address. This would have to be done on the DHCP servers in the production site and in the DR site.
There are some points to consider:
- By default, Hyper-V virtual machines have dynamic MAC addresses. DHCP reservations require static IP addresses, so you will have to configure each virtual network card to use a static MAC.
- Your DHCP servers just became mission critical. You absolutely must ensure that the DHCP reservations are being backed up. You also might want to give some thought to clustering your DHCP services.
Figure 11-7 Assigning DHCP addresses to virtual machines
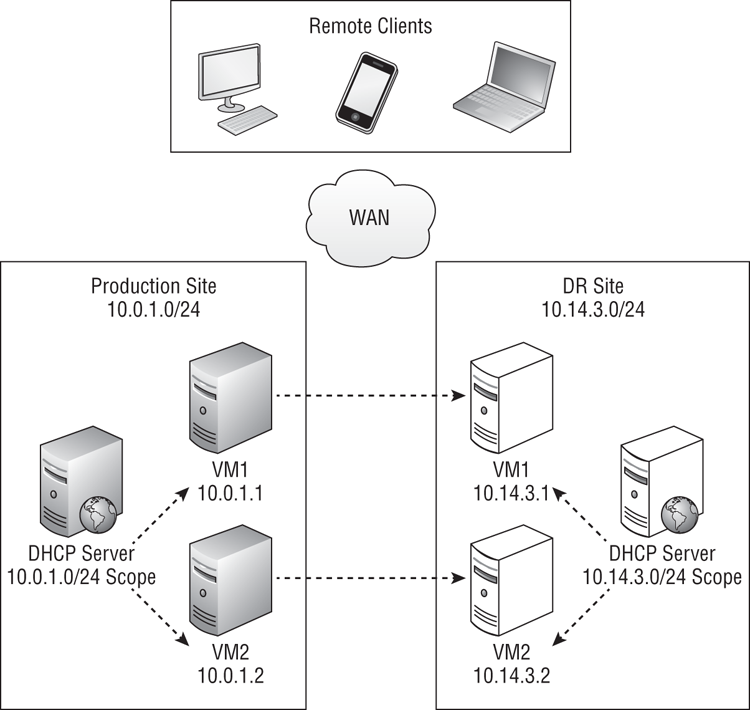
Would you really want to have DHCP running as a virtual machine that is being failed over? If so, make sure it is given a High failover priority and that all virtual machines depending on DHCP are either Medium or Low. This will ensure that the DHCP virtual machine will power up before the others. This does restrict the number of possible High virtual machines; using a physical DHCP server/cluster would be better, but this increases the cost of ownership, which is counterintuitive for an “economy” solution. You could do a lot of mouse-powered engineering to configure the MAC address of your virtual machines in the properties of each virtual machine’s virtual network cards in Hyper-V Manager. It would be quicker to use PowerShell:
Set-VMNetworkAdapter VM1 -StaticMacAddress “001DD8B71C00”If you have System Center 2012 Virtual Machine Manager (with Service Pack 1), you could use the Static MAC address pool feature to do this configuration for you and set each virtual machines’ network card(s) and virtual machine template to use static MAC addresses by default.
You can create each DHCP reservation one at a time by using the DHCP console, or you can bulk-create the DHCP reservations by using PowerShell:
Add-DhcpServerv4Reservation -ComputerName VM1 -ScopeId 10.14.3.0 -IPAddress `
10.14.3.1 -ClientId 00-1D-D8-B7-1C-00 -Name VM1 -Description “Reservation for VM1”Many engineers and consultants hate using DHCP, even with reservations, to address servers. It is a risk, and it adds one more moving part to the invocation of a BCP.
There is no doubt that using DHCP reservations is an economic way to allocate IP addresses to a large number of virtual machines when they power up in the DR site. It is also very flexible, allowing virtual machines to move between networks or clouds that are owned by different organizations, such as cloud DR service providers and their many customers’ networks.
Stretched VLANs
Changing the IP addresses of a machine that provides a network service is disruptive. Consider this scenario:
That is the experience with changing just the IP address of a single virtual machine. Imagine this happening to dozens, hundreds, or thousands of virtual machines and the many clients that are accessing them. You might have designed and deployed a multi-site Hyper-V cluster that enables virtual machines to fail over and start up in just a matter of minutes, but you could have clients that cannot access these services for a relatively long time. For some applications that queue up transactions (such as SMTP/POP3 email at an email hosting company), this could have a compound result that creates the effects of a distributed denial-of-service (DDoS) attack when the clients are able to resume operations when they all try to push through their workloads at once.
The DHCP reservation method for allocating IP addresses that was just discussed would be subject to this. Even though the virtual machines might be running and their services could be reached by their new IP addresses, just about every client will fail to connect to the services until their cached DNS records’ TTLs have expired. If we were being conservative, we would have to say that the DNS record TTL has to be counted as a part of the RTO, possibly extending it from 5 minutes to 25 minutes or longer.
One solution might be to reduce the TTL of the DNS records to a time such as 5 minutes. You would have to be careful of doing this in large enterprises because it would create a much greater load on the DNS servers, which are usually domain controllers. You would have to manually configure existing TTL records or do this via a script, careful to avoid any that should not be modified. The default TTL can be modified by using the instructions found at http://support.microsoft.com/kb/297510. This would not be an option for public clouds, where the DNS records could be anywhere on the planet, with whatever registrar that the customer is using to host the zone.
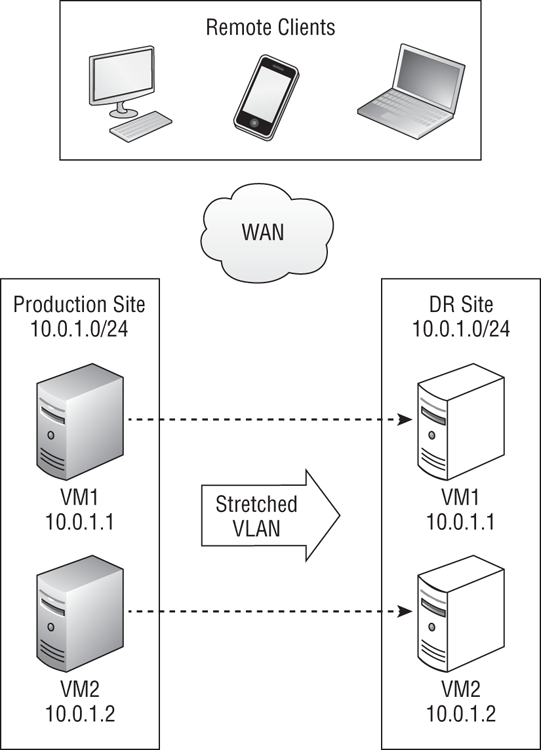
It is for this reason that an organization will prefer to keep the IP addresses the same when a virtual machine fails over from the production site to the DR site. Normally a subnet or VLAN is restricted within a physical site. But it is possible for network administrators to stretch VLANs across sites so that subnets can exist in the production site and the DR site at the same time, as illustrated in Figure 11-8. Stretching the VLANs means that virtual machines can be configured with static IP addresses, as normal, and they will continue to communicate in the DR site with the same IP address.
One consideration about stretched VLANs: you can do it only between two infrastructures that you own. In other words, you can stretch VLANs between two networks or private clouds that your organization owns. A service provider that is selling a public-cloud DR solution could stretch VLANs from each client site to the hosted multi-tenant cloud.
The benefits of stretched VLANs are as follows:
- Each virtual machine requires just a single IP address.
- There is no disruption to normal IP address allocation or DNS operations.
- The RTO does not need to include the length of time of the DNS records’ TTL.
- Stretching VLANs also simplifies the implementation of multi-site clusters.
- Stretched VLANs is a set-it-and-forget-it solution that is cloud friendly. A virtual machine’s cloud-allocated IP address is effective across all sites in the cloud.
Figure 11-8 Stretched VLANs
Network Abstraction Devices
In rare circumstances, an organization cannot stretch VLANs across datacenters. DHCP reservations must be used, but the RTO requirements are too low to allow for a 5-minute DNS record TTL. A large enterprise or telecommunications company solution is to use network abstraction devices, as shown in Figure 11-9.
Each datacenter has its own set of VLANs and DHCP servers. Every virtual network card in every virtual machine has a reserved DHCP address in the production datacenter and the DR datacenter.
A device or devices reside on the WAN between the production and DR datacenters. This abstraction solution integrates with and heartbeats with network devices in the production and DR datacenters. A policy is configured in the abstraction solution to map a virtual IP address (VIP) for each virtual machine to the reserved IP address(es) for that virtual machine. For example, VM1 is 10.0.1.1 in the production datacenter, and it is 10.14.3.1 in the DR datacenter. A policy is created for it to map the VIP of 10.100.1.1 to both of those IP addresses. The DNS record for VM1 resolves to the VIP of 10.100.1.1. That means that no matter what IP address DHCP gives to VM1, it is always known to clients as 10.100.1.1, and they can always connect to it as that.
During normal operations, a remote client on the WAN will try to connect to VM1. DNS resolves the name as 10.100.1.1. When traffic is routed to this address, the network abstraction solution intercepts the traffic and reroutes it to 10.0.1.1. In the event of a disaster, the abstraction solution will detect a failure and start to reroute traffic to the alternative IP address of VM1, 10.14.3.1. Meanwhile, VM1 will fail over to the DR site, power up, and be allocated the DR site address of 10.14.3.1. Clients will continue to resolve VM1 and 10.100.1.1, and 10.100.1.1 will be routed to 10.14.3.1.
Figure 11-9 Using a device to abstract the production and DR VLANs
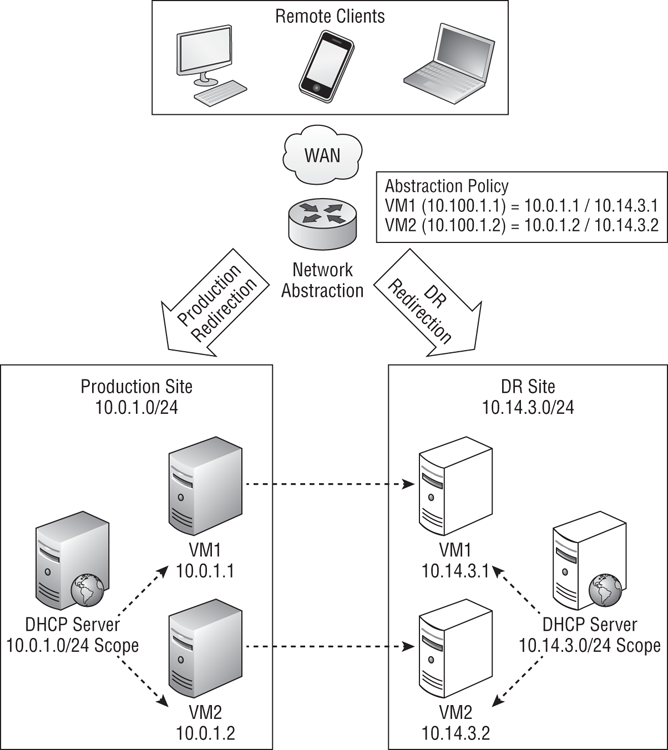
This is a solution for the large enterprise or a telecom company. The abstraction solution lives on the WAN, between the remote clients and the fault-tolerant data centers. A number of high-end appliances will be involved in this solution, and they are not the sort of thing that will fit into the budget of an SME. There are some questions you have to ask yourself when considering a solution such as this if you are building a large farm or a self-service powered cloud:
- Do you have to create/delete a VIP policy for each DHCP address or can you have a more static policy?
- Can you get the abstraction solution to register the DNS records or must they be created manually?
- How automated (scripting/orchestration) can the VIP/DNS configuration be made? This is important in a true cloud, where IT is the last to know about frequently new/removed virtual machines, IP address allocation, or services.
Windows Server 2012 Hyper-V Network Virtualization
The network abstraction solution should have sounded familiar. You learned about a new cloud feature called Network Virtualization in in Chapter 5, “Cloud Computing.”
Thanks to Network Virtualization, a virtual machine can move from the production site to a DR site without having to change its static IP address. The DR site will have a completely different physical IP address, but the virtualization of the network communications offered by Hyper-V will hide this from clients and the virtual machines themselves.
Figure 11-10 shows how VM1 can move from the production site to the DR site without the need to change the IP address and without the need to use stretched VLANs.
Figure 11-10 Network Virtualization enabling static IP failover without stretched VLANs
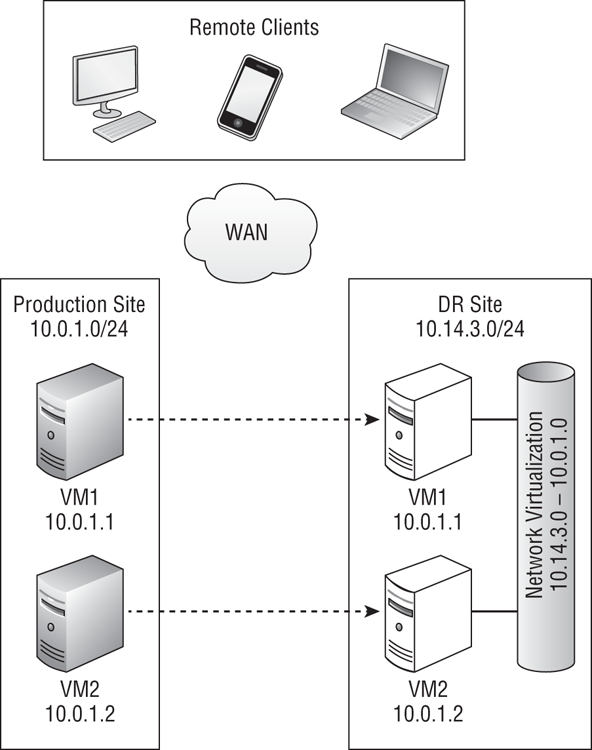
Network Virtualization will be of great interest to those designing DR solutions for Windows Server 2012 Hyper-V in situations where a business cannot stretch VLANs between the production and DR site. This could be the enterprise that was looking at a network abstraction device solution. This could be a business that has a network issue that prevents stretched VLANs. It could also be a situation where a hosting company is selling a hosted multi-tenant (public cloud) DR to many customers.
Where Do the Clients Fail Over To?
For a large enterprise, client devices such as PCs are usually in an office that is remote from the production datacenter, so they fall out of scope for the Hyper-V engineer. But it is different in small businesses, and maybe even medium-sized enterprises, as the production site probably consists of a normal office building with a computer room where the Hyper-V compute cluster is located. In this case, we have to consider how clients are going to access the services that are being failed over to the DR site. What point is there in having a BCP for the services that are running in the virtual machines when there are no PCs for the end users to use those services on?
The traditional solution was for this company to use a specialist DR data center. A number of rooms would be filled with office furniture, phones, PCs, and printers. These rooms were either dedicated to a client of the datacenter or made available on a first-come, first-served basis. Either way, the rooms were typically full of old PCs that were normally turned off, with either no current image or no image at all. Getting these PCs powered up and configured/updated was another thing for IT to do during the invocation of the BCP. In some cases, these rooms were available only on a first-come, first-served basis. If a widespread disaster occurred, only the first few customers of the DR site would get a suite for their users to work in.
There are a few approaches to solving this problem. This is one of the scenarios where Remote Desktop Services (RDS) offers something that a PC cannot. RDS Session Hosts (formerly known as Terminal Servers) and/or VDI (hosted on Hyper-V hosts) can be deployed in one of two ways:
There are a few ways for users to access the RDS Gateway and the business services that lie behind it:
Other solutions might include the following:
These are just some examples of how to let business users have access to services running the DR site after a disaster. Many options exist, and the number is only increasing, thanks to the explosion in mobile computing and the evolution of remote working.
We’ll end this subject with some thoughts for your BCP author to ponder.
Have you considered whether there will be Internet access to the DR site after the emergency? Past disasters have shown us that the telecommunications industry is put under huge stress as friends and family try to make contact and stay in touch. While remote access solutions are economical, they are subject to these stresses. In this situation, traditional PC suites at a DR site are best.
Have you assumed that people can get to the DR site? Will the emergency prevent travel? It became impossible to escape the confines of New Orleans before Hurricane Katrina because of traffic congestion. Routes in and out of Manhattan Island were sealed off after the 9/11 attacks.
Maybe one solution for connecting end users to the services in the DR site is not the right way to go. And sadly, we should not write our BCP to depend on any one person. There might be victims in the emergency, and some may understandably prioritize the safety of their families over their employer’s business.
Finally, the plan should be documented, communicated, and tested. It should include as much automation as you consider reasonable, and should assume that things will go wrong and that the day will be the worst of everyone’s lives.