
Implementation of a Hyper-V Multi-site Cluster
At a high level, creating a multi-site Hyper-V cluster looks like it is going to be just like creating a normal Hyper-V cluster (see Chapter 8). For the most part, it is, with one teeny, tiny exception: there’s a limited-bandwidth, (relatively) high-latency link connecting the two sites that the clustered Hyper-V hosts are spread between. You saw examples of this earlier, in Figure 11-4 and Figure 11-5.
How you create the cluster depends greatly on various factors, including the following:
- What storage are you using?
- How will you configure the cluster to calculate quorum? What happens to the cluster islands if the site link fails?
- What sort of link exists between the two sites? Is there enough bandwidth for replication and cluster communications? How latent is the link?
To be honest, the storage manufacturer is going to dictate a lot of the cluster design—probably including terms for the bandwidth and latency. You will design and deploy the replicating SANs in the two sites according to this guidance. The manufacturer may even have instructions for the storage connections of the hosts. Yes, this has turned into a storage engineering project because in a multi-site cluster, the storage is more important than ever; and it already started out as being a keystone in the virtualization project.
After that is done, you will create the Hyper-V Cluster. Everything you read in Chapter 8 still applies, but there are some sides to the engineering that are specific to multi-site clusters, and that’s where this section offers you help.
Replication Link Networking
High reliability, relatively low latency, and bandwidth that is sufficient for the needs of cluster communications and SAN replication is required for a multi-site cluster. Consider these factors for your bandwidth:
Another important question is whether you have a dedicated or multipurpose link for DR replication:
Multi-site Cluster Quorum
You might remember that quorum comes into play when a cluster becomes fragmented. The cluster uses quorum to decide which of the two fragments should remain online. In a single-site cluster, this is a minor risk. But it is a genuine risk in a multi-site cluster.
The thing that keeps the multi-site cluster (hosts in two sites) acting as a unit is the WAN link. How reliable are WAN links normally? You might put in dual WAN links. But what happens if there’s a power outage outside your control? What happens if work on a building or road tears up the ground where both ISPs are running their cable? And unfortunately, it seems that every datacenter has a single point of failure, even those designed to withstand just about anything.
File Share Witness
Using a witness disk for quorum just won’t be reliable in a multi-site Hyper-V cluster. That is why Microsoft has historically recommended using a File Share Witness for quorum. The File Share Witness is actually just a file share. Where do you create the file share?
Figure 11-11 A File Share Witness running in a third, independently networked site
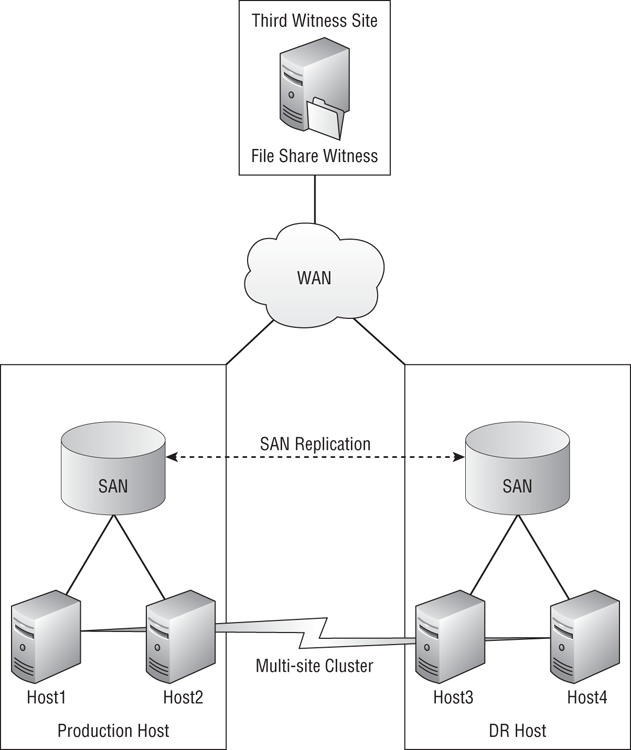
A good practice is to create a file share that is named after the cluster’s Client Access Point (CAP—the name of the cluster) in question. The Active Directory computer object for the cluster/CAP should be given read/write permissions to the share and to the folder in the file system.
Configure the cluster quorum to use the File Share Witness after the cluster is created:
You should test and stress the cluster repeatedly to ensure that you get predictable results during host, link, and site failure. You should not assume that everything will work perfectly; in this type of environment, assumption is the first step to unemployment.
Quorum Voting Rights
Microsoft has historically advised that when we build a multi-site cluster, we use the File Share Witness in a third site. This can add complexity and cost to the infrastructure:
- You need a third site for the witness, and that might involve paying for virtual machine hosting in a public cloud if you don’t have one.
- The production and DR sites need independent networking paths to the witness site.
- Ideally, the File Share Witness needs to be clustered. Does this cluster need to be a multi-site cluster too? Where do you locate the File Share Witness for the File Share Witness cluster?
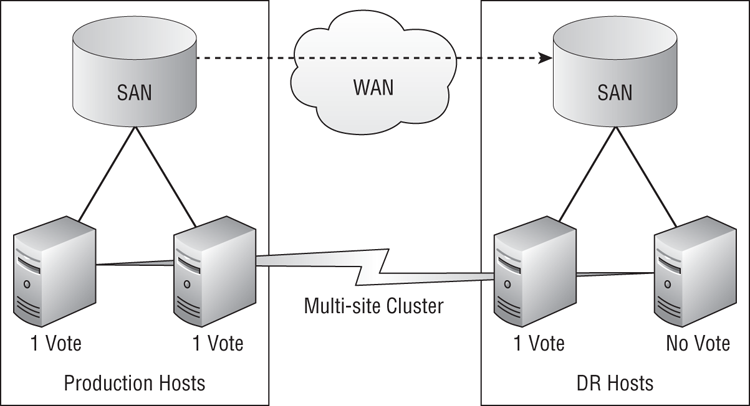
We have an alternative way to disable the multi-site Hyper-V cluster hosts from forming quorum without using a File Share Witness. The quorum vote that is normally assigned to nodes in the cluster can be manipulated. By disabling a node’s or nodes’ right to vote, we can dispense with the need for the File Share Witness at all. Figure 11-12 depicts an example of a quorum vote being disabled.
Figure 11-12 Using disabled quorum votes to maintain quorum in a multi-site cluster
We can configure the ability of cluster nodes (hosts) to vote for quorum by doing the following:
You can do this in PowerShell by running the following:
(Get-ClusterNode Host2).NodeWeight = 0The NodeWeight is 0 if the node has no vote, and the NodeWeight is 1 if the node does have a vote.
Figure 11-13 Disabling cluster node voting rights

Using the example that was previously shown in Figure 11-12, we could disable the voting rights of one node in the DR site. This results in the following:
How many votes should you disable in the DR site? That depends on your architecture. You could disable all of the nodes in the DR site from voting. There is a risk with this; what happens if a number of voting hosts in the production site (V) is less than half the size of the total number of hosts in the cluster (C), because of maintenance or normal host failure? If V < (C/2), you don’t have enough hosts left to form quorum. There is a balancing act:
- Disable enough hosts in the DR site so that they don’t have enough to form quorum by themselves if the DR link fails.
- Leave enough hosts with voting rights so that you can survive host maintenance/failure in the production site.
In a simple multi-site cluster, you might disable one host’s vote in the DR site.
Tuning Cluster Heartbeat
The most important thing for cluster communications is not bandwidth; it is quality of service and latency. Using traffic shaping on the network, we can provide the cluster communications network (heartbeat, and so on) a reliable amount of bandwidth.
Latency is important for cluster communications. The heartbeat between the nodes in the cluster tests to see whether neighboring nodes are responsive. The heartbeats work as follows by default:
The cluster heartbeat is sensitive to latency. By stretching a cluster across multiple sites, we have introduced latency, and this can create false-positives, where nodes may appear offline because the default heartbeat settings are too strict. We can alter the heartbeat settings to compensate for the increase in latency. Configuring the cluster heartbeat is
- Done in PowerShell
- A cluster-wide operation, not a per-host one
You can see the value of a setting by running Get-Cluster to query the cluster and adding the heartbeat setting as an attribute of the query:
(Get-Cluster).SameSubnetDelayThat gives you one value at a time. If you want to see the values for the same subnet, you could run this example that uses a wildcard:
Get-Cluster | Fl SameSubnet*You can also see all the heartbeat settings at once by specifying multiple values with wildcards:
Get-Cluster | Fl *SubnetDelay, *SubnetThresholdThe following example shows how you can set any one of the four heartbeat settings. It will configure the delay for multiple subnet multi-site clusters to be 5 seconds, extending the heartbeat time-out to be five times the original value:
(Get-Cluster).CrossSubnetDelay = 5000How do you decide on the configuration of these settings?
- Quite simply, do not change the default values if you do not need to. Start by testing and stressing a new cluster to see what (if any) problems may occur. You might unearth infrastructure issues that need to be dealt with by the responsible engineers. You should adjust the heartbeat settings only if you have genuine latency issues that are causing false-positive failovers.
- If you find a latency issue impacting a stretched VLAN multi-site cluster, determine the nature of the issue and tune the same-subnet heartbeat settings. Adjusting the cross-subnet settings will do nothing for this cluster.
- If you find a latency issue impacting a multiple VLAN multi-site cluster, determine the nature of the issue and tune the cross-subnet heartbeat settings. Do not tune the same-subnet settings in this scenario, because they will not impact the cross-WAN heartbeat.
Preferred Owners (Hosts)
What is a cluster? It is a compute cluster, a pool of compute power that is managed as a unit. In a cloud, services are deployed to a compute cluster and that’s normally that—you don’t care what host the virtual machines (that make up the services) are running on. In fact, the cloud may be using features such as Dynamic Optimization to load-balance the host workloads, or Power Optimization to power down hosts (both features of System Center 2012 Virtual Machine Manager). The cloud could also be using Live Migration to consolidate and balance the virtual machines across the cluster in ways that appear random to us humans outside the “black box” that is the cloud. Hyper-V cluster administration features such as Cluster Aware Updating do something similar, sending virtual machines around the cluster so that management OS patching can be orchestrated and even automated.
This would be bad if left uncontrolled on a multi-site Hyper-V cluster. This single cluster spread across two sites has no concept of active site or passive site. By default, each virtual machine sees a pool of hosts, and it can run on any of them. That means that not long after you deploy virtual machines in the production site of a multi-site cluster, they can start Live Migrating or failing over to the DR site. But there is something you can do to limit this.
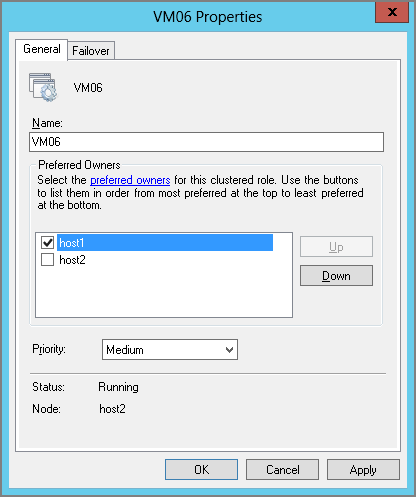
Each resource group, such as a virtual machine, in a cluster has a Preferred Owners setting. This setting instructs the cluster to attempt to fail over the configured virtual machine to the preferred nodes (hosts) first, and to use the nonpreferred hosts if there is no alternative. You could configure the Preferred Owners setting for each virtual machine.
In an active/passive multi-site cluster, the preferred owners would be the hosts in the production site. In the event of a host failure, the virtual machines will fail over to hosts with capacity in the production site. If you lose the production site, the virtual machines will fail over to the DR site.
In the case of an active/active multi-site cluster, the virtual machines in site A would prefer the hosts in site A, and the virtual machines in site B would prefer the hosts in site B.
You can also order the preferred ownership (hosting) of a virtual machine if you want to.
You can configure Preferred Owners in two ways. The first is to use Failover Clustering Manager:
You might also take this opportunity to configure the failover priority (the Priority setting) while in this window. This subject was covered in Chapter 8; you can order the bootup of virtual machines after failover by using one of three buckets: high, medium, or low.
Figure 11-14 Configuring preferred owners for a virtual machine
If you use Failover Clustering Manager only to manage the Hyper-V cluster and the virtual machines, this is a very good solution. However, an organization that is big enough to afford a multi-site cluster will probably put in a management system or a cloud such as System Center. If that’s the case, there is some bad news. System Center 2012 Virtual Machine Manager pays no attention to the Preferred Owners setting when it performs Intelligent Placement during operations such as Dynamic Optimization (virtual workload balancing). That means it will start sending your virtual machines all over the cluster, turning your active/passive multi-site cluster into an active/active multi-site cluster. That will have implications on bandwidth, application performance, and possibly more.
Summarizing Multi-site Clusters
A multi-site cluster will create a hugely scalable DR solution. It is very much a storage salesperson’s dream come true because it requires expensive storage, twice the normal amount of that storage, and maybe even additional licensing/hardware to enable synchronous replication. Your account manager in the ISP is also going to have a good day when you ask about networking for this solution.
You will end up with a fire-and-forget architecture, where virtual machines that are placed in site A will automatically appear in site B. That sounds like it is the ideal way to do DR for a cloud. It can give you completely automated failover of virtual machines after a disaster, having services back online within minutes, without waiting for any human intervention.
But there are complications. Management systems will see both sites in the cluster as a single compute cluster, placing virtual machines on the “best possible” host. And let’s be honest: creating a stretched cluster creates a lot of moving parts that can drive up the cost of the cloud to unreasonable levels, way beyond the real risk of a disaster. Fortunately, Windows Server 2012 Hyper-V includes an alternative that you can consider.